Yolov(2015年华盛顿大学的 Joseph Redmon 和 Ali Farhadi 发布)
Yolov2(2016年Joseph Redmon发布)
Yolov3(2018年Joseph Redmon发布)
Yolov4(2020年Alexey Bochkovskiy发布)
Yolov5(2018年Glen Jocher发布)
Yolov6(2022年美团团队发布)
Yolov7(2022年WongKinYiu发布)
Yolov8(2023年Ultralytics发布)
Yolov9(2023年发布)
Yolov10(2024年清华大学团队发布)
其中Yolov10是刚刚2024年5月底才刚发布的,其中v10实现了一个无NMS的架构,具有一致的双重分配,显著减少了后处理时间,并改善了整体延迟,让后处理变得更简单很多。
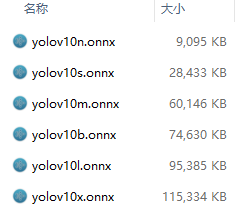
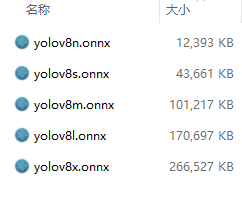
模型支持导出成静态模型和动态模型,静态模型是[1,3,640,640],要求宽高符合32对齐。
动态模型则没有要求,其中v8的动态模型会随着输入尺寸不同,输出的尺寸会跟着变化。
而v10输入尺寸无论怎样,输出的尺寸都是固定的[1,300,6]。
我已将动态静态两种处理方式都融合在一份代码上,根据加载后的模型推理后的输出长度是否等于1800来判断是否是v10,均可在其内部进行处理。
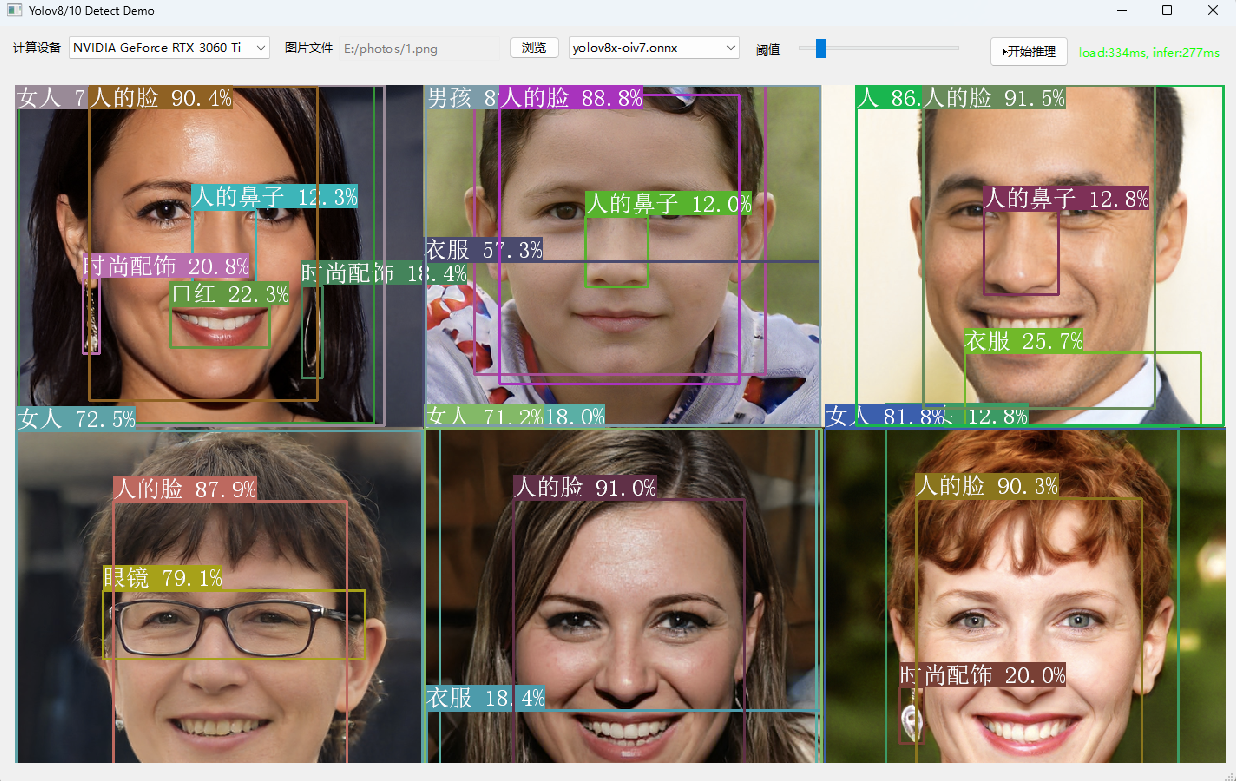
Yolov8的后处理代码:
std::vector<YoloResult> filterYolov8Detections( float* inputs, float confidence_threshold, int num_channels, int num_anchors, int num_labels, int infer_img_width, int infer_img_height ) { std::vector<YoloResult> detections; cv::Mat output = cv::Mat((int)num_channels, (int)num_anchors, CV_32F, inputs).t(); for (int i = 0; i < num_anchors; i++) { auto row_ptr = output.row(i).ptr<float>(); auto bboxes_ptr = row_ptr; auto scores_ptr = row_ptr + 4; auto max_s_ptr = std::max_element(scores_ptr, scores_ptr + num_labels); float score = *max_s_ptr; if (score > confidence_threshold) { float x = *bboxes_ptr++; float y = *bboxes_ptr++; float w = *bboxes_ptr++; float h = *bboxes_ptr; float x0 = std::clamp((x - 0.5f * w), 0.f, (float)infer_img_width); float y0 = std::clamp((y - 0.5f * h), 0.f, (float)infer_img_height); float x1 = std::clamp((x + 0.5f * w), 0.f, (float)infer_img_width); float y1 = std::clamp((y + 0.5f * h), 0.f, (float)infer_img_height); cv::Rect_<float> bbox; bbox.x = x0; bbox.y = y0; bbox.width = x1 - x0; bbox.height = y1 - y0; YoloResult object; object.object_id = max_s_ptr - scores_ptr; object.score = score; object.box = bbox; detections.emplace_back(object); } } return detections; }
Yolov10的后处理代码:
std::vector<YoloResult> filterYolov10Detections( const std::vector<float> &inputs, float confidence_threshold) { std::vector<YoloResult> detections; const int num_detections = inputs.size() / 6; for (int i = 0; i < num_detections; ++i) { float left = inputs[i * 6 + 0]; float top = inputs[i * 6 + 1]; float right = inputs[i * 6 + 2]; float bottom = inputs[i * 6 + 3]; float confidence = inputs[i * 6 + 4]; int class_id = inputs[i * 6 + 5]; if (confidence >= confidence_threshold) { cv::Rect_<float> bbox; bbox.x = left; bbox.y = top; bbox.width = right - left; bbox.height = bottom - top; detections.push_back({class_id, confidence, bbox}); } } return detections; }