
大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」
人工智能领域的权威吴恩达教授,在其创立的《The Batch》周报中发表了一篇博文,概述了机器学习领域六种基础算法的历史和重要性。他强调了在这一领域不断学习和更新知识的必要性。
这些算法包括线性回归、逻辑回归、梯度下降、神经网络、决策树和k均值聚类算法,它们是机器学习进步的基石。本文将进一步探讨这些算法的背景、原理、优缺点及应用场景。

背景:
线性回归是最古老也是最简单的回归算法之一,其历史可以追溯到 18 世纪,由卡尔·弗里德里希·高斯(Carl Friedrich Gauss)提出。最初的应用主要集中在天文学和物理学中,用于预测轨迹和其他连续变量。这种方法在统计学中占据了重要地位,成为许多复杂算法的基础。随着计算技术的进步,线性回归逐渐在经济学、工程学和社会科学等领域得到广泛应用。
原理:
线性回归通过寻找数据点之间的最佳拟合直线,来预测目标变量。其数学模型为:
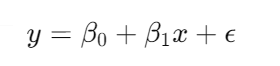
其中,( y ) 是目标变量,( x ) 是特征变量,( \beta_0 ) 和 ( \beta_1 ) 分别为截距和斜率,( \epsilon ) 是误差项。我们通过最小化均方误差(Mean Squared Error, MSE)来估计这些参数:
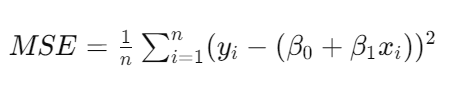
步骤:
优缺点:
优点:
缺点:
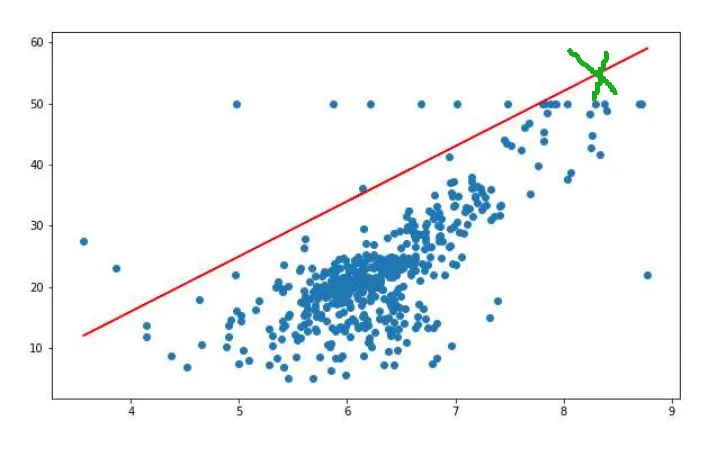
(图:对异常值敏感)
应用场景:
线性回归在经济学、金融学、社会学等领域有广泛应用。以下是一些具体的应用场景:
案例分析:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 设置matplotlib支持中文显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文显示
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
# 创建武侠世界中的功力(X)与成名年数(y)的数据
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1) # 功力等级
y = np.array([2, 3, 3.5, 5, 6, 7.5, 8, 9, 10.5, 11]) # 成名年数
# 使用线性回归模型
model = LinearRegression()
model.fit(X, y) # 训练模型
# 预测功力等级对应的成名年数
X_predict = np.array([11, 12, 13]).reshape(-1, 1) # 新的功力等级
y_predict = model.predict(X_predict) # 进行预测
# 绘制功力与成名年数的关系
plt.scatter(X, y, color='red', label='实际成名年数') # 原始数据点
plt.plot(X, model.predict(X), color='blue', label='功力成名模型') # 拟合的直线
plt.scatter(X_predict, y_predict, color='green', label='预测成名年数') # 预测点
plt.xlabel('功力等级')
plt.ylabel('成名年数')
plt.title('武侠世界的功力与成名年数关系')
plt.legend()
plt.show()
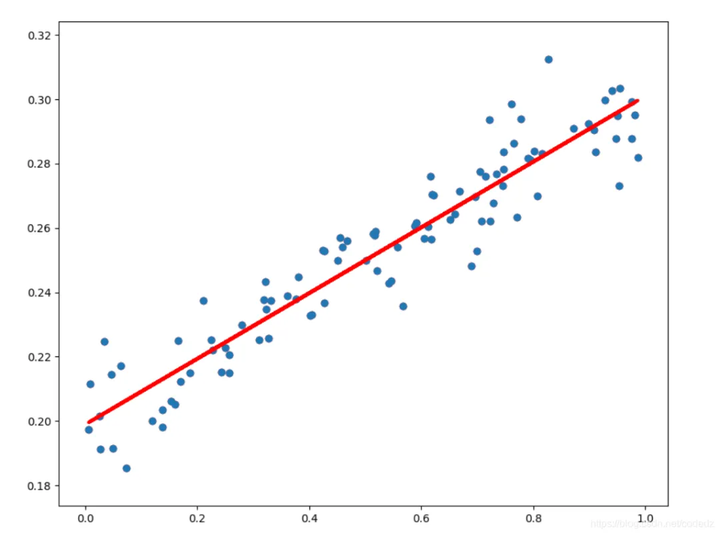
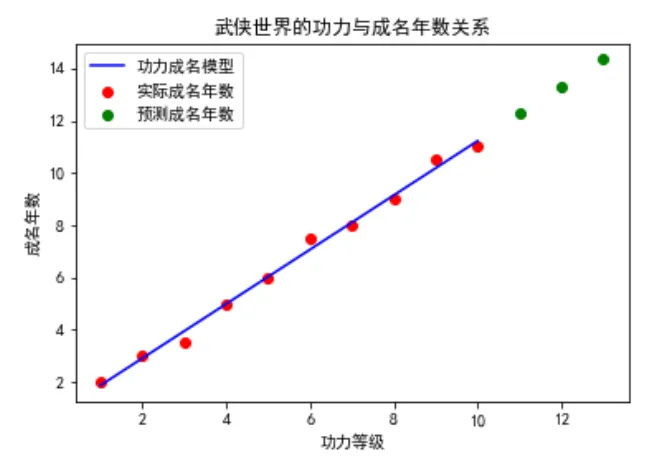
复制我们首先创建了一组简单的数据,模拟武侠世界中的人物功力等级与他们成名所需年数之间的关系。
然后,我们使用了线性回归模型来拟合这些数据,并对新的功力等级进行了成名年数的预测。
最后,通过绘图展示了功力等级与成名年数之间的线性关系,以及模型的预测效果。
添加图片注释,不超过 140 字(可选)
背景:
逻辑回归(Logistic Regression)最早由英国统计学家 David Cox 于 1958 年提出,尽管其名称中包含“回归”二字,但它实际上是一种分类算法,主要用于解决二分类问题。随着计算能力的提升和数据量的增加,逻辑回归在医学、金融、社会科学等领域得到了广泛应用,成为统计学习和机器学习的重要工具之一。
原理:
逻辑回归通过一个逻辑函数(logistic function)将线性回归的输出映射到一个 (0, 1) 区间,从而进行二分类。其数学模型为:
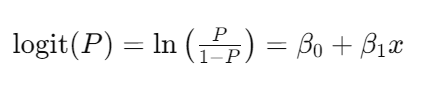
其中,( P ) 是事件发生的概率,( x ) 是特征变量,( \beta_0 ) 和 ( \beta_1 ) 分别为截距和系数。最终,通过最大似然估计法(Maximum Likelihood Estimation, MLE)来估计这些参数。
特别的,Sigmoid 函数
Sigmoid 函数:逻辑回归中使用的Sigmoid函数 能将任意实数值映射到 (0, 1) 区间,便于解释为概率。
一图胜千言:
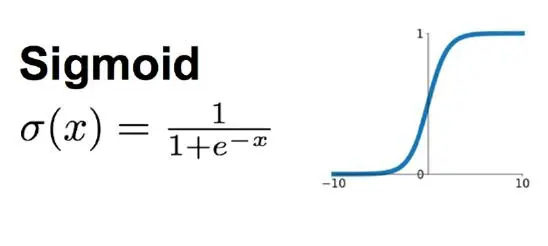
具体步骤包括:
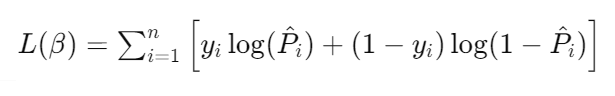
优缺点:
优点:
缺点:
应用场景:
逻辑回归在医学诊断、市场营销、信用评分等领域有广泛应用。以下是一些具体的应用场景:
案例分析:
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
import numpy as np
# 生成模拟的武侠世界功力和内功心法数据集
X, y = make_classification(n_samples=100, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=42)
# 创建逻辑回归模型对象
lr = LogisticRegression()
# 训练模型
lr.fit(X, y)
# 定义决策边界绘制函数
def plot_decision_boundary(X, y, model):
# 设置最小和最大值,以及增量
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
# 预测整个网格的值
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制决策边界和散点图
plt.contourf(xx, yy, Z, alpha=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolor='k')
plt.xlabel('功力')
plt.ylabel('内功心法')
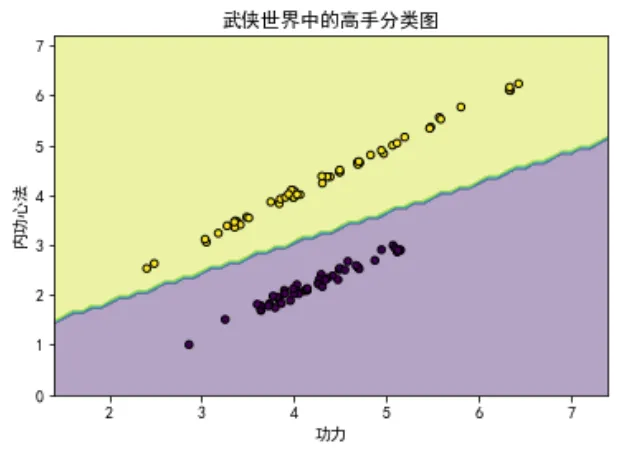
plt.title('武侠世界中的高手分类图')
# 绘制决策边界和数据点
plot_decision_boundary(X, y, lr)
plt.show()
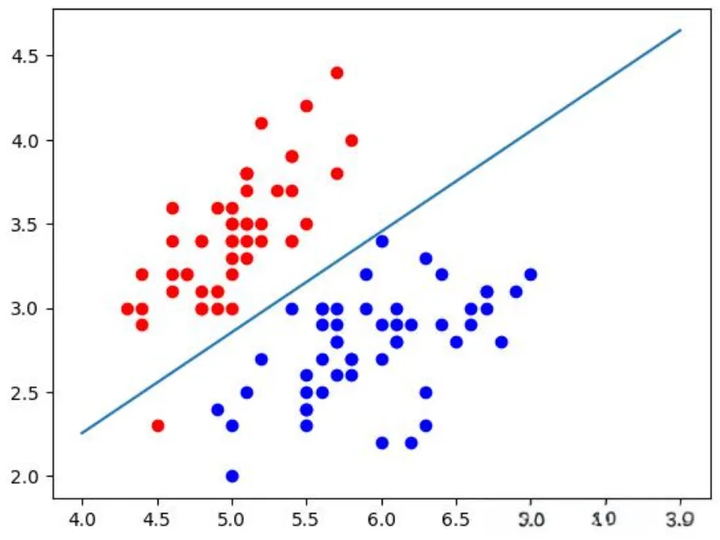
复制我们首先使用make_classification函数生成了一组模拟的二维数据,模拟武侠世界中的人物根据其功力和内功心法被分为两类:普通武者和高手。
然后,我们训练了一个逻辑回归模型并绘制了决策边界,以及不同类别的样本点,直观展示了模型的分类效果。
在图形中,我们可以看到如何根据功力和内功心法来区分不同的武侠人物。

背景:
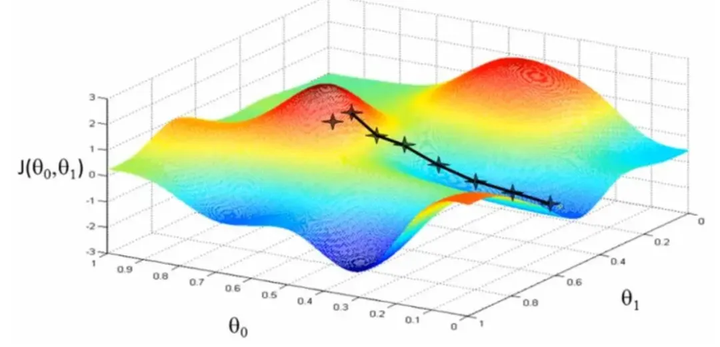
梯度下降法(Gradient Descent)由法国数学家 Augustin-Louis Cauchy 在 1847 年提出,是一种用于寻找函数最小值(或最大值)的迭代优化算法。梯度下降在机器学习中尤为重要,因为它是许多算法(如线性回归、逻辑回归和神经网络)中用于参数优化的核心方法。
原理:
梯度下降的基本思想是从一个初始点开始,沿着函数的负梯度方向迭代更新参数,以最小化损失函数。梯度是函数在该点的偏导数向量,表示函数在该点的变化方向。梯度下降的更新公式为:

具体步骤包括:
类型:
梯度下降有几种常见的变种:
优缺点:
优点:
缺点:
应用场景:
梯度下降广泛应用于各种机器学习模型的训练过程中。以下是一些具体的应用场景:
案例分析:
import numpy as np
import matplotlib.pyplot as plt
# 示例数据
X = np.array([[1, 1], [1, 2], [2, 2], [2, 3]])
y = np.dot(X, np.array([1, 2])) + 3
# 初始化参数,考虑偏置项
theta = np.random.randn(3, 1)
iterations = 1000
alpha = 0.01
# 损失函数
def compute_cost(X, y, theta):
m = len(y)
predictions = X.dot(theta)
cost = (1 / 2 * m) * np.sum(np.square(predictions - y))
return cost
# 梯度下降
def gradient_descent(X, y, theta, alpha, iterations):
m = len(y)
cost_history = np.zeros(iterations)
for i in range(iterations):
gradients = X.T.dot(X.dot(theta) - y) / m
theta = theta - alpha * gradients
cost_history[i] = compute_cost(X, y, theta)
return theta, cost_history
# 添加偏置项
X_b = np.c_[np.ones((len(X), 1)), X]
# 运行梯度下降
theta, cost_history = gradient_descent(X_b, y, theta, alpha, iterations)
# 结果可视化
plt.plot(range(1, iterations + 1), cost_history, 'b-')
plt.xlabel('迭代次数')
plt.ylabel('损失值')
plt.title('梯度下降优化损失值')
plt.show()
print(f"优化后的参数: {theta.ravel()}")
复制
背景:
决策树(Decision Tree)是一种基于树形结构的监督学习算法,用于分类和回归任务。决策树算法最早由 Ross Quinlan 在 20 世纪 80 年代提出,包括经典的 ID3、C4.5 和 CART 算法。决策树的直观和易于解释的特点,使其在金融、医疗和市场营销等领域得到了广泛应用。
原理:
决策树通过递归地将数据集分割成更小的子集来构建树状模型。每个内部节点代表一个特征,每个分支代表该特征的一个取值,每个叶节点代表一个类别或预测值。决策树的构建过程包括以下步骤:
信息增益:信息增益用于衡量某一特征对数据集进行分割时所带来的信息熵的减少。信息熵(Entropy)表示数据集的纯度,计算公式为:

基尼系数:基尼系数(Gini Index)用于衡量数据集的不纯度,计算公式为:
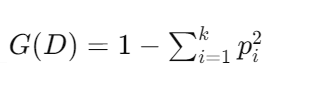
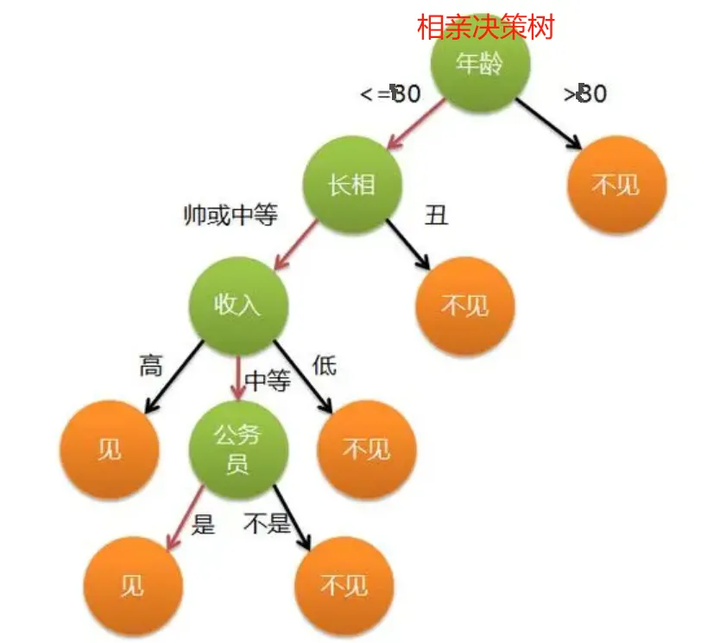
优缺点:
优点:
缺点:
应用场景:
决策树在金融、医疗、市场营销等领域有广泛应用。以下是一些具体的应用场景:
案例分析:
让我们来看一个具体的案例:使用决策树进行客户分类。假设我们有一个数据集,其中包含客户的年龄、收入和购买情况(0 表示未购买,1 表示购买)。我们可以使用决策树来建立客户特征与购买情况之间的关系模型。
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
import numpy as np
# 生成武侠风格的数据,确保所有特征值为正数
X, y = make_classification(n_samples=200, n_features=2, n_redundant=0, n_informative=2,
n_clusters_per_class=1, random_state=42)
X += np.abs(X.min()) # 平移数据确保为正
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建决策树模型,并设置最大深度为3
dt = DecisionTreeClassifier(max_depth=3)
# 训练模型
dt.fit(X_train, y_train)
# 绘制数据点和决策边界
def plot_decision_boundary(model, X, y):
# 设置最小和最大值,以及增量
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
np.arange(y_min, y_max, 0.01))
# 预测整个网格的值
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制决策边界
plt.contourf(xx, yy, Z, alpha=0.4)
# 绘制不同类别的样本点
plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], c='red', marker='x', label='普通武者')
plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], c='blue', marker='o', label='武林高手')
plt.xlabel('功力值')
plt.ylabel('内功心法')
plt.title('武侠世界中的武者分类图')
plt.legend()
# 绘制决策边界和数据点
plot_decision_boundary(dt, X, y)
plt.show()
复制这段代码首先生成了一组包含200个样本的武侠风格数据,每个样本有两个特征:功力值和内功心法,目标是分类武者是否为武林高手。
然后,我们使用DecisionTreeClassifier创建了一个决策树模型并对其进行训练。
通过定义plot_decision_boundary函数,我们绘制了模型的决策边界,并使用不同颜色和形状标记来区分普通武者和武林高手,直观地展示了决策树在二分类任务中的分类效果。
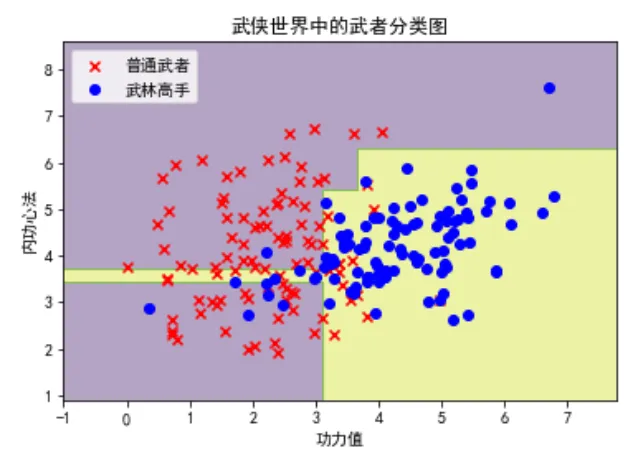
(你可以修改 max_depth 看看有什么变化)
背景:
神经网络(Neural Networks)起源于 20 世纪 40 年代,由 Warren McCulloch 和 Walter Pitts 提出。他们的工作灵感来源于人脑的结构和功能,希望通过数学模型模拟生物神经元的工作方式。神经网络的发展经历了多次起伏,直到 2006 年 Geoffrey Hinton 等人提出深度学习(Deep Learning)的概念,神经网络才重新获得关注,并迅速成为人工智能领域的热点。
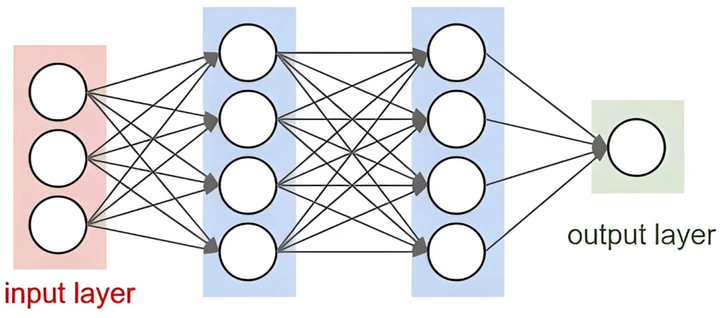
原理:
神经网络由多个层级的节点(神经元)组成,每个节点通过加权连接传递信号。一个典型的神经网络结构包括输入层、隐藏层和输出层。输入层接收原始数据,隐藏层通过加权求和和激活函数处理数据,输出层生成最终的预测结果。每层节点的输出由前一层节点的加权和通过激活函数计算得到:
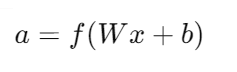
其中,( a ) 是输出,( W ) 是权重矩阵,( x ) 是输入向量,( b ) 是偏置向量,( f ) 是激活函数。
激活函数:
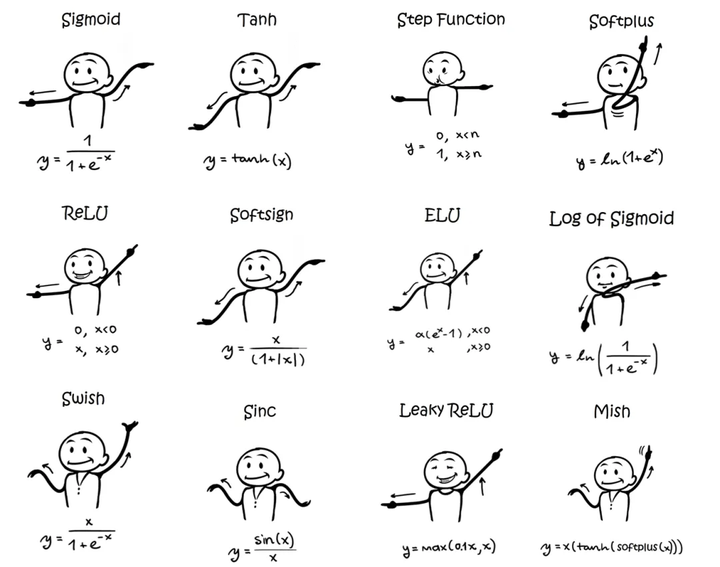
训练: 神经网络通过反向传播算法(Backpropagation)进行训练。反向传播通过计算损失函数的梯度,调整网络中的权重和偏置,以最小化预测误差。训练过程包括以下步骤:
优缺点:
优点:
缺点:
应用场景:
神经网络在图像识别、语音识别、自然语言处理等领域有广泛应用。以下是一些具体的应用场景:
案例分析:
让我们来看一个具体的案例:使用神经网络进行手写数字识别。假设我们使用经典的 MNIST 数据集,其中包含 28x28 像素的手写数字图片,每张图片对应一个数字标签(0-9)。
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.utils import to_categorical
# 加载数据
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 预处理数据
X_train = X_train.reshape(-1, 28 * 28) / 255.0
X_test = X_test.reshape(-1, 28 * 28) / 255.0
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# 创建模型
model = Sequential([
Flatten(input_shape=(28 * 28,)),
Dense(128, activation='relu'),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
# 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print(f"Test Accuracy: {accuracy:.4f}")
复制在这个例子中,我们使用 TensorFlow 和 Keras 库创建了一个简单的全连接神经网络,用于识别手写数字。通过训练模型,我们可以在测试数据上评估其准确性,并可视化模型的性能。

背景:
K均值聚类(K-means Clustering)是一种常用的无监督学习算法,用于将数据集划分为 K 个互斥的簇。该算法由 Stuart Lloyd 于 1957 年在电话信号处理研究中首次提出,1967 年由 James MacQueen 正式命名并推广应用。K均值聚类在许多领域得到广泛应用,如图像处理、市场营销、模式识别等。

原理:
K均值聚类通过迭代优化的方法,将数据点分配到 K 个簇中,使得每个簇内的数据点与簇中心(质心)之间的距离平方和最小化。具体步骤包括:
算法的目标是最小化以下目标函数:

优缺点:
优点:
缺点:
比如下图数据分布,使用 K-means 的效果就很忧伤了
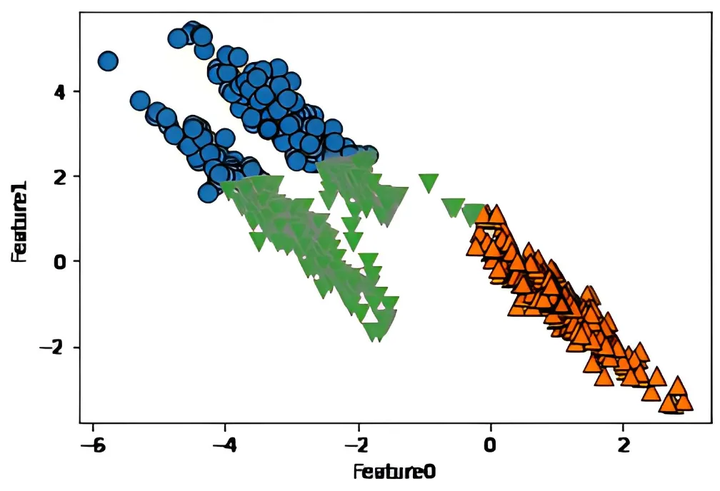
应用场景:
K均值聚类在市场营销、图像处理、模式识别等领域有广泛应用。以下是一些具体的应用场景:
案例分析:
让我们来看一个具体的案例:使用K均值聚类进行客户分类。假设我们有一个数据集,其中包含客户的年龄和收入。我们可以使用K均值聚类将客户分为三个群体。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
# 示例数据
data = {
'age': [25, 45, 35, 50, 23, 31, 22, 35, 42, 51],
'income': [50000, 100000, 75000, 120000, 40000, 60000, 45000, 80000, 110000, 130000]
}
df = pd.DataFrame(data)
# 创建K均值模型
kmeans = KMeans(n_clusters=3)
kmeans.fit(df)
# 预测聚类结果
df['cluster'] = kmeans.labels_
# 可视化聚类结果
plt.scatter(df['age'], df['income'], c=df['cluster'], cmap='viridis')
plt.xlabel('Age')
plt.ylabel('Income')
plt.title('Customer Segments')
plt.show()
print(df)
复制在这个例子中,我们使用 sklearn 库中的 KMeans 模型来对客户的年龄和收入进行聚类。通过训练模型,我们可以将客户分为三个群体,并可视化聚类结果。同时,可以输出每个客户的聚类标签。
线性回归,一种简单而有效的回归算法,
逻辑回归,一种简单而有效的分类算法,
梯度下降,一种基本且重要的优化算法,
决策树,一种直观且易于解释的机器学习模型,
神经网络,一种强大的深度学习模型,
K均值聚类,一种简单高效的无监督学习算法,
这些基础算法构成了机器学习的核心,无论是线性回归的简洁性,还是神经网络的复杂性,都展示了它们在不同应用场景中的价值。同时,这些算法正被不断改进和创新,Enjoy

烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;我们一起,让更多人享受智能乐趣
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖