学过正交化,如何设立开发集和测试集,用人类水平错误率来估计贝叶斯错误率以及如何估计可避免偏差和方差。现在把它们全部组合起来写成一套指导方针,如何提高学习算法性能的指导方针。

所以想要让一个监督学习算法达到实用,基本上希望或者假设可以完成两件事情。首先,的算法对训练集的拟合很好,这可以看成是能做到可避免偏差很低。还有第二件事可以做好的是,在训练集中做得很好,然后推广到开发集和测试集也很好,这就是说方差不是太大。
在正交化的精神下,可以看到这里有第二组旋钮,可以修正可避免偏差问题,比如训练更大的网络或者训练更久。还有一套独立的技巧可以用来处理方差问题,比如正则化或者收集更多训练数据。
总结一下前面博客见到的步骤,如果想提升机器学习系统的性能,建议看看训练错误率和贝叶斯错误率估计值之间的距离,让知道可避免偏差有多大。换句话说,就是觉得还能做多好,对训练集的优化还有多少空间。然后看看的开发错误率和训练错误率之间的距离,就知道的方差问题有多大。换句话说,应该做多少努力让的算法表现能够从训练集推广到开发集,算法是没有在开发集上训练的。
如果想用尽一切办法减少可避免偏差,建议试试这样的策略:比如使用规模更大的模型,这样算法在训练集上的表现会更好,或者训练更久。使用更好的优化算法,比如说加入momentum或者RMSprop,或者使用更好的算法,比如Adam。还可以试试寻找更好的新神经网络架构,或者说更好的超参数。这些手段包罗万有,可以改变激活函数,改变层数或者隐藏单位数,虽然这么做可能会让模型规模变大。或者试用其他模型,其他架构,如循环神经网络和卷积神经网络。新的神经网络架构能否更好地拟合的训练集,有时也很难预先判断,但有时换架构可能会得到好得多的结果。
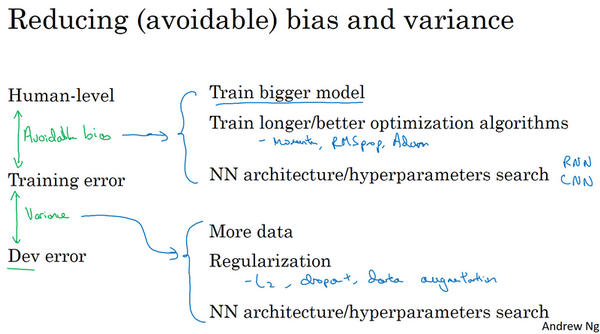
另外当发现方差是个问题时,可以试用很多技巧,包括以下这些:可以收集更多数据,因为收集更多数据去训练可以帮更好地推广到系统看不到的开发集数据。可以尝试正则化,包括\(L2\)正则化,dropout正则化或者在之前博客中提到的数据增强。同时也可以试用不同的神经网络架构,超参数搜索,看看能不能帮助,找到一个更适合的问题的神经网络架构。
想这些偏差、可避免偏差和方差的概念是容易上手,难以精通的。如果能系统全面地应用本系列博客里的概念,实际上会比很多现有的机器学习团队更有效率、更系统、更有策略地系统提高机器学习系统的性能。