在当今人工智能领域,midjourney无疑是生成图片的王者,但是苦于付费才能使用,今天我就给大家分享一下midjourney平替stable diffusion,实现本地生成不逊色于midjourney的图片
先上一个我自己生成的效果(就是在我的Mac上用CPU生成的)

是不是非常棒?下面就让我们一起来深入探讨 Stable Diffusion 的使用方法吧!
官网:https://stablediffusionweb.com/
官网提供的在线上能力比较弱鸡,而且很多参数不能调节,使用次数还有限制,不推荐
如果你想要更高的自由度和定制化,推荐尝试本地搭建。这里推荐一个强大的工具包:
安装之后的页面
模型资源网站
我在这里简要说一下我的搭建过程,Mac的安装参考:https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Installation-on-Apple-Silicon
1. 安装 Python 3.10
确保安装 3.10 版本的 Python,其他版本可能会有兼容性问题。你可以参考 AUTOMATIC1111 的安装指南 完成安装。
2. 拉取仓库并运行
在命令行中,克隆仓库并启动安装脚本:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cd stable-diffusion-webui
./webui.sh
复制安装过程会自动下载必要的依赖和默认的模型,当命令行出现如下日志时,表示安装成功:
Running on local URL: http://127.0.0.1:7860
复制3. 下载模型
在 Civitai 上找到一个你喜欢的模型并下载,例如 国风3模型。将下载的 checkpoint 文件放入 stable-diffusion-webui/models/Stable-diffusion 文件夹,然后重启服务。
4. 填写参数
在 Web UI 中,你需要设置以下几个关键参数:
例如,我使用以下参数生成图片:
### Checkpoint
https://civitai.com/models/10415/3-guofeng3?modelVersionId=17414
### 正向词
best quality, masterpiece, highres, 1girl,china dress,hair ornament,necklace, jewelry,Beautiful face,upon_body, tyndall effect,photorealistic, dark studio, rim lighting, two tone lighting,(high detailed skin:1.2), 8k uhd, dslr, soft lighting, high quality, volumetric lighting, candid, Photograph, high resolution, 4k, 8k, Bokeh
### 负向词
(((simple background))),monochrome ,lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, lowres, bad anatomy, bad hands, text, error, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, ugly,pregnant,vore,duplicate,morbid,mut ilated,tran nsexual, hermaphrodite,long neck,mutated hands,poorly drawn hands,poorly drawn face,mutation,deformed,blurry,bad anatomy,bad proportions,malformed limbs,extra limbs,cloned face,disfigured,gross proportions, (((missing arms))),(((missing legs))), (((extra arms))),(((extra legs))),pubic hair, plump,bad legs,error legs,username,blurry,bad feet
### Sampling Steps
30
### CFG Scale
7
### Seed
2467180841
复制5. 生成图片
填写完参数后,点击右上角的 Generate 按钮。命令行会显示生成进度,大约需要3分钟。
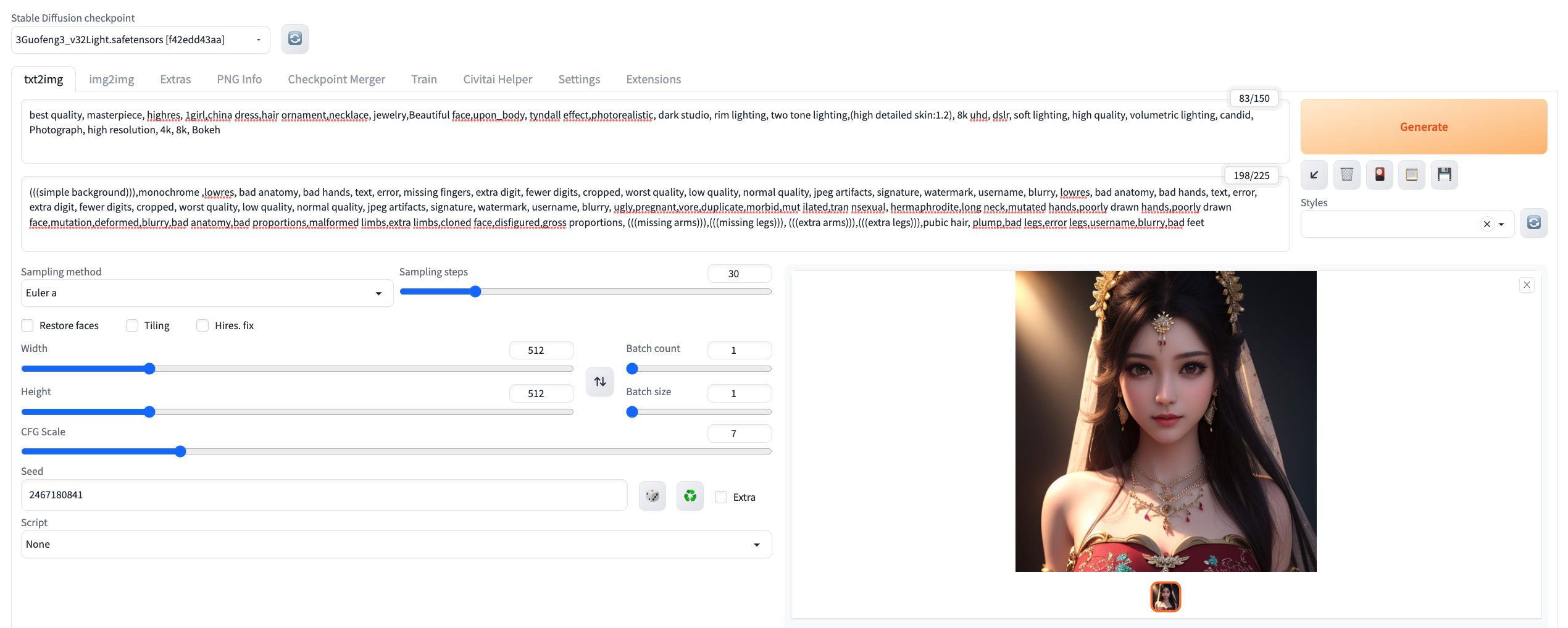
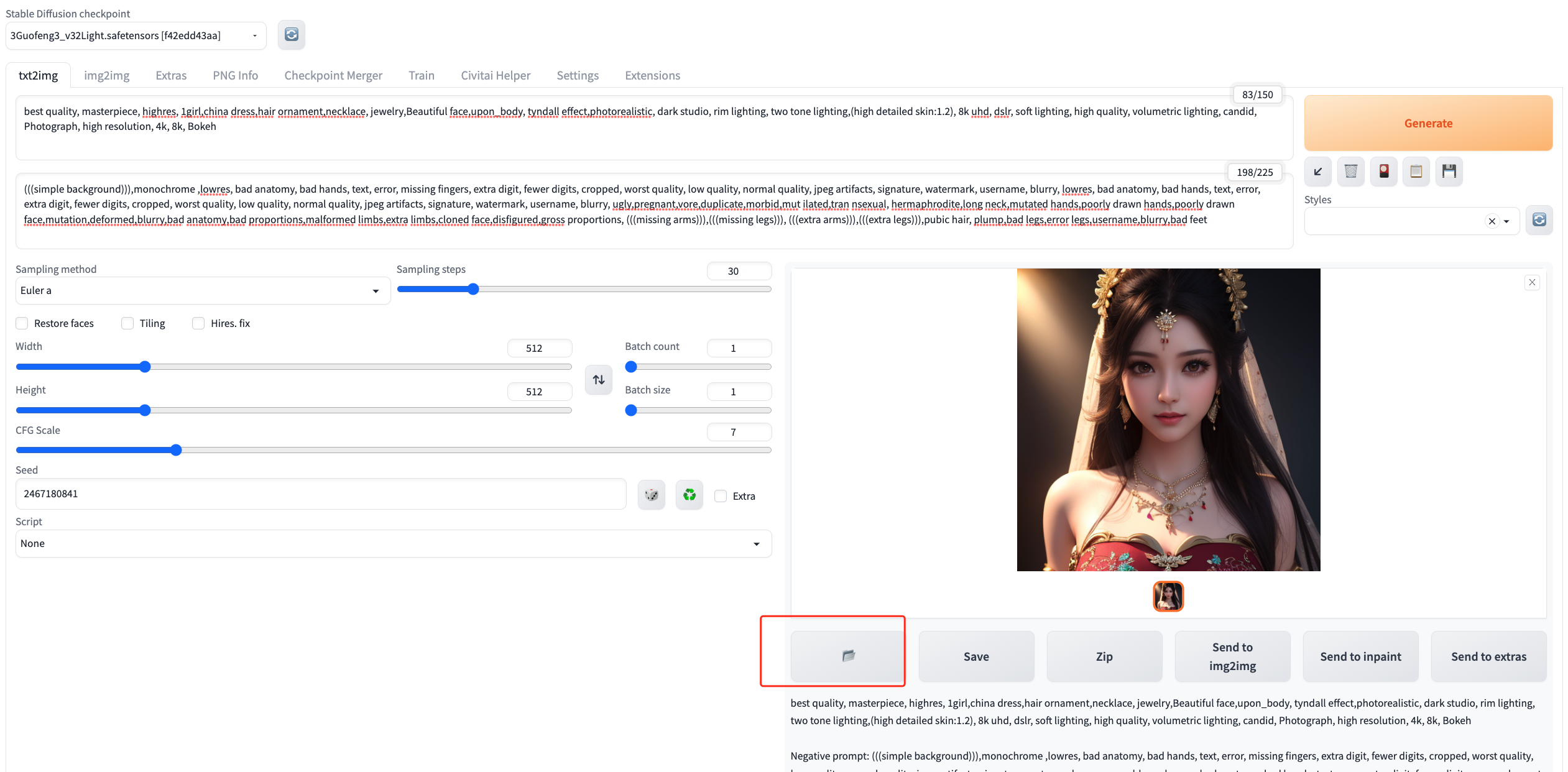
生成的图片分辨率可能不够理想,没关系!我们可以通过“放大修复”来提高图片质量。
6、提升分辨率
1. 选择 Extra 选项
在 Web UI 中,选择 Extra 选项卡,然后将刚刚生成的图片上传。
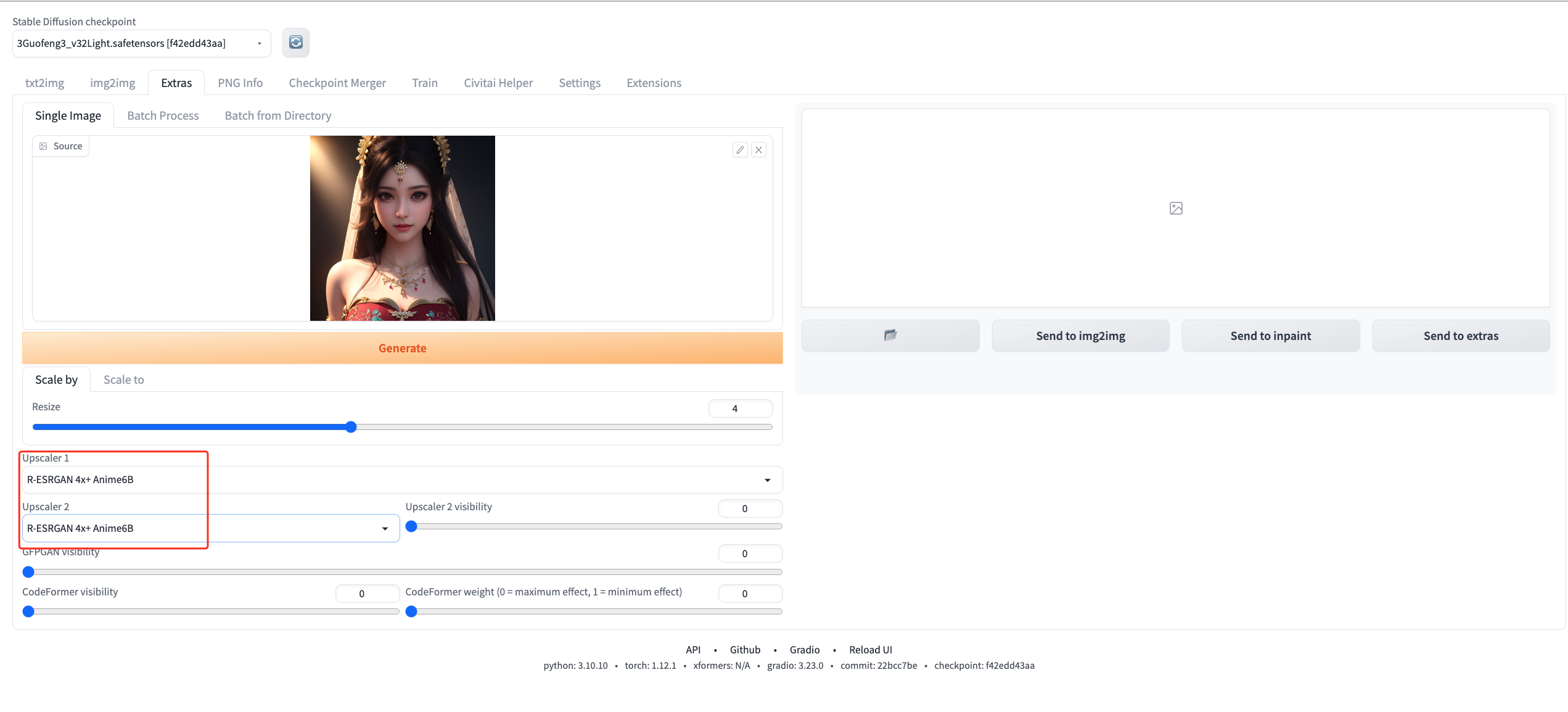
2. 设置放大参数
将 Upscaler1 和 Upscaler2 都设置为 R-ESRGAN 4X + Anime6B,这个配置可以显著提升图像质量。
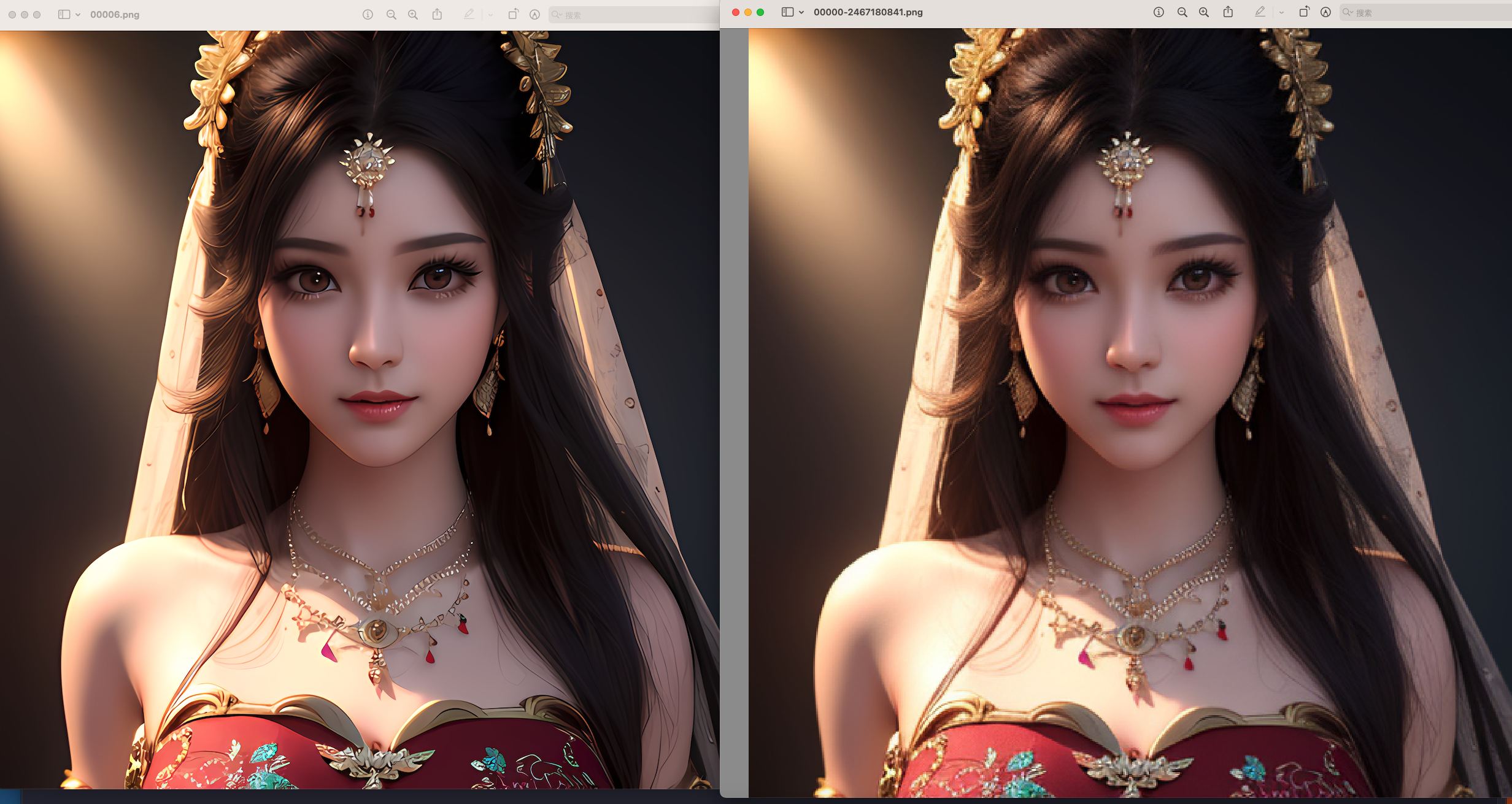
3. 看一下对比图,是不是效果显著提升?
CPU 高负载: 由于 Mac 通常没有强大的 GPU,生成过程会完全依赖 CPU,这可能导致 CPU 使用率飙升。建议在非工作时间操作,以免影响日常使用。
生成结果的差异性: 尽管设置相同参数,不同设备、不同显卡甚至不同运行环境都会影响生成的效果。高性能显卡通常能带来更好的效果,显卡越好生产的效果越好,模型网站的图片基本都是顶级显卡跑出来的
模型选择和参数调整: 不同的模型和参数组合会产生不同的结果,可以多尝试找到最适合的设置。
我们的公众号还将定期分享:
最新互联网资讯:让你时刻掌握行业动态。
AI前沿新闻:紧跟技术潮流,不断提升自我。
技术分享与职业发展:助你在职业生涯中走得更远、更稳。
程序员生活趣事:让你在忙碌的工作之余找到共鸣与乐趣。
关注回复【1024】惊喜等你来拿!
