Linux内核中是如何分配出页面的,如果我们站在CPU的角度去看这个问题,CPU能分配出来的页面是以物理页面为单位的。也就是我们计算机中常讲的分页机制。本文就看下Linux内核是如何管理,释放和分配这些物理页面的。
大家都知道,Linux内核的页面分配器的基本算法是基于伙伴系统的,伙伴系统通俗的讲就是以2^order 分配内存的。这些内存块我们就称为伙伴。
两个块大小相同
两个块地址连续
两个块必须是同一个大块分离出来的
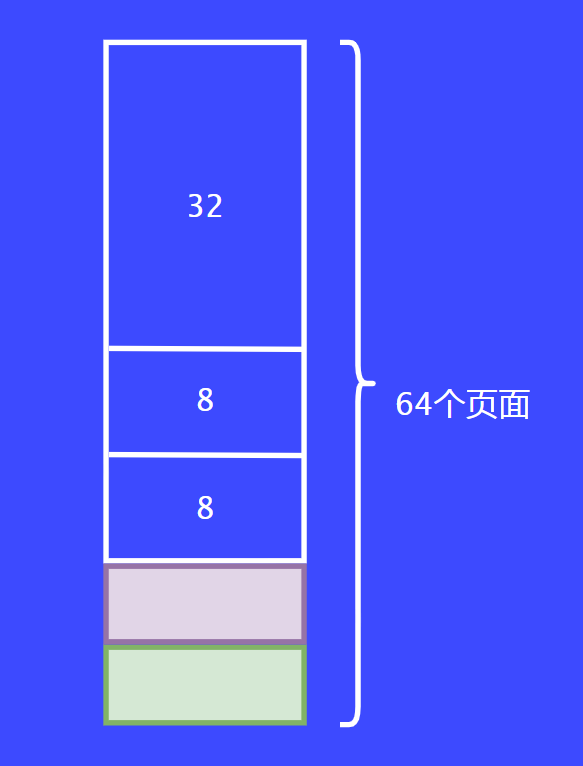
下面我们举个例子理解伙伴分配算法。假设我们要管理一大块连续的内存,有64个页面,假设现在来了一个请求,要分配8个页面。总不能把64个页面全部给他使用吧。

首先把64个页面一切为二,每部分32个页面。
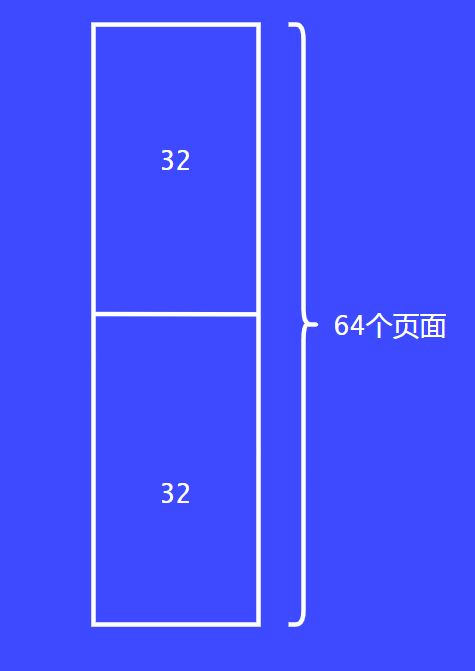
把32个页面给请求者还是很大,这个时候会继续拆分为16个。
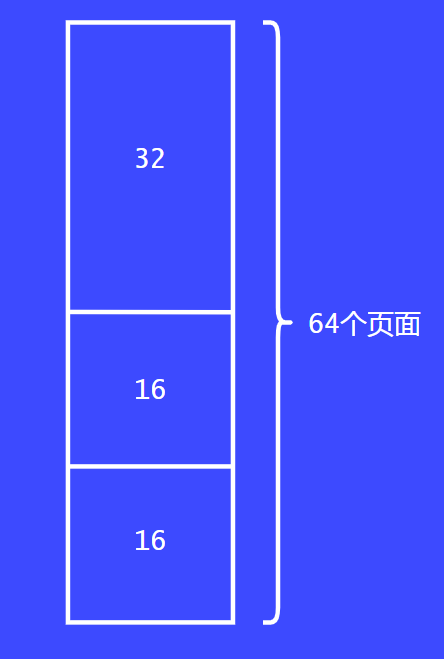
最后会将16个页面继续拆分为8个,将其返回给请求者,这就完成了第一个请求。
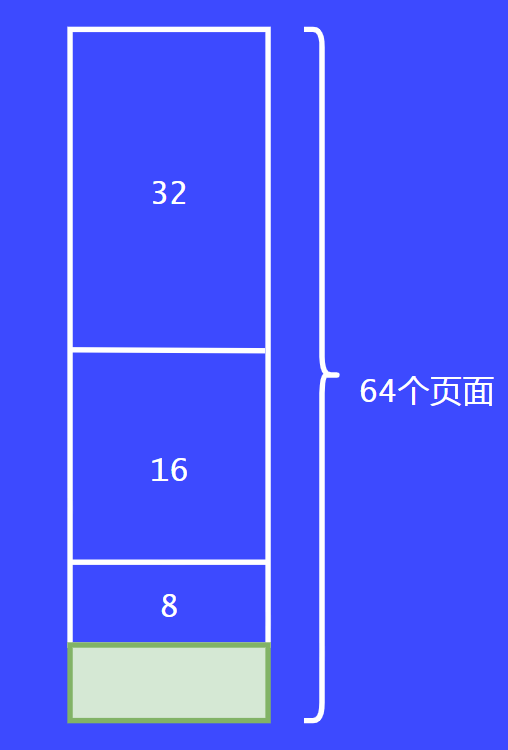
这个时候,第二个请求者也来了,同样的请求8个页面,这个时候系统就会把另外8个页面返回给请求者。
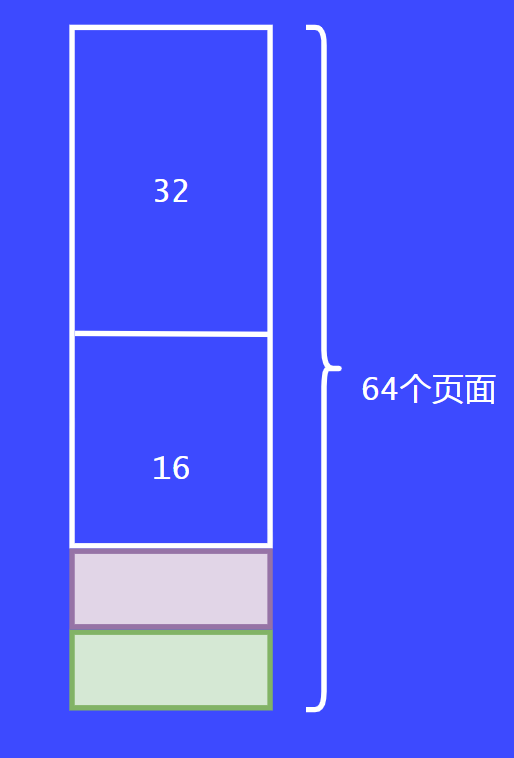
假设现在有第三个请求者过来了,它请求4个页面。这个时候之前的8个页面都被分配走了,这个时候就要从16个页面的内存块切割了,切割后变为每份8个页面。最后将8个页面的内存块一分为二后返回给调用者。
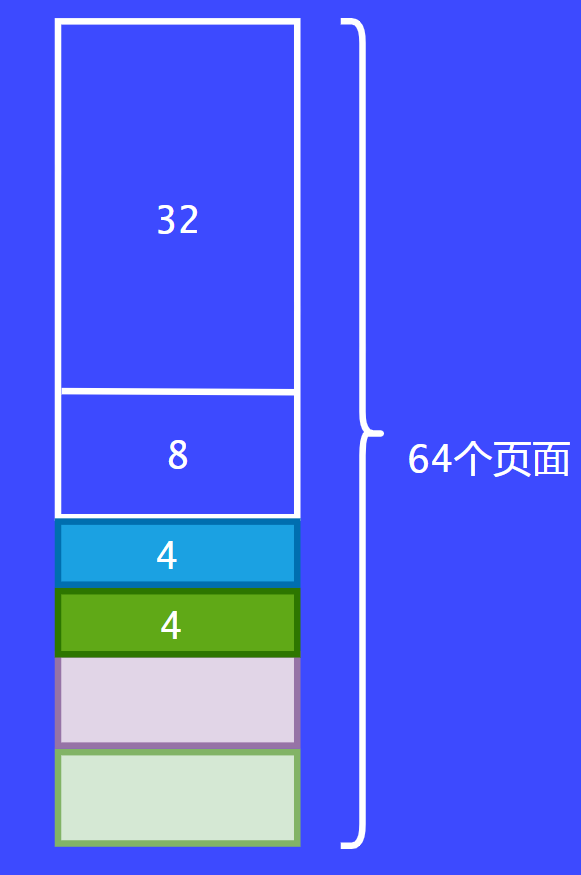
假设前面分配的8个页面都已经用完了,这个时候可以把两个8个页面合并为16个页面。
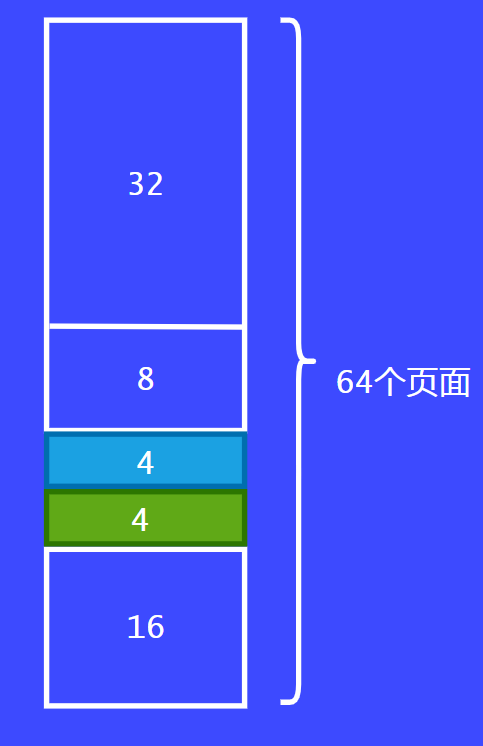
以上例子就是伙伴系统的简单的例子,大家可以通过这个例子通俗易懂的理解伙伴系统。
另外一个例子将要去说明三个条件中的第三个条件:两个块必须要是从同一个大块中分离出来的,这两个块才能称之为伙伴,才能去合并为一个大块。
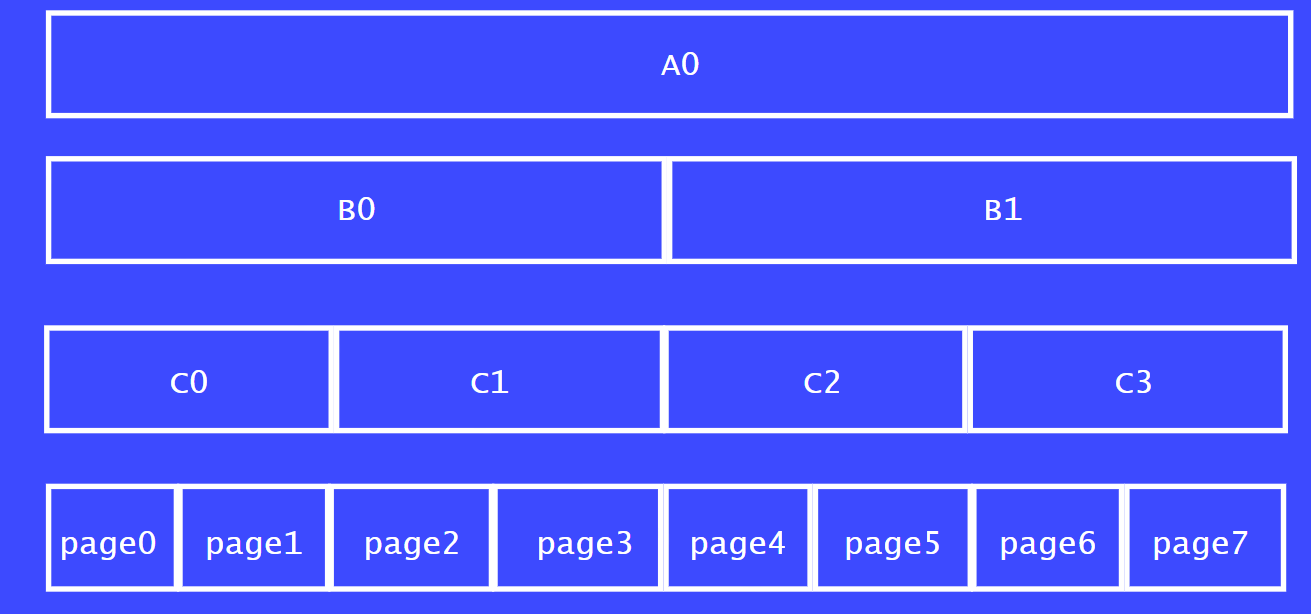
我们以8个页面的一个大块为例子来说明,如图A0所示。将A0一分为二分,分别为 B0,B1。
B0:4页
B1:4页
再将B0,B1继续切分:
C0:2页
C1:2页
C2:2页
C3:2页
最后可以将C0,C1,C2,C3切分为1个页面大小的内存块。
我们从C列来看,C0,C1称之为伙伴关系,C2,C3为伙伴关系。
同理,page0 和 page1也为伙伴关系,因为他们都是从C0分割出来的。
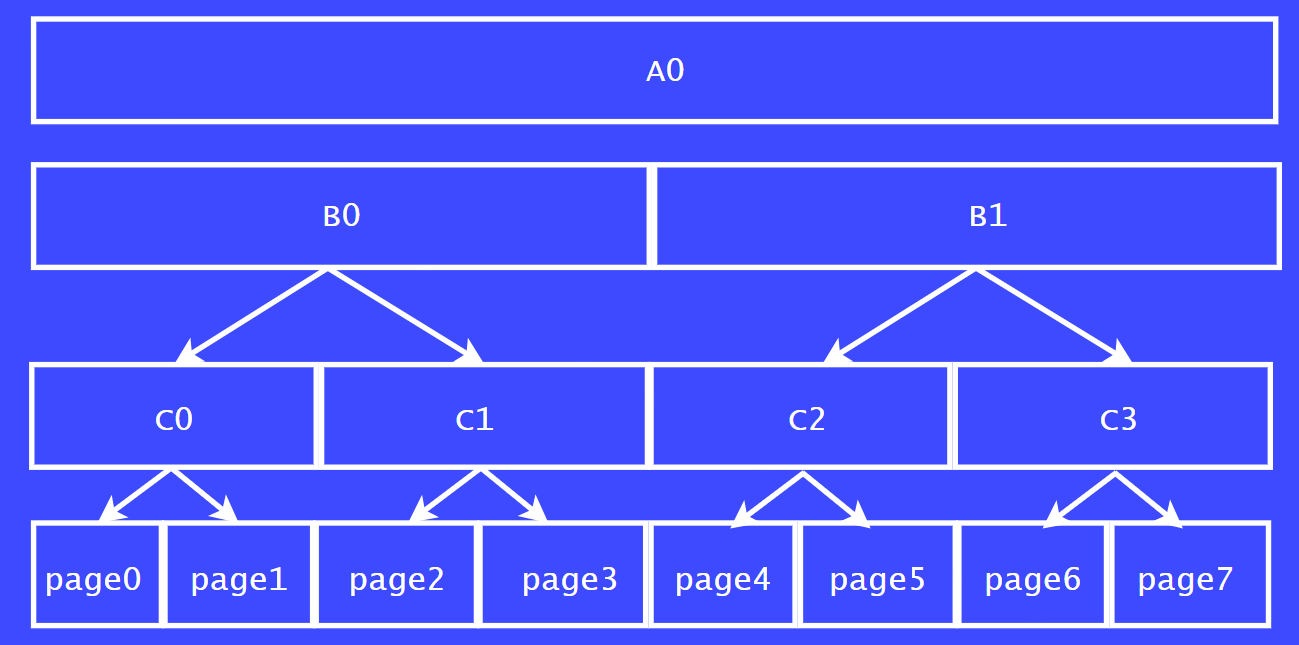
假设,page0正在使用,page1 和 page2都是空闲的。那page1 和 page 2 可以合并成一个大的内存块吗?
我们从上下级的关系来看,page 1,page 2 并不属于一个大内存块切割而来的,不属于伙伴关系。
如果我们把page 1 page 2,page4 page 5 合并了,看下结果会是什么样子。
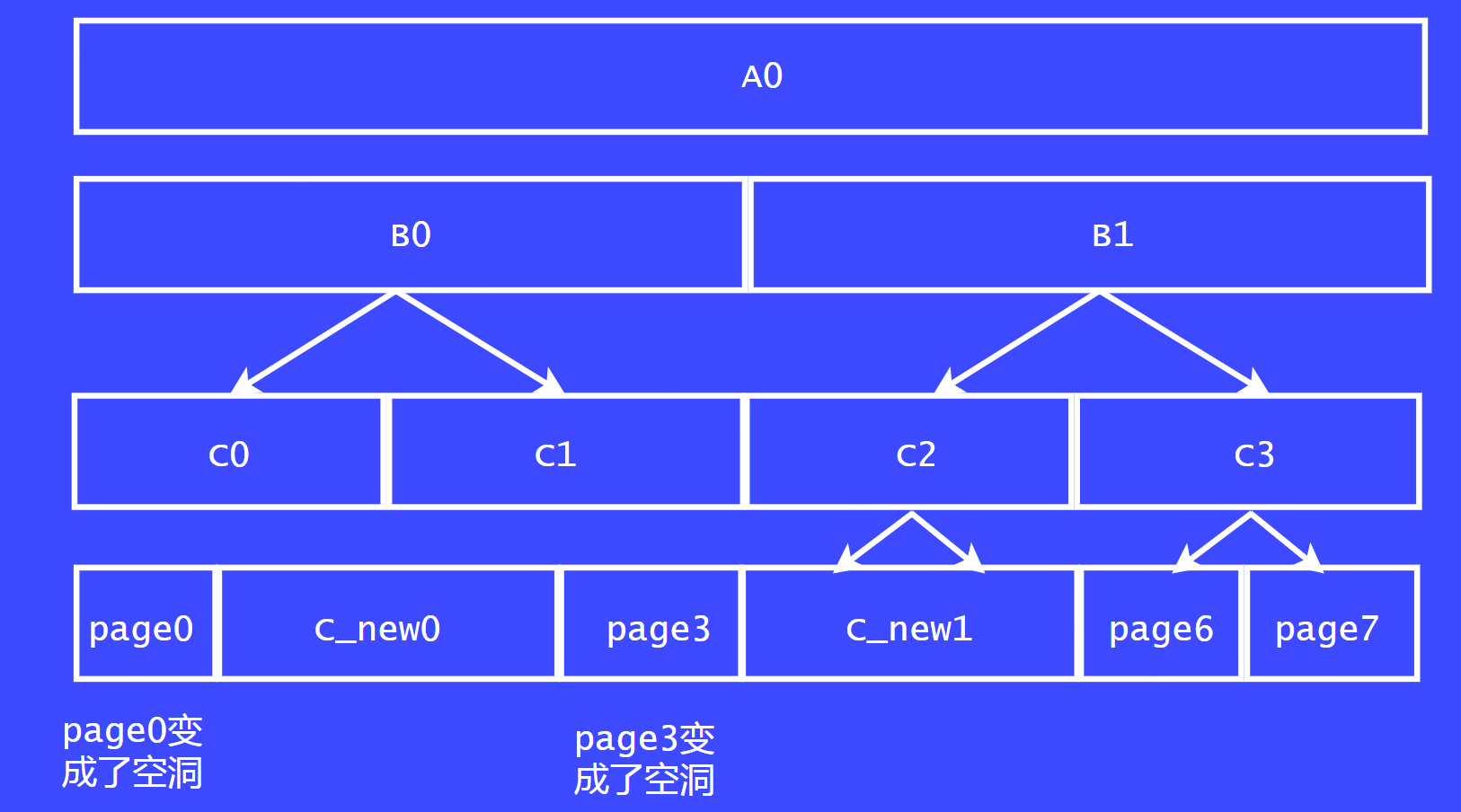
page0和page3 就会变成大内存块中孤零零的空洞了。page 0 和 page3 就无法再和其他块合并了。这样就形成了外碎片化。因此,内核的伙伴系统是极力避免这种清空发生的。
下面我们看下内核中是怎么实现伙伴系统的。
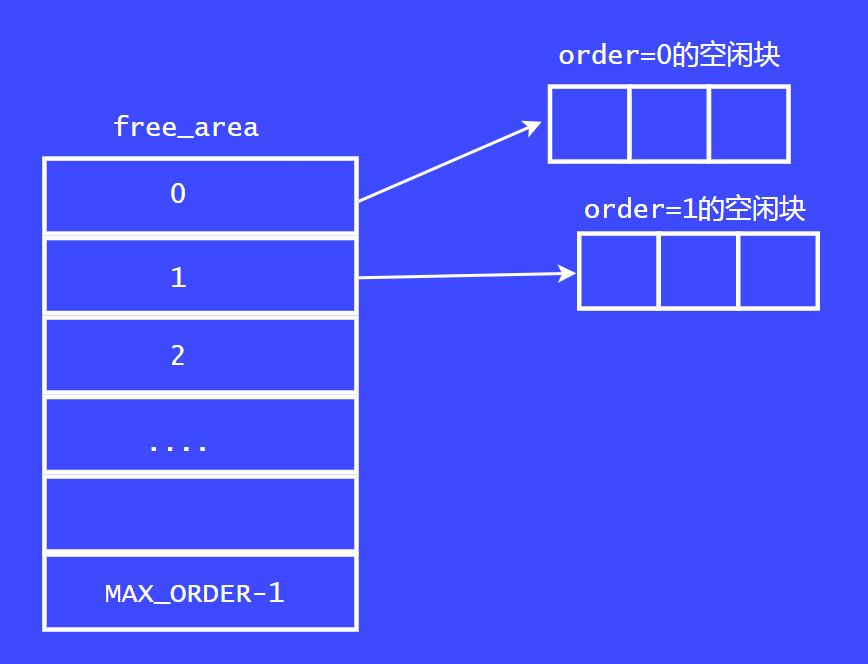
上面这张图是内核中早期伙伴系统的实现
内核中把内存以2^order 为单位分为多个链表。order范围为[0,MAX_ORDER-1],MAX_ORDER一般为11。因此,Linux内核中可以分配的最大的内存块为2^10= 4M,术语叫做page block。
内核中有一个叫free_area的数据结构,这个数据结构为链表的数组。数组的大小为MAX_ORDER。数组的每个成员为一个链表。分别表示对应order的空闲链表。以上就是早期的伙伴系统的页面分配器的实现。
现在的伙伴系统中的页面分配器的实现,为了解决内存碎片化的问题,在Linux内核2.6.4中引入了迁移类型的 算法缓解内存碎片化的问题。
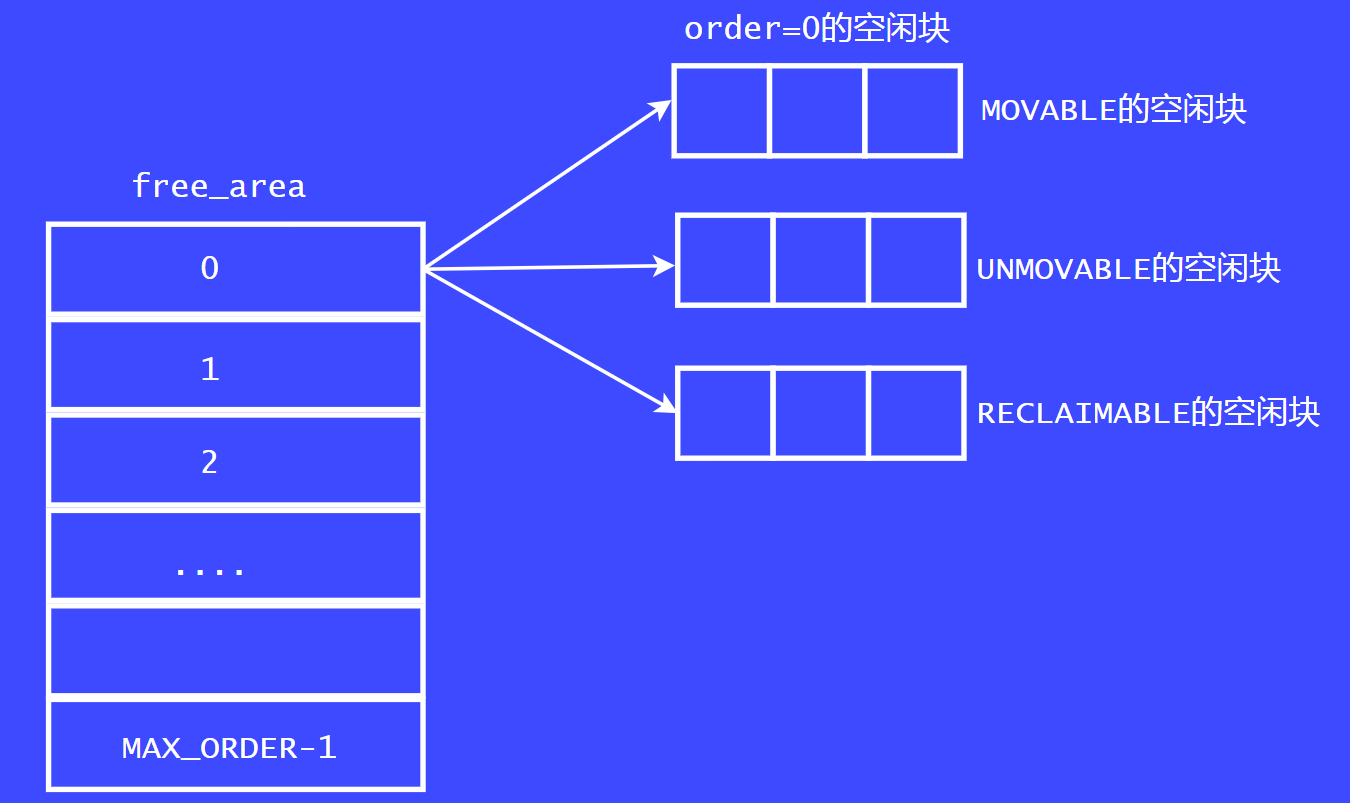
我们看这张图,现在的页面分配器中,每个free_area数组成员中都增加了一个迁移类型。也就是说在每个order链表中多增加了一个链表。例如,order = 0 的链表中,新增了MOVABLE 链表,UNMOVABLE 链表,RECLAIMABLE链表。随着内核的发展,迁移类型越来越多,但常用的就那三个。
在Linux内核2.6.4内核中引入了反碎片化的概念,反碎片化就是根据迁移类型来实现的。我们知道迁移类型 是根据page block来划分的。我们看下常用的迁移类型。
MIGRATE_UNMOVABLE:在内存中有固定位置,不能随意移动,比如内核分配的内存。那为什么内核分配的不能迁移呢?因此要迁移页面,首先要把物理页面的映射关系断开,在新的地方分配物理页面,重新建立映射关系。在断开映射关系的途中,如果内核继续访问这个页面,会导致oop错误或者系统crash。因为内核是敏感区,内核必须保证它使用的内存是安全的。这一点和用户进程不一样。如果是用户进程使用的内存,我们将其断开后,用户进程再去访问,就会产生缺页中断,重新去寻找可用物理内存然后建立映射关系。
MIGRATE_MOVABLE:可以随意移动,用户态app分配的内存,mlock,mmap分配的 匿名页面。
MIGRATE_RECLAIMABLE:不能移动可以删除回收,比如文件映射。
伙伴系统的迁移算法可以解决一些碎片化的问题,但在内存管理的方面,长期存在一个问题。从系统启动,长期运行之后,经过大量的分配-释放过程,还是会产生很多碎片,下面我们看下,这些碎片是怎么产生的。
我们以8个page的内存块为例,假设page3是被内核使用的,比如alloc_page(GFP_KERNRL),所以它属于不可移动的页面,它就像一个桩一样,插入在一大块内存的中间。
尽管其他的页面都是空闲页面,导致page0 ~ page 7 不能合并为一个大块的内存。

下面我们看下,迁移类型是怎么解决这类问题的。我们知道,迁移算法是以page block为单位工作的,一个page block大小就是页面分配器能分配的最大内存块。也就是说,一个page block 中的页面都是属于一个迁移类型的。所以,就不会存在上面说的多个page中夹着一个不可迁移的类型的情况。
alloc_pages是内核中常用的分配物理内存页面的函数, 用于分配2^order个连续的物理页。
static inline struct page *alloc_pages(gfp_t gfp_mask, unsigned int order)
复制get free page, 因此gfp_mask表示页面分配的方法。gfp_mask的具体分类后面我们会详细介绍。MAX_ORDER为11, 即最多一次性分配2 ^(MAX_ORDER-1)个页。struct page指针__get_free_page() 是页面分配器提供给调用者的最底层的内存分配函数。它分配连续的物理内存。__get_free_page() 函数本身是基于 buddy 实现的。在使用 buddy 实现的物理内存管理中最小分配粒度是以页为单位的。
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
复制#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
复制alloc_page 是宏定义,逻辑是调用 alloc_pages,传递给 order 参数的值为 0,表示需要分配的物理页个数为 2 的 0 次方,即 1 个物理页,需要用户传递参数 GFP flags。
void free_pages(unsigned long addr, unsigned int order)
复制释放2^order大小的页块,传入参数是页框首地址的虚拟地址
#define __free_page(page) __free_pages((page), 0)
复制释放一个页,传入参数是指向该页对应的虚拟地址
#define free_page(addr) free_pages((addr), 0)
复制释放一个页,传入参数是页框首地址的虚拟地址
| 标志 | 描述 |
|---|---|
| GFP_WAIT | 分配器可以睡眠 |
| GFP_HIGH | 分配器可以访问紧急的内存池 |
| GFP_IO | 不能直接移动,但可以删除 |
| GFP_FS | 分配器可以启动文件系统IO |
| GFP_REPEAT | 在分配失败的时候重复尝试 |
| GFP_NOFAIL | 分配失败的时候重复进行分配,直到分配成功位置 |
| GFP_NORETRY | 分配失败时不允许再尝试 |
| 标志 | 描述 |
|---|---|
| GFP_DMA | 从ZONE_DMA中分配内存(只存在与X86) |
| GFP_HIGHMEM | 可以从ZONE_HIGHMEM或者ZONE_NOMAL中分配 |
| 标志 | 描述 |
|---|---|
| GFP_ATOMIC | 分配过程中不允许睡眠,通常用作中断处理程序、下半部、持有自旋锁等不能睡眠的地方 |
| GFP_KERNEL | 常规的内存分配方式,可以睡眠 |
| GFP_USER | 常用于用户进程分配内存 |
| GFP_HIGHUSER | 需要从ZONE_HIGHMEM开始进行分配,也是常用于用户进程分配内存 |
| GFP_NOIO | 分配可以阻塞,但不会启动磁盘IO |
| GFP_NOFS | 可以阻塞,可以启动磁盘,但不会启动文件系统操作 |
GFP_MASK除了表示分配行为之外,还可以表示从那些ZONE来分配内存。还可以确定从那些迁移类型的page block 分配内存。
我们以ARM为例,由于ARM架构没有ZONE_DMA的内存,因此只能从ZONE_HIGHMEM或者ZONE_NOMAL中分配.
在内核中有两个数据结构来表示从那些地方开始分配内存。
struct zonelist {
struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];
};struct zonelist
复制zonelist是一个zone的链表。一次分配的请求是在zonelist上执行的。开始在链表的第一个zone上分配,如果失败,则根据优先级降序访问其他zone。
zlcache_ptr 指向zonelist的缓存。为了加速对zonelist的读取操作 ,用_zonerefs 保存zonelist中每个zone的index。
struct zoneref {
struct zone *zone; /* Pointer to actual zone */
int zone_idx; /* zone_idx(zoneref->zone) */
};
复制页面分配器是基于ZONE来设计的,因此页面的分配有必要确定那些zone可以用于本次页面分配。系统会优先使用ZONE_HIGHMEM,然后才是ZONE_NORMAL 。
基于zone 的设计思想,在分配物理页面的时候理应以zone_hignmem优先,因为hign_mem 在zone_ref中排在zone_normal的前面。而且,ZONE_NORMAL是线性映射的,线性映射的内存会优先给内核态使用。
页面分配的时候从那个迁移类型中分配出内存呢?
函数static inline int gfp_migratetype(const gfp_t gfp_flags)可以根据掩码类型转换出迁移类型,从那个迁移类型分配页面。比如GFP_KERNEL是从UNMOVABLE类型分配页面的。
页面分配器是基于ZONE的机制来实现的,怎么去管理这些空闲页面呢?Linux内核中定义了三个警戒线,WATERMARK_MIN,WATERMARK_LOW,WATERMARK_HIGH。大家可以看下面这张图,就是分配水位和警戒线的关系。
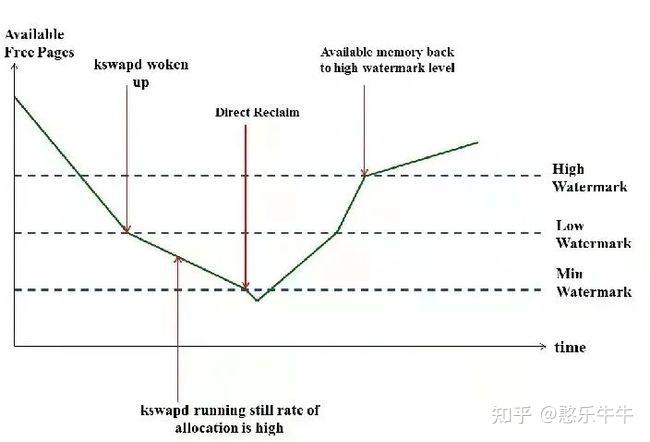
GFP_ATOMIC来分配内存,此时才会允许我们使用保留在min水位以下的内存。WMARK_MIN的125%WMARK_MAX的150%在进行内存分配的时候,如果分配器(比如buddy allocator)发现当前空余内存的值低于”low”但高于”min”,说明现在内存面临一定的压力,那么在此次内存分配完成后,kswapd将被唤醒,以执行内存回收操作。在这种情况下,内存分配虽然会触发内存回收,但不存在被内存回收所阻塞的问题,两者的执行关系是异步的
对于kswapd来说,要回收多少内存才算完成任务呢?只要把空余内存的大小恢复到”high”对应的watermark值就可以了,当然,这取决于当前空余内存和”high”值之间的差距,差距越大,需要回收的内存也就越多。”low”可以被认为是一个警戒水位线,而”high”则是一个安全的水位线。
如果内存分配器发现空余内存的值低于了”min”,说明现在内存严重不足。这里要分两种情况来讨论,一种是默认的操作,此时分配器将同步等待内存回收完成,再进行内存分配,也就是direct reclaim。还有一种特殊情况,如果内存分配的请求是带了PF_MEMALLOC标志位的,并且现在空余内存的大小可以满足本次内存分配的需求,那么也将是先分配,再回收。
内核会经常请求和释放单个页框,比如网卡驱动。
页面分配器分配和释放页面的时候需要申请一把锁:zone->lock
当请求单个页框时,直接从本地cpu的页框告诉缓存池中获取页框
体现了预先建立缓存池的优势,而且是每个CPU有一个独立的缓存池
由于页框频繁的分配和释放,内核在每个zone中放置了一些事先保留的页框。这些页框只能由来自本地CPU的请求使用。zone中有一个成员pageset字段指向per-cpu的高速缓存,高速缓存由struct per_cpu_pages数据结构来描述。
struct per_cpu_pages {
int count; /* number of pages in the list */
int high; /* high watermark, emptying needed */
int batch; /* chunk size for buddy add/remove */
/* Lists of pages, one per migrate type stored on the pcp-lists */
struct list_head lists[MIGRATE_PCPTYPES];
};
复制https://www.cnblogs.com/dennis-wong/p/14729453.html
https://blog.csdn.net/yhb1047818384/article/details/112298996