在数据库性能调优的实践中,SQL性能分析是至关重要的一环。一个执行效率低下的SQL语句可能会导致整个系统的性能瓶颈。
为了快速定位并解决这些问题,我们需要对SQL进行性能分析。本文将介绍一些常用的方法和技术,帮助大家快速定位SQL问题。
首先,我们需要找到执行时间最长的SQL。这可以通过查询数据库的性能数据来实现。
1.1 使用SHOW PROCESSLIST
例如,在MySQL中,我们可以使用SHOW PROCESSLIST命令来查看当前正在执行的所有SQL语句及其执行时间。通过筛选出执行时间最长的SQL,我们可以快速定位到可能存在性能问题的SQL。
当然如果上述命令无法直观满足你的需求,你也可以通过下述查询语句,找出执行时间最长的SQL。
select * from information_schema.processlist where Command<>'Sleep' order by time desc ;
复制一般情况下,我们关注查询出来的第一条数据。其执行时间超过30s,表示存在性能问题。
如果有很多执行时间长的SQL,并且这些SQL执行的时间都比较接近,一般是因为第一条sql导致数据库阻塞。临时办法是kill掉这个SQL请求,例如kill 285380,最终解决办法是对这个SQL分析优化,不然问题还是会反复出现。
1.2 慢查询日志
开启MySQL的慢查询日志(slow query log)功能,可以记录执行时间超过指定阈值的SQL语句。通过分析慢查询日志,我们可以找到执行时间较长的SQL,并对其进行优化。
开启慢查询日志:
在MySQL的配置文件(如my.cnf或my.ini)中添加或修改以下行来开启慢查询日志,并设置阈值为1秒:
slow_query_log = 1
slow_query_log_file = /var/log/mysql/slow.log
long_query_time = 1
复制重启MySQL服务使更改生效。
分析慢查询日志:
使用mysqldumpslow工具来查看慢查询日志中最慢的查询。例如,查看最慢的10条查询并按执行时间排序:
mysqldumpslow -s t -t 10 /var/log/mysql/slow.log
复制输出将显示类似以下的结果:
Count: 10 Time=12.34s (123s) Lock=0.00s (0s) Rows=100000, ... SELECT ... WHERE ... ORDER BY ... LIMIT ...
复制如果是在Oracle数据库中,可以使用v$sql视图来查询执行时间最长的SQL语句:
SELECT *
FROM (
SELECT sql_id, executions, elapsed_time/1e6 as elapsed_sec,
ROUND(elapsed_time/executions) as avg_time_per_exec,
sql_text
FROM v$sql
WHERE executions > 0
ORDER BY elapsed_time DESC
)
WHERE ROWNUM <= 10;
复制有时候,多个相似的SQL语句同时执行可能会导致性能问题。为了找出这些同类型的并发SQL,我们可以使用数据库的监控工具。例如,在MySQL中,我们可以使用Performance Schema来监控SQL语句的执行情况。或者也可以使用(Percona Monitoring and Management, PMM),实时查看当前正在执行的SQL语句及其并发情况。
假设,我们使用Percona Monitoring and Management (PMM)工具,我们可以在图形化界面中查看当前正在执行的SQL语句及其并发情况。PMM通常会提供SQL执行时间、等待锁的时间、执行计划等详细信息,帮助我们快速识别同类型并发SQL。
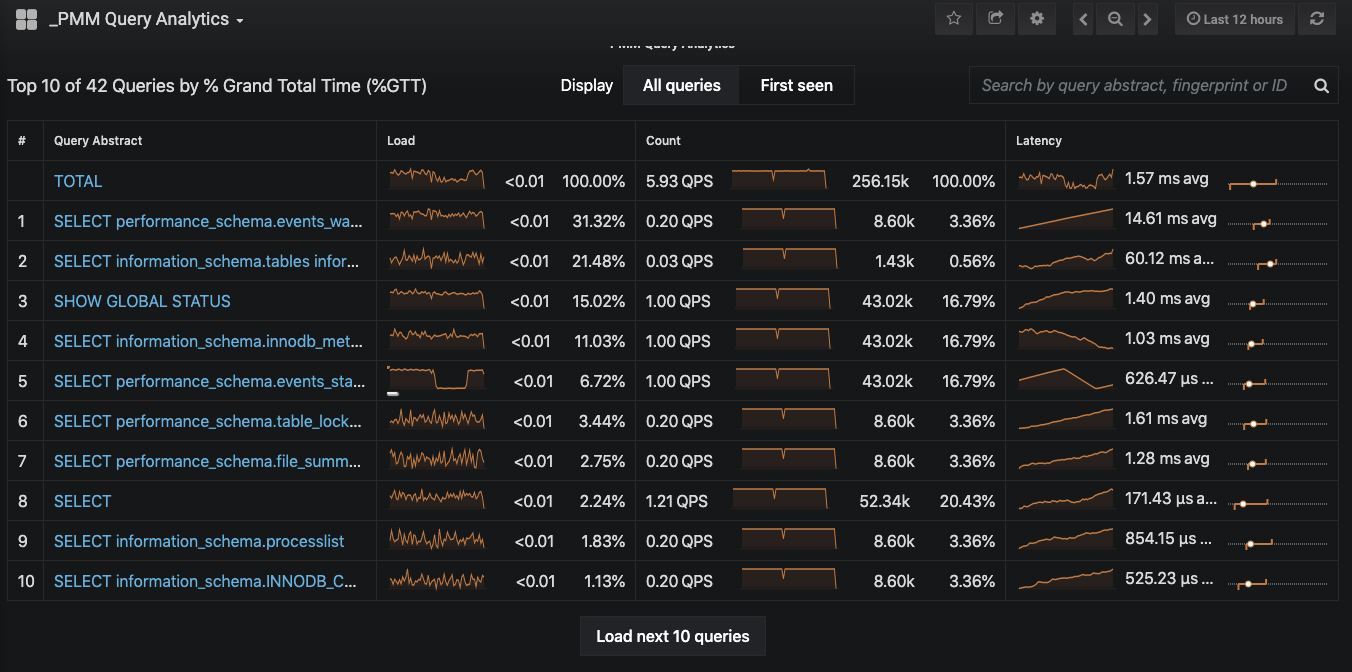
通过分析这些数据,我们可以找出同类型的并发SQL,从而进一步定位问题。
在某些情况下,一个SQL语句可能会阻塞其他SQL语句的执行。为了找出这些阻塞和被阻塞的SQL,我们可以使用数据库的锁等待信息。通过分析这些信息,我们可以找到阻塞和被阻塞的SQL,从而解决性能问题。
3.1 使用SHOW ENGINE INNODB STATUS
在MySQL的InnoDB存储引擎中,可以运行以下命令查看锁等待和阻塞情况:
SHOW ENGINE INNODB STATUS\G
复制在输出中搜索“LATEST DETECTED DEADLOCK”或“LATEST FOREIGN KEY ERROR”等关键词,找到锁等待和死锁的详细信息。
3.2 监控工具
一些数据库监控工具提供了图形化界面来展示锁等待情况,方便我们快速定位阻塞和被阻塞的SQL。
4.1 锁等待
当某个事务尝试访问一个被其他事务锁定的资源时,它会被阻塞并等待锁的释放。长时间的锁等待会导致性能问题。为了避免这种情况,我们应该尽量减少锁的持有时间,优化事务逻辑,并合理使用索引。
4.2 死锁
死锁是两个或多个事务相互等待对方释放资源的一种情况。当发生死锁时,系统性能会急剧下降。为了解决死锁问题,我们可以使用SHOW ENGINE INNODB STATUS命令来分析死锁的原因,并调整事务的执行顺序或优化数据库设计。
锁等待和死锁是数据库性能问题的常见原因。为了找出这些问题,我们可以使用数据库的锁等待信息和死锁日志。例如,在MySQL中,我们可以使用SHOW ENGINE INNODB STATUS命令来查看当前的锁等待情况,以及SHOW ENGINE INNODB STATUS LIKE '%deadlock%'命令来查看死锁日志。
在SHOW ENGINE INNODB STATUS的输出中,找到“TRANSACTIONS”部分,并查看其中的“LOCK WAIT”和“RUNNING”事务。特别是关注“LOCK WAIT”事务的“Waiting for this lock to be granted”部分,这通常会告诉我们哪个事务正在等待锁,以及哪个事务持有这个锁。
慢查询日志是数据库性能调优的重要资源。通过分析慢查询日志,我们可以找到执行效率较低的SQL语句,并对其进行优化。以下是一些慢日志分析的常用方法:
5.1 排序和筛选
对慢查询日志进行排序和筛选,找到执行时间最长、调用次数最多的SQL语句。
5.2 使用EXPLAIN
对于从慢查询日志中找到的SQL语句,我们可以使用EXPLAIN命令来分析其执行计划:
EXPLAIN SELECT ... WHERE ... ORDER BY ... LIMIT ...;
复制5.3 优化SQL语句
根据EXPLAIN的输出结果,对SQL语句进行优化,如添加缺失的索引、调整查询条件、优化连接顺序等。
本文介绍了如何快速定位SQL性能问题的方法,包括找出执行时间最长的SQL、同类型并发SQL、阻塞和被阻塞SQL、锁等待和死锁,以及慢日志分析。在实际应用中,我们应该根据具体情况选择合适的方法来定位和解决SQL性能问题。同时,我们也应该关注数据库的设计和运维,确保数据库的高效运行。