在我们使用SD web UI的过程中,有很多采样器可以选择,那么什么是采样器?它们是如何工作的?它们之间有什么区别?你应该使用哪一个?这篇文章将会给你想要的答案。
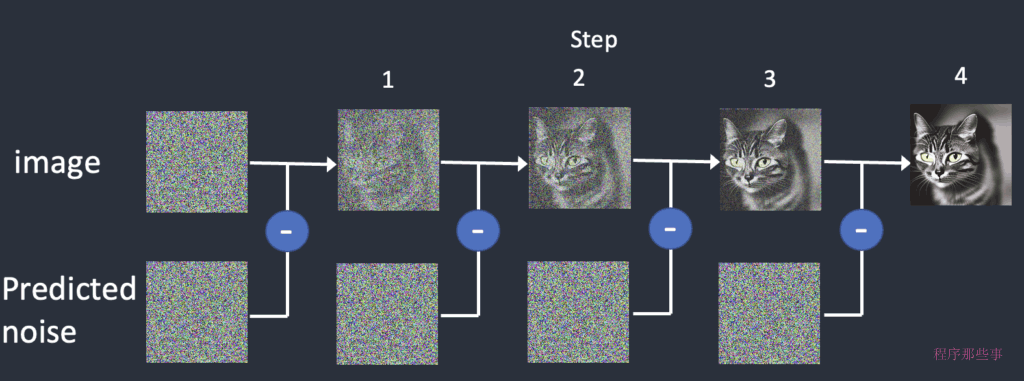
Stable Diffusion模型通过一种称为“去噪”的过程来生成图像,这个过程涉及到在潜在空间中逐步从随机噪声中提取出有意义的图像特征。
下面是一个实际的采样过程。采样器逐渐产生越来越干净的图像。

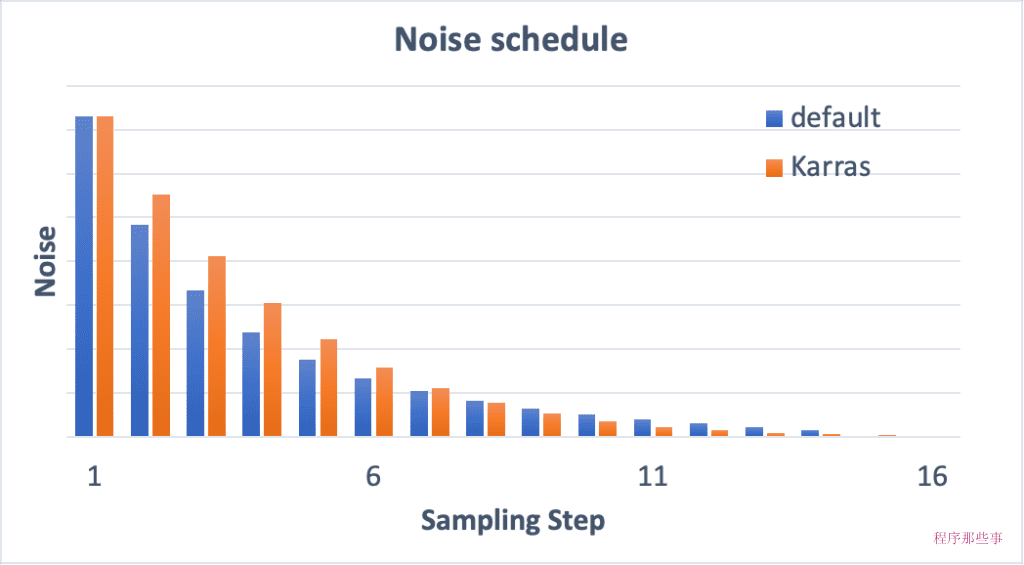
在Stable Diffusion模型的去噪过程中,噪声表(noise schedule)扮演着至关重要的角色。
噪声表是一个预先定义的计划,它决定了在每一步采样过程中应用的噪声水平。
下面是一个Noise schedule的基本工作原理:
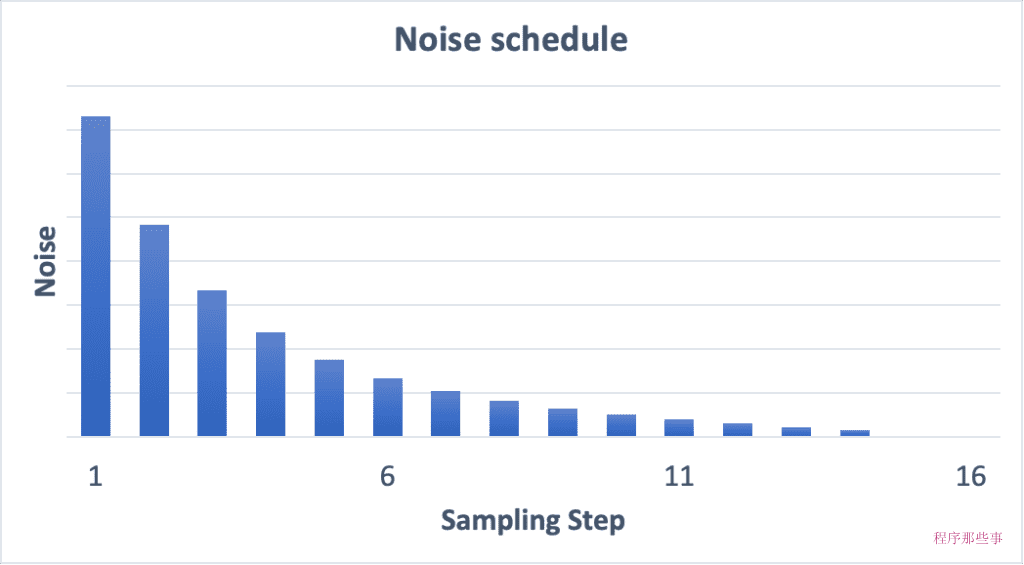
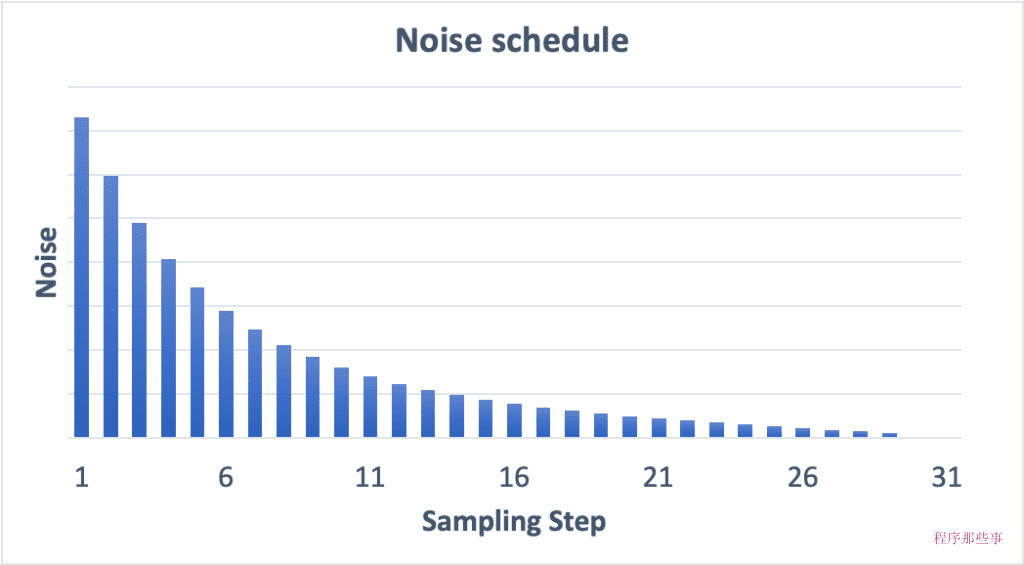
如果我们增加采样步骤数,那么每个步骤之间的降噪幅将会变小。这有助于减少采样的截断误差。
可以比较一下 15 个步骤和 30 个步骤的噪音时间表。
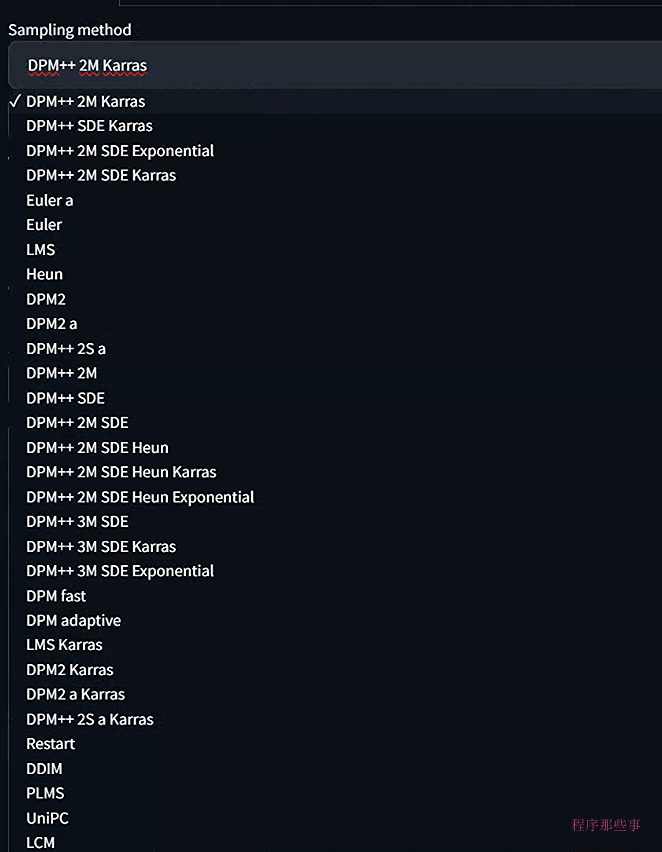
webUI自带了很多不同的采样器,并且这个采样器的个数还在不停的增加,那么这些采样器都有些什么不同呢?
让我们看一下最简单采样器。这些采样器算法已经被发明很久很久了。它们是常微分方程 (ODE) 的老式采样器。
Euler– 最简单的采样器。
Heun– 更准确但更慢的 Euler 版本。
LMS(线性多步法) – 与 Euler 的速度相同,但(据说)更准确。
如果你注意观察的话,可以看到某些采样器的名称上带有一个字母'a'。 比如:
Euler a
DPM2 a
DPM++ 2S a
DPM++ 2S a Karras
他们是Ancestral采样器。Ancestral采样器在每个采样步骤中都会向图像添加噪声。它们是随机采样器,因为采样结果具有一定的随机性。
当然也有很多随机采样器的名字上是不带a的。
使用Ancestral采样器的缺点是图像不会收敛。也就是说你有可能不会得到相同的结果。
还是刚刚的例子,我们比较一下使用 Euler a 和 Euler 生成的图像。(为了便于对比,我们加入了另外一个收敛的采样器)

可以看到Euler和DMP++ 2M Karras最终生成的图片其实是大致一样的,但是他们两个跟Euler a的结果不太相同。
所以为了可重复性,那就用收敛采样器。如果要生成细微的变化,那么可以考虑使用随机采样器。
带有“Karras”标签的采样器使用 Karras 文章中推荐的 noise schedule。和传统的采样器相比,你会发现噪声步长在接近尾声时变小了。这样的变化据说可以提高图像的质量。
DDIM(去噪扩散隐式模型)和 PLMS(伪线性多步法)是原始 Stable Diffusion v1 附带的采样器。DDIM是首批为扩散模型设计的采样器之一。PLMS 是 DDIM 的更新、更快的替代方案。
这两个采样器已经过时了,我们通常不会使用他们。
DPM(扩散概率模型求解器)和 DPM++ 是专为 2022 年发布的扩散模型设计的新采样器。它们表示具有类似体系结构的求解器系列。DPM 和 DPM2 相似,但 DPM2 是二阶的(更准确但更慢)。DPM++ 是对 DPM 的改进。
DPM adaptive是自适应调整步长。所以它可能很慢,并且不能保证在采样步骤数内完成。
UniPC(统一预测器校正器)是 2023 年发布的新采样器。受常微分方程求解器中预测变量-校正器方法的启发,它可以在 5-10 个步骤内实现高质量的图像生成。
那么这么多的采样器,我们应该如何选择呢?我想我们可以从采样算法是否收敛,采样的速度和最终生成图片的质量这几个方面来具体考量需要使用什么样的采样器。
首先,对Euler、DDIM、PLMS、LMS Karras 和 Heun这些老式的常微分方程求解器或原始扩散求解器来说,PLMS和LMS Karras收敛效果不佳。Heun收敛得更快。
对于所有的Ancestral采样器来说,都是不收敛的。这些采样器有:Euler a, DPM2 a, DPM++ 2S a, DPM2 a Karras, DPM++ 2S a Karras。
DPM++ SDE 和 DPM++ SDE Karras 与Ancestral采样器存在相同的缺点。它们不仅不会收敛,而且图像也会随着步数的变化而显着波动。
DPM++ 2M 和 DPM++ 2M Karras 表现良好。当步数足够高时,karras变体收敛得更快。
UniPC 收敛速度比 Euler 慢一点,但还不错。
下图是使用不同采样器的采样速度:
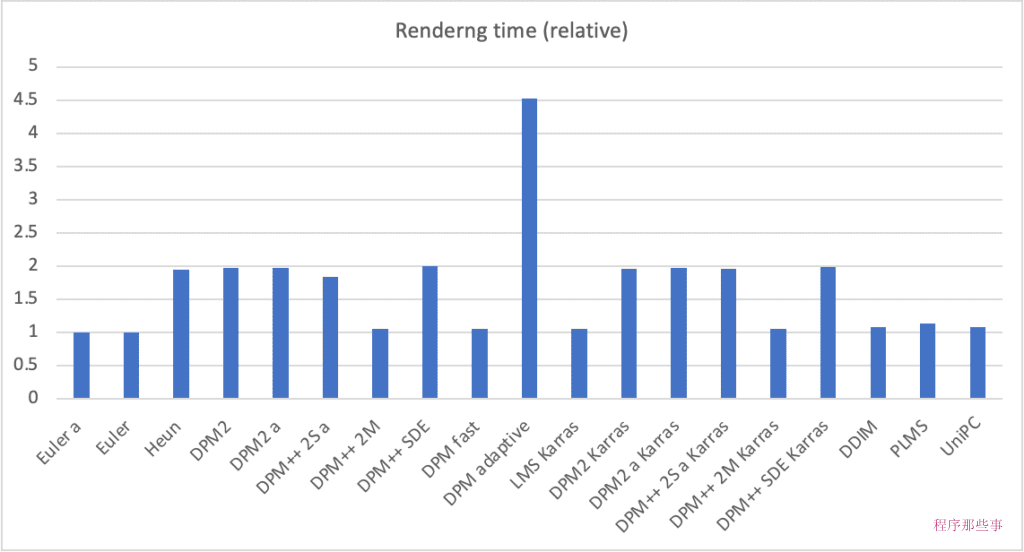
虽然 DPM adaptive在收敛方面表现良好,但它也是最慢的。
其余的渲染时间可以分为两组,第一组花费的时间大致相同(约 1 倍),另一组花费的时间大约是两倍(约 2 倍)。时间花费2倍的是因为他们用的是2阶求解器。
二阶求解器虽然更准确,但需要对去U-Net进行两次评估,所以它们花费的时间大概是2倍。
当然,前面讲的收敛和速度都是次要的,如果最终生成的图片质量不好,那么收敛和速度也就无从谈起了。
我们比较一下常用的一些采样器的最终图片效果:



大家觉得哪幅图更好?事实上,哪幅图更好是一个主观上的标准,每个人的审美观点不同,最后可能选出来不同的结果。
我不能说哪个是最好的,但是我可以给点我的建议。
如果您想快速、有创造力并且质量不错,那么可以这样选择:
如果您想要高质量的图像并且不关心收敛性,那么可以这样选择:
DPM++ SDE Karras,10-15 步(注意:这是一个较慢的采样器)
DDIM,10-15 步。
如果您喜欢稳定、可重现的图像,请避免使用任何Ancestral采样器。
Euler和Heun也是不错的选择.
在我们使用SD web UI的过程中,有很多采样器可以选择,那么什么是采样器?它们是如何工作的?它们之间有什么区别?你应该使用哪一个?这篇文章将会给你想要的答案。
嵌入,也称为文本反转,是在 Stable Diffusion 中控制图像样式的另一种方法。在这篇文章中,我们将学习什么是嵌入,在哪里可以找到它们,以及如何使用它们。