核心概念
1.索引定义
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
2.索引的数据结构
3.选用B+树而不选用B树作为索引
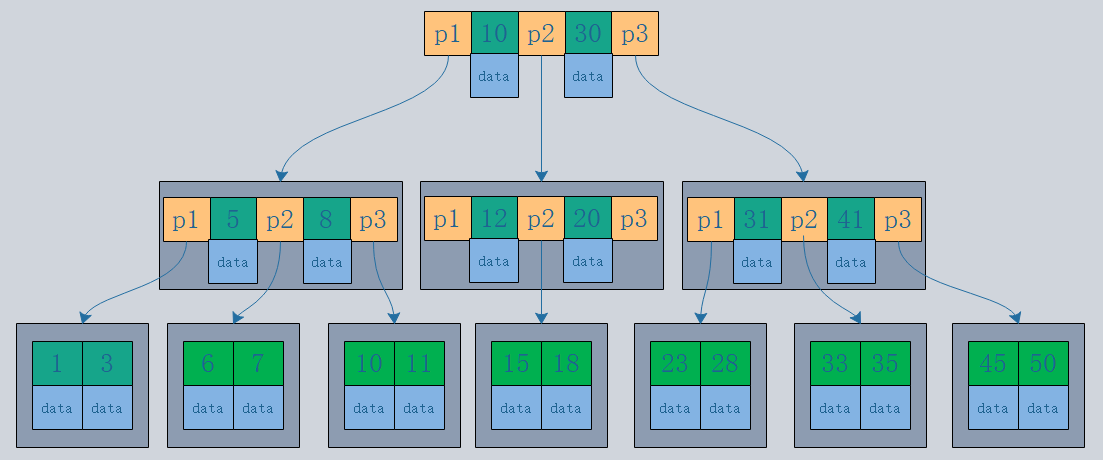
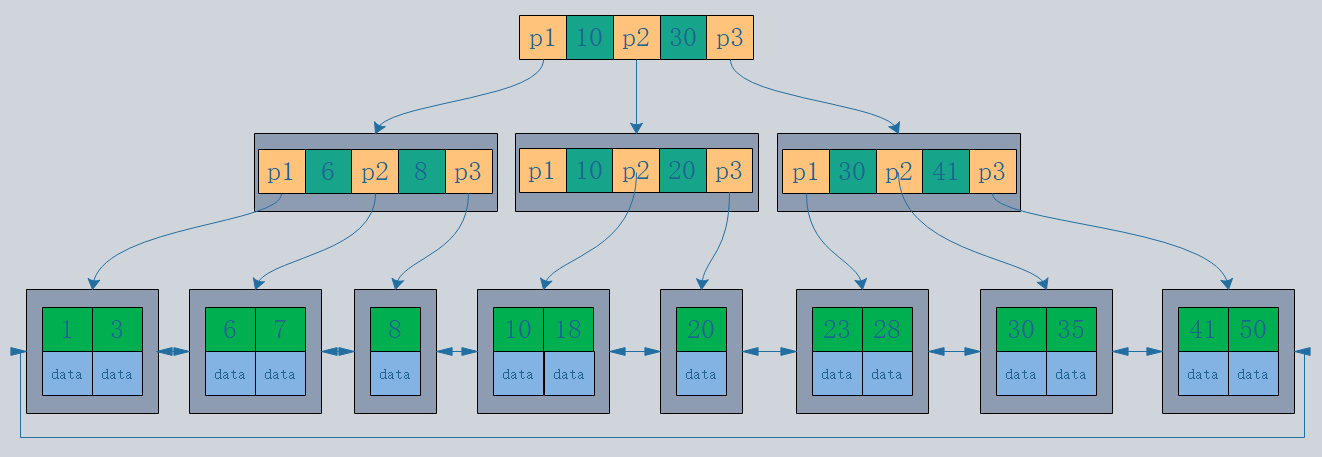
1.主键索引和二级索引
主键索引:索引的叶子节点是数据行
二级索引:索引的叶子节点是KEY字段加主键索引,因此,通过二级索引询首先查到是主键值,然后InnoDB再根据查到的主键值通过主键索引找到相应的数据块。
innodb的主索引文件上 直接存放该行数据,称为聚簇索引,次索引指向对主键的引用
myisam中, 主索引和次索引,都指向物理行(磁盘位置).
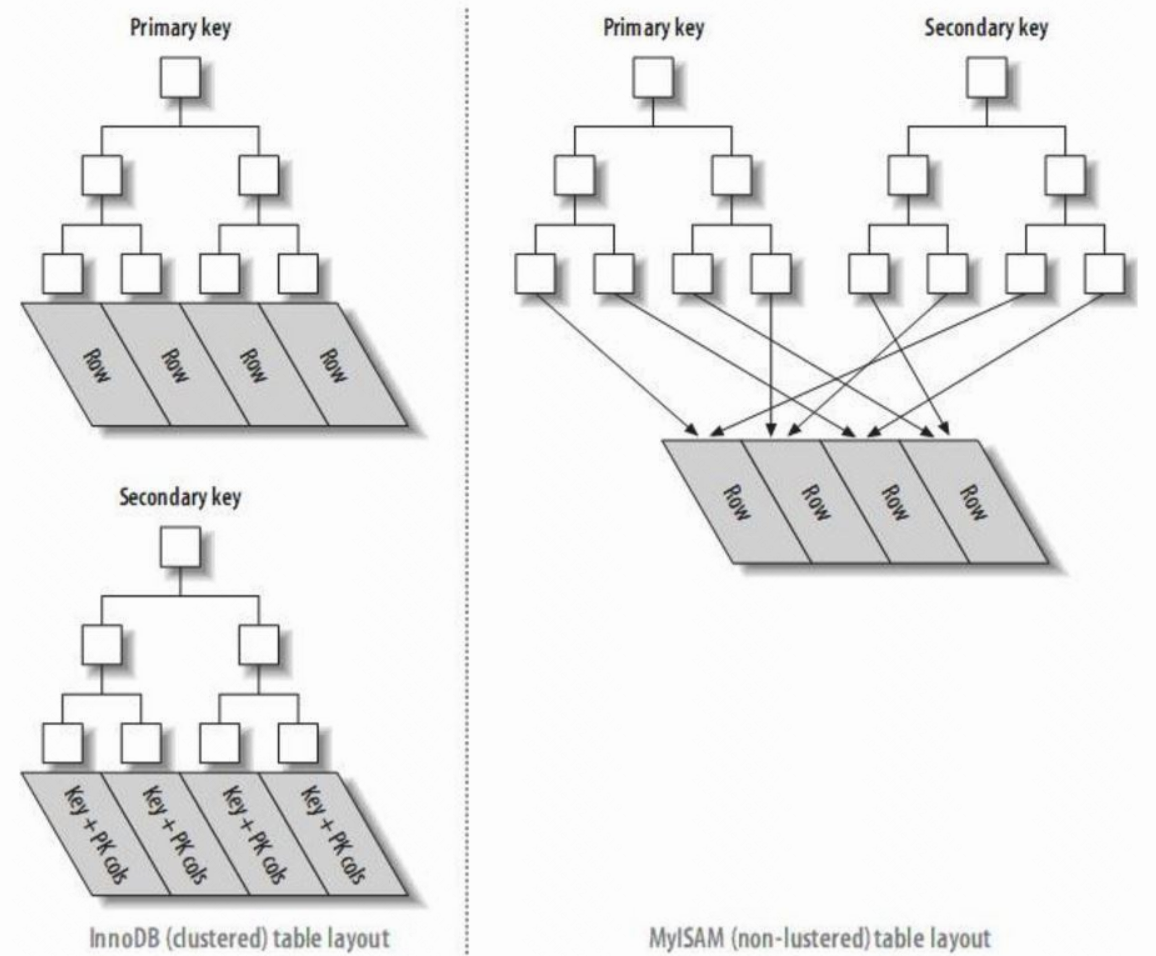
2.聚簇索引和非聚簇索引
3.聚簇索引优劣
优势: 根据主键查询条目比较少时,不用回行(数据就在主键节点下)
劣势: 如果碰到不规则数据插入时,造成频繁的页分裂。
1.回表
回表的概念涉及到主键索引和非主键索引的查询区别
select * from T where ID=500,即主键查询,则只需要搜索 ID 这棵树。select * from T where k=5,即非主键索引查询,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。而从存储空间的角度讲,因为非主键索引树的叶结点存放的是主键的值,那么,应该考虑让主键的字段尽量短,这样非主键索引的叶子结点就越小,非主键索引占用的空间也就越小。一般情况下,建议创建一个自增主键,这样非主键索引占用的空间最小。
2.索引覆盖
3.联合索引
联合索引是指对表上的多个列进行索引。
场景一:
联合索引 (a, b) 是根据 a, b 进行排序(先根据 a 排序,如果 a 相同则根据 b 排序)。因此,下列语句可以直接使用联合索引得到结果(事实上,也就是用到了最左前缀原则)
select … from xxx where a=xxx;select … from xxx where a=xxx order by b;而下列语句则不能使用联合查询:
select … from xxx where b=xxx;场景二:
对于联合索引 (a, b, c),下列语句同样可以直接通过联合索引得到结果:
select … from xxx where a=xxx order by b;select … from xxx where a=xxx and b=xxx order by c;而下列语句则不行,需要执行一次 filesort 排序操作。
select … from xxx where a=xxx order by c;总结:
以联合索引(a,b,c)为例,建立这样的索引相当于建立了索引a、ab、abc三个索引。一个索引顶三个索引当然是好事,毕竟每多一个索引,都会增加写操作的开销和磁盘空间的开销。
4.最左匹配原则
5.索引下推
MySQL 5.6 引入了索引下推优化,可以在索引遍历过程中,对索引中包含的字段先做判断,过滤掉不符合条件的记录,减少回表字数。
CREATE TABLE `test` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`age` int(11) NOT NULL DEFAULT '0',
`name` varchar(255) CHARACTER SET utf8 NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_name_age` (`name`,`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
SELECT * from user where name like '陈%' 最左匹配原则,命中idx_name_age索引
SELECT * from user where name like '陈%' and age=20
age=20这个条件的),匹配2条记录,然后找到对应的2个id。回表之后,在根据age=20进行过滤age=20条件,在回表之前就会根据age进行过滤。此即索引下推,可以减少回表的数据量,增加查询性能6.前缀索引
当索引是很长的字符序列时,这个索引将会很占内存,而且会很慢,这时候就会用到前缀索引了。通常可以索引开始的几个字符,而不是全部值,以节约空间并得到好的性能。所谓的前缀索引就是使用索引的前面几个字母作为索引,但是要降低索引的重复率,索引我们还必须要判断前缀索引的重复率。
select 1.0*count(distinct name)/count(*) from test select 1.0*count(distinct left(name,1))/count(*) from test 取name字符串第一个作为前缀索引的占比select 1.0*count(distinct left(name,2))/count(*) from test 取name字符串前两个作为前缀索引的占比left(str, n)的n不在显著增加时,此时可以选取n作为前缀索引的截取数alter table test add key(name(n));当我们添加索引之后,如何去查看索引呢?又或者执行语句的时候执行的特别慢,我们如何去排查呢?
explain 通常用于查看索引是否生效。
当我们获得慢查询的日志之后,查看日志,观察那些语句执行是慢查询,在该语句之前加上 explain 再次执行,explain 会在查询上设置一个标志,当执行查询时,这个标志会使其返回关于在执行计划中每一步的信息,而不是执行该语句。它会返回一行或多行信息,显示出执行该计划中的每一部分和执行次序.
explain 执行语句返回的重要字段:
explain的 type字段:
我还将定期分享:
最新互联网资讯:让你时刻掌握行业动态。
AI前沿新闻:紧跟技术潮流,不断提升自我。
技术分享与职业发展:助你在职业生涯中走得更远、更稳。
程序员生活趣事:让你在忙碌的工作之余找到共鸣与乐趣。
关注回复【1024】惊喜等你来拿!

本文记录了一次排查FullGC导致的TP99过高过程,介绍了一些排查时思路,线索以及工具的使用,希望能够帮助一些新手在排查问题没有很好的思路时,提供一些思路,让小白也能轻松解决FullGC问题
网上找到的Master公式推导过程都太过于复杂了,为此我特地找到一种小白也能看懂的推导过程。看完这篇文章后,你会对递归的时间复杂度深谙于心,打死都不会忘记。