直接在https://github.com/THUDM/ChatGLM3,下载源码
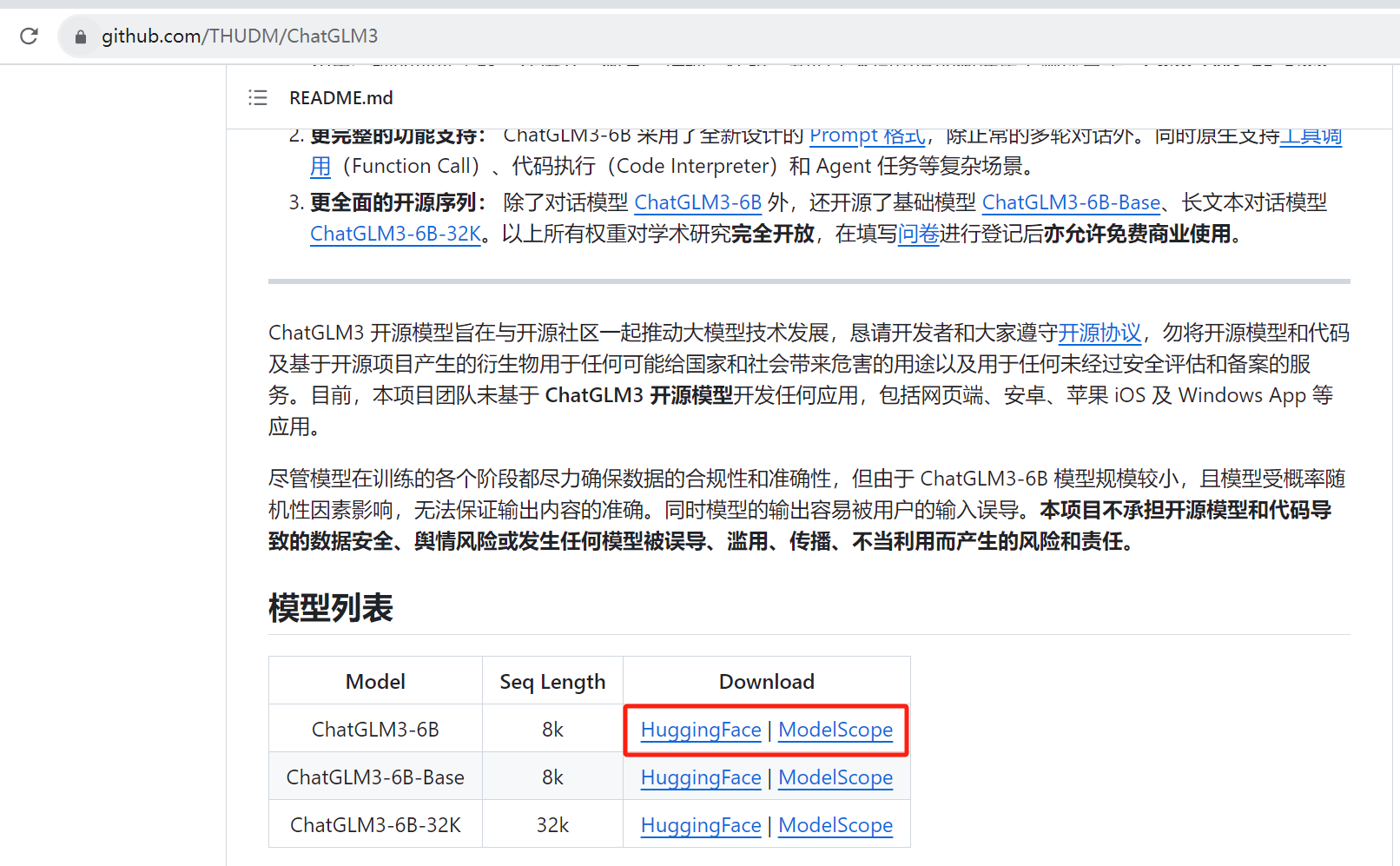
如果显卡8G一下建议下载ChatGLM3-6B,ModelScope是国内的,下载比较快
用下面两种方式都可以下载
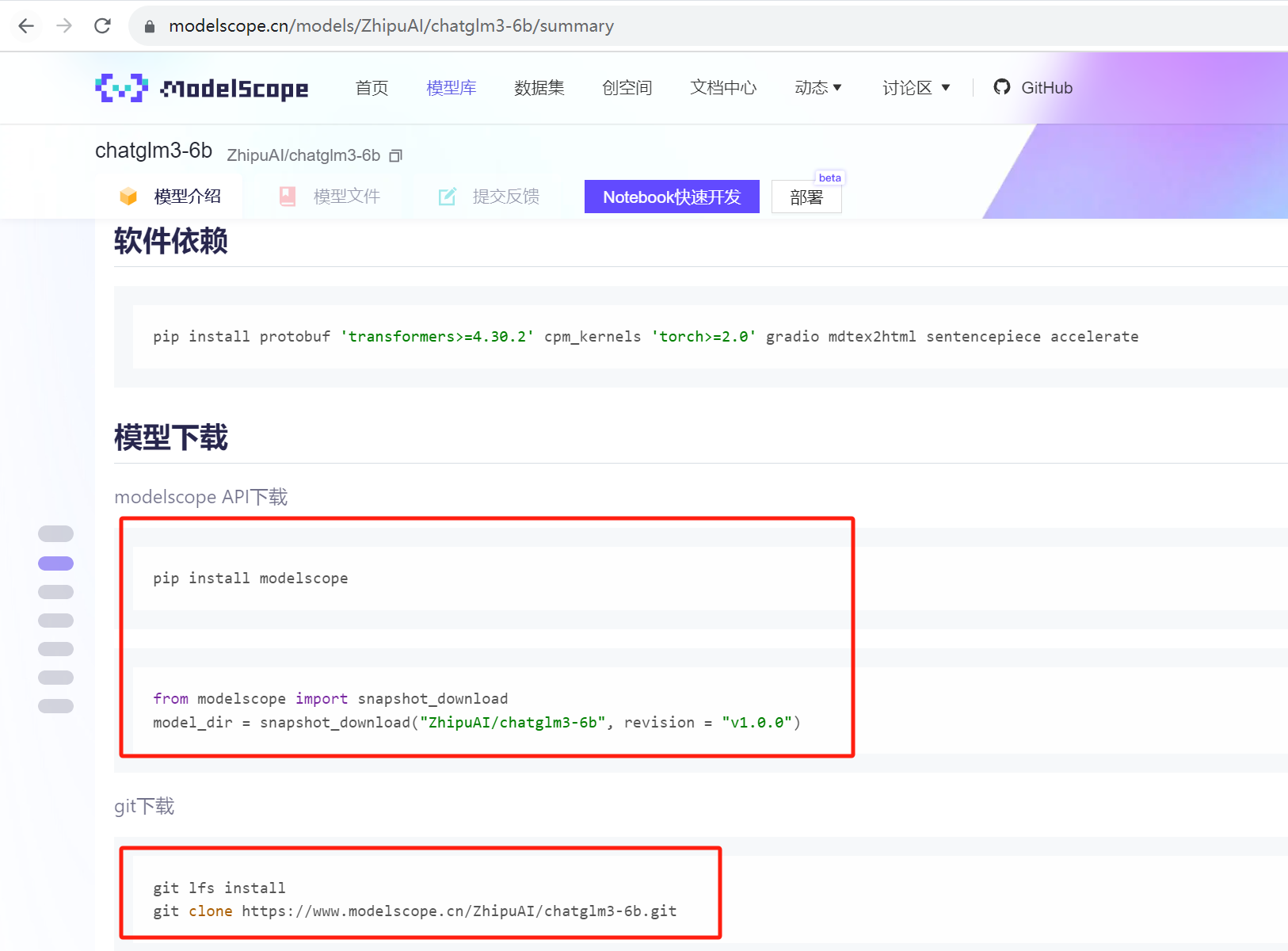
使用git在MadelScope下载大概半小时左右,看个人网速
使用Anaconda Prompt窗口执行以下命令新建一个 conda 环境并安装所需依赖:
注意:我这里修改了一下requirements.txt,指定了明确的torch版本,为了后续可以安装符合本机对应的torch的cuda版本
torch>=2.0
改成了
torch==2.1.0# 进入ChatGLM3-main解压目录
cd D:\chatglm3-6b\ChatGLM3-main
# 查看conda环境列表
conda env list
# 创建一个python为3.11名称为chatglm3-demo的环境
conda create -n chatglm3-demo python=3.11
# 激活环境
conda activate chatglm3-demo
pip install -r requirements.txt出现如下打印信息说明已经安装好了
请注意,本项目需要 Python 3.10 或更高版本。
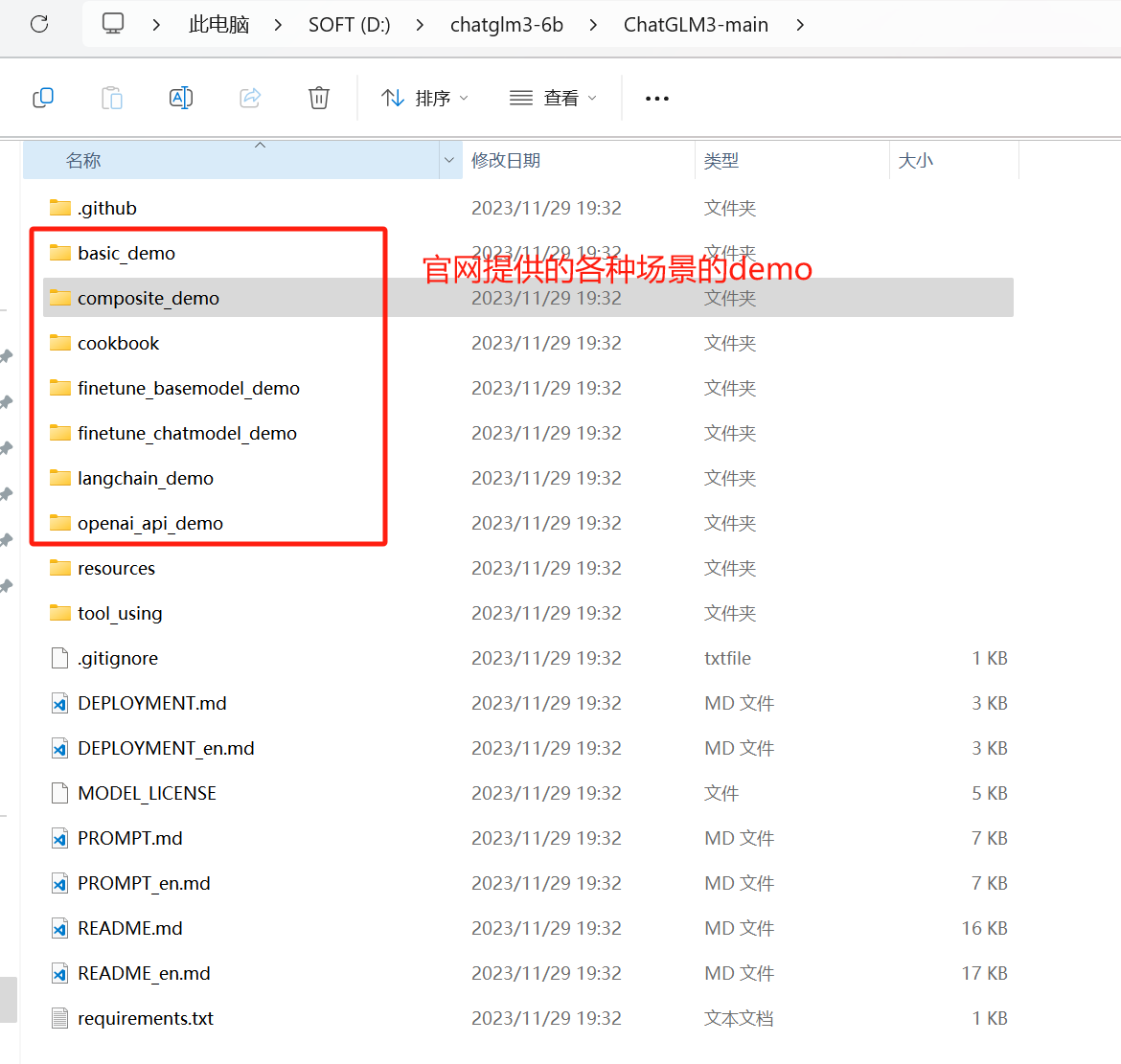
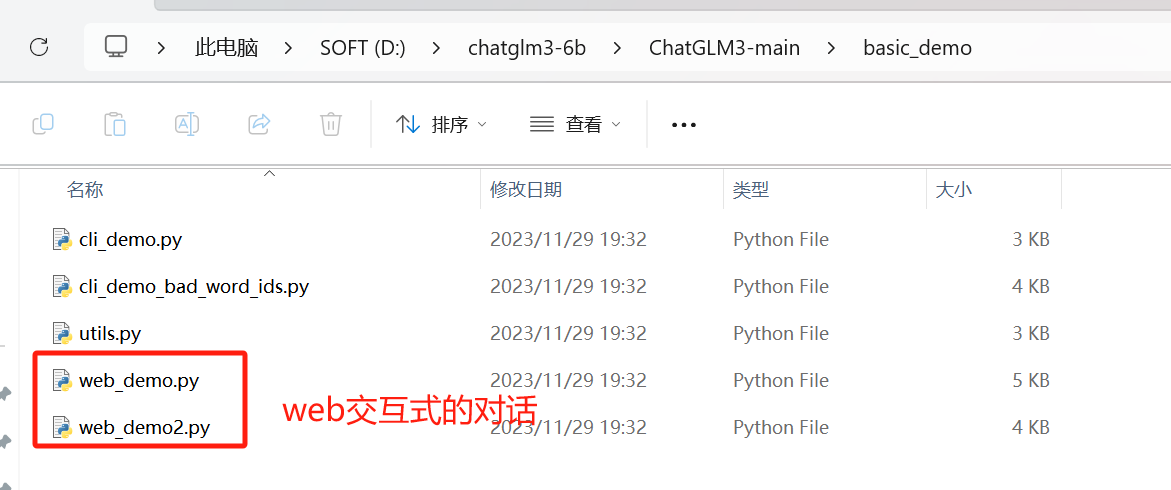
web_demo.py为基于 Gradio 的网页版 demo,启动如下
python web_demo.pyweb_demo2.py为基于 Streamlit 的网页版 demo
streamlit run web_demo2.py网页版 demo 会运行一个 Web Server,并输出地址。在浏览器中打开输出的地址即可使用。 经测试,基于 Streamlit 的网页版 Demo 会更流畅。
openai_api.py实现了 OpenAI 格式的流式 API 部署,可以作为任意基于 ChatGPT 的应用的后端
cd openai_api_demo
python openai_api.pynvidia-smi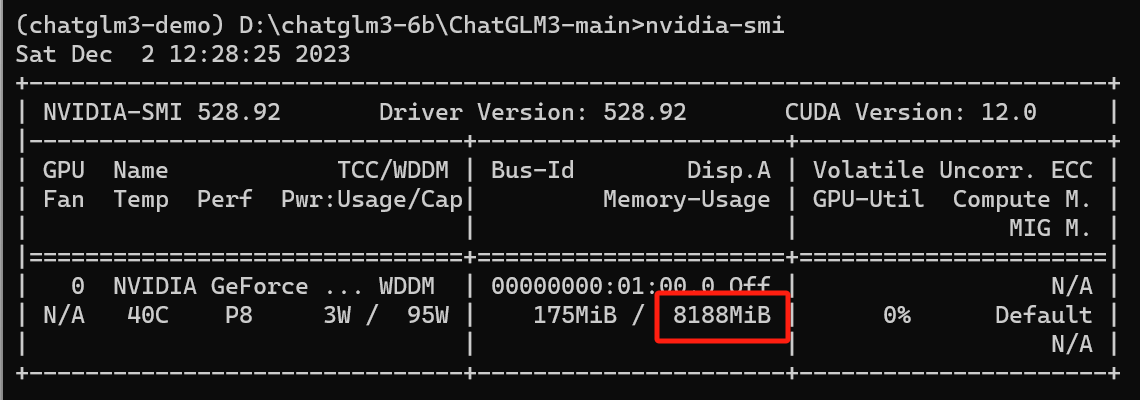
以web_demo.py为例
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
model = AutoModel.from_pretrained("THUDM/chatglm3-6b",trust_remote_code=True).quantize(4).cuda()模型量化会带来一定的性能损失,经过测试,ChatGLM3-6B 在 4-bit 量化下仍然能够进行自然流畅的生成。
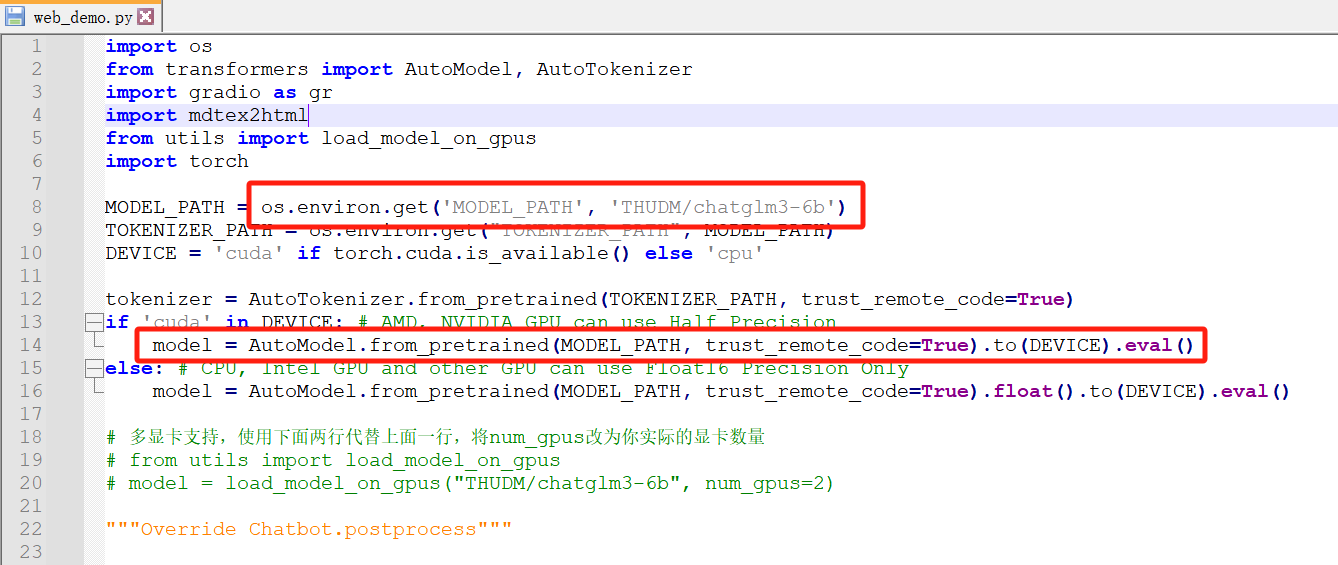
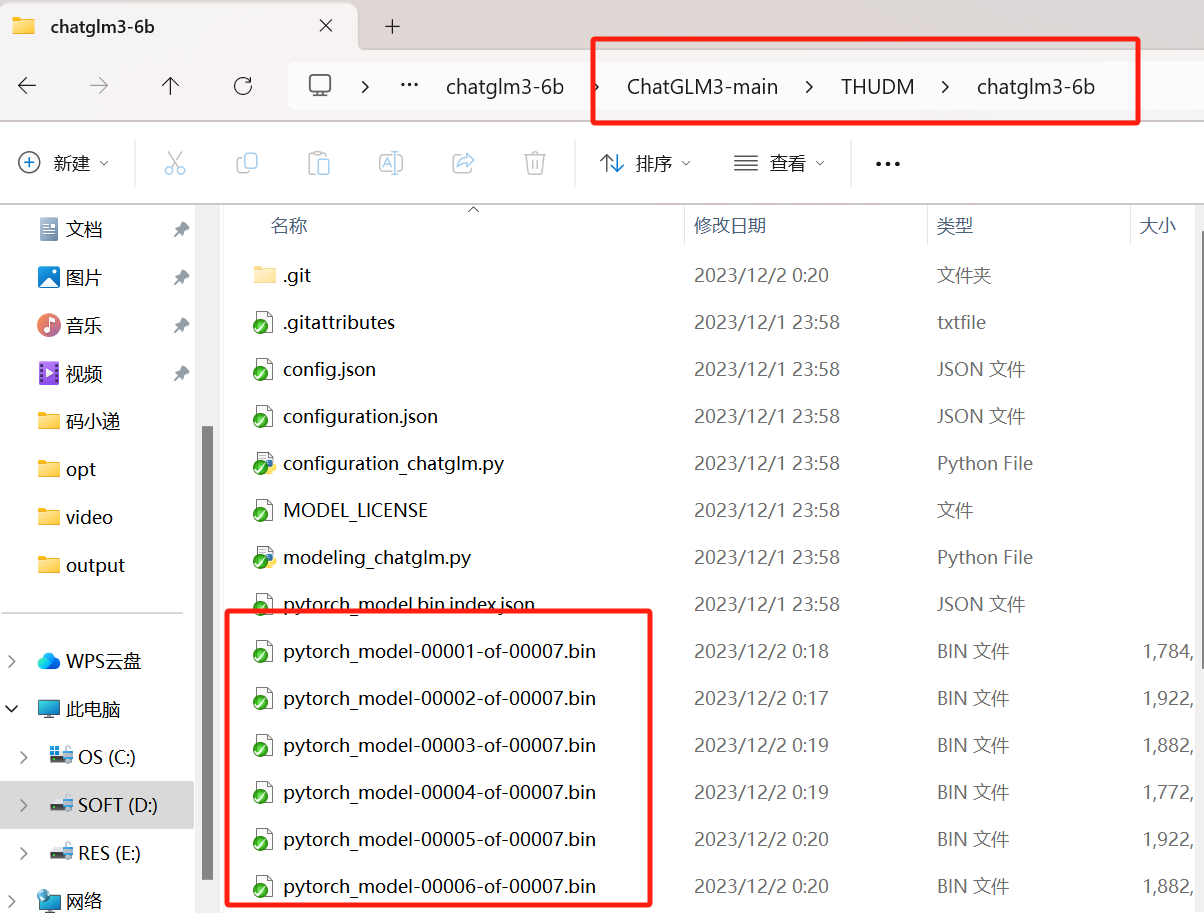
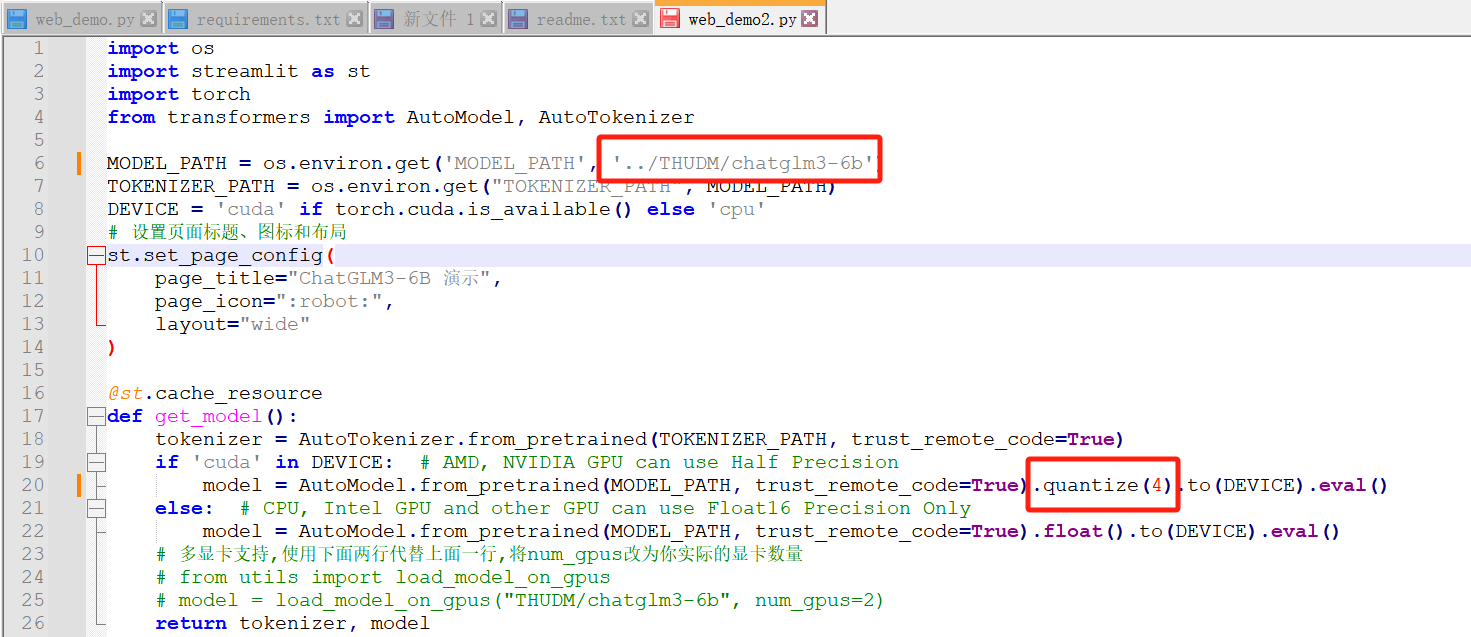
从第一个红框可以看出,我们需要把下载的模型文件夹放在THUDM这个相对目录下,如下
并且将MODEL_PATH改成../THUDM/chatglm3-6b,避免启动时再次下载,如下
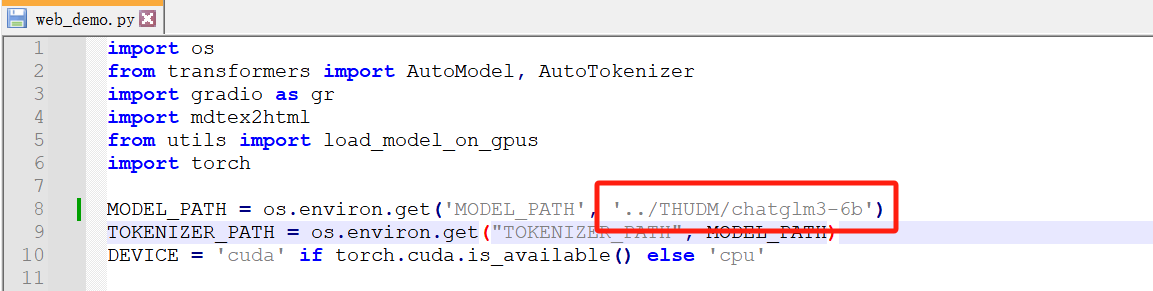
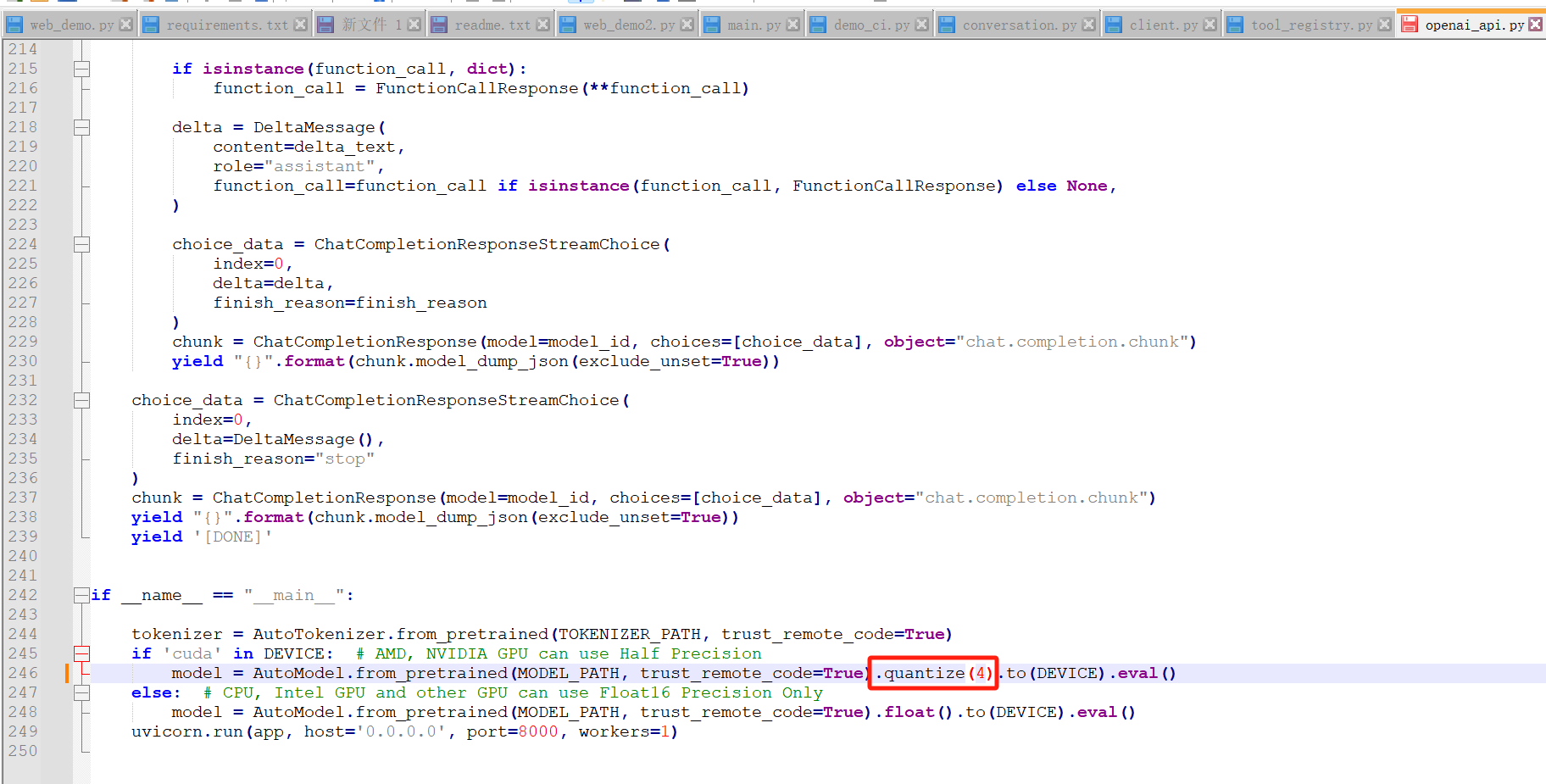
将第二个红框代码改成如下,使用ChatGLM3-6B 在 4-bit 量化
model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True).quantize(4).to(DEVICE).eval()出现如下错误
(chatglm3-demo) D:\chatglm3-6b\ChatGLM3-main\basic_demo>python web_demo.py
Traceback (most recent call last):
File "D:\chatglm3-6b\ChatGLM3-main\basic_demo\web_demo.py", line 4, in <module>
import mdtex2html
ModuleNotFoundError: No module named 'mdtex2html'可以使用pip install安装
(chatglm3-demo) D:\chatglm3-6b\ChatGLM3-main\basic_demo>pip install mdtex2html
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting mdtex2html
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/47/fa/5156a032ad68f6c32ae0dc3aaf8b3d690004b42497d4735a08bb4cea6ec3/mdtex2html-1.2.0-py3-none-any.whl (13 kB)
Collecting markdown (from mdtex2html)
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/70/58/2c5a654173937d9f540a4971c569b44dcd55e5424a484d954cdaeebcf79c/Markdown-3.5.1-py3-none-any.whl (102 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 102.2/102.2 kB 1.2 MB/s eta 0:00:00
Requirement already satisfied: latex2mathml in d:\anaconda\envs\chatglm3-demo\lib\site-packages (from mdtex2html) (3.76.0)
Installing collected packages: markdown, mdtex2html
Successfully installed markdown-3.5.1 mdtex2html-1.2.0再次启动,如下启动成功
访问web界面如下
如果明明正确安装了cuda,其它AI组件都可以正常使用GPU,我们启动发现GPU完全没有用到,内存使用很大,我们可以在web-demo.py中增加如下打印,查看cuda和pytorch
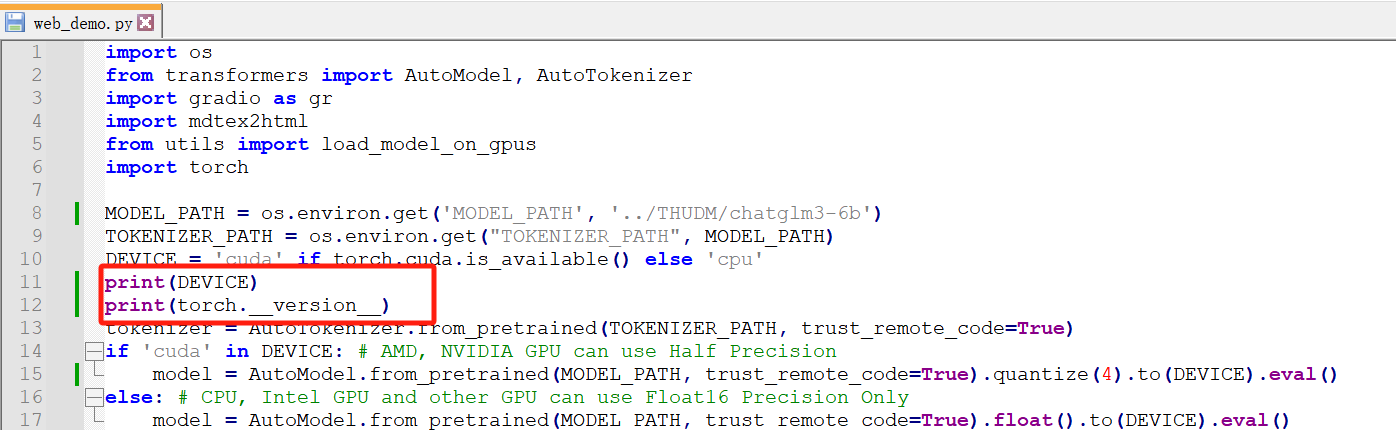
打印如下

很明显使用了cpu,虽然可以使用,但是问答会很慢
我们再用命令确认一下cuda版本,发现版本正常

这里很明显就是pytorch使用了cpu版本,需要更换成gpu版本
在如下pytorch的下载地址上下载对应版本的pytorch
http://download.pytorch.org/whl/torch_stable.html
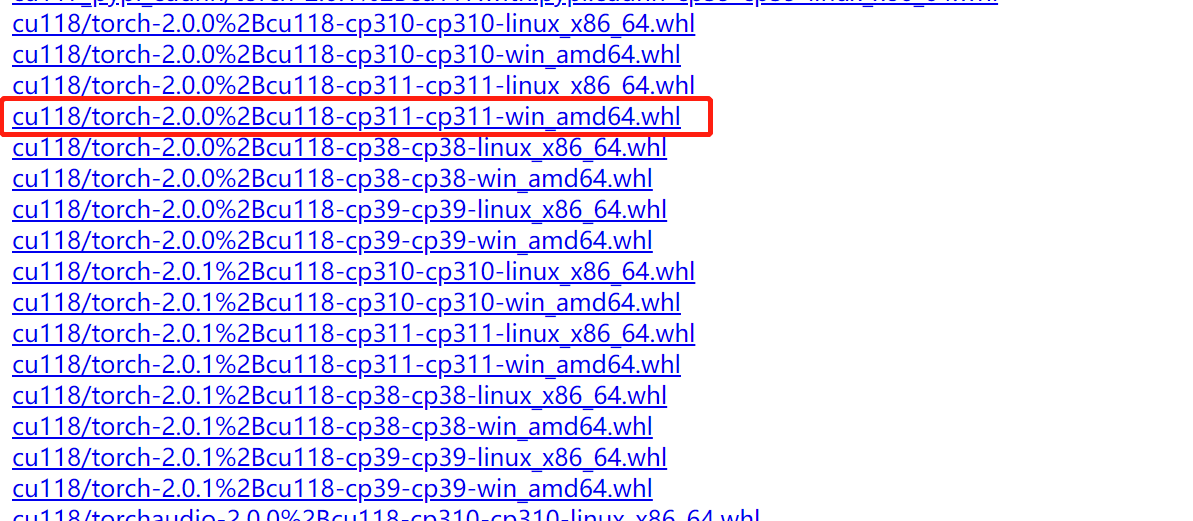
其中cu118表示cuda 11.8,cp311表示python 3.11
下载之后我放在了D:\anaconda\cuda_package 路径下,先手动删除掉anacoda对应环境的torch的相关包

然后使用如下命令安装torch
pip install "D:\anaconda\cuda_package\torch-2.0.0+cu118-cp311-cp311-win_amd64.whl"
pip install "D:\anaconda\cuda_package\torchvision-0.15.0+cu118-cp311-cp311-win_amd64.whl"
pip install "D:\anaconda\cuda_package\torchaudio-2.0.0+cu118-cp311-cp311-win_amd64.whl"验证cuda和torch
python
import torch
torch.cuda.is_available()
torch.__version__打印如下

可以看到torch版本已经是cuda了,再次启动如下
经过测试,目前为止,web_demo.py回答问题没法正常显示,会出现js错误
注意:同样需要修改一下web_demo2.py
使用streamlit启动web_demo2
streamlit run web_demo2.py界面如下
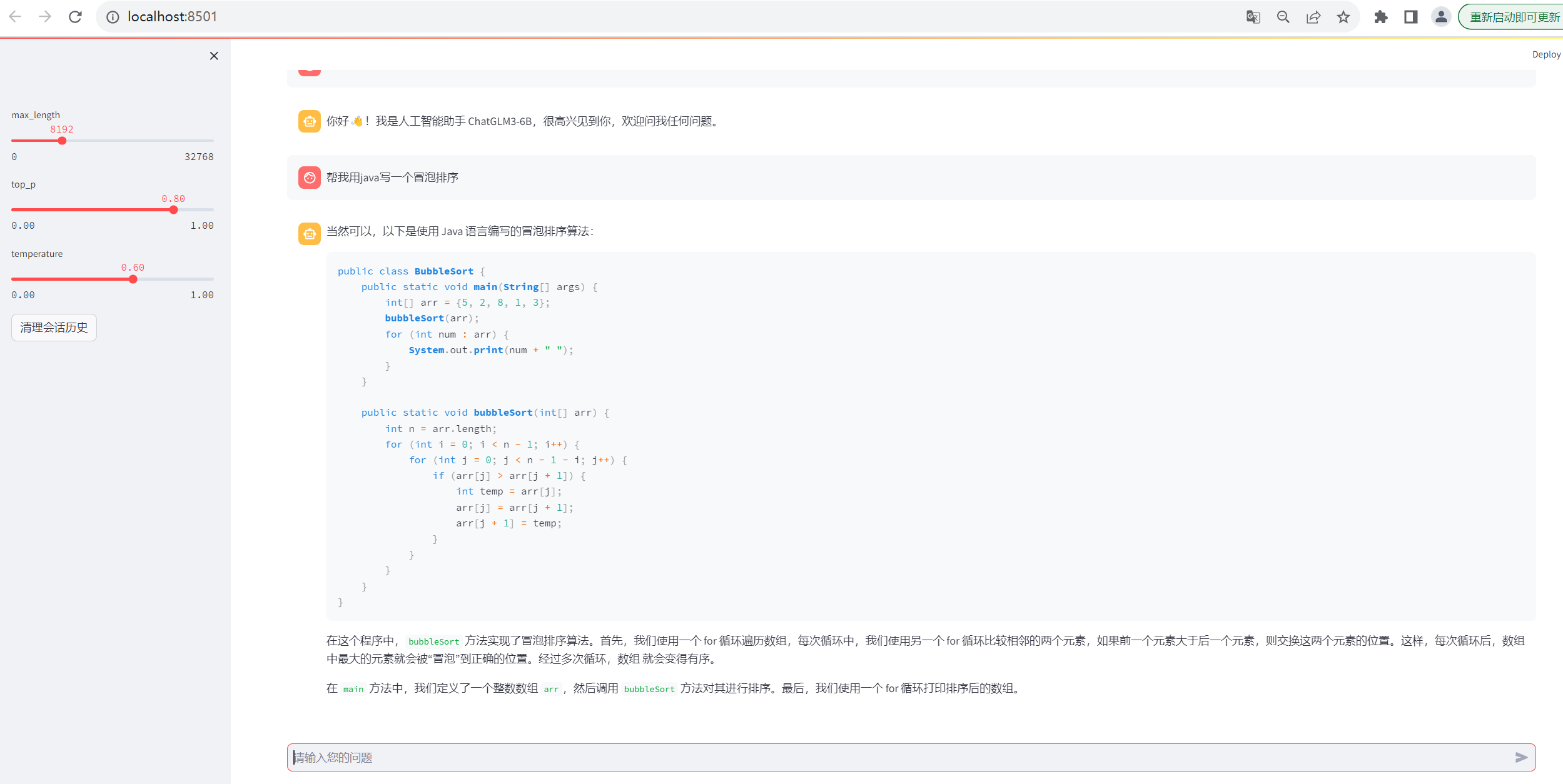
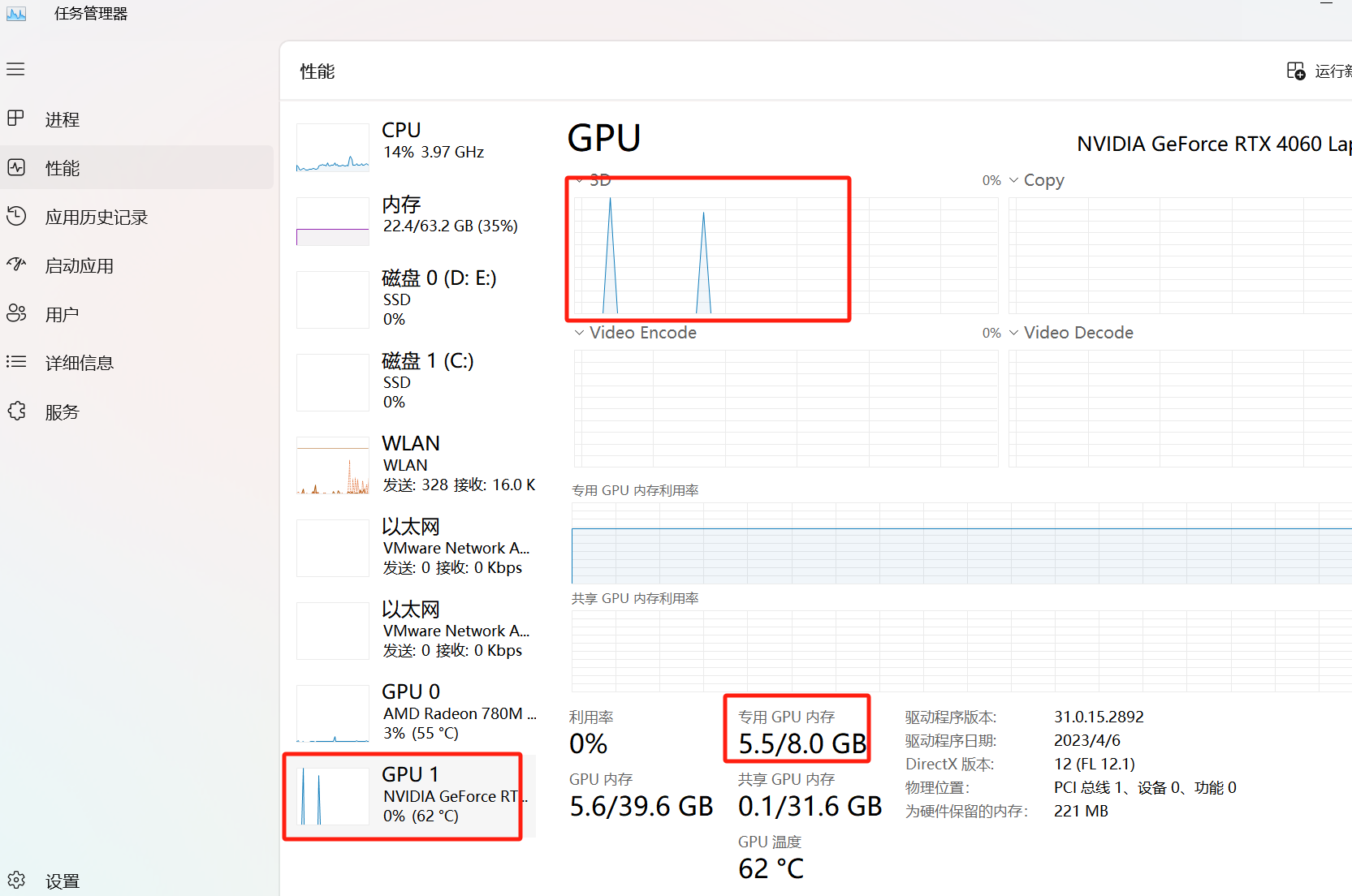
回答问题的时候查看GPU情况,压力不算大
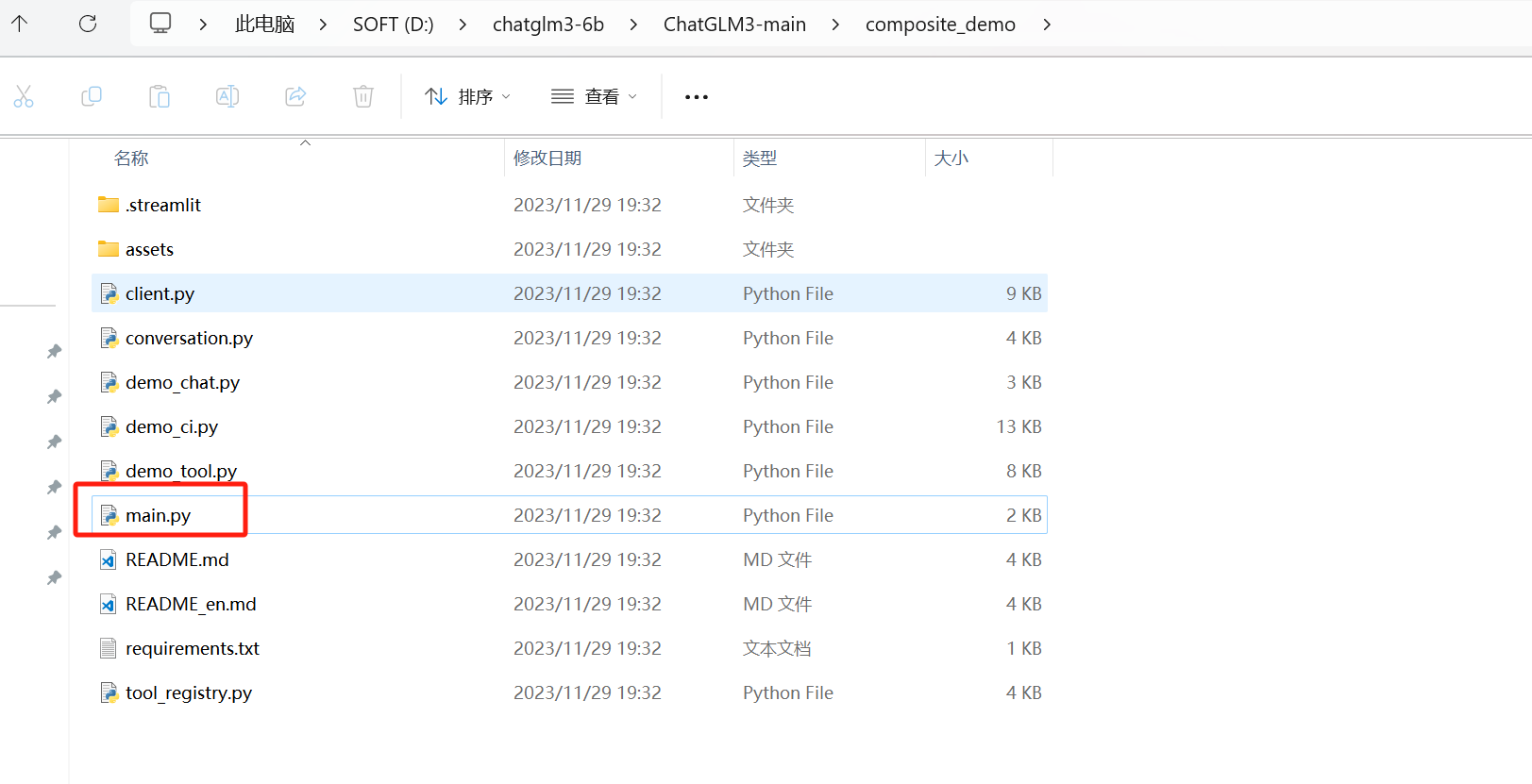
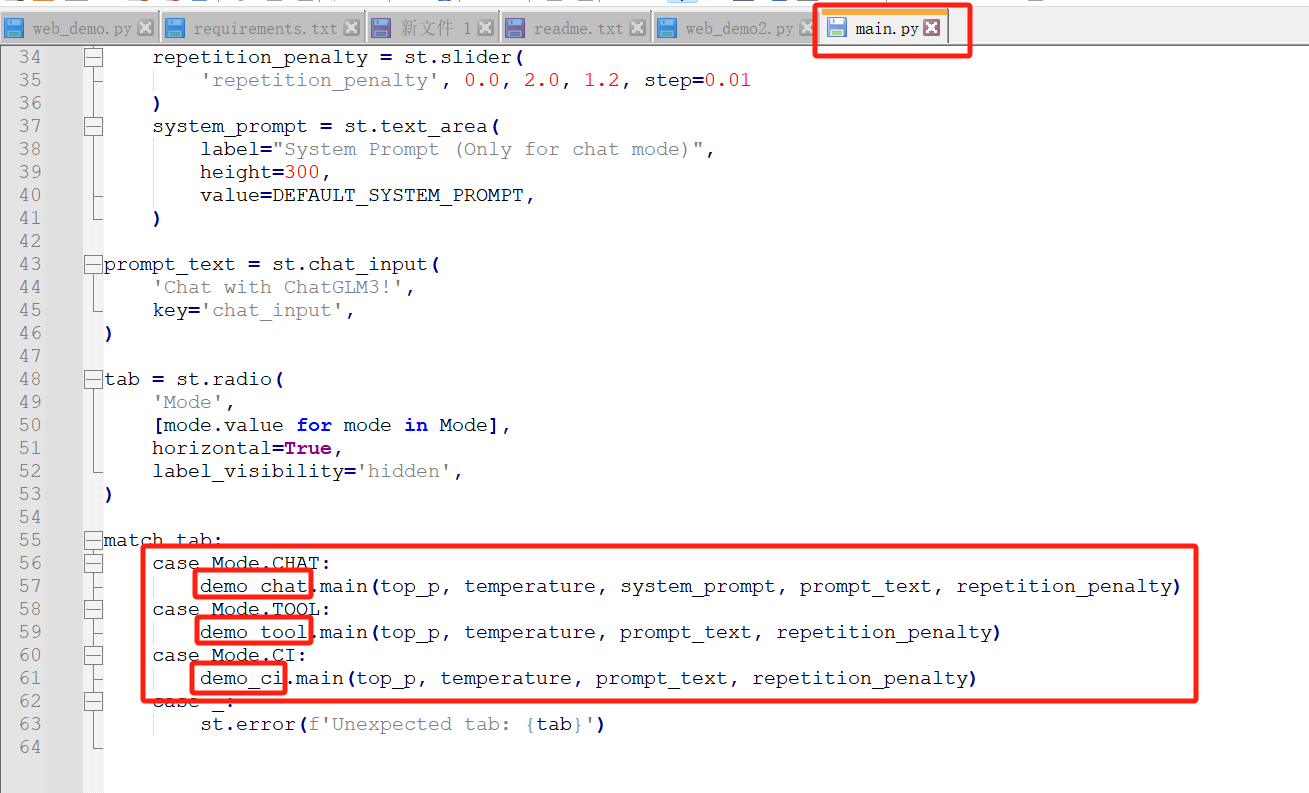
查看源码,可以发现根据模式不同,调用了其余三个python的main方法,所以理论上其余三个都要修改一下model地址和量化精度
一番查找,可以看出,三个py都是调用的client.py,所以只需要修改client.py就行了
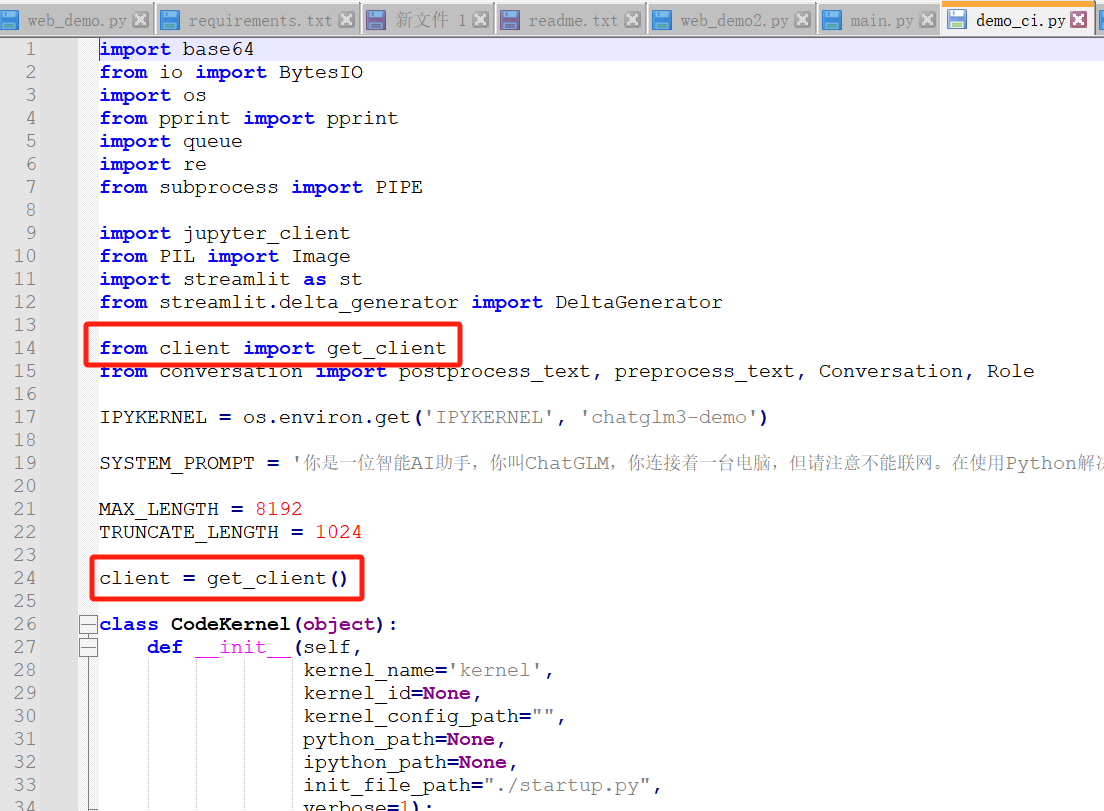
又是熟悉的地方,这里要改下路径
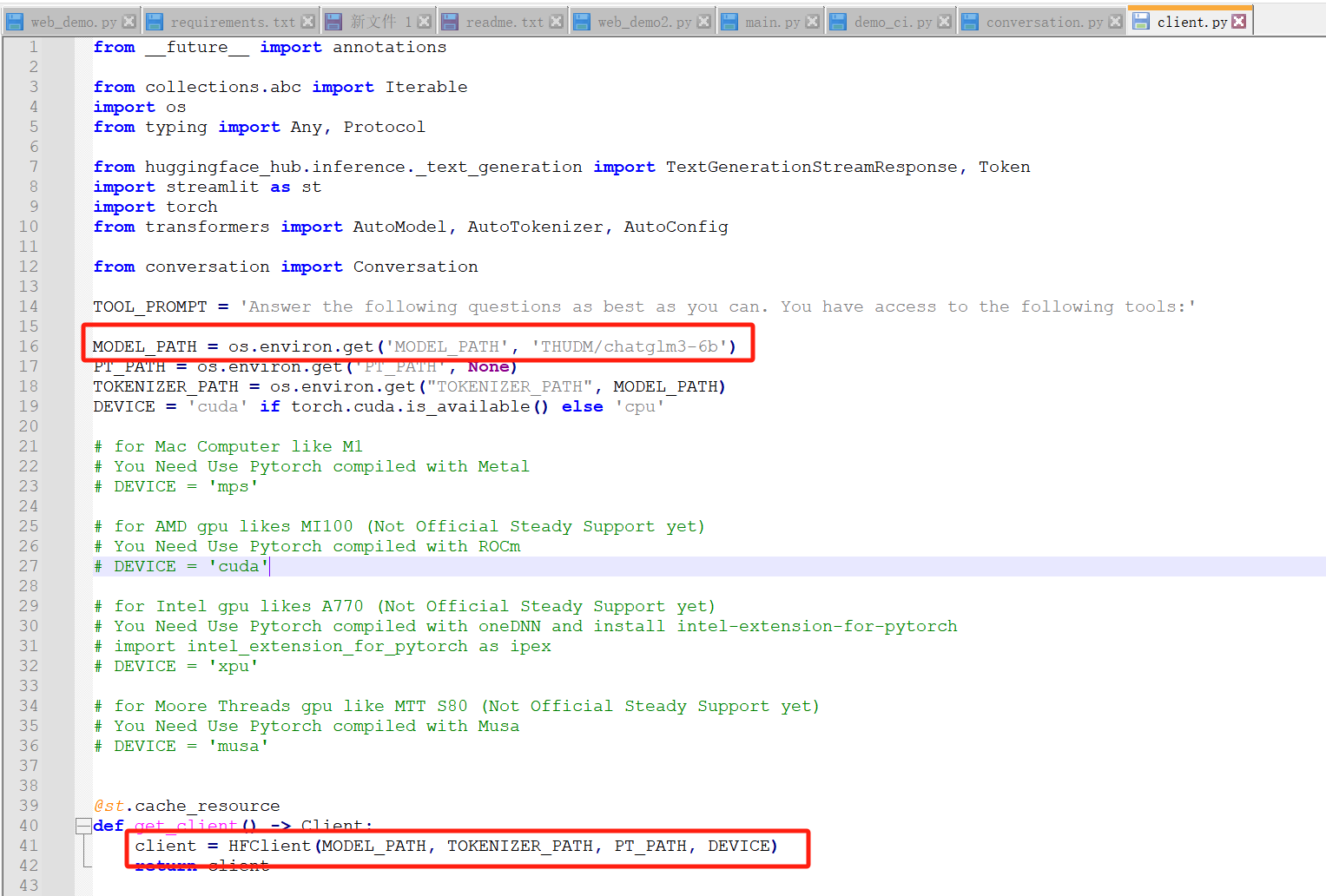
改路径之后如下
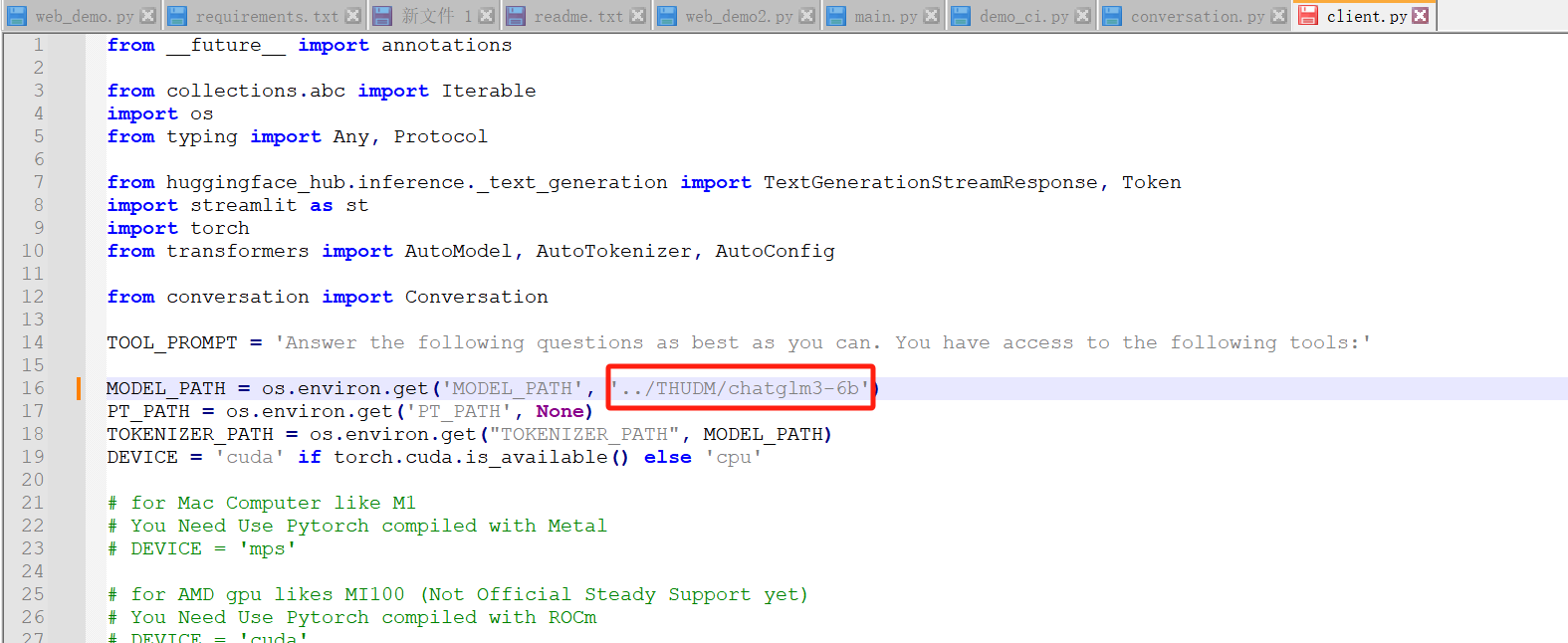
还有一个模型量化要改成int4,不然显存扛不住,如下改红框处就可以了
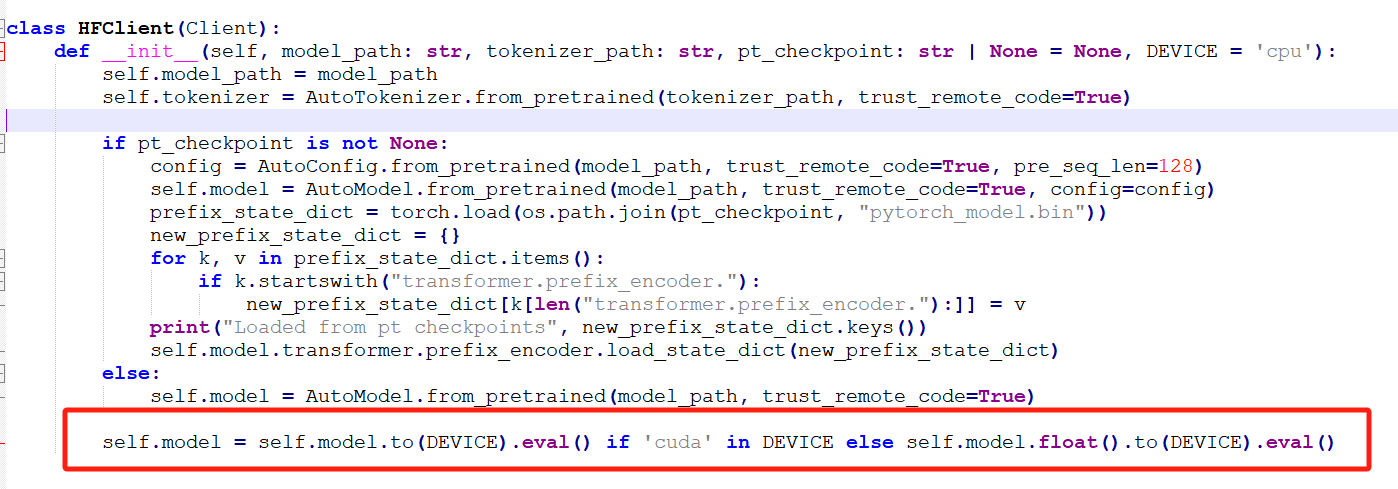
改之后如下

从main.py中可以看到streamlit,所以我们可以通过streamlit启动
streamlit run main.py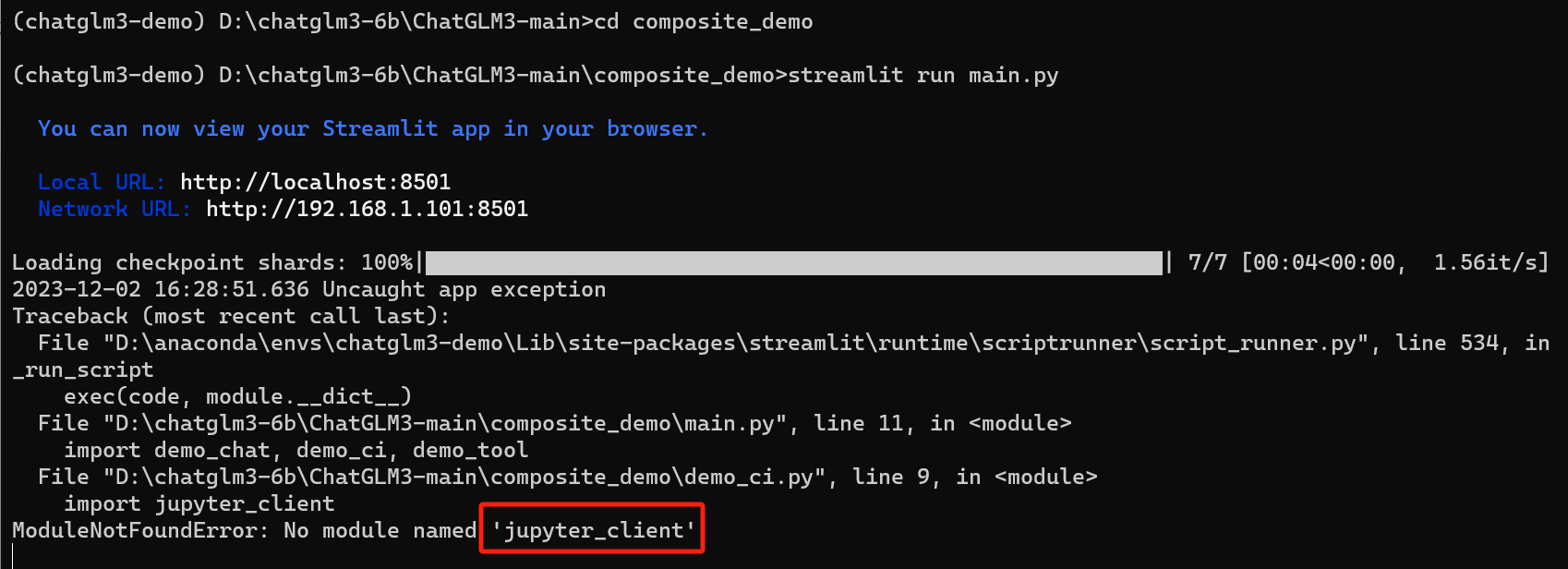
没有找到,就安装一下
pip install jupyter_client再次运行,如下
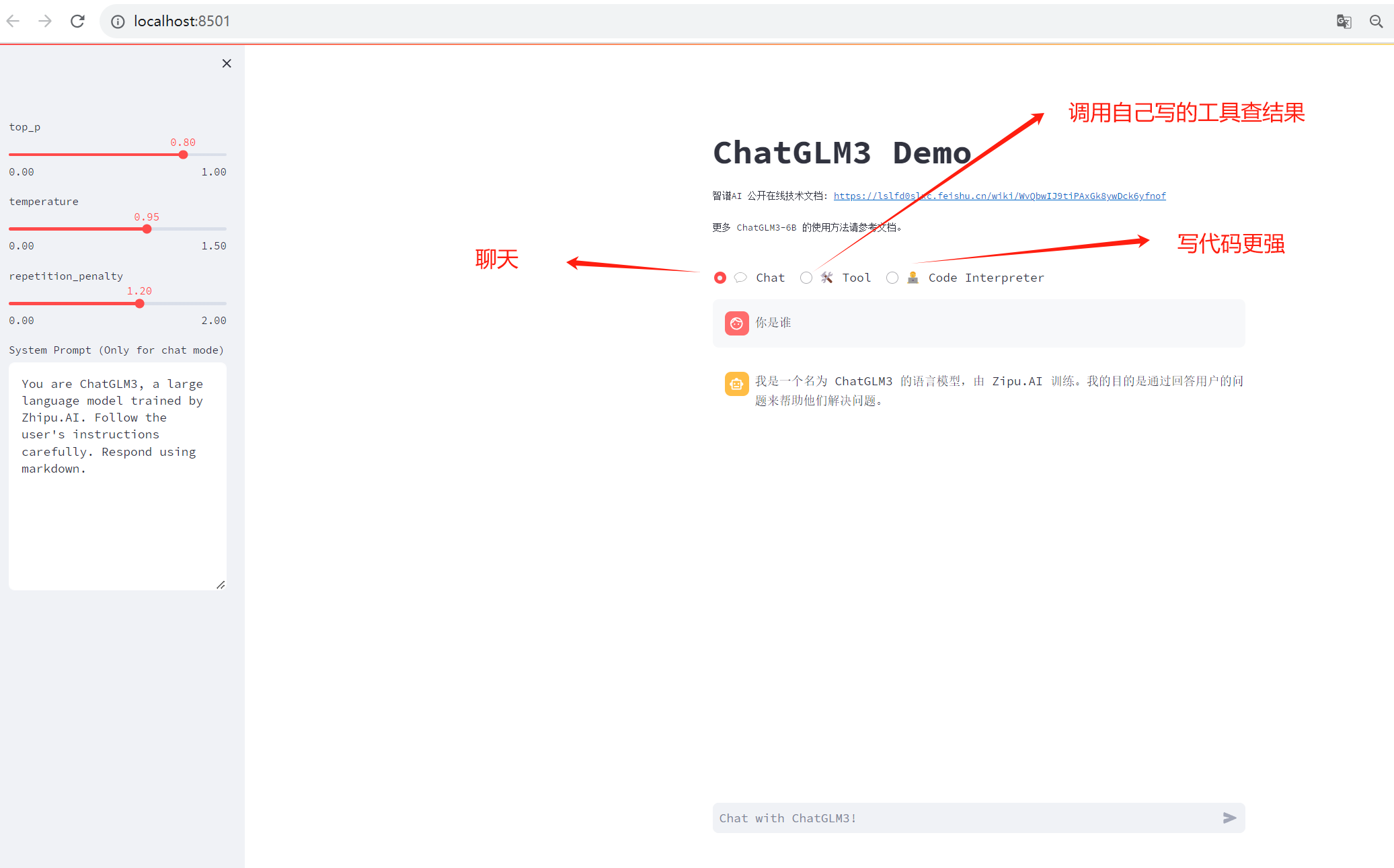
top_p:具体而言,当你调用 ChatGLM3 时,它首先会对所有预测结果进行排序,并按照一定的顺序给出它们。然后,在返回回复时,它将从所有预测框中选择最大的 k 个预测结果(其中 k 是 的值),并根据这些框中的最大概率预测生成回复。通常情况下,较高的 值会增加生成的回复的长度,但可能会降低回复的准确性。
temperature:在ChatGLM3中,Temperature是用来调节回复的多样性和广度的。具体来说,温度控制了在生成回复时,模型更有可能在哪些预测框上进行探索。在ChatGLM3的默认设置中,温度参数是开启的,也就是说是可以随机生成的。这样的回复会显得比较简洁、直接和明确。如果你的 temperature 参数被关闭,则只会生成一种类型的回复,而不会有多种。在这种情况下,生成的回复将会更加具体和聚焦。需要注意的是, Temperature 参数影响力回复的质量。更高的温度会使模型生成更广泛、更具创造性和多样性的回复,但也可能导致一些不可 Predictable 的或是离谱的回复。
repetition_penalty:Repetition Penalty(重复惩罚)是聊天机器人领域的一个常见概念,也应用于ChatGLM3。它的作用是在对话中鼓励模型生成更多的信息或响应,从而使对话更有意义和连贯。具体来说,Repetition Penalty会在一段时间内奖励模型生成更多的相同主题或相关内容的回应。随着时间推移,如果没有新的信息或回应出现,模型就会受到惩罚。这个惩罚力度 then 会使得模型更加努力生成不同的内容。简单地说,它就像一个“奖励”机制,驱动着模型不断寻找新的信息,以避免陷入过度的重复状态。值得注意的是,对话系统的研究者们在构建模型时已经注意到了这个潜在的问题,并且在他们的研究中提出了一些解决方案来处理这个问题。
以上是和chatglm3对话,它自己说的


AI机器人是根据历史的训练过的数据来回答用户的问题,假如现在需要查询当前的天气,正常是没办法的,ChatGLM3提供了自定义的可扩展的Tool来实现这种查询实时信息的能力。
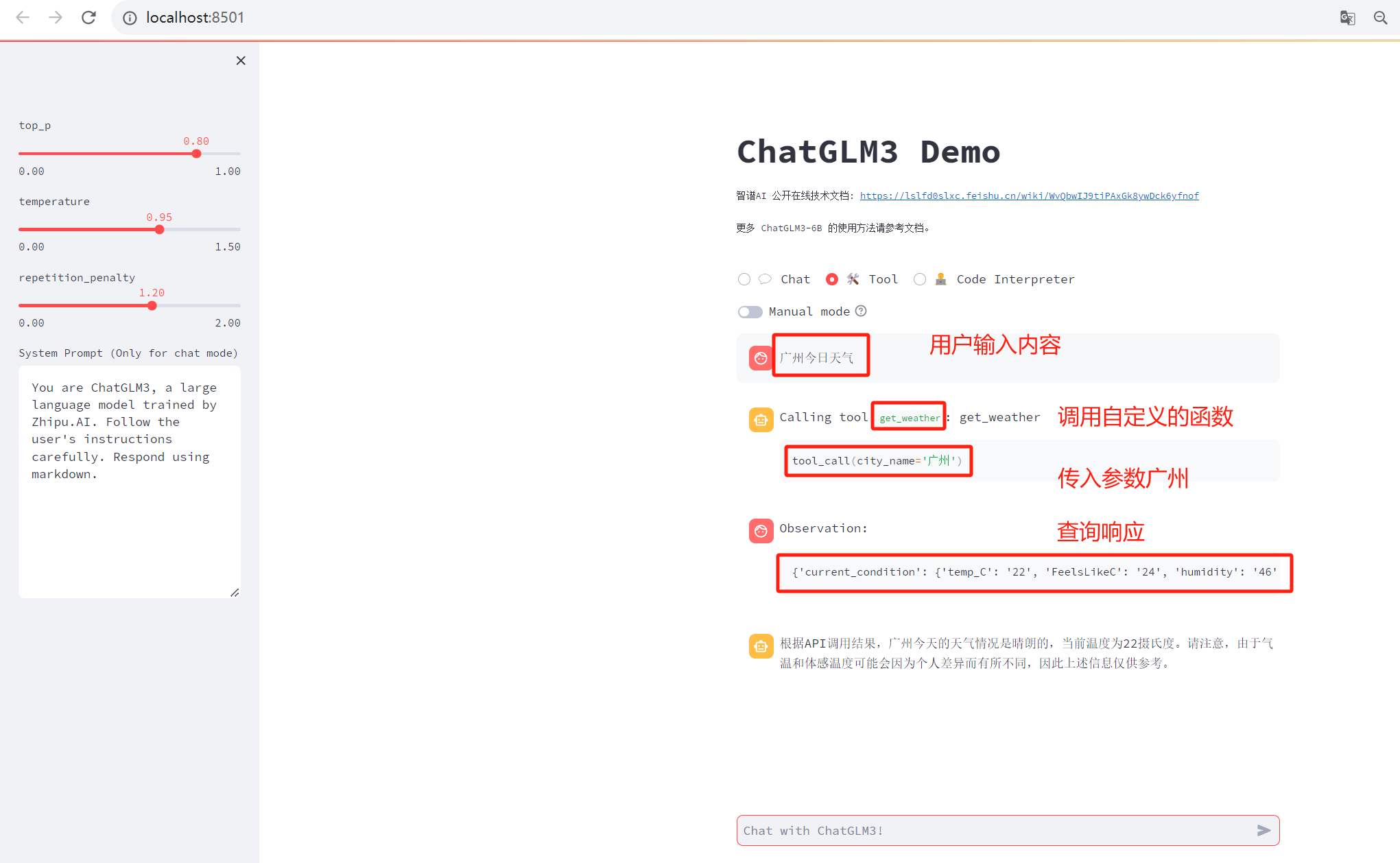
这个工具可以在tool_registry.py中自定义
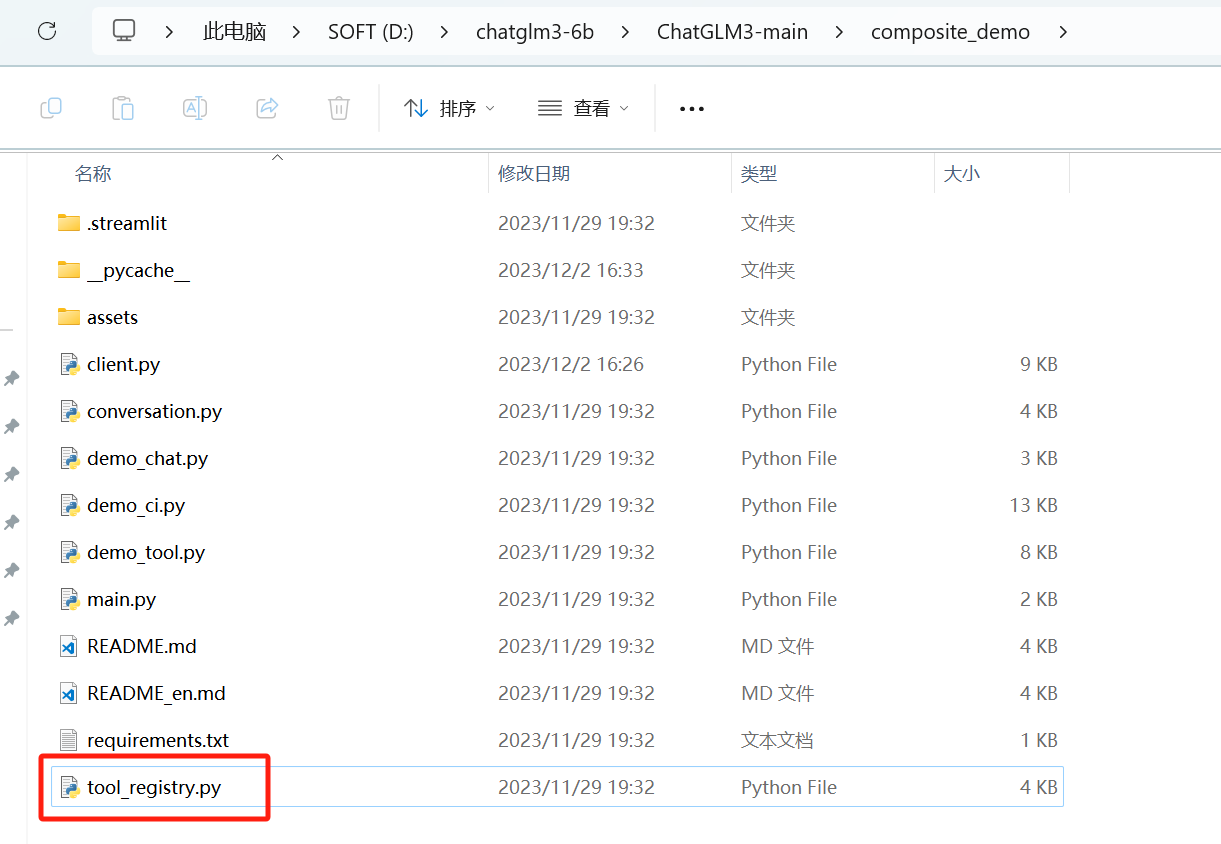
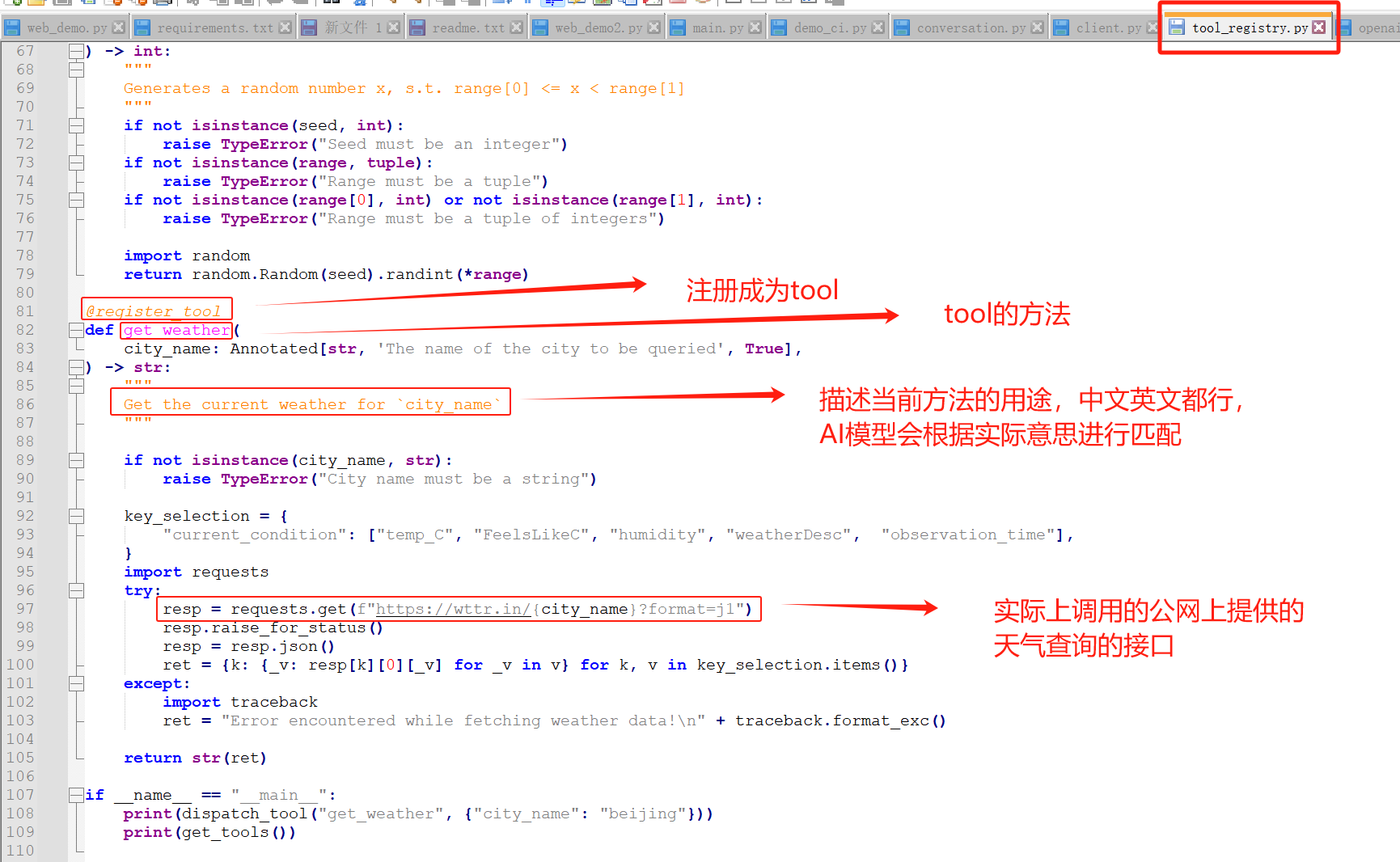
从上可以看出,如果想自己加工具,可以在tool_registry.py中按照上面的方式添加一个函数,然后重启一下main.py就可以了
同样需要修改一下模型地址
还需要修改一下模型量化为int4
python openai_api.py
可以查看一下源码里有哪些接口
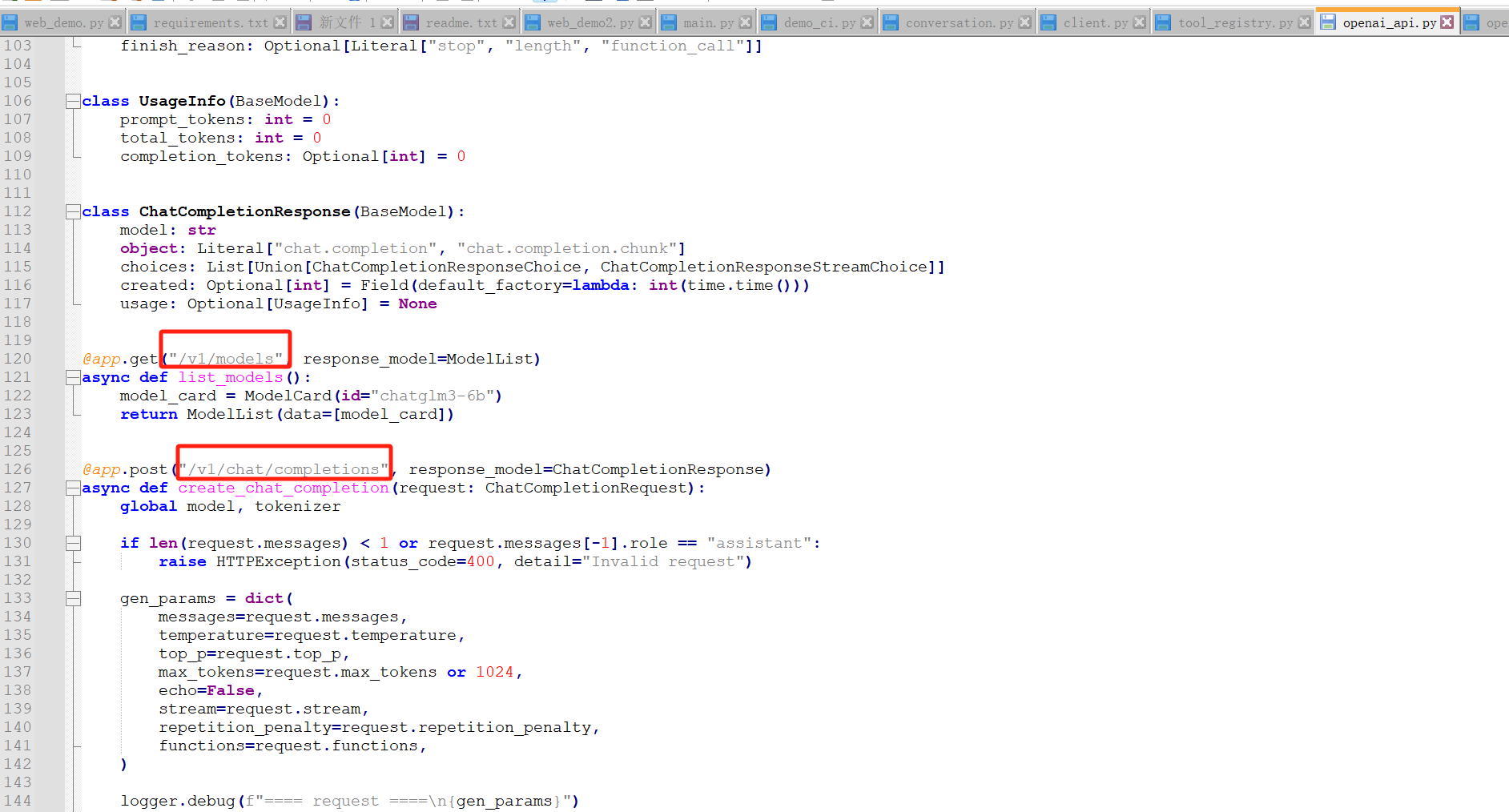
然后可以看一下openai_api_request.py中提交的参数
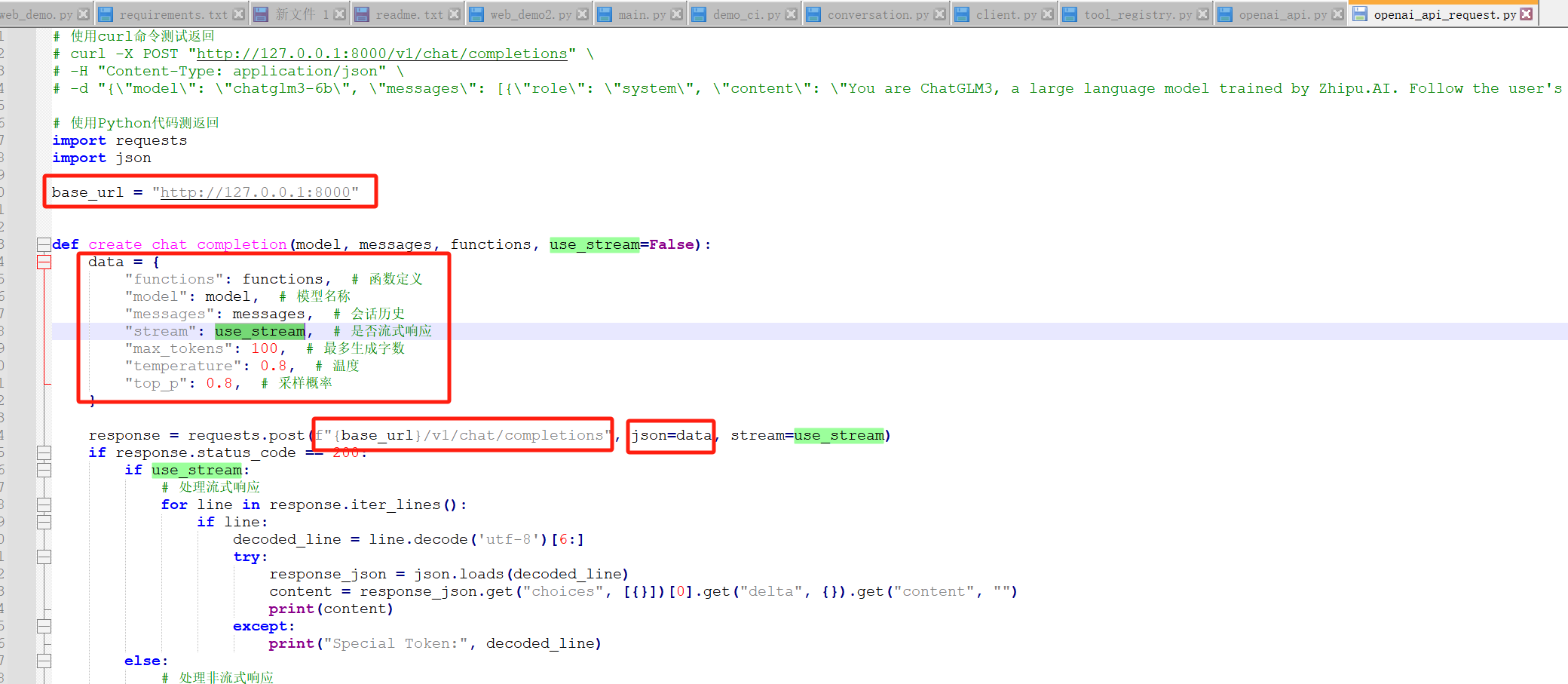
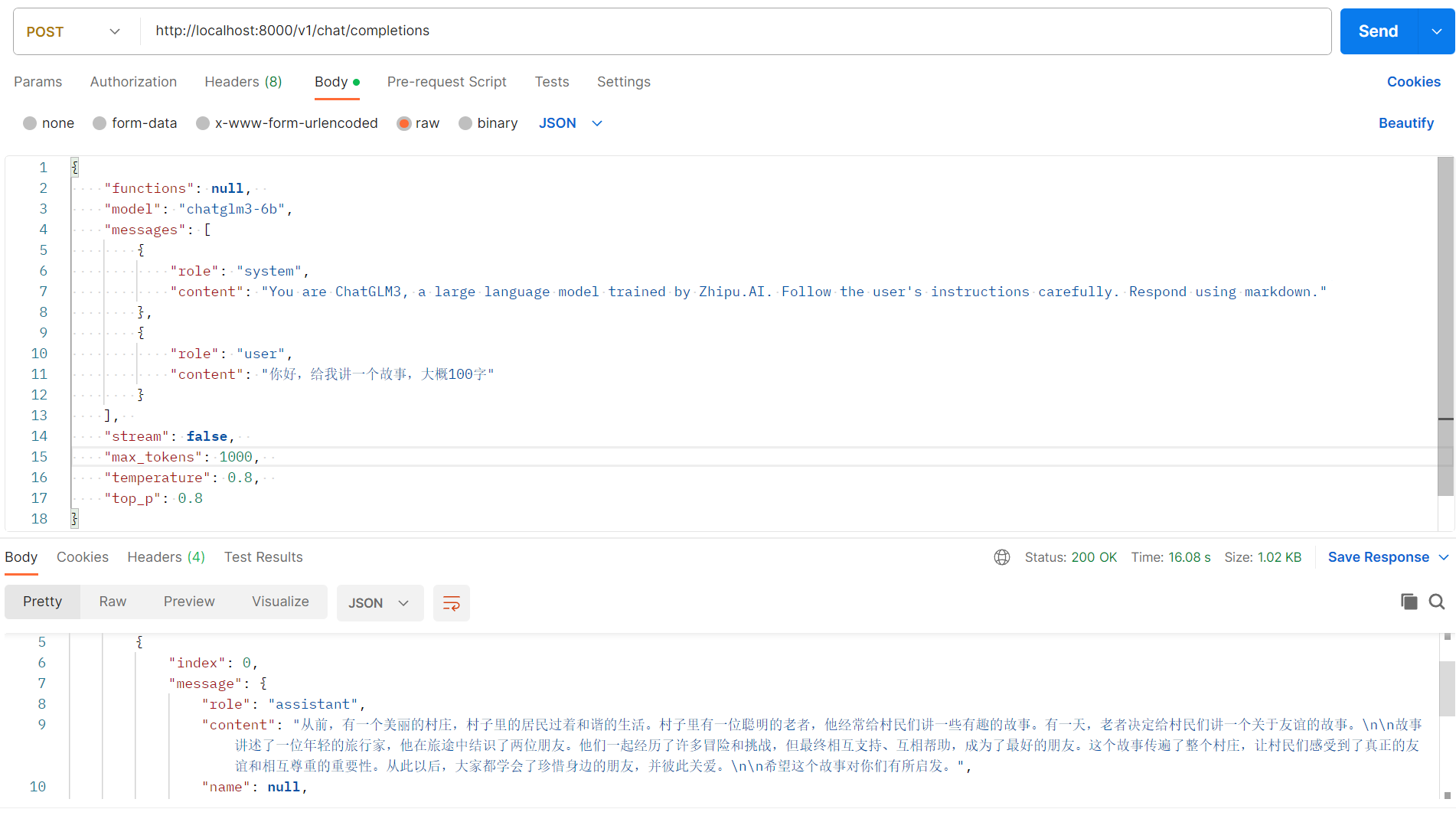
可以看出,post请求地址为http://localhost:8000/v1/chat/completions,请求内容如下
{
"functions": null,
"model": "chatglm3-6b", # 模型
"messages": [ #问答历史记录
{
"role": "system",
"content": "You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown.",
},
{
"role": "user",
"content": "你好,给我讲一个故事,大概100字"
}
],
"stream": false, # 是否流式
"max_tokens": 100, # 最长的字数
"temperature": 0.8,
"top_p": 0.8
}
返回如下
{
"model": "chatglm3-6b",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "从前,有一个美丽的村庄,村子里的居民过着和谐的生活。村子里有一位聪明的老者,他经常给村民们讲一些有趣的故事。有一天,老者决定给村民们讲一个关于友谊的故事。\n\n故事讲述了一位年轻的旅行家,他在旅途中结识了两位朋友。他们一起经历了许多冒险和挑战,但最终相互支持、互相帮助,成为了最好的朋友。这个故事传遍了整个村庄,让村民们感受到了真正的友谊和相互尊重的重要性。从此以后,大家都学会了珍惜身边的朋友,并彼此关爱。\n\n希望这个故事对你们有所启发。",
"name": null,
"function_call": null
},
"finish_reason": "stop"
}
],
"created": 1701510921,
"usage": {
"prompt_tokens": 54,
"total_tokens": 178,
"completion_tokens": 124
}
}
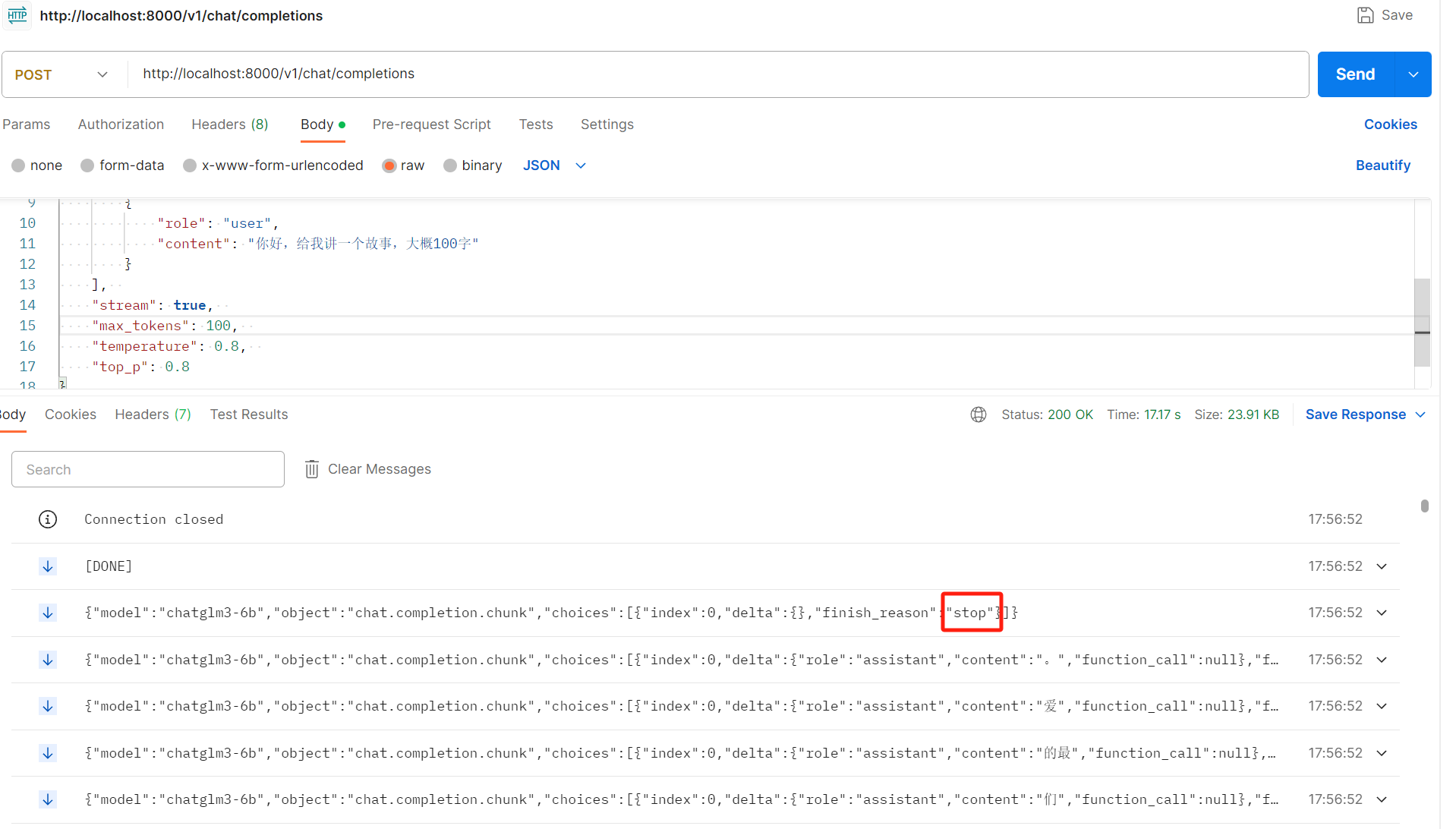
需要注意的是请求参数stream为true表示流式,会在一个请求里不断的返回
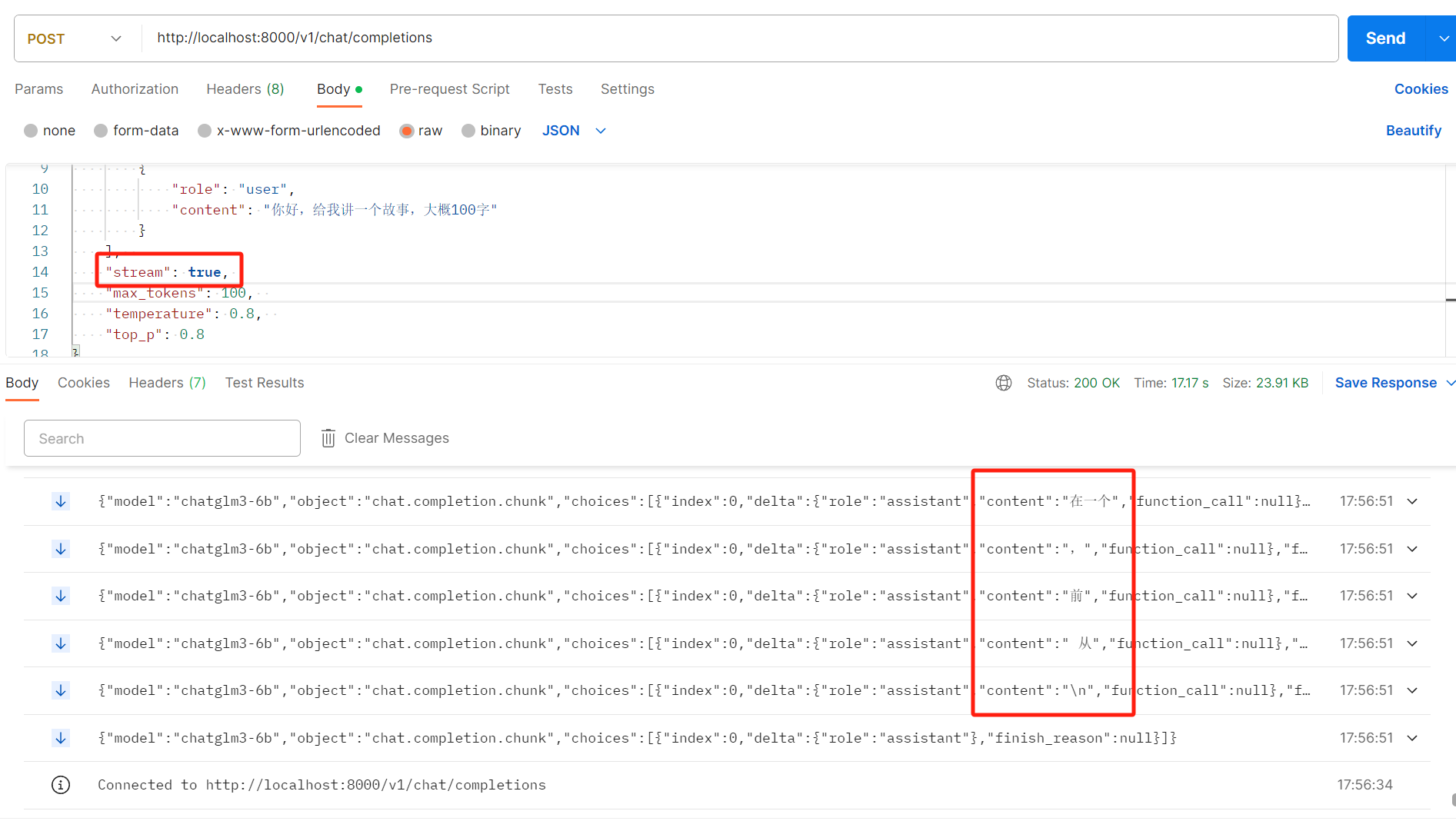
直到finish_reason为stop就停止了,然后http链接关闭
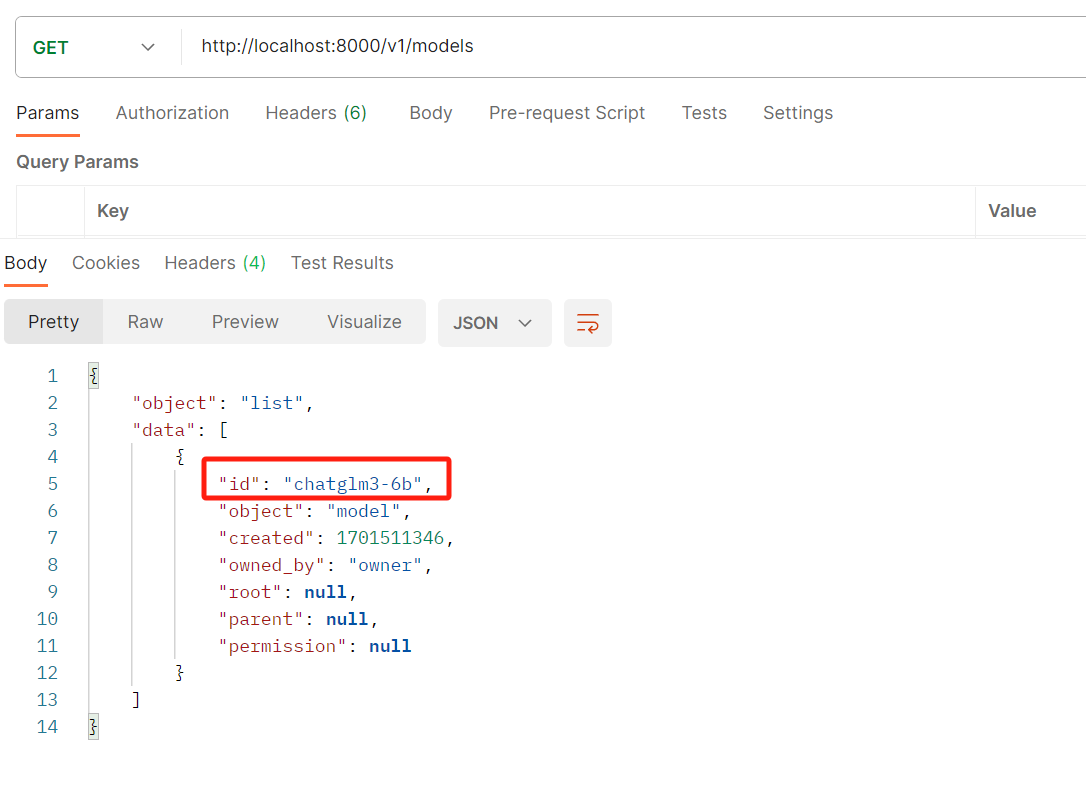
http://localhost:8000/v1/models
Chatgpt的风靡,也让其背后LLM(大型语言模型)技术中的数据隐私保护问题进一步受到关注。作为国内隐私计算行业领军者,京东科技全程深度参与了「4大报告+3大标准」的编写研制工作,取得丰硕成果。