这一章我们聊聊大模型表格理解任务,在大模型时代主要出现在包含表格的RAG任务,以及表格操作数据抽取文本对比等任务中。这一章先聊单一的文本模态,既你已经通过OCR或者多模态等方式从PDF或者图片中获取了表格的文本数据。和前文相同,我们分别介绍微调和基于Prompt的两种方案。
首先我们介绍基于Prompt的方案,核心节约表格问答和推理中的两个问题:表格太大或包含的信息散落各处,问题复杂涉及到多步推理。如何使用prompt让模型在表格任务上更好进行COT,Dater和Chain-of-Table给出了方案,二者有前后关系,Dater在前。
而针对Prompt设计,表格推理还要解决表格数据如何输入prompt,推理效果更好的问题,这里微软的Table Meets LLM也做了实验尝试。
- Large Language Models are Versatile Decomposers: Decompose Evidence and Questions for Table-based Reasoning
Dater的整体流程包含三个步骤:表格分解,问题分解,和合并推理。论文使用了GPT3 Codex作为模型。
第一步是证据拆解,从原始表格数据中,抽取和问题相关的数据,这里Dater使用行号和列号来表示相关的数据。以下使用Few-Shot Prompt来引导模型预测哪些Cell(row, index)和提问相关并返回。之后直接使用行号和列号从原始的表格中抽取出问题相关的数据,构建成更小更聚合的新的表格。
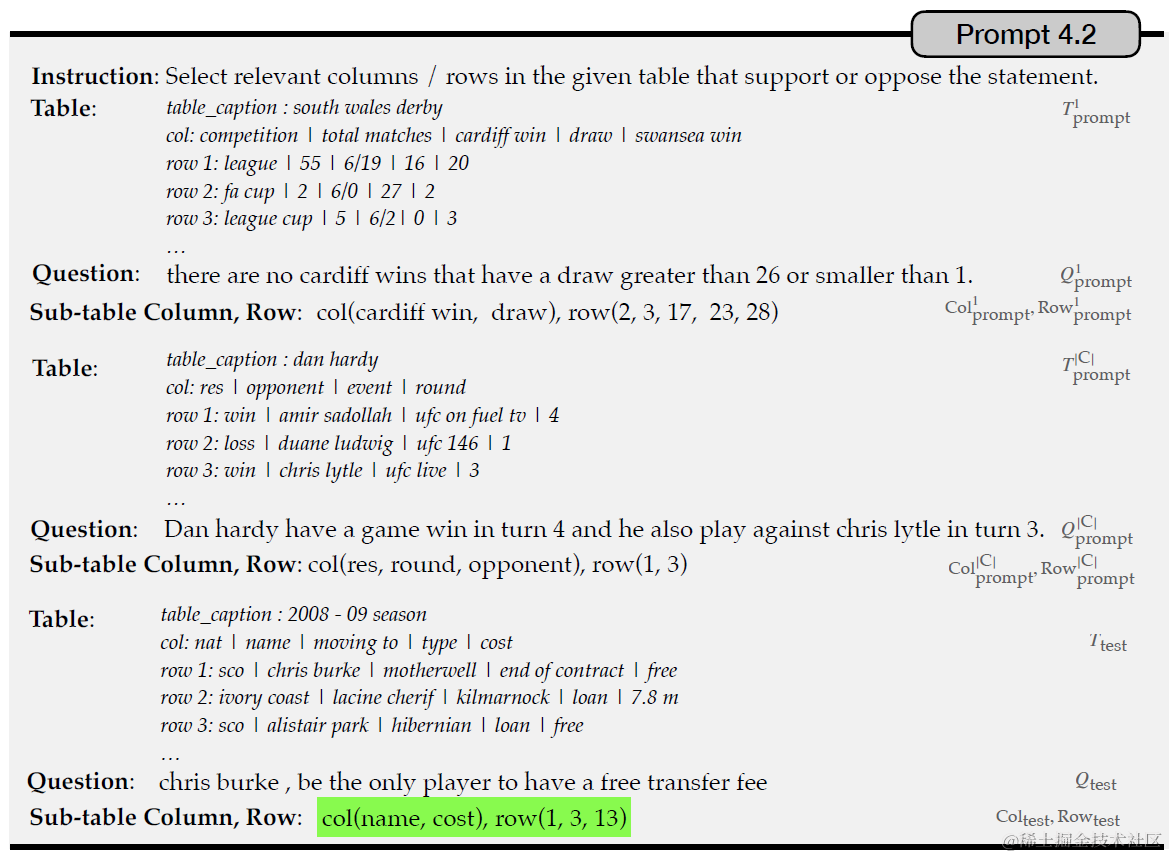
第二步是问题拆解,论文提出如果直接使用COT进行推理,在表格问题上很容易出现幻觉,所以论文提出了"Parsing-execution-filling"的方案,其实和ReACT,Self-ASK,IRCOT的思路是一样的,不过是适配到了表格任务上。
首先基于以下Few-Shot Prompt把原始问题拆解成子问题。这里需要注意的是,子问题不会直接使用表格中的数据进行回答,而是会把涉及数值答案的部分用{}进行掩码。

其次会基于以下few-shot prompt把子问题转化成SQL语句,这在TableQA的任务范式中较为常见,很多经典方案都是把TableQA转化成了NL2SQL的问题进行解决。

这里的表格数据只使用了原始的表格转化成了文本格式,并没有加入更多表格行,列相关Schema的数据,其实相比真实场景做了简化,这部分Schema和NL2SQL任务相似,可以参考解密Prompt系列15. LLM Agent之数据库应用设计
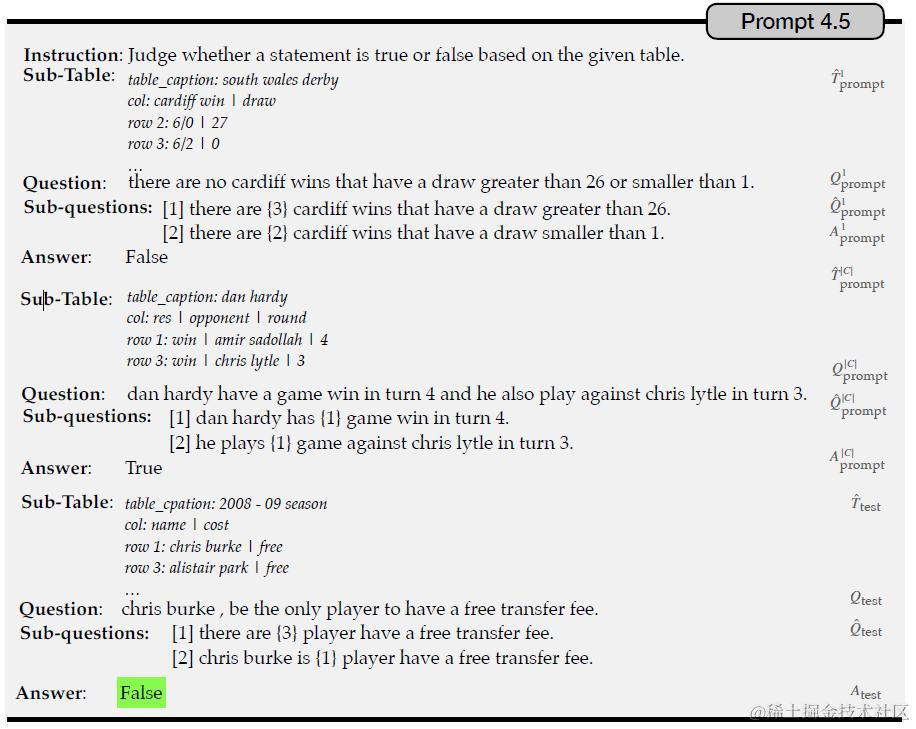
第三步是把前两步得到的sub-evidence和sub-questions(sql)合并在一起,同样是使用few-shot prompt进行推理。以下prompt是TableNLI任务,也就是基于表格数据判断描述是对还是错。效果我们放到后面的论文里一起说。
- Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding
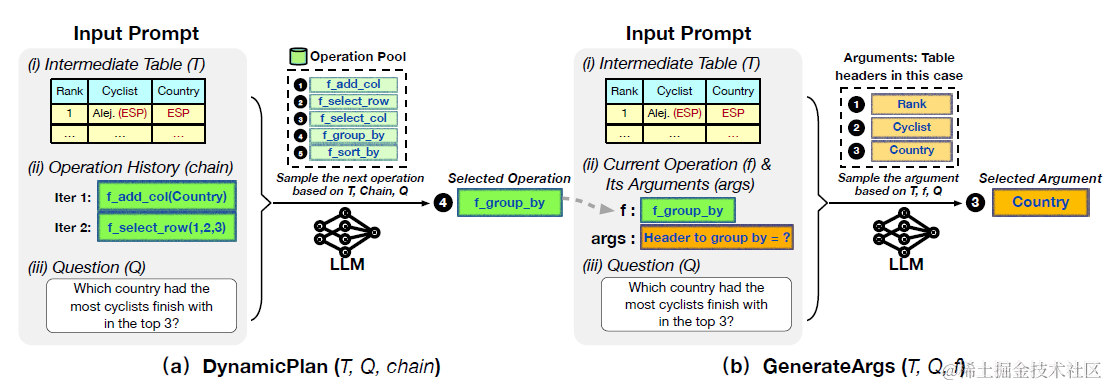
谷歌提出的Chain-of-Table在Dater的基础上加入了更多,更灵活的表格操作。整个任务同样分成三个主要步骤:动态规划,参数推理和最终结果。整个过程中通过大模型多步规划和参数生成,对表格进行变换操作,直到输出最终变换后表格,并推理出最终的结果。
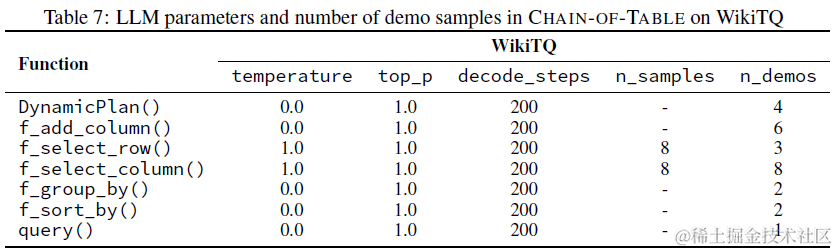
动态规划是模型基于当前表格状态,历史表格操作,和用户提问,推理生成新的表格操作函数。对比Dater只通过选择CELL来缩小表格范围,这里Chain-of-Table利用大模型In-Context Function calling的能力,定义了可以灵活扩展的几个表格操作函数,以下为不同functino的解码参数和few-shot数量,其中f_select_row + f_select_column其实就对应上面Dater的表格操作。
动态规划部分prompt包括:以上每个函数的few-shot sample和函数描述,经过多步操作后当前的表格状态,问题和历史的Function chain。模型推理是下一步的操作function,或者END结束如下
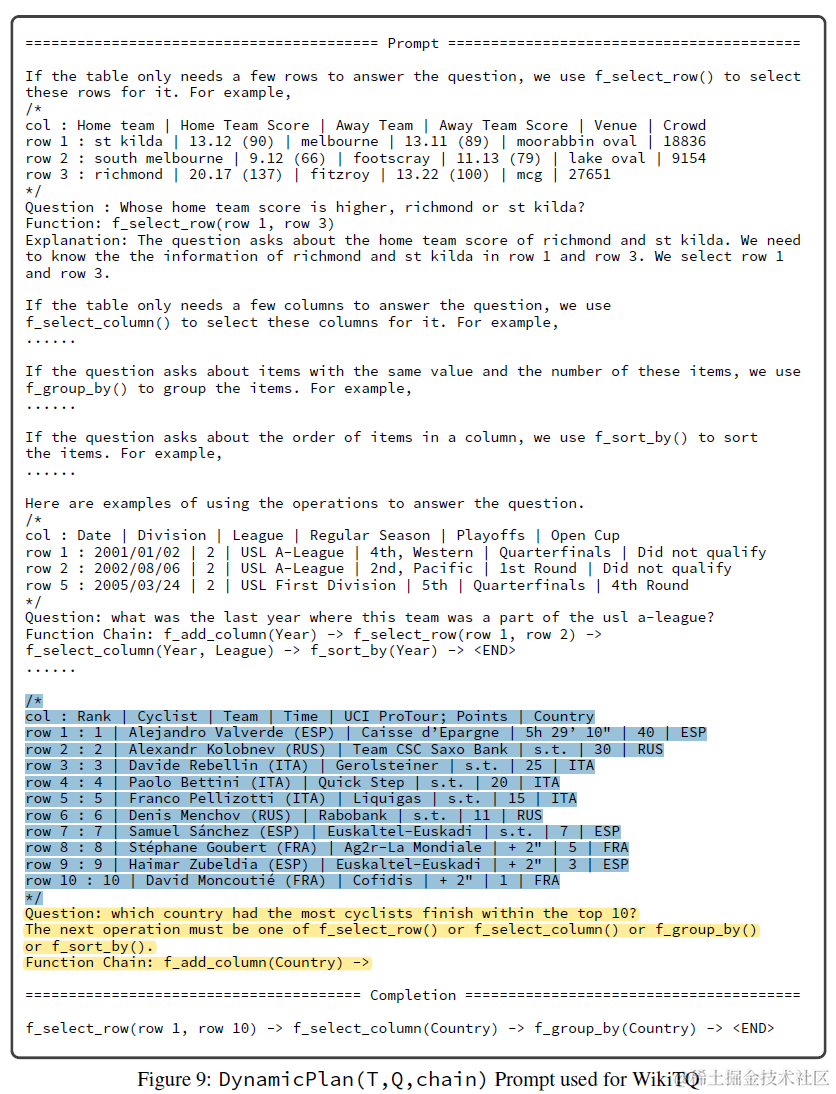
这里论文其实是把Function Call拆成了两步,分别是使用哪个操作,以及操作的入参。所以这一步是基于上面推理的操作函数,推理该函数的入参
参数生成的prompt包括:和规划prompt相同的表格状态,规划生成的操作函数,和每个操作的few-shot sample。这里不同的操作Function的推理格式会有差异,例如f_add_column,除了需要推理增加的列,还需要同时给出列的取值。再例如f_select_columns存在多列选择,因此使用*等正则表达式来支持可变参数列表。以下分别为f_add_column, 和f_select_column的few-shot demos
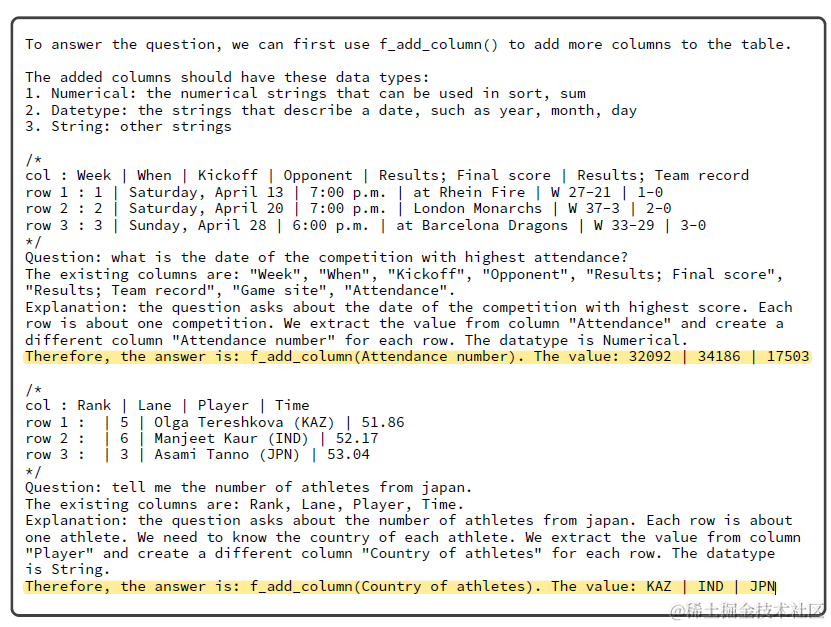
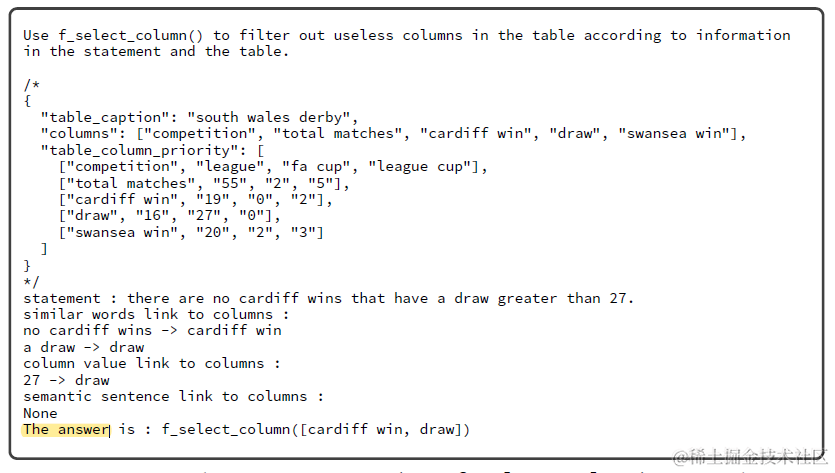
经过一步或者多步上面的动态规划生成函数+参数生成生成入参,会使用该函数对表格进行多步操作,最后得到的表格用于问题回答。回答部分同样是few-shot prompt如下,基于多步操作得到的最终的表格和提问进行回答。
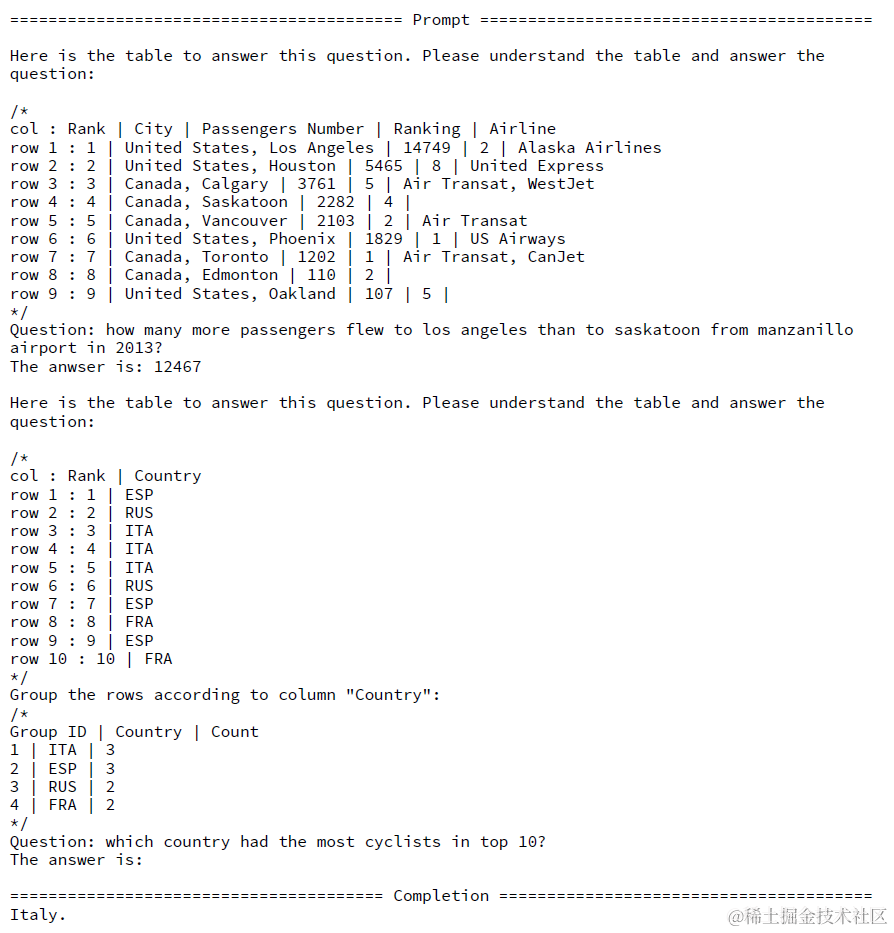
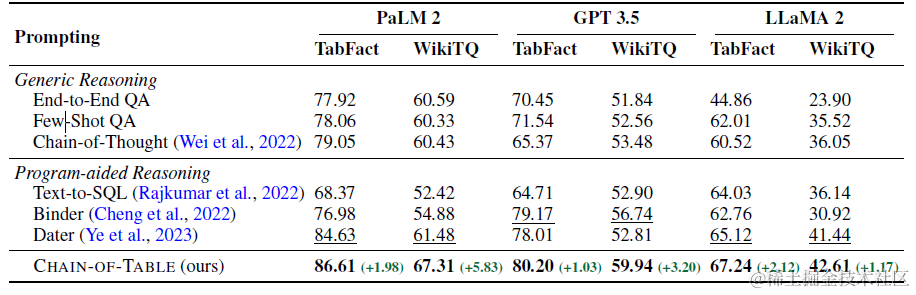
效果上对比Dater,使用不同的基座模型,Chain-of-Table在Wiki TQ和TabFact等表格理解任务上均有一定的提升。并且在不同大小的表格数据上也都有显著的提升。
- Table Meets LLM: Can Large Language Models Understand Structured Table Data? A Benchmark and Empirical Study
微软这篇论文主要实验并回答了两个问题
首先论文把表格理解任务拆分成了多个可以定量评估的子任务,相比直接评估表格问答能力,以下子任务的评估更加简单直接,包括:
基于上述的7个子任务,论文首先对比了不同的表格数据表征形式的效果差异。这里论文实验了包括JSON,3种不同的标记语言markdonw,XML,HTML,以及在众多表格任务中常见的使用“|”分隔符直接分割表的NL+Sep模式。上面的Dater和Chain of Table就是NL+Sep。以下为子任务的对比结果

以上实验数据不难得到两个结论
之前在看新加坡Prompt大赛冠军秘籍时就发现,prompt中不同内容的分割符,和结构化数据例如标签,表格等数据使用XML,HTML等标记语言进行表征,效果是显著更好的,例如使用XML表征分类标签在我们的任务上分类的结果更稳定,模型更不容易在分类前后给你瞎逼逼。再例如用HTML表征表格,模型定位到具体数值的准确率也会更高。
之后论文以HTML作为基准,进一步对其他prompt细节进行了测试,如下
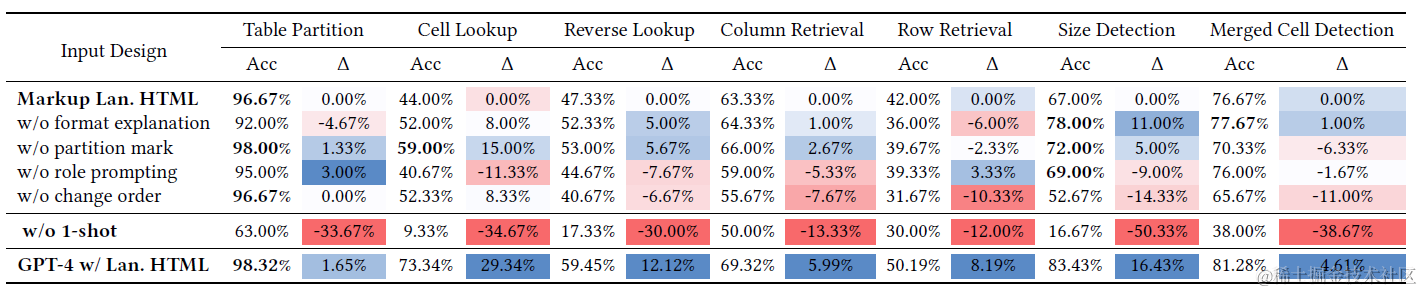
以上消融实验比较明显的结论也有两个
论文还提出了self-augmented prompt,个人感觉略微缺乏针对性一些,感兴趣的朋友自己去看细节吧~
除了以上利用GPT的Prompt方案,我们再介绍两个微调方案:Table Llama和TableLLM
- TableLlama: Towards Open Large Generalist Models for Tables
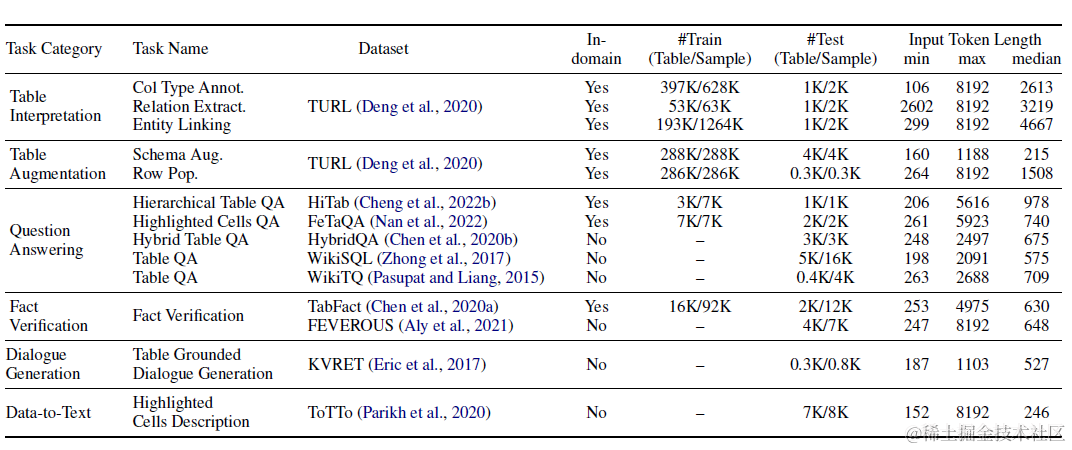
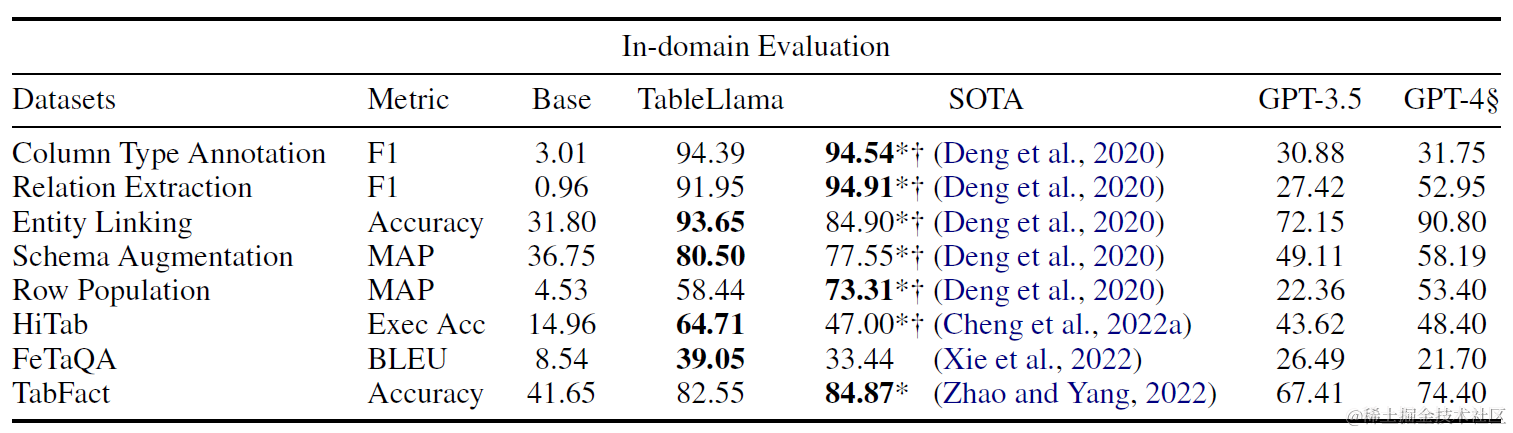
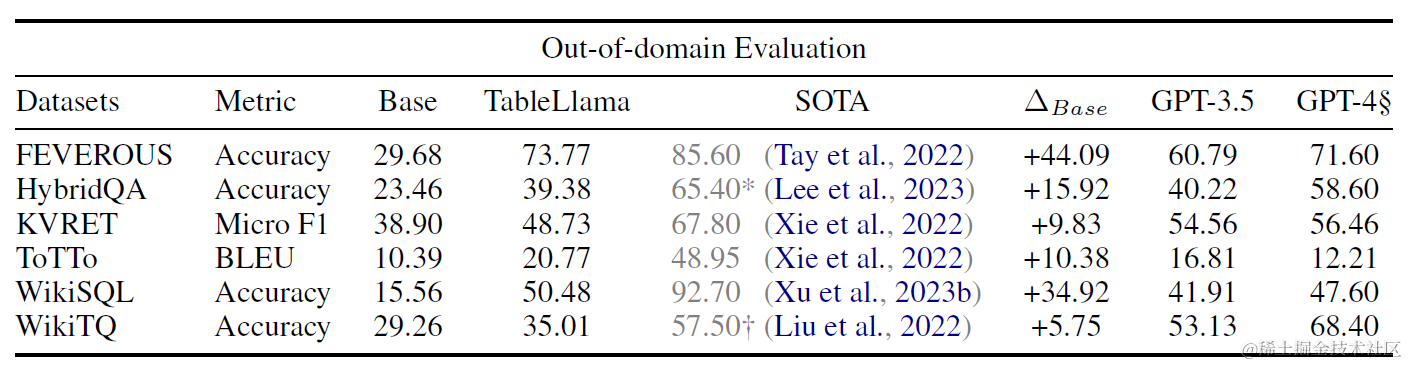
Table Llama是很典型的垂直领域微调方案。论文设计了TableInstruct微调数据集,筛选了总共包括14个表格数据集的总共11类任务。其中训练集选择8个数据集和8类任务,测试集为6个数据集和4类任务,来检测模型在样本外任务类型上的泛化效果。数据集和任务分布如下
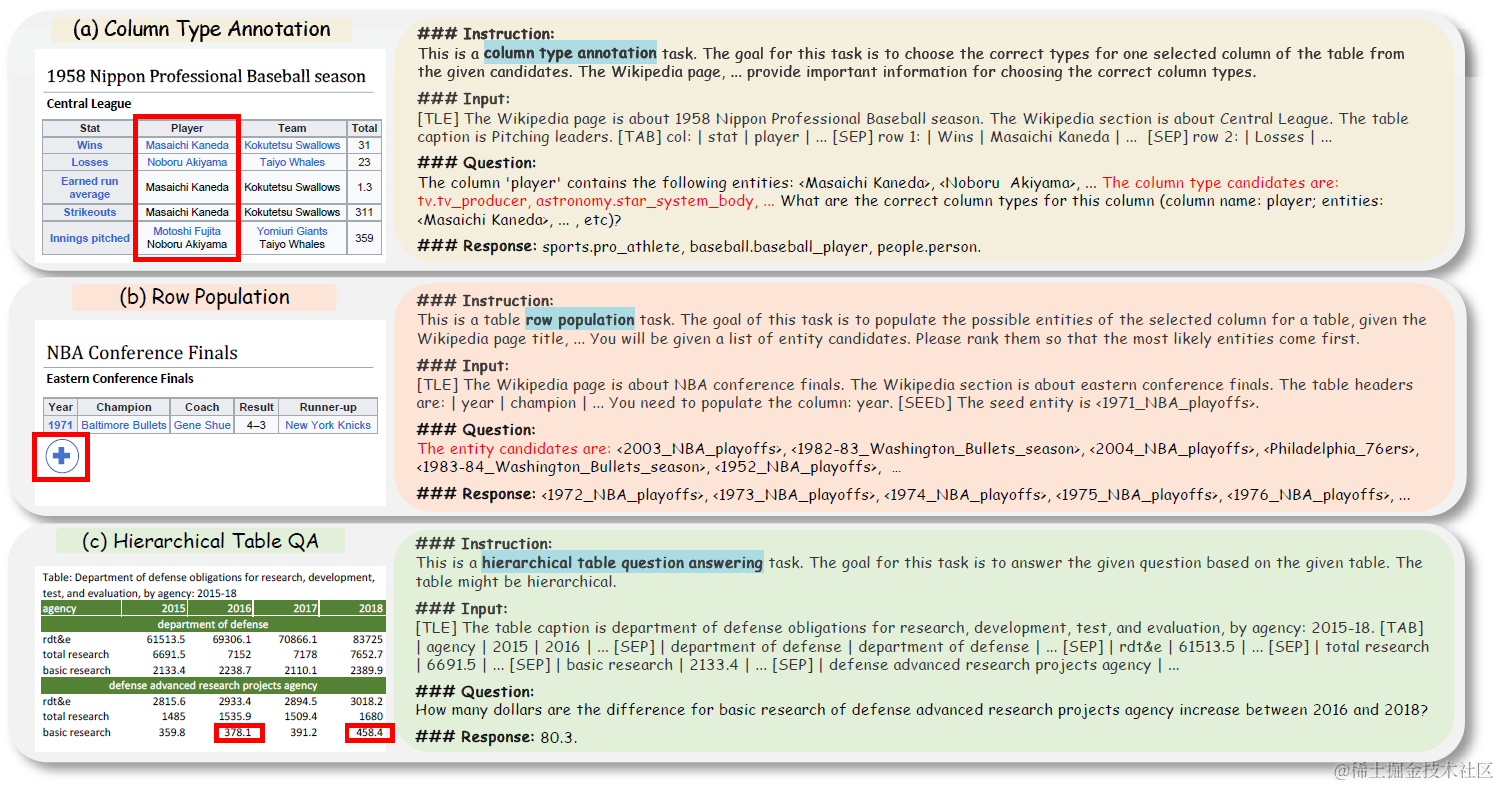
微调数据的构成就是Instruction+Input+Quesiton为输入,Response为输出。这里论文使用了NL+SEP来表征表格数据,并加入了表格任务的描述。考虑表格数据的长度往往超过4K,这里选用LongLora微调后的7B模型为基座,
效果上分别看下样本内和样本外任务上的效果提升,这里Base使用了LongLora微调后的7B,以及对比了GPT3.5和GPT4(采样了部分样本)。在样本内任务上TableLlama能超越GPT4,在样本外任务上TableLlama相比Base有显著提升,但部分任务效果不及GPT4
- TableLLM: Enabling Tabular Data Manipulation by LLMs in Real Office Usage Scenarios
- https://github.com/RUCKBReasoning/TableLLM
TableLLM论文做了以下的用户调研,更充分地了解了用户对于表格任务究竟有哪些真实需求。除了前面Table Llama涵盖的TableQA,Table Extraction,Dialogue,Fact Verfication等传统Table2Text任务之外,还包含了更多操作类任务,例如表格匹配,表格绘图。
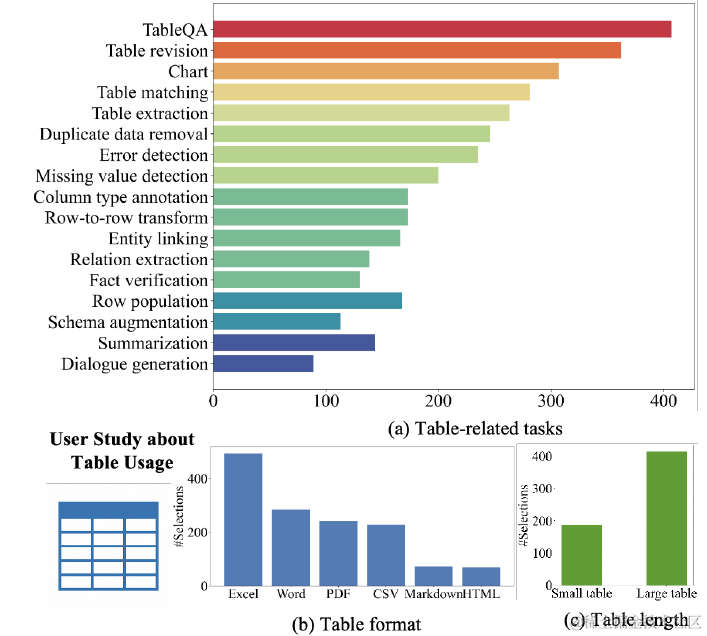
整体上论文把表格数据涉及到的操作类型分成了Query,Update,Merge和Chart四大类,这四种操作在不同类型的表格数据上侧重不同,在纯表格数据上四种操作类型都会有,更接近现在众多ChatBI在做的方向,更多是code-driven。而在文本中内嵌的表格数据上query查询是主要操作,更多用于像RAG的场景,依赖纯文本的理解推理。
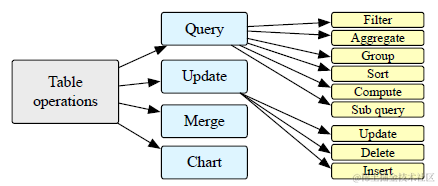
基于上面的两大类表格数据和四种操作类型,TableLLM说自己使用了远程监督构建了微调数据集,其实就是传统的Table,SQL数据集上用大模型构建了新的推理和回答作为样本。数据集构成包含三个主要部分
之后基于上面构建的样本,针对不同的数据和操作,论文使用了不同的prompt来构建指令微调样本,在CodeLlama-7B和13B模型上进行了微调。整个数据构建和微调prompt如下
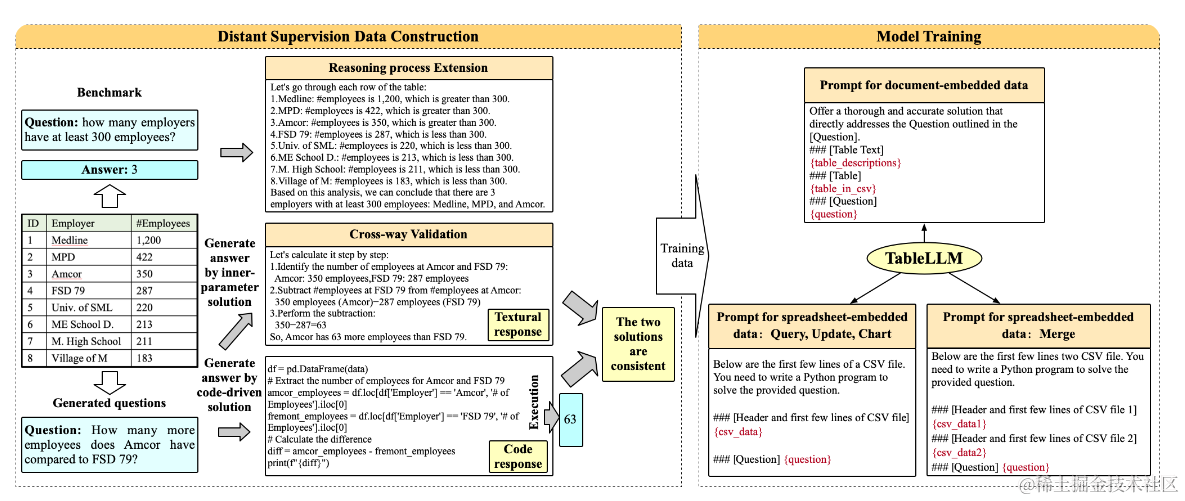
这里主要是看下上面表格数据构建的流程,效果对比就不说了因为部分数据集这里加入了训练集,而上面的Table Llama则放到了OOB测试集,不能直接对比。
想看更全的大模型相关论文梳理·微调及预训练数据和框架·AIGC应用,移步Github >> DecryPrompt
这一章我们聊聊大模型表格理解任务,在大模型时代主要出现在包含表格的RAG任务,以及表格操作数据抽取文本对比等任务中。这一章先聊单一的文本模态,我们分别介绍微调和基于Prompt的两种方案。
前几章我们讨论了RLHF的样本构建优化和训练策略优化,这一章我们讨论两种不同的RL训练方案,分别是基于过程训练,和使用弱Teacher来监督强Student 循序渐进:PRM & ORM 想要获得过程
这一章我们聚焦多模态图表数据。先讨论下单纯使用prompt的情况下,图片和文字模态哪种表格模型理解的效果更好更好,再说下和表格相关的图表理解任务的微调方案
模型想要完成自主能力进化和自主能力获得,需要通过Self-Reflection from Past Experience来实现。那如何获得经历,把经历转化成经验,并在推理中使用呢?本章介绍三种方案
这一章介绍自主浏览操作网页的WebAgent和数据集:初级MiniWoB++,高级MIND2WEB,可交互WEBARENA,多模态WebVoyager,多轮对话WebLINX,复杂AutoWebGLM
这一章介绍通过扩写,改写,以及回译等半监督样本挖掘方案对种子样本进行扩充,提高种子指令样本的多样性和复杂度,这里我们分别介绍Microsoft,Meta和IBM提出的三个方案。
总结下指令微调、对齐样本筛选相关的方案包括LIMA,LTD等。论文都是以优化指令样本为核心,提出对齐阶段的数据质量优于数量,少量+多样+高质量的对齐数据,就能让你快速拥有效果杠杠的模型