
大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」
高斯过程算法是一种强大的非参数机器学习方法,广泛应用于回归、分类和优化等任务中。其核心思想是利用高斯分布来描述数据的分布,通过核函数来度量数据之间的相似性。与传统的机器学习方法相比,高斯过程在处理小样本数据和不确定性估计方面具有独特的优势。
接下来,我们将详细探讨高斯过程的基本原理、数学表述及其在机器学习中的应用,并提供相关的代码示范和实际案例分析。

1.1 高斯过程定义
高斯过程是一种用于定义数据分布的概率模型。其核心在于任意数量的随机变量的集合中,每个子集的联合分布都是多元正态分布。通俗来讲,高斯过程是一种“函数的分布”,用来描述函数值在给定输入下的可能取值。
1.2 高斯过程的核心思想
高斯过程通过核函数来度量数据点之间的相似性。核函数不仅决定了数据点之间的相互关系,还影响了整个高斯过程模型的平滑性和复杂性。常用的核函数包括线性核、径向基核(RBF核)和多项式核。
1.3 高斯过程与正态分布的关系
高斯过程是由多元正态分布推广而来的。在高斯过程中,每个数据点都可以看作是一个多元正态分布的一部分,其均值和协方差由核函数决定。因此,高斯过程具有与正态分布相同的优良性质,如平稳性和解析性。
更多分布见微*公号往期文章:数据科学家 95% 时间都在使用的 10 大基本分布
95% 数据科学家都在使用,确定数据分布正态性 10 大方法,附 Python 代码
1.4 高斯过程的优点
高斯过程在处理小样本数据和不确定性估计方面具有独特的优势:
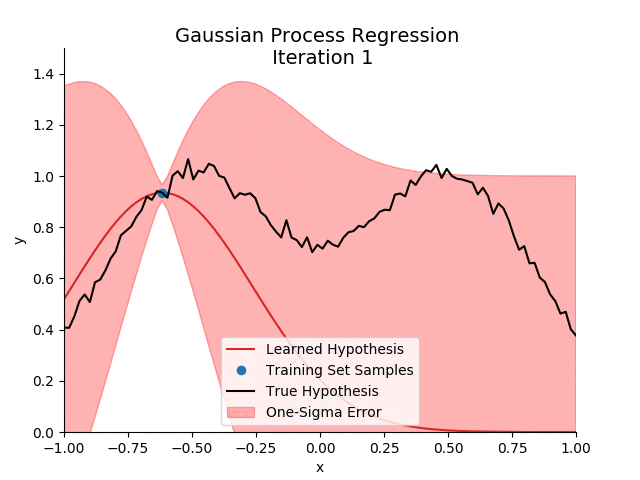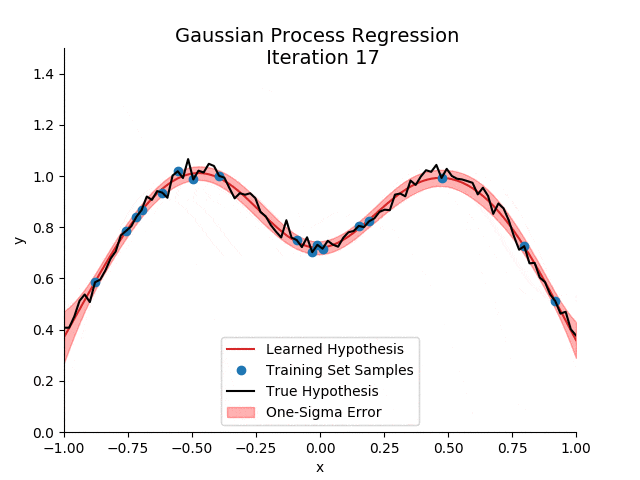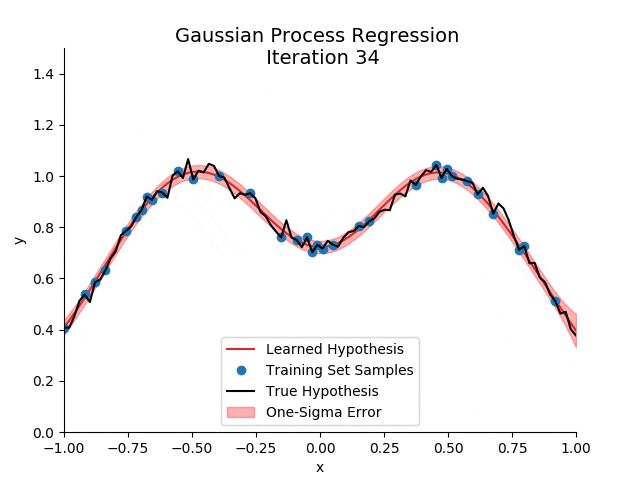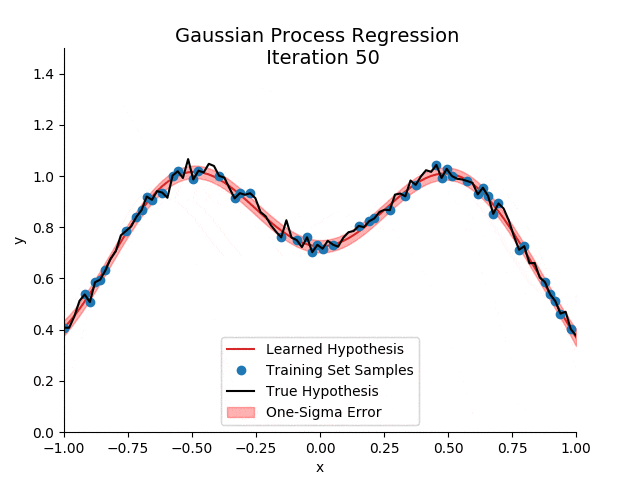
不想脑瓜疼的铁子,可以考虑跳过这一部分
2.1 核函数的定义与作用
在高斯过程模型中,核函数(或称为协方差函数)是关键组成部分。它用于度量数据点之间的相似性。常见的核函数包括:
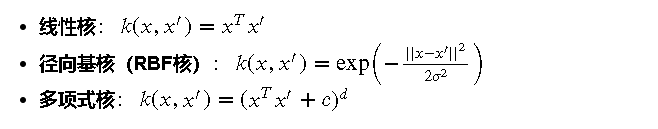
核函数的选择对高斯过程的性能有显著影响,不同的核函数能够捕捉数据的不同特性。
2.2 协方差函数
协方差函数 𝑘(𝑥,𝑥′)描述了两个输入点 𝑥 和 𝑥′ 之间的相关性。给定输入数据 𝑋={𝑥1,𝑥2,…,𝑥𝑛},我们可以构建协方差矩阵 𝐾,其元素为 𝐾𝑖𝑗=𝑘(𝑥𝑖,𝑥𝑗)。这个协方差矩阵用于确定高斯过程的平滑性和复杂性。
2.3 高斯过程的先验和后验分布
在高斯过程中,先验分布和后验分布是两个重要概念:

3.1 优点
高斯过程在机器学习中具有以下优点:
3.2 缺点
尽管高斯过程有许多优点,但也存在一些缺点:
3.3 高斯过程与其他机器学习方法的比较
与其他常见的机器学习方法相比,高斯过程具有以下特点:
更多分布见微*公号往期文章:十大回归算法 ,支持向量机 SVM , 决策树算法,随机森林, 神经网络

添加图片注释,不超过 140 字(可选)
4.1 稀疏高斯过程
高斯过程模型的一个主要缺点是其计算复杂度随着数据量的增加而迅速增长。稀疏高斯过程(Sparse Gaussian Processes, SGP)通过引入一组少量的诱导点来近似完整数据集,从而显著降低计算复杂度。稀疏高斯过程的方法包括:
稀疏高斯过程能够在保证模型性能的同时,大幅降低计算和存储需求,非常适合大规模数据集的应用。
4.2 非平稳高斯过程
标准高斯过程假设数据的协方差结构是平稳的,即核函数参数在整个数据空间内是固定的。然而,许多实际问题中,数据的协方差结构可能随空间或时间变化。非平稳高斯过程(Non-stationary Gaussian Processes, NSGP)通过引入位置或时间依赖的核函数参数来建模这种变化。
常见的非平稳高斯过程模型包括:
非平稳高斯过程能够更灵活地适应实际数据的复杂特性,提高模型的预测准确性。
4.3 多任务高斯过程
多任务高斯过程(Multi-task Gaussian Processes, MTGP)扩展了标准高斯过程,能够同时处理多个相关任务。其核心思想是通过共享协方差结构来捕捉不同任务之间的相关性。
多任务高斯过程的典型应用包括:
多任务高斯过程不仅能够提高单个任务的预测性能,还能有效利用不同任务之间的相互信息,提高整体模型的鲁棒性和准确性。
代码示例及可视化
我们生成一个包含 30 天数据的小规模数据集,其中包括武林高手的功力、武器熟练度以及战斗胜率。接下来,我们使用高斯过程回归模型对战斗胜率进行建模和预测。
数据集生成
数据生成代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF, ConstantKernel as C
# 生成数据集
np.random.seed(42)
days = np.arange(1, 31)
power = 50 + 0.5 * days + np.random.normal(0, 5, len(days))
weapon_skill = 50 + 0.3 * days + np.random.normal(0, 5, len(days))
battle_win_rate = 0.3 * power + 0.7 * weapon_skill + np.random.normal(0, 5, len(days))
data = pd.DataFrame({
'天数': days,
'功力': power,
'武器熟练度': weapon_skill,
'战斗胜率': battle_win_rate
})
# 提取特征和目标变量
X = data[['天数']].values
y = data['战斗胜率'].values
复制模型训练和预测
定义高斯过程回归模型并进行训练和预测:
# 定义高斯过程回归模型
kernel = C(1.0, (1e-3, 1e3)) * RBF(1.0, (1e-2, 1e2))
gp = GaussianProcessRegressor(kernel=kernel, n_restarts_optimizer=10)
# 训练模型
gp.fit(X, y)
# 生成一组测试数据
X_test = np.linspace(1, 30, 100).reshape(-1, 1)
# 预测战斗胜率
y_pred, sigma = gp.predict(X_test, return_std=True)
复制结果可视化
绘制拟合曲线和不确定性范围:
# 绘制拟合曲线和不确定性
plt.figure(figsize=(10, 6))
plt.scatter(X, y, c='b', label='实际战斗胜率')
plt.plot(X_test, y_pred, 'r', label='预测战斗胜率')
plt.fill_between(X_test.flatten(), y_pred - 1.96 * sigma, y_pred + 1.96 * sigma, alpha=0.2, color='darkorange', label='95% 置信区间')
plt.xlabel('天数')
plt.ylabel('战斗胜率')
plt.title('高斯过程回归预测战斗胜率')
plt.legend()
plt.show()
复制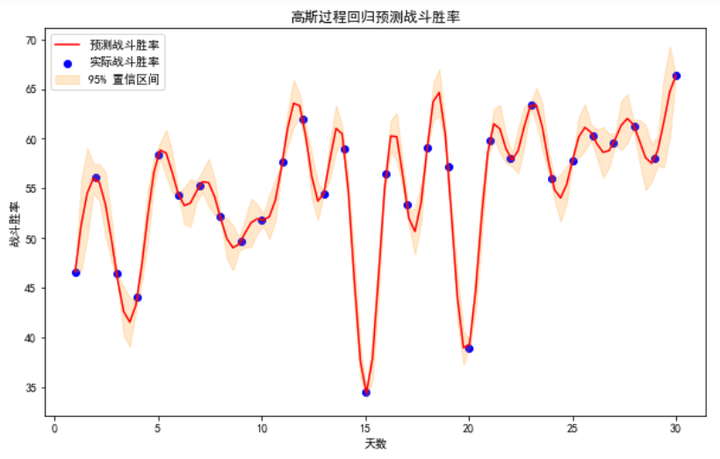
解说可视化结果
在上述可视化结果中,我们可以观察到以下几点:
我们展示了高斯过程回归模型在预测战斗胜率方面的应用。模型能够较好地拟合数据,并提供置信区间以表示预测的不确定性。
每天一个简单通透的小案例,如果你对类似于这样的文章感兴趣。
欢迎关注、点赞、转发~

希望本文能够帮助大侠们更好地理解和应用高斯过程算法,提高在实际问题中的分析和预测能力。
- 科研为国分忧,创新与民造福 -

日更时间紧任务急,难免有疏漏之处,还请大侠海涵 内容仅供学习交流之用,部分素材来自网络,侵联删
如果觉得内容有价值,烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖