Large Language Model (LLM) 即大规模语言模型,是一种基于深度学习的自然语言处理模型,它能够学习到自然语言的语法和语义,从而可以生成人类可读的文本。
所谓"语言模型",就是只用来处理语言文字(或者符号体系)的 AI 模型,发现其中的规律,可以根据提示 (prompt),自动生成符合这些规律的内容。
LLM 通常基于神经网络模型,使用大规模的语料库进行训练,比如使用互联网上的海量文本数据。这些模型通常拥有数十亿到数万亿个参数,能够处理各种自然语言处理任务,如自然语言生成、文本分类、文本摘要、机器翻译、语音识别等。
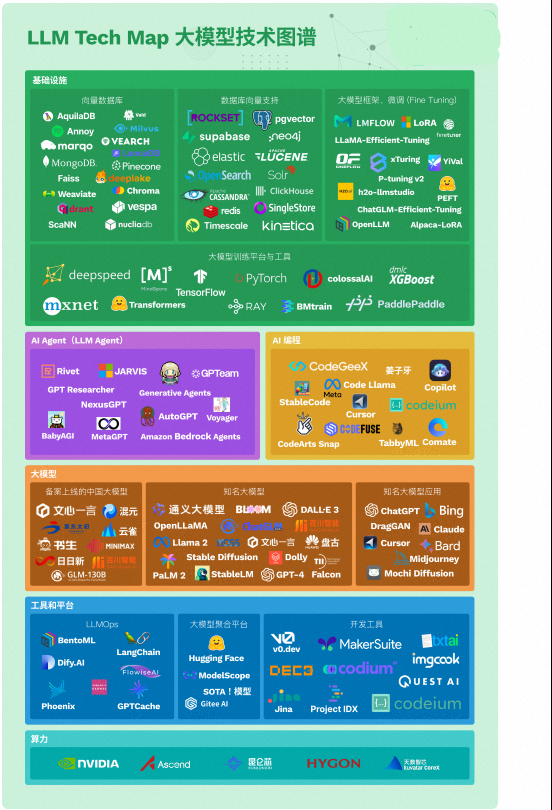
本文对国内外公司、科研机构等组织开源的 LLM 进行了全面的整理。
ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,并针对中文进行了优化。该模型基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 虽然规模不及千亿模型,但大大降低了推理成本,提升了效率,并且已经能生成相当符合人类偏好的回答。
基于 ChatGLM 初代模型的开发经验,ChatGLM2-6B 全面升级了基座模型,更长的上下文,更高效的推理、更开放的协议。
VisualGLM-6B 是一个开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数。
MOSS 是一个支持中英双语和多种插件的开源对话语言模型, moss-moon 系列模型具有 160 亿参数,在 FP16 精度下可在单张 A100/A800 或两张 3090 显卡运行,在 INT4/8 精度下可在单张 3090 显卡运行。
MOSS 基座语言模型在约七千亿中英文以及代码单词上预训练得到,后续经过对话指令微调、插件增强学习和人类偏好训练具备多轮对话能力及使用多种插件的能力。
DB-GPT 是一个开源的以数据库为基础的 GPT 实验项目,使用本地化的 GPT 大模型与数据和环境进行交互,无数据泄露风险,100% 私密,100% 安全。
DB-GPT 为所有以数据库为基础的场景,构建了一套完整的私有大模型解决方案。 此方案因为支持本地部署,所以不仅仅可以应用于独立私有环境,而且还可以根据业务模块独立部署隔离,让大模型的能力绝对私有、安全、可控。
CPM-Bee 是一个 完全开源、允许商用的百亿参数中英文基座模型。它采用 Transformer 自回归架构(auto-regressive),使用万亿级高质量语料进行预训练,拥有强大的基础能力。
CPM-Bee 的特点可以总结如下:
开源可商用:OpenBMB 始终秉承 “让大模型飞入千家万户” 的开源精神,CPM-Bee 基座模型将完全开源并且可商用,以推动大模型领域的发展。如需将模型用于商业用途,只需企业实名邮件申请并获得官方授权证书,即可商用使用。
中英双语性能优异:CPM-Bee 基座模型在预训练语料上进行了严格的筛选和配比,同时在中英双语上具有亮眼表现,具体可参见评测任务和结果。
超大规模高质量语料:CPM-Bee 基座模型在万亿级语料上进行训练,是开源社区内经过语料最多的模型之一。同时,我们对预训练语料进行了严格的筛选、清洗和后处理以确保质量。
OpenBMB 大模型系统生态支持:OpenBMB 大模型系统在高性能预训练、适配、压缩、部署、工具开发了一系列工具,CPM-Bee 基座模型将配套所有的工具脚本,高效支持开发者进行进阶使用。
强大的对话和工具使用能力:结合 OpenBMB 在指令微调和工具学习的探索,我们在 CPM-Bee 基座模型的基础上进行微调,训练出了具有强大对话和工具使用能力的实例模型,现已开放定向邀请内测,未来会逐步向公众开放。
CPM-Bee 的基座模型可以准确地进行语义理解,高效完成各类基础任务,包括:文字填空、文本生成、翻译、问答、评分预测、文本选择题等等。
LaWGPT 是一系列基于中文法律知识的开源大语言模型。
该系列模型在通用中文基座模型(如 Chinese-LLaMA、ChatGLM 等)的基础上扩充法律领域专有词表、大规模中文法律语料预训练,增强了大模型在法律领域的基础语义理解能力。在此基础上,构造法律领域对话问答数据集、中国司法考试数据集进行指令精调,提升了模型对法律内容的理解和执行能力。
相比已有的中文开源模型,伶荔模型具有以下优势:
在 32*A100 GPU 上训练了不同量级和功能的中文模型,对模型充分训练并提供强大的 baseline。据知,33B 的 Linly-Chinese-LLAMA 是目前最大的中文 LLaMA 模型。
公开所有训练数据、代码、参数细节以及实验结果,确保项目的可复现性,用户可以选择合适的资源直接用于自己的流程中。
项目具有高兼容性和易用性,提供可用于 CUDA 和 CPU 的量化推理框架,并支持 Huggingface 格式。
目前公开可用的模型有:
Linly-Chinese-LLaMA:中文基础模型,基于 LLaMA 在高质量中文语料上增量训练强化中文语言能力,现已开放 7B、13B 和 33B 量级,65B 正在训练中。
Linly-ChatFlow:中文对话模型,在 400 万指令数据集合上对中文基础模型指令精调,现已开放 7B、13B 对话模型。
Linly-ChatFlow-int4 :ChatFlow 4-bit 量化版本,用于在 CPU 上部署模型推理。
进行中的项目:
Chinese-Vicuna 是一个中文低资源的 LLaMA+Lora 方案。
项目包括
Chinese-LLaMA-Alpaca 包含中文 LLaMA 模型和经过指令微调的 Alpaca 大型模型。
这些模型在原始 LLaMA 的基础上,扩展了中文词汇表并使用中文数据进行二次预训练,从而进一步提高了对中文基本语义理解的能力。同时,中文 Alpaca 模型还进一步利用中文指令数据进行微调,明显提高了模型对指令理解和执行的能力。
ChatYuan 是一个支持中英双语的功能型对话语言大模型。ChatYuan-large-v2 使用了和 v1 版本相同的技术方案,在微调数据、人类反馈强化学习、思维链等方面进行了优化。
ChatYuan-large-v2 是 ChatYuan 系列中以轻量化实现高质量效果的模型之一,用户可以在消费级显卡、 PC 甚至手机上进行推理(INT4 最低只需 400M )。
HuatuoGPT(华佗 GPT)是开源中文医疗大模型,基于医生回复和 ChatGPT 回复,让语言模型成为医生,提供丰富且准确的问诊。
HuatuoGPT 致力于通过融合 ChatGPT 生成的 “蒸馏数据” 和真实世界医生回复的数据,以使语言模型具备像医生一样的诊断能力和提供有用信息的能力,同时保持对用户流畅的交互和内容的丰富性,对话更加丝滑。
本草(BenTsao)【原名:华驼 (HuaTuo)】是基于中文医学知识的 LLaMA 微调模型。
此项目开源了经过中文医学指令精调 / 指令微调 (Instruct-tuning) 的 LLaMA-7B 模型。通过医学知识图谱和 GPT3.5 API 构建了中文医学指令数据集,并在此基础上对 LLaMA 进行了指令微调,提高了 LLaMA 在医疗领域的问答效果。
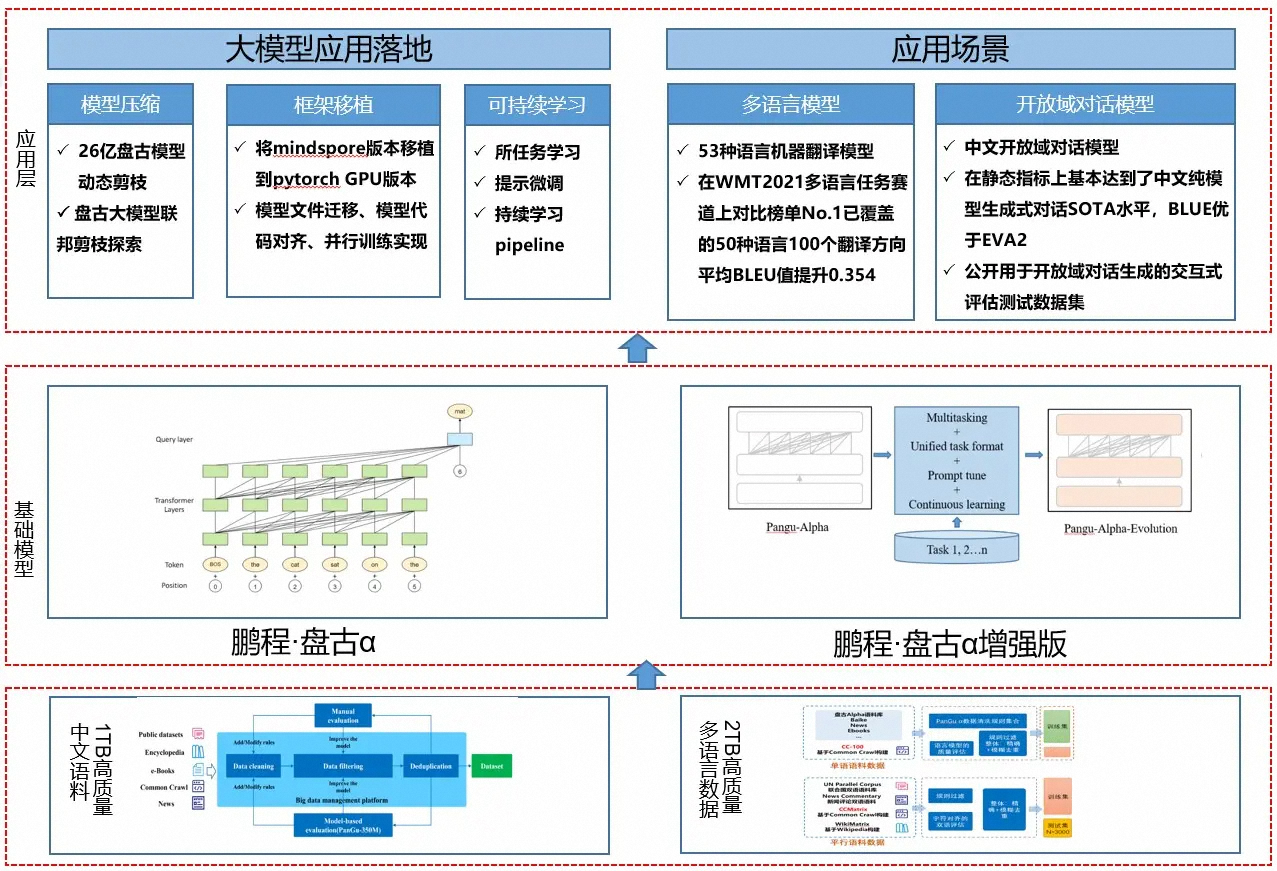
「鹏程·盘古α」是业界首个 2000 亿参数以中文为核心的预训练生成语言模型,目前开源了两个版本:鹏程·盘古α和鹏程·盘古α增强版,并支持NPU和GPU两个版本,支持丰富的场景应用,在知识问答、知识检索、知识推理、阅读理解等文本生成领域表现突出,具备较强的少样本学习的能力。
基于盘古系列大模型提供大模型应用落地技术帮助用户高效的落地超大预训练模型到实际场景。整个框架特点如下:
主要有如下几个核心模块:
数据集:从开源开放数据集、common crawl 数据集、电子书等收集近 80TB 原始语料,构建了约 1.1TB 的高质量中文语料数据集、53 种语种高质量单、双语数据集 2TB。
基础模块:提供预训练模型库,支持常用的中文预训练模型,包括鹏程・盘古 α、鹏程・盘古 α 增强版等。
应用层:支持常见的 NLP 应用比如多语言翻译、开放域对话等,支持预训练模型落地工具,包括模型压缩、框架移植、可持续学习,助力大模型快速落地。
鹏程・盘古对话生成大模型 (PanGu-Dialog)。
PanGu-Dialog 是以大数据和大模型为显著特征的大规模开放域对话生成模型,充分利用大规模预训练语言模型的知识和语言能力,构建可控、可靠可信、有智慧的自然人机对话模型。主要特性如下:
“悟道” 是双语多模态预训练模型,规模达到 1.75 万亿参数。项目现有 7 个开源模型成果。
CogView 参数量为 40 亿,模型可实现文本生成图像,经过微调后可实现国画、油画、水彩画、轮廓画等图像生成。目前在公认 MS COCO 文生图任务上取得了超过 OpenAI DALL・E 的成绩,获得世界第一。
BriVL (Bridging Vision and Language Model) 是首个中文通用图文多模态大规模预训练模型。BriVL 模型在图文检索任务上有着优异的效果,超过了同期其他常见的多模态预训练模型(例如 UNITER、CLIP)。
GLM 是以英文为核心的预训练语言模型系列,基于新的预训练范式实现单一模型在语言理解和生成任务方面取得了最佳结果,并且超过了在相同数据量进行训练的常见预训练模型(例如 BERT,RoBERTa 和 T5),目前已开源 1.1 亿、3.35 亿、4.10 亿、5.15 亿、100 亿参数规模的模型。
CPM 系列模型是兼顾理解与生成能力的预训练语言模型系列,涵盖中文、中英双语多类模型,目前已开源 26 亿、110 亿和 1980 亿参数规模的模型。
Transformer-XL 是以中文为核心的预训练语言生成模型,参数规模为 29 亿,目前可支持包括文章生成、智能作诗、评论 / 摘要生成等主流 NLG 任务。
EVA 是一个开放领域的中文对话预训练模型,是目前最大的汉语对话模型,参数量达到 28 亿,并且在包括不同领域 14 亿汉语的悟道对话数据集(WDC)上进行预训练。
Lawformer 是世界首创法律领域长文本中文预训练模型,参数规模达到 1 亿。
ProtTrans 是国内最大的蛋白质预训练模型,参数总量达到 30 亿。
BBT-2 是包含 120 亿参数的通用大语言模型,在 BBT-2 的基础上训练出了代码,金融,文生图等专业模型。基于 BBT-2 的系列模型包括:
BBT-2-12B-Text:120 亿参数的中文基础模型
BBT-2.5-13B-Text: 130 亿参数的中文+英文双语基础模型
BBT-2-12B-TC-001-SFT 经过指令微调的代码模型,可以进行对话
BBT-2-12B-TF-001 在 120 亿模型上训练的金融模型,用于解决金融领域任务
BBT-2-12B-Fig:文生图模型
BBT-2-12B-Science 科学论文模型
BELLE: Be Everyone's Large Language model Engine(开源中文对话大模型)
本项目目标是促进中文对话大模型开源社区的发展,愿景做能帮到每一个人的 LLM Engine。现阶段本项目基于一些开源预训练大语言模型(如 BLOOM),针对中文做了优化,模型调优仅使用由 ChatGPT 生产的数据(不包含任何其他数据)。
TigerBot 是一个多语言多任务的大规模语言模型(LLM)。根据 OpenAI InstructGPT 论文在公开 NLP 数据集上的自动评测,TigerBot-7B 达到 OpenAI 同样大小模型的综合表现的 96%。
中国人民大学高瓴人工智能学院相关研究团队(由多位学院老师联合指导)展开了一系列关于指令微调技术的研究,并发布了学院初版大语言对话模型——YuLan-Chat,旨在探索和提升大语言模型的中英文双语对话能力。
“百聆”是中国科学院计算技术研究所自然语言处理团队开发一个具有增强的语言对齐的英语/中文大语言模型。“百聆”具有优越的英语/中文生成能力、指令遵循能力和多轮交互能力,在多项测试中取得ChatGPT 90%的性能。“百聆”内测已经开启,欢迎试用。
通义千问 - 7B(Qwen-7B) 是阿里云研发的通义千问大模型系列的 70 亿参数规模的模型。
Qwen-7B 基于 Transformer 在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在 Qwen-7B 的基础上,使用对齐机制打造了基于大语言模型的 AI 助手 Qwen-7B-Chat。
Qwen-7B 系列模型的特点包括:
Code Llama 是基于 Llama 2 的 AI 代码生成大模型,可根据代码和自然语言提示生成代码和有关代码的自然语言,支持多种主流编程语言,包括 Python、C++、Java、PHP、Typescript (Javascript)、C# 和 Bash。
Code Llama 基于 Llama 2 大语言模型打造,提供了三种模型:
它们具有开放式模型中领先的性能、填充能力、对大型输入上下文的支持以及用于编程任务的零指令跟随能力。所有模型都是基于 16k 标记序列进行训练,并在最多 100k 标记输入上显示出改进。
CodeFuse-13B 是基于 GPT-NeoX 框架训练的 13B 参数代码生成模型,能够处理 4096 个字符的代码序列。
该模型在 1000B Token 的代码、中文、英文数据数据集上进行预训练,覆盖超过 40 种编程语言。
为了进一步提升生成代码的效果和质量,该模型还在 CodeFuse-Evol-instruction-66k 数据集上进行了微调,使得该模型能够生成更加准确、高效、符合要求的代码。在 HumanEval 评测集上 Pass@1 达到 37.1%(采用 BeamSearch 解码,其中 BeamSize=3)。
MiLM-6B 是由小米开发的一个大规模预训练语言模型,参数规模为 64 亿。在 C-Eval 和 CMMLU 上均取得同尺寸最好的效果。
根据 C-Eval 给出的信息,MiLM-6B 模型在具体各科目成绩上,在 STEM(科学、技术、工程和数学教育)全部 20 个科目中,计量师、物理、化学、生物等多个项目获得了较高的准确率。
LLaMA 语言模型全称为 "Large Language Model Meta AI",是 Meta 的全新大型语言模型(LLM),这是一个模型系列,根据参数规模进行了划分(分为 70 亿、130 亿、330 亿和 650 亿参数不等)。
其中 LaMA-13B(130 亿参数的模型)尽管模型参数相比 OpenAI 的 GPT-3(1750 亿参数) 要少了十几倍,但在性能上反而可以超过 GPT-3 模型。更小的模型也意味着开发者可以在 PC 甚至是智能手机等设备上本地运行类 ChatGPT 这样的 AI 助手,无需依赖数据中心这样的大规模设施。
Stanford Alpaca(斯坦福 Alpaca)是一个指令调优的 LLaMA 模型,从 Meta 的大语言模型 LLaMA 7B 微调而来。
Stanford Alpaca 让 OpenAI 的 text-davinci-003 模型以 self-instruct 方式生成 52K 指令遵循(instruction-following)样本,以此作为 Alpaca 的训练数据。研究团队已将训练数据、生成训练数据的代码和超参数开源,后续还将发布模型权重和训练代码。
Lit-LLaMA 是一个基于 nanoGPT 的 LLaMA 语言模型的实现,支持量化、LoRA 微调、预训练、flash attention、LLaMA-Adapter 微调、Int8 和 GPTQ 4bit 量化。
主要特点:单一文件实现,没有样板代码;在消费者硬件上或大规模运行;在数值上等同于原始模型。
Lit-LLaMA 认为人工智能应该完全开源并成为集体知识的一部分。但原始的 LLaMA 代码采用 GPL 许可证,这意味着使用它的任何项目也必须在 GPL 下发布。这“污染”了其他代码,阻止了与生态系统的集成。Lit-LLaMA 永久性地解决了这个问题。
GloVe的全称叫Global Vectors for Word Representation,它是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具,它可以把一个单词表达成一个由实数组成的向量,这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等。我们通过对向量的运算,比如欧几里得距离或者cosine相似度,可以计算出两个单词之间的语义相似性。
以下是 GloVe 提供的预训练词向量,遵循 Public Domain Dedication and License 许可。
Dolly 是一个低成本的 LLM,Dolly 采用 EleutherAI 现有的 60 亿参数的开源模型,并对其进行细微的修改,以激发指令跟随能力。
尽管模型小得多,只有 60 亿个参数,以及较小的数据集和训练时间(ChatGPT 的参数是 1750 亿个),但 Dolly 仍然表现出了 ChatGPT 所展示的同样的 "神奇的人类互动能力"。
OPT-175B 是 Meta 开源的大语言模型,拥有超过 1750 亿个参数 —— 和 GPT-3 相当。相比 GPT-3,OPT-175B 的优势在于它完全免费。
Meta 还公布了代码库、开发过程日志、数据、研究论文和其他与 OPT-175B 相关的信息。尽管 OPT-175B 是免费的,但 Meta 也给出了一些限制。为了防止误用和 “保持完整性”,OPT-175B 只允许在非商业用途下使用。也就是说,OPT-175B 的多数应用场景还是在科研上。
Cerebras GPT 是由 Cerebras 公司开源的自然语言处理领域的预训练大模型,其模型参数规模最小 1.11 亿,最大 130 亿,共 7 个模型。
与业界的模型相比,Cerebras-GPT 几乎是各个方面完全公开,没有任何限制。不管是模型架构,还是预训练结果都是公开的。
Bloom 是用于自然语言处理的大语言模型,包含 1760 亿个参数,支持 46 种自然语言(包括中文)和 13 种编程语言,可以用来回答问题、翻译文本、从文件中提取信息片段,还能像 GitHub Copilot 一样用于生成代码。
BLOOM 模型的最大优势是它的易获取性,任何个人或机构都可以从 Hugging Face 免费获得 1760 亿个参数的完整模型。用户有多个语种可选,然后将需求输入到 BLOOM 中,任务类型包括撰写食谱或诗歌、翻译或总结文本,甚至还有代码编程。人工智能开发者可以在该模型的基础上构建他们自己的应用程序。
BLOOMChat 是一个新的、开放的、多语言的聊天 LLM。SambaNova 和 Together 使用 SambaNova 独特的可重构数据流架构在 SambaNova DataScale 系统上训练了 BLOOMChat;其建立在 BigScience 组织的 BLOOM 之上,并在 OpenChatKit、Dolly 2.0 和 OASST1 的 OIG 上进行了微调。
GPT-J 是一个基于 GPT-3,由 60 亿个参数组成的自然语言处理 AI 模型。
该模型在一个 800GB 的开源文本数据集上进行训练,并且能够与类似规模的 GPT-3 模型相媲美。 该模型通过利用 Google Cloud 的 v3-256 TPU 以及 EleutherAI 的 The Pile 数据集进行训练,历时大约五周时间。GPT-J 在标准 NLP 基准工作负载上实现了与 OpenAI 报告的 67 亿参数版本的 GPT-3 类似的准确性。模型代码、预训练的权重文件、Colab 文档和一个演示网页都包含在 EleutherAI 的开源项目中。
GPT-2 是一种基于 transformer 的大型语言模型,具有 15 亿个参数,在 800 万网页数据集上进行训练。
GPT-2 能够翻译文本、回答问题、总结段落,并生成文本输出。虽然其输出内容有时与人类相似,但在生成长段落时输出内容可能会变得重复或无意义。
GPT-2 是一个通用学习器,没有经过专门训练来执行任何特定的任务,并且是作为 OpenAI 2018 GPT 模型的“直接扩展”而创建的,其参数数量和训练数据集的大小均增加了十倍。
RWKV 是结合了 RNN 和 Transformer 的语言模型,适合长文本,运行速度较快,拟合性能较好,占用显存较少,训练用时较少。
RWKV 整体结构依然采用 Transformer Block 的思路,相较于原始 Transformer Block 的结构,RWKV 将 self-attention 替换为 Position Encoding 和 TimeMix,将 FFN 替换为 ChannelMix。其余部分与 Transfomer 一致。
白泽是使用 LoRA 训练的开源聊天模型,它改进了开源大型语言模型 LLaMA,通过使用新生成的聊天语料库对 LLaMA 进行微调,该模型在单个 GPU 上运行,使其可供更广泛的研究人员使用。
白泽目前包括四种英语模型:白泽 -7B、13B 和 30B(通用对话模型),以及一个垂直领域的白泽 - 医疗模型,供研究 / 非商业用途使用,并计划在未来发布中文的白泽模型。
白泽的数据处理、训练模型、Demo 等全部代码已经开源。
CodeGeeX 是一个具有 130 亿参数的多编程语言代码生成预训练模型。CodeGeeX 采用华为 MindSpore 框架实现,在鹏城实验室 “鹏城云脑 II” 中的 192 个节点(共 1536 个国产昇腾 910 AI 处理器)上训练而成。
CodeGeeX 有以下特点:
「Falcon」由阿联酋阿布扎比的技术创新研究所(TII)开发,从性能上看,Falcon比LLaMA的表现更好。TII表示,Falcon迄今为止最强大的开源语言模型。其最大的版本,Falcon 40B,拥有400亿参数,相对于拥有650亿参数的LLaMA来说,规模上还是小了一点。规模虽小,性能能打。
Vicuna 模型对 LLaMA 进行了微调,由加州大学伯克利分校、卡内基梅隆大学、斯坦福大学、加州大学圣地亚哥分校和 MBZUAI 的学术团队进行微调训练而成,有两种大小可供选择:7B 和 13B。
Vicuna-13B 与 Stanford Alpaca 等其他开源模型相比展示了具有竞争力的性能。
以 GPT-4 为评判标准的初步评估显示,Vicuna-13B 达到了 OpenAI ChatGPT 和 Google Bard 90% 以上的质量,同时在 90% 以上的情况下超过了 LLaMA 和 Stanford Alpaca 等其他模型的表现。训练 Vicuna-13B 成本约为 300 美元。训练和服务代码,以及在线演示都是公开的,可用于非商业用途。
RedPajama 项目旨在创建一套领先的全开源大语言模型。目前,该项目已完成了第一步,成功复制了 LLaMA 训练数据集超过 1.2 万亿个数据 token。该项目由 Together、Ontocord.ai、ETH DS3Lab、斯坦福大学 CRFM、Hazy Research 和 MILA 魁北克 AI 研究所联合开发。
RedPajama 包含三个主要组成部分:预训练数据、基础模型和指令调优数据与模型。
OpenAssistant 是一个开源项目,旨在开发免费提供给所有人使用的 AI 聊天机器人。
训练数据集 OpenAssistant Conversations 包含了超过 60 万个涉及各种主题的交互,用于训练各种模型。目前发布了经过指令调整的 LLaMA 13B 和 30B 模型,以及其他使用相同数据集训练的模型。
StableLM 项目仓库包含 Stability AI 正在进行的 StableLM 系列语言模型开发,目前 Stability AI 发布了初始的 StableLM-alpha 模型集,具有 30 亿和 70 亿参数。150 亿和 300 亿参数的模型正在开发中。
StableLM 模型可以生成文本和代码,并为一系列下游应用提供支持。它们展示了小而高效的模型如何在适当的训练下提供高性能。
StarCoder(150 亿参数)是 Hugging Face 联合 ServiceNow 发布的免费大型语言模型,该模型经过训练主要用途是可以生成代码,目的是为了对抗 GitHub Copilot 和亚马逊 CodeWhisperer 等基于 AI 的编程工具。
SantaCoder 是一个语言模型,该模型拥有 11 亿个参数,可以用于 Python、Java 和 JavaScript 这几种编程语言的代码生成和补全建议。
根据官方提供的信息,训练 SantaCoder 的基础是 The Stack(v1.1)数据集,SantaCoder 虽然规模相对较小,只有 11 亿个参数,在参数的绝对数量上低于 InCoder(67 亿)或 CodeGen-multi(27 亿),但 SantaCoder 的表现则是要远好于这些大型多语言模型。
MLC LLM 是一种通用解决方案,它允许将任何语言模型本地部署在各种硬件后端和本地应用程序上。
此外,MLC LLM 还提供了一个高效的框架,供使用者根据需求进一步优化模型性能。MLC LLM 旨在让每个人都能在个人设备上本地开发、优化和部署 AI 模型,而无需服务器支持,并通过手机和笔记本电脑上的消费级 GPU 进行加速。
Web LLM 是一个可将大型语言模型和基于 LLM 的聊天机器人引入 Web 浏览器的项目。一切都在浏览器内运行,无需服务器支持,并使用 WebGPU 加速。这开辟了许多有趣的机会,可以为每个人构建 AI 助手,并在享受 GPU 加速的同时实现隐私。
WizardLM 是一个经过微调的 7B LLaMA 模型。它通过大量具有不同难度的指令跟随对话进行微调。这个模型的新颖之处在于使用了 LLM 来自动生成训练数据。
WizardLM 模型使用一种名为 Evol-Instruct(是一种使用 LLM 代人类自主批生成各种难度等级和技术范围的开放指令,以提高 LLM 能力的新方法)的新方法,通过 70k 个计算机生成的指令进行训练,该方法生成具有不同难度级别的指令。
YaLM 100B是一个类似 GPT 的神经网络,用于生成和处理文本。
该模型利用了 1000 亿个参数,在 800 个 A100 显卡和 1.7 TB 在线文本、书籍以及海量其他英文和俄文资源的集群上训练该模型花了 65 天时间。
OpenLLaMA 是 Meta AI 的 LLaMA 大语言模型的开源复现版本,采用宽松许可证。
仓库包含经过训练的 2000 亿标记的 7B OpenLLaMA 模型的公共预览版,并提供了预训练的 OpenLLaMA 模型的 PyTorch 和 Jax 权重,以及评估结果和与原始 LLaMA 模型的比较。
OpenLLM 是一个生产级的操作大语言模型 (LLM) 的开放平台。支持便捷 Fine-tune 微调、Serve 模型服务、部署和监控任何 LLM。借助 OpenLLM,可以使用任何开源大语言模型运行推理,部署到云端或本地,并构建强大的 AI 应用程序。
OpenLLM 特性包括:
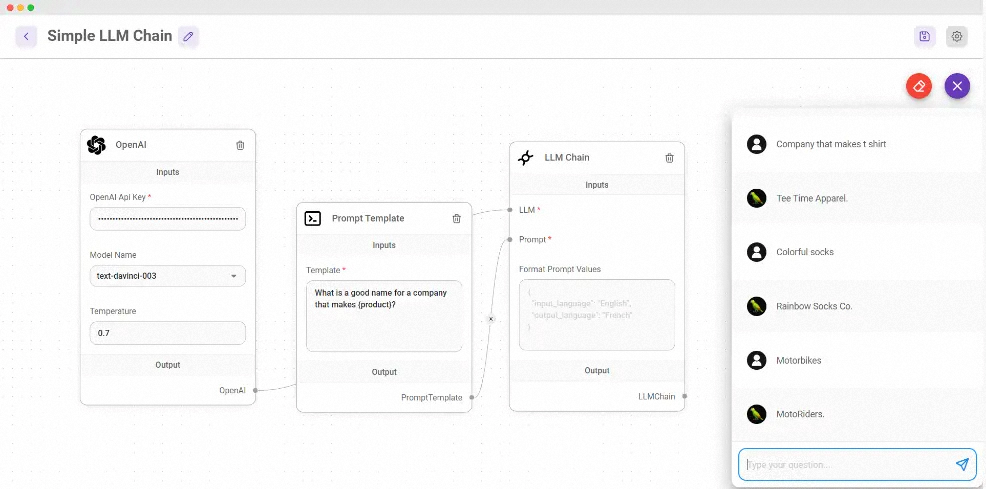
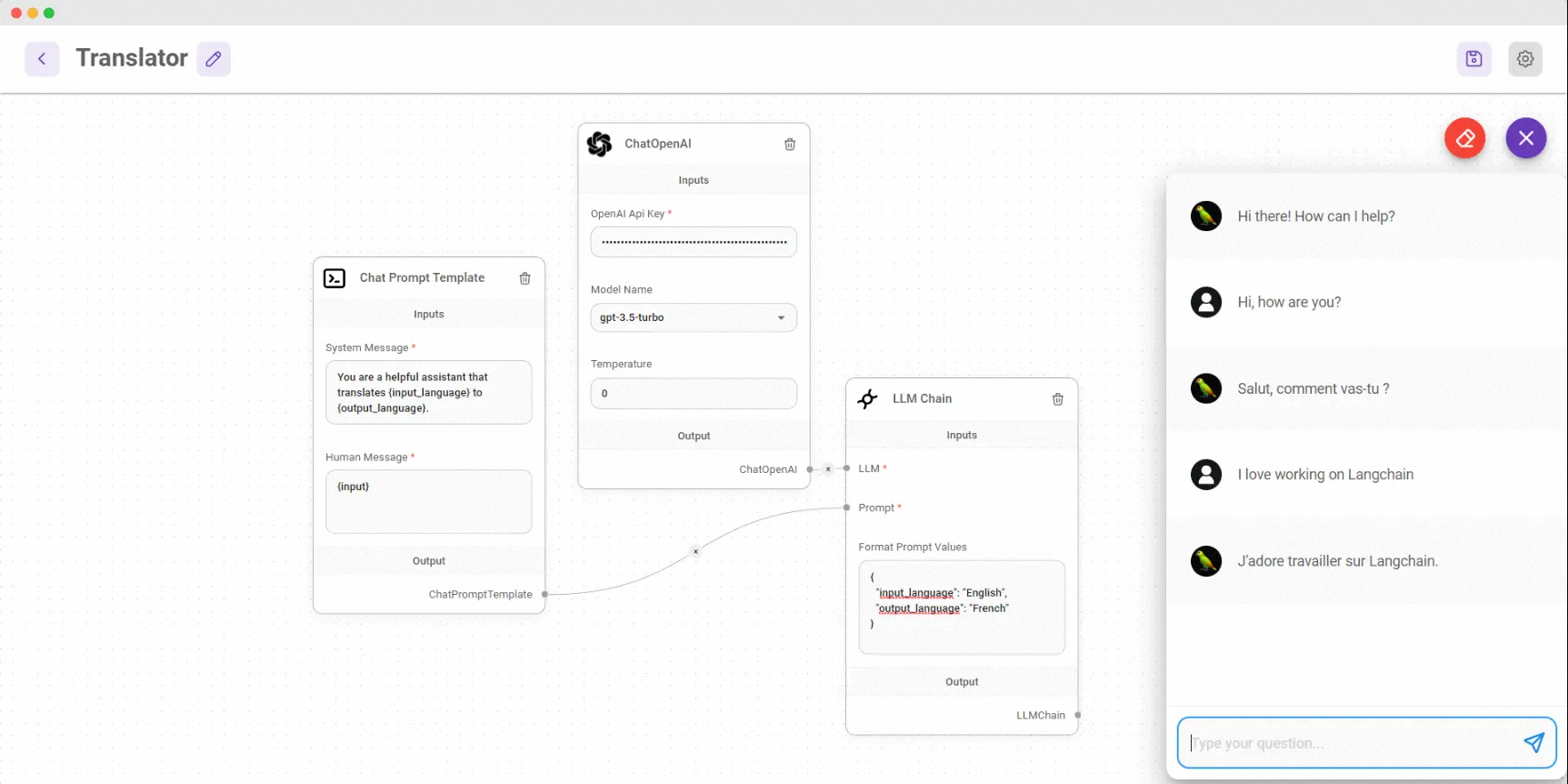
LangChain 是一个用于构建基于大型语言模型(LLM)的应用程序的库。它可以帮助开发者将 LLM 与其他计算或知识源结合起来,创建更强大的应用程序。
LangChain 提供了以下几个主要模块来支持这些应用程序的开发:
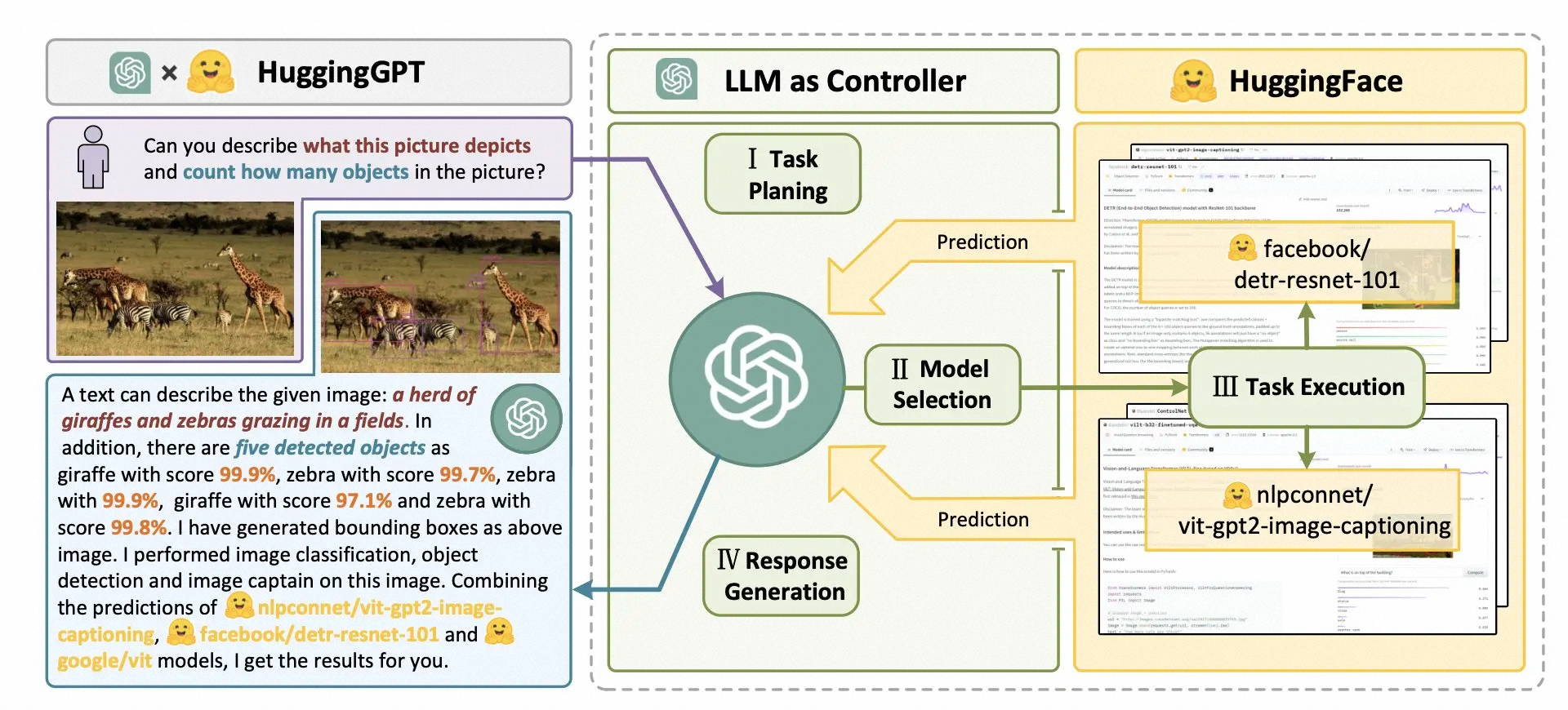
JARVIS 是用于连接 LLM 和 AI 模型的协作系统。该系统由 LLM(大语言模型)作为控制器和许多AI 模型作为协作执行者(来自 HuggingFace Hub)组成。
系统的工作流程包括四个阶段:
Semantic Kernel 是一种轻量级 SDK,可将 AI 大语言模型 (LLM) 与传统编程语言集成。
Semantic Kernel 可扩展编程模型结合了自然语言语义功能、传统代码原生功能和基于嵌入的内存,释放新的潜力并通过 AI 为应用程序增加价值。
Semantic Kernel 旨在支持和封装来自最新 AI 研究的多种设计模式,以便开发人员可以为他们的应用程序注入复杂的技能,如提示链、递归推理、总结、零 / 少样本学习、上下文记忆、长期记忆、嵌入、语义索引、规划和访问外部知识存储以及内部数据等功能。
LMFlow 由香港科技大学统计和机器学习实验室团队发起,致力于建立一个全开放的大模型研究平台,支持有限机器资源下的各类实验,并且在平台上提升现有的数据利用方式和优化算法效率,让平台发展成一个比之前方法更高效的大模型训练系统。
LMFlow 的最终目的是帮助每个人都可以用尽量少的资源来训练一个专有领域的、个性化的大模型,以此来推进大模型的研究和应用落地。
LMFlow 拥有四大特性:可扩展、轻量级、定制化和完全开源。
基于此,用户可以很快地训练自己的模型并继续进行二次迭代。这些模型不仅限于最近流行的 LLaMA,也包括 GPT-2、Galactica 等模型。
xturing 为 LLM 提供了快速、高效和简单的微调,如 LLaMA、GPT-J、GPT-2、OPT、Cerebras-GPT、Galactica 等。通过提供一个易于使用的界面,再根据你自己的数据和应用来个性化 LLM,xTuring 使构建和控制 LLM 变得简单。整个过程可以在你的电脑内或在你的私有云中完成,确保数据的隐私和安全。
通过 xturing,你可以:
Dify是一个易用的 LLMOps 平台,旨在让更多人可以创建可持续运营的原生 AI 应用。Dify 提供多种类型应用的可视化编排,应用可开箱即用,也能以 “后端即服务” 的 API 提供服务。
“Dify” 这个名字来源于 “Define” 和 “Modify” 这两个词。它代表了帮助开发人员不断改进其 AI 应用程序的愿景。“Dify” 可以理解为 “Do it for you”。
通过 Dify 创建的应用包含了:
Dify 兼容 Langchain,这意味着将逐步支持多种 LLMs ,目前已支持:
Dify.AI 核心能力
正在开发中的功能:
Flowise 是一个开源 UI 可视化工具,使用以 Node Typescript/Javascript 编写的 LangchainJS 构建自定义 LLM 流程。
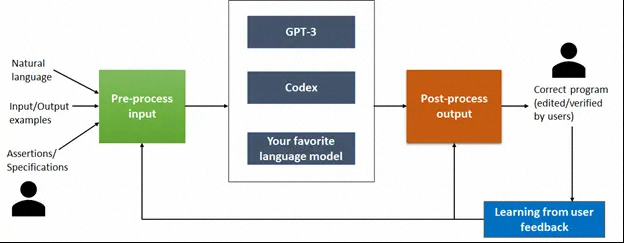
Jigsaw 是微软推出的一种可以提高大型语言模型性能(如 GPT-3、Codex 等)的新工具。
Jigsaw 部署了理解程序语法和语义的后处理技术,然后利用用户反馈来提高未来的性能;该工具旨在使用多模式输入为 Python Pandas API 合成代码。Pandas 是数据科学中广泛使用的 API,具有数百个用于 manipulating dataframes 或具有行和列的表的函数。
目标是使部分审查自动化,以提高使用 Codex 等大型语言模型进行代码合成的开发人员的生产力。
Jigsaw 获取英语查询并使用适当的上下文对其进行预处理,以构建可以馈送到大型语言模型的输入。该模型被视为一个黑盒子,并且 Jigsaw 已使用 GPT-3 和 Codex 进行了评估。这种设计的优势在于它支持即插即用最新和最好的可用型号。
微软在实验中发现,Jigsaw 可以在 30% 的时间内创建正确的输出。如果代码失败,那么修复过程在后处理阶段开始。
GPTCache 是一个用于创建语义缓存以存储来自 LLM 查询的响应的库。将你的 LLM API 成本削减 10 倍,将速度提高 100 倍。
ChatGPT 和各种大型语言模型(LLM)拥有令人难以置信的多功能性,能够开发广泛的应用程序。然而,随着你的应用程序越来越受欢迎,遇到更高的流量水平,与 LLM API 调用相关的费用可能会变得很高。此外,LLM 服务可能会表现出缓慢的响应时间,特别是在处理大量的请求时。GPTCache 的创建就是为了应对这一挑战,这是一个致力于建立一个用于存储 LLM 响应的语义缓存的项目。
闻达:一个大型语言模型调用平台。目前支持 chatGLM-6B、chatRWKV、chatYuan 和 chatGLM-6B 模型下自建知识库查找。
chatGLM-6B、chatRWKV、chatYuan。chatGLM-6B、chatRWKV流式输出和输出过程中中断MindSpore MindFormers 套件的目标是构建一个大模型训练、推理、部署的全流程开发套件: 提供业内主流的 Transformer 类预训练模型和 SOTA 下游任务应用,涵盖丰富的并行特性。 期望帮助用户轻松的实现大模型训练和创新研发。
MindSpore MindFormers 套件基于 MindSpore 内置的并行技术和组件化设计,具备如下特点:
目前支持的模型列表如下:
Code as Policies 是一种以机器人为中心的语言模型生成的程序在物理系统上执行的表述。CaP 扩展了 PaLM-SayCan,使语言模型能够通过通用 Python 代码的完整表达来完成更复杂的机器人任务。通过 CaP,Google 建议使用语言模型,通过少量的提示来直接编写机器人代码。实验证明,与直接学习机器人任务和输出自然语言动作相比,CaP 输出代码表现更好。CaP 允许单一系统执行各种复杂多样的机器人任务,而不需要特定的任务训练。
用于控制机器人的常见方法是用代码对其进行编程,以检测物体、移动执行器的排序命令和反馈回路来指定机器人应如何执行任务。但为每项新任务重新编程的可能很耗时,而且需要领域的专业知识。
ColossalAI 是一个具有高效并行化技术的综合大规模模型训练系统。旨在无缝整合不同的并行化技术范式,包括数据并行、管道并行、多张量并行和序列并行。
Colossal-AI 的目标是支持人工智能社区以与他们正常编写模型相同的方式编写分布式模型。这使得他们可以专注于开发模型架构,并将分布式训练的问题从开发过程中分离出来。
ColossalAI 提供了一组并行训练组件。旨在支持用户编写分布式深度学习模型,就像编写单 GPU 模型一样。提供友好的工具,只需几行即可启动分布式培训。
BentoML 是 AI 应用程序开发人员的平台,提供工具和基础架构来简化整个 AI 产品开发生命周期。BentoML 使创建准备好部署和扩展的机器学习服务变得容易。
BentoML 原生支持所有流行的 ML 框架,包括 Pytorch、Tensorflow、JAX、XGBoost、HuggingFace、MLFlow,以及最新的预构建开源 LLM(大型语言模型)和生成式 AI 模型。
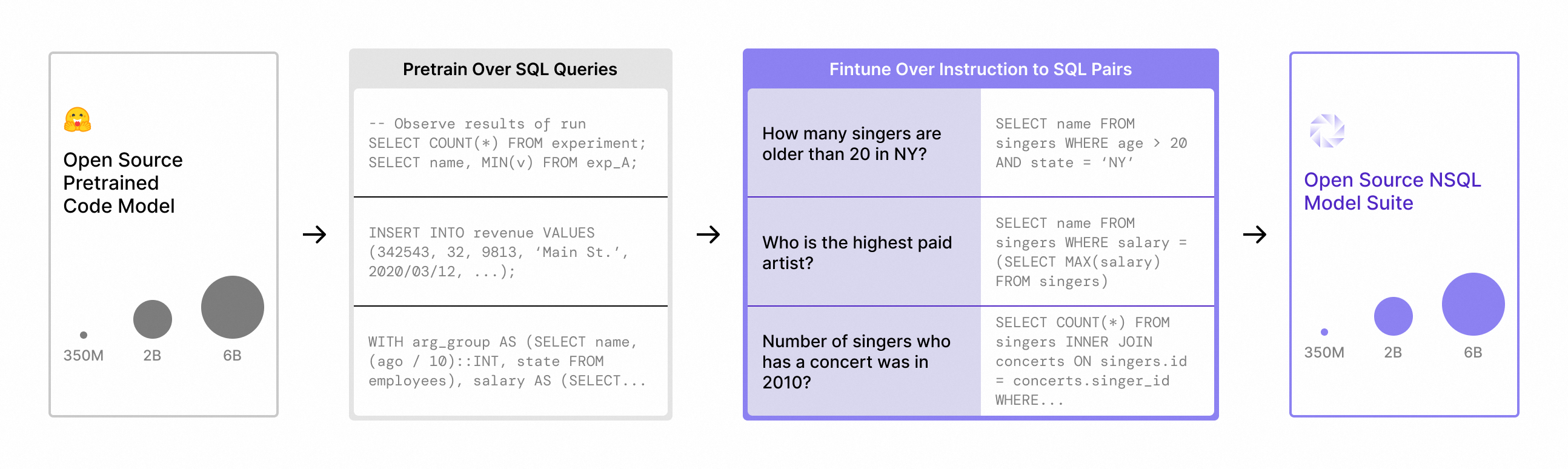
NSQL,这是一个专为 SQL 生成任务设计的全新开源大型基础模型 (FM) 系列,包括 NSQL 350M、NSQL 2B 和 NSQL 6B。
Highlights
Unified Model Serving API
无摩擦过渡到生产的标准化流程
具有强大的性能优化的可扩展性
以 DevOps 友好的方式部署到任何地方