本章节暂不考虑服务器性能指标, 目前仅对核心开发板资源占用、延时作为硬性考虑指标
目前市面上常见的推拉流协议有:RTMP、HLS、HTTP-FLV、RTSP、WebRTC
| 协议名称 | 延时 | 传输协议 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|---|
| RTMP | 1~5s | TCP | 1. 协议成熟 2. 上手成本低 |
兼容性问题,大部分主流浏览器已不支持 Flash | PC 端延时不敏感直播 |
| HLS | >10s | TCP | 1. 点播场景非常适用 2. 平滑播放(像播放视频文件一样直播) |
延迟非常高 | 点播场景 |
| HTTP-FLV | 1~5s | TCP | 1. 延时较低且可浏览器播放 | 浏览器上适用需要用到特定本播放器(flv.js) | 对延时有一定要求并期望在浏览器上播放的场景 |
| RTSP | <1s | TCP/UDP | 1. 延时极低 |
属于被动协议,需要客户端主动去拉流,不会向外推流(GB28181 可以实现向外推流) | 各大摄像头厂商基本协议 |
| WebRTC | <500ms | UDP | 1.延时很低 | 上手难度大 | 低时延直播、会议室 |
上述的表格统计也仅为本人经验总结,欢迎大佬们指正与指点迷津。😀😀
🚩 上述延时均为大概范围,具体时间还得看不同的拉流手段、服务器环境、网路环境等因素。
🔶🔶 题外话:
本人项目中也试过这样的推拉流方案:
- 推流端: RTSP
- 拉流端: JSMpeg
- 中转端: FFmpeg
整个流程:RTSP -> FFmpeg -> JAVA 服务 -> WebSocket -> 客户端
FFmpeg 拉取 RTSP 流,转码并转成 TCP 流至 JAVA 服务,JAVA 服务将接收到的流通过 WebSocket 推送至浏览器客户端;客户端接收后利用 JSMpeg 来播放整个流
当初这样处理主要是为了少搭建一个流媒体服务器,一般情况下我还是会去选择转 RTMP 后适用 flv.js 播放
本次实验与测试对象如下
服务器相关资源
相关环境安装的教程建议参考官方文档(好的项目总是不断更新迭代的,经常翻阅文档将会是一个不错的习惯)
目前由于学习成本与时间关系:仅从以下几种低成本的方式进行选择性测试,后续再发文其他方式的相关文章。
由于对延时的要求较高,因此目前暂不考虑 HLS 这等高延时方案,RTSP 由于是一个被动拉取的协议,因此也暂时不考虑 RTSP 的方案,WebRTC 方案技术成本较高,放后续进行测试与整理文档。
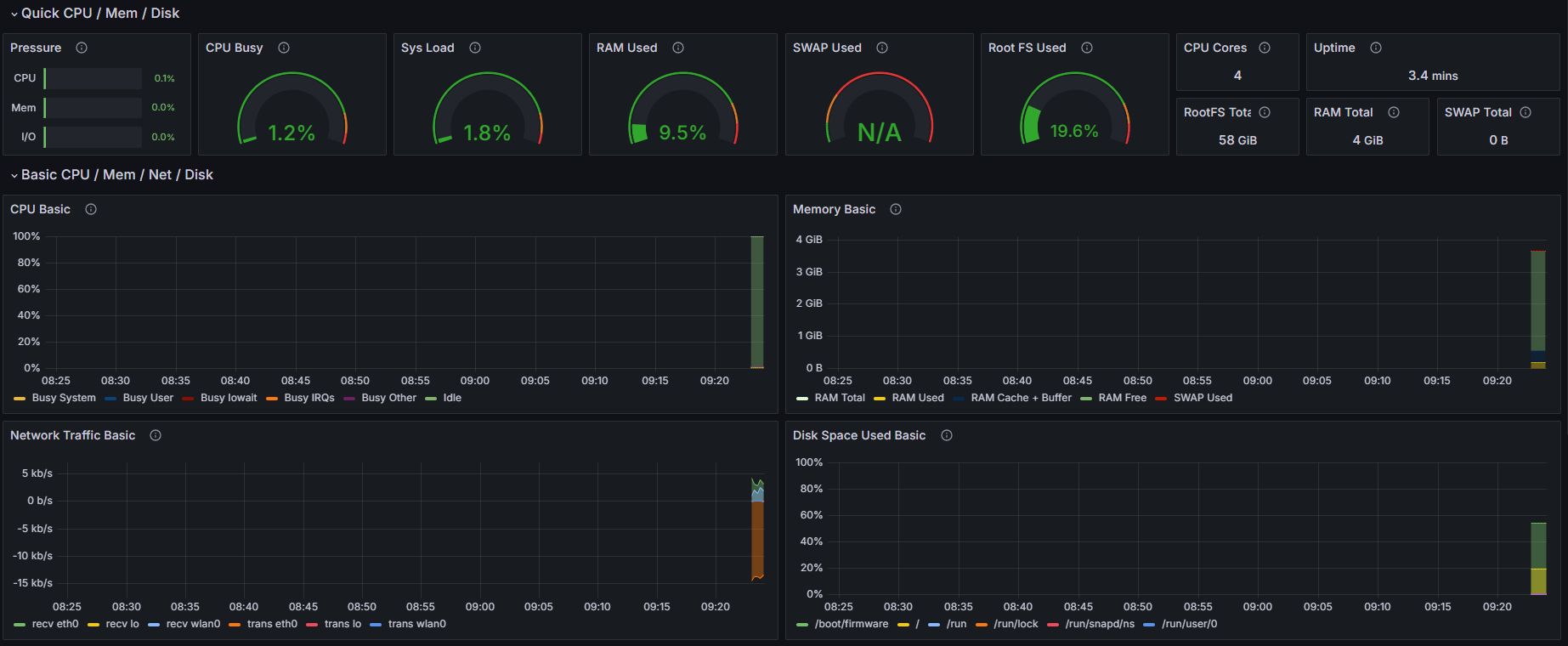
如上图所示,在未进行任何推流的情况下资源占用
开发板中仅运行了:node_exporter 用于监控开发板资源
由于是内网环境,目前下属文件配置环境中的 candidate 设置的 ip 为我局域网 ip
# main config for srs.
# @see full.conf for detail config.
listen 1935;
max_connections 1000;
#srs_log_tank file;
#srs_log_file ./objs/srs.log;
daemon on;
http_api {
enabled on;
listen 1985;
}
http_server {
enabled on;
listen 8080;
dir ./objs/nginx/html;
#这里开启了跨域允许
crossdomain on;
}
rtc_server {
enabled on;
listen 8000; # UDP port
# @see https://ossrs.net/lts/zh-cn/docs/v4/doc/webrtc#config-candidate
candidate 192.168.108.9;
}
vhost __defaultVhost__ {
enabled on;
tcp_nodelay on;
min_latency on;
hls {
#暂不适用hls,不做开启
enabled off;
}
http_remux {
enabled on;
mount [vhost]/[app]/[stream].flv;
}
rtc {
enabled on;
nack on;
rtmp_to_rtc on;
twcc on;
}
play{
gop_cache off;
queue_length 10;
mw_latency 350;
}
publish{
mr on;
mr_latency 350;
}
}
此时设备刚开机,CPU 占用~=40%,查看了一下进程,发现是自动更新了某些东西
因此等待更新完成后再做下列操作
推流前系统资源占用情况
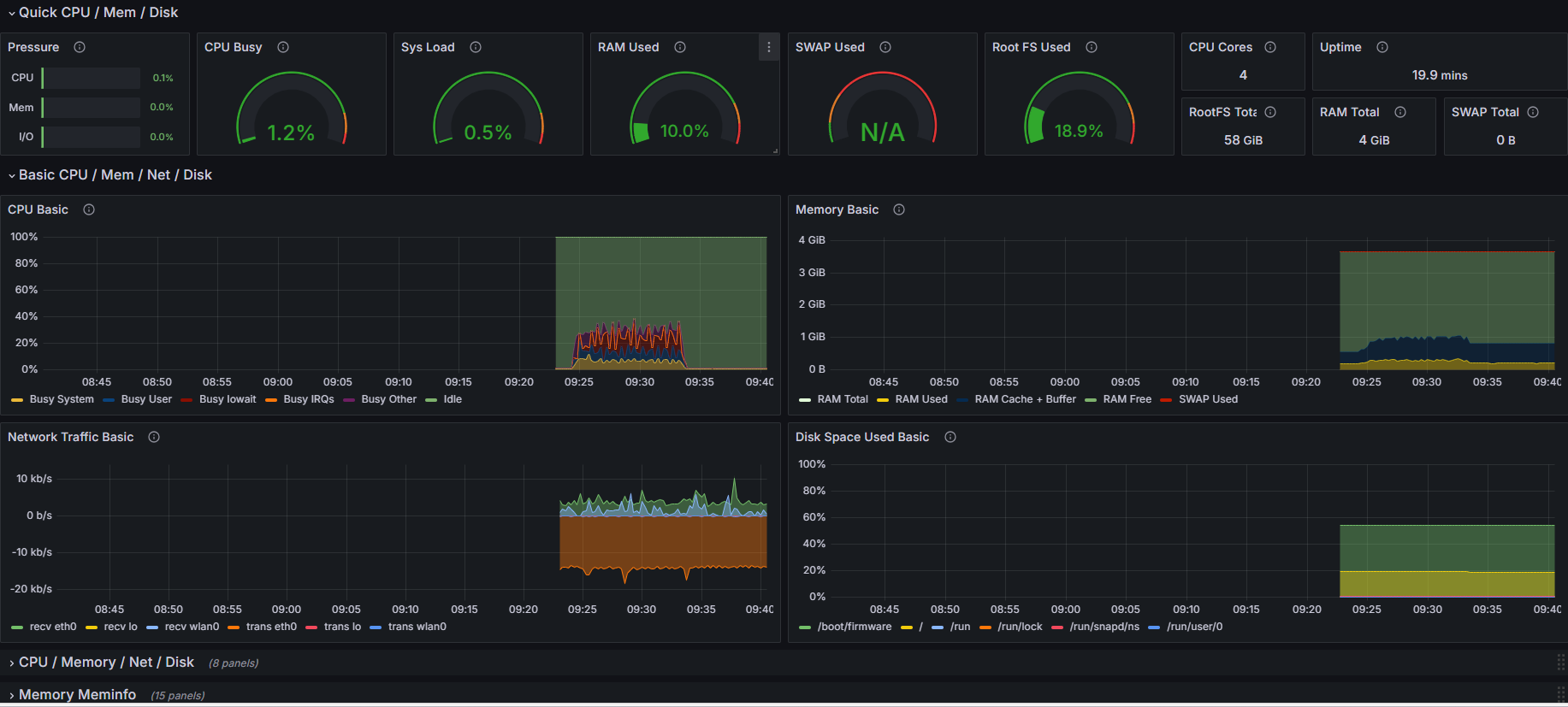
推流指令
gst-launch-1.0 -v v4l2src device=/dev/video0 ! 'video/x-h264, width=1280, height=720, framerate=30/1' ! h264parse ! flvmux ! rtmpsink location='${ip}'
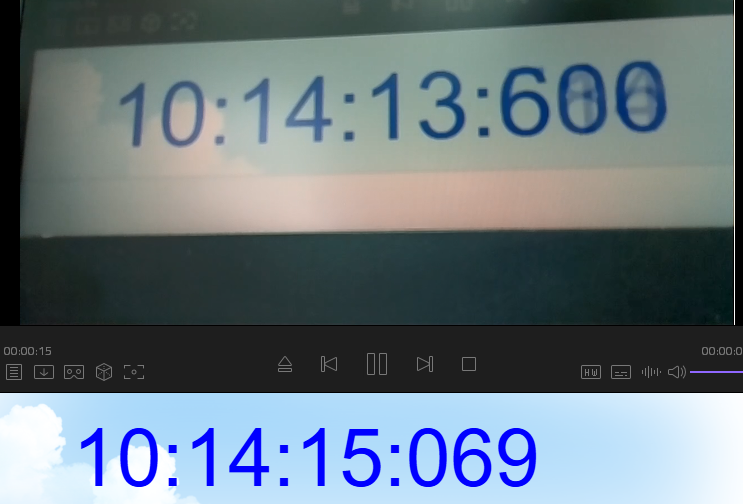
推流了大概 5 分钟后延时图
推流资源占用情况
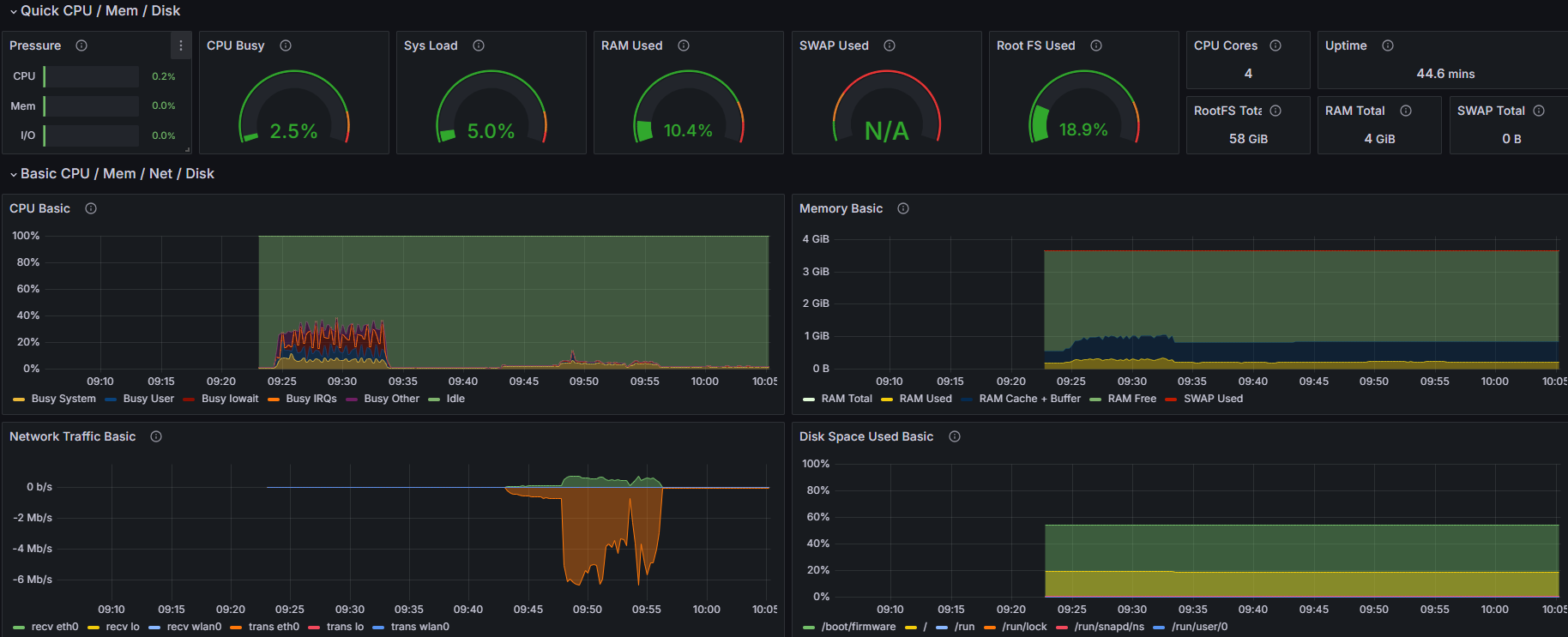
| 时机 | CPU | 内存 | 网络 |
|---|---|---|---|
| 推流前 | 1% | 10% | 0 kb/s |
| 推流后 | 2.5% | 10.3% | 60 kb/s ~ 7 Mb/s |
推流直播延时
本次推流大概使用的资源如下
总的看来,使用 GStreamer 推流时带宽使用的较为大外,资源占用情况还是比较低的
我们其实可以看到
Network Traffic Basic这一栏的波动,前一段是一个平缓的数值,突然间上涨到一个高度,然后再后续下降下来,最后呈现出一个很低的平缓直线一开始我还在好奇,怎么流量上涨了这么多?我好像也没处理什么,还以为有什么其他程序增高了这个
但后想了以下,也没开其他应用程序;
然后怀疑是
H.264传输压缩的问题, 测试了一下,当我将摄像头摆在一个画面丰富且动态变化的情况下,此时网络占用非常高;当我将摄像头盖起来(基本上处于一个黑色不变的情况下),此时网络占用几近于无(~=60 kb/s)做了这个实验其实已经证实了我的想法,
H.264编码里面会使用I帧、P帧、B帧来组成画面与减少数据体积;[1]当我们画面几乎不变时 使用
P帧和B帧编码是数据体积会很小,因此节省了很多的带宽资源。
推流前先用了 echo 3 > /proc/sys/vm/drop_caches 命令清空了 buff/cache
此时系统占用情况
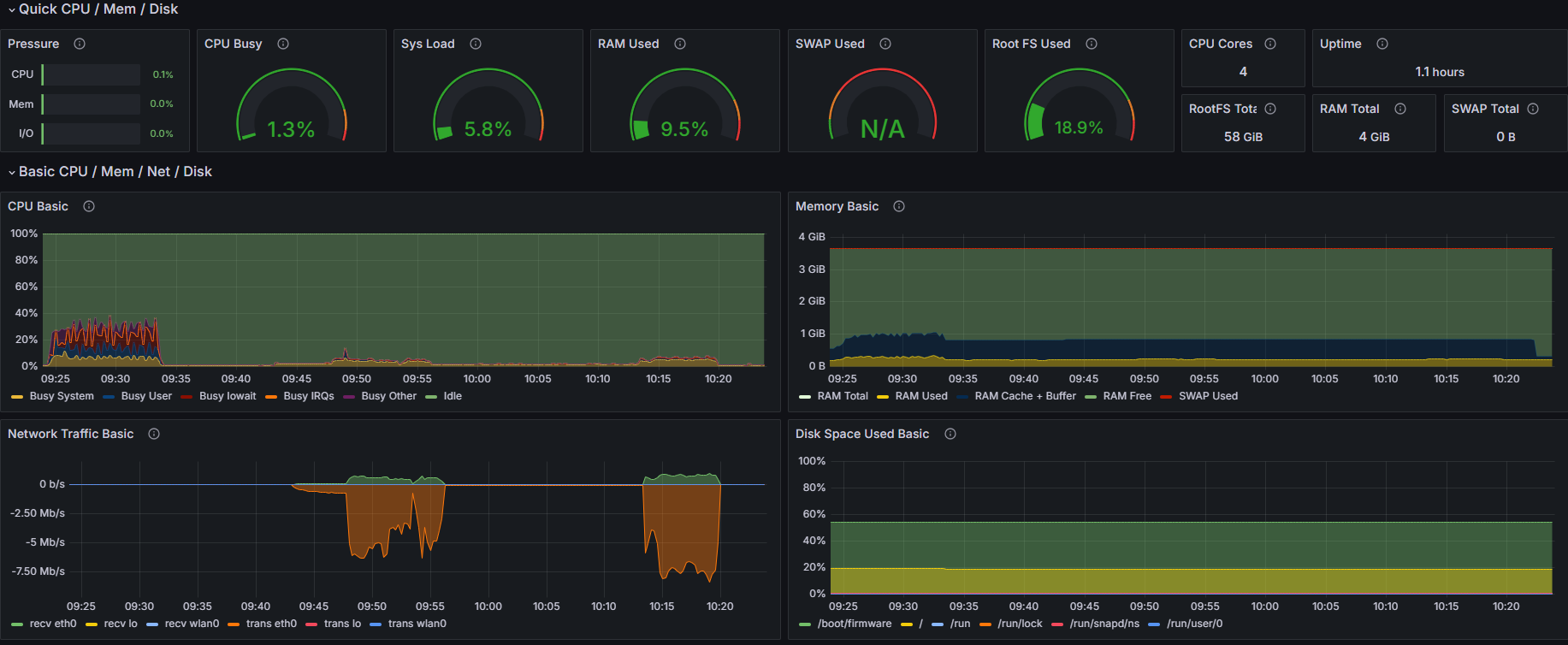
推流指令
ffmpeg -f v4l2 -framerate 30 -video_size 1280x720 -i /dev/video0 \
-c:v libx264 -preset veryfast -maxrate 1000k -bufsize 2000k -pix_fmt yuv420p \
-c:a aac -b:a 128k -ar 44100 \
-f flv ${ip}
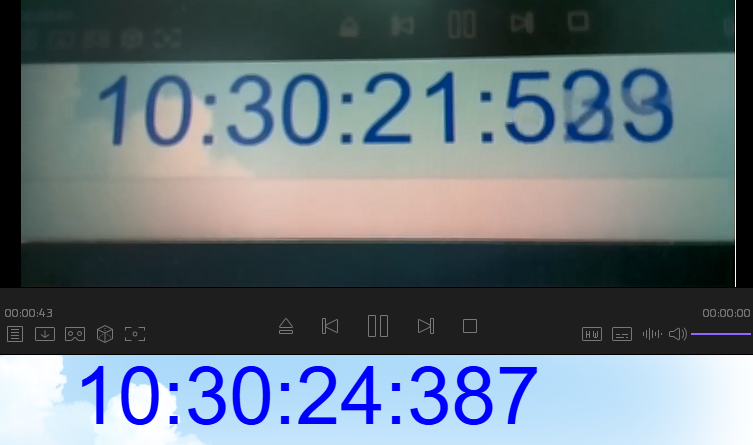
推流了大概 5 分钟后延时图
系统资源占用情况
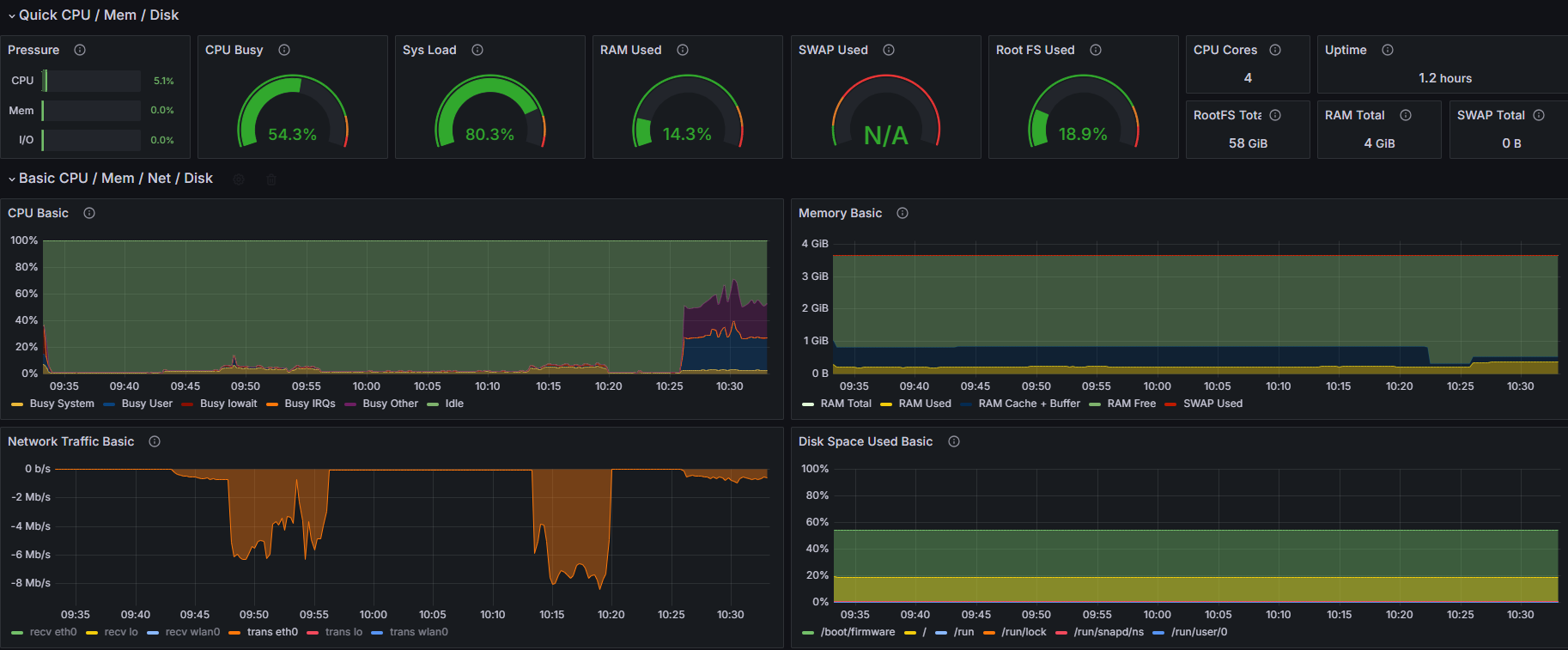
| 时机 | CPU | 内存 | 网络 |
|---|---|---|---|
| 推流前 | 1.3% | 9.5% | 0 kb/s |
| 推流后 | 58.2% | 14.3% | 600 kb/s |
推流直播延时
本次推流大概使用的资源如下
这里可以看到与 Gstreamer 推流相比,FFmpeg 推流下系统资源占用,延时等明显上升了一个台阶,但是带宽稳定在 600 kb/s
这里应该是对整个视频流进行了压缩处理导致需要较多的 CPU 资源与 内存占用(目前还没熟悉 FFmpeg 的相关参数,后续对其学习后整理相关的文档在过来重新分析对此进行分析)
| 推流方式 | 延时 | CPU 占用 | 内存占用 | 带宽占用 |
|---|---|---|---|---|
| GStreamer | 1.3s | 1.5% | ~=3M | 60 kb/s ~ 7 Mb/s(具体看画面变化) |
| FFmpeg | 3s | 58% | ~=140M | 600 kb/s |
上面的总结测试并不完整与科学;明显能得出的是 FFmpeg 应该会去压缩画面从而减少带宽,但与之相对应的是系统资源的占用提升;目前由于我们第一要义是选择资源占用小的,延时低的,暂时先选择用 GStreamer 来进行推流;(欢迎各位大佬来帮忙解答这部分)
由于推流在方案一里已经做了对比效果,因此本方案只使用 GStreamer 进行推流;然后只针对于 HTTP-FLV 拉流的方式进行查看延时效果
拉流效果图

总的来说效果还是出乎我的意料的;看上去延时不是特别高,而且最主要还能直接通过浏览器进行播放;
由于推流在方案一里已经做了对比效果,因此本方案只使用 GStreamer 进行推流;然后只针对于 WebRTC 拉流的方式进行查看延时效果
拉流效果图

这个局域网拉流的实际效果已经非常不错了,基本上可以算是一个比较实时的反馈了。当然其实 WebRTC 还是一个比较庞大且复杂的东西,里面还需要我更深入的去研究才能做出更好的选择。
| 推流方式 | 拉流方式 | 延时 | 备注 |
|---|---|---|---|
| GStreamer - RTMP | KMPlayer - RTMP | 1.3s | 资推流资源占用较低,但拉流时间较高 |
| FFmpeg - RTMP | KMPlayer - RTMP | 3s | 资源占用较高, |
| GStreamer - RTMP | HTTP-FLV | 1s | 效果还行,普通的低延时场景够用,如果做远程控制则还是不太足够 |
| GStreamer - RTMP | WebRTC | 200ms | 效果不错,但挪到公网上还有待考究 |
最后的总结:
如果双端都能做到走 WebRTC 的方案,延时会更小更稳定一些吧;
如果是普通场景,我觉得我去先择 RTMP + HTTP-FLV 已经十分足够了,但是目前需要做远程控制,而且还需要做到外网控制的话, WebRTC 是一个不错的选择。
当然,本次实验的过程其实可以说是漏洞百出,例如:
# Docker run Prometheus
docker run -itd -p 9090:9090 --name promethues prom/prometheus
# Docker run Grafana
docker run -d --name grafana -p 3000:3000 grafana/grafana-enterprise
https://stackoverflow.com/questions/70655928/live-streaming-from-raspberry-pi-to-nodejs-server-hosted-on-google-app-engine/70675353#70675353
https://opensource.com/article/19/1/gstreamer
https://github.com/ossrs/srs/issues/2304
http://www.riqicha.com/beijingshijian.html