SQL语句中,聚合函数在统计业务数据结果时起到了重要作用,比如计算每个业务地区的业务总数、每个班级的学生平均分以及每个分类的最大值等。然而,今天小编将为大家介绍窗口函数,与聚合函数相比,它们也是一组函数,但在使用方法和适用场景上有所不同。在本章节中,我将重点介绍窗口函数中的RANK和DENSE_RANK函数,以及它们在排名和筛选方面的应用场景。这些窗口函数可以帮助我们更灵活地处理数据并获得所需的结果,需要注意的是,目前主流的数据库对窗口函数的最低需求版本如下:
Mysql (>=8.0)
PostgreSQL(>=8.4)
SQL Server(>2005)
SQLite(>3.25.0)
如果您的数据库版本低于上述要求,将无法使用窗口函数。
为了让大家更好的理解,小编将以学生数据作为查询的条件背景:假设现在某个学校的某个年级的同学完成了一次考试,成绩也已经录入到数据库中:

现在该年级的教务主任想要看一下:
1.这次考试本年级各个科目的前2名的同学。
2.这次考试每个班级中各个科目的前2名。
3.这次考试每个班级中的总分排名前2名。
如果用普通的SQL查询即麻烦也费时间,而使用RANK和DENSE_RANK函数就可以很快的查询出想要的学生数据,下面将为大家介绍如何使用RANK和DENSE_RANK函数实现学生数据的查询。
为了获得各个不同科目各自的前2名,小编需要先使用 Rank() 函数来给每个学生在各自科目的分区打上成绩排名, 执行如下SQL 语句,查询出来的结果如下图。
select sd.*, RANK() over(partition by subject order by score desc) as _rank from score_data sd;

可以看到,执行结果里面已经根据各个科目的成绩得到了排名字段 _rank, 接下来只需要使用过滤掉 _rank 字段大于2的部分即可,查询的结果如下图所示。
select * from (
select sd.*, RANK() over(partition by subject order by score desc) as _rank from score_data sd
) tmp
where tmp._rank <=2

从上图中看到如果存在成绩一样的情况,就会出现像数学科目的查询结果:数学查询出来了三个值(因为有两个人的数学成绩是一样的77分),如果只想保留一条重复的数据,可以使用DENSE_RANK函数,这个函数的计算语法和 RANK 基本一致,唯一不同的点在于, Rank 计算时会得到成绩高于当前行的记录的总行数,也就是上图查询出来的数学科目的三条数据,而DENSE_RANK 则是计算成绩高于当前行的去重记录的总行数,也就是说,如果出现像上图的数学科目中的重复的数据,就会去掉重复的数据。
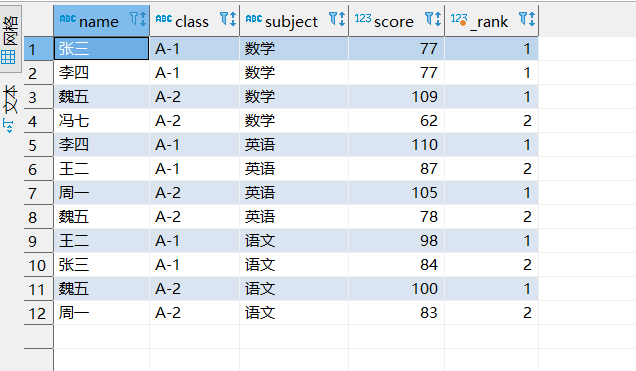
查询每个班级中各个科目的前2名只需要在第一步(查询本年级各个科目前2名的同学)的加上一个 class 班级的分区规则即可,查询的结果如下图所示:
select * from (
select sd.*, RANK() over(partition by subject, class order by score desc) as _rank from score_data sd
) tmp
where tmp._rank <=2
同理,在第二步(查询score_data表中每个班级中各个科目的前2名)的基础上再添加一个成绩的总和SUM(score)函数即可查询每个班级中的总分前两名。
select class,name,SUM(score) AS total_score,
RANK() over (PARTITION by class order by SUM(score) desc)
from score_data sd group by class,name

在这个指标的计算中,需要把聚合函数和排名函数结合起来使用,因为每个人的总成绩被拆分为了多个科目的和,所以需要在班级和科目的联合分组维度上进行聚合,把数据压缩到每人总分的颗粒度。
窗口函数是 SQL 函数中非常强大的工具,尤其是在报表统计等场景领域。它们不仅能够简化复杂的数据计算和分析,还能提高查询效率和灵活性。
扩展链接: