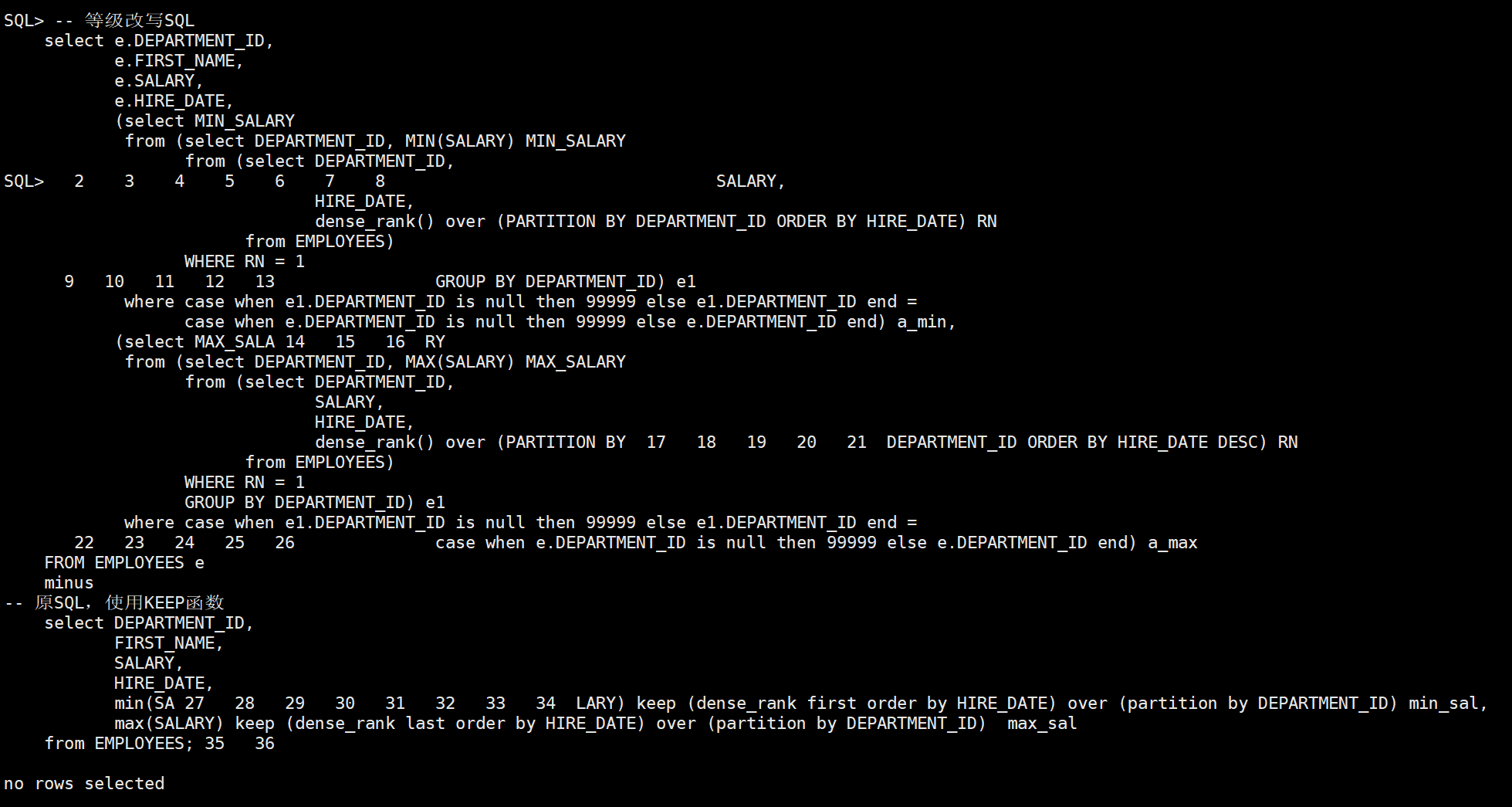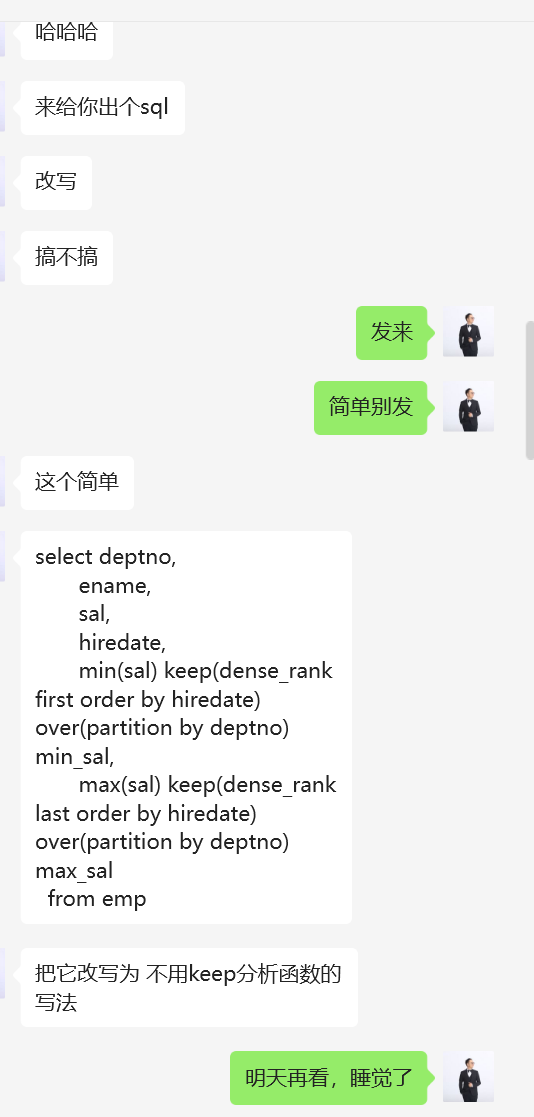
一哥们出条sql题给我玩,将下面sql改成不使用keep分析函数的写法。
select deptno, ename, sal, hiredate, min(sal) keep(dense_rank first order by hiredate) over(partition by deptno) min_sal, max(sal) keep(dense_rank last order by hiredate) over(partition by deptno) max_sal from emp;复制
我一开始改错了,被这哥们喷菜鸡,我草。
-- 错误等价改写,逻辑不等价 with x as ( select e1.deptno, e1.ename, e1.sal, e1.hiredate, row_number() over (partition by DEPTNO order by HIREDATE) rn_first, row_number() over (partition by DEPTNO order by HIREDATE DESC) rn_last from EMP e1) select e.deptno, e.ename, e.sal, e.hiredate, x1.SAL, x2.SAL from emp e inner join x x1 on e.DEPTNO = x1.DEPTNO and x1.rn_first = 1 inner join x x2 on e.DEPTNO = x2.DEPTNO and x2.rn_last = 1;复制
我换了张表测试下,发现上面改写是逻辑有问题,如果同一个组内有相同日期的,分组字段内有NULL值的,确实会导致SQL结果集不一致。
-- 将EMP表替换成EMPLOYEES,如果使用上面等价改写就错误了。 select DEPARTMENT_ID, FIRST_NAME, SALARY, HIRE_DATE, min(SALARY) keep(dense_rank first order by HIRE_DATE) over(partition by DEPARTMENT_ID) min_sal, max(SALARY) keep(dense_rank last order by HIRE_DATE) over(partition by DEPARTMENT_ID) max_sal from EMPLOYEES;复制
最终等价改写的SQL,增加了分组字段内有NULL值的逻辑,和处理一个组内有相同日期的逻辑。
select e.DEPARTMENT_ID, e.FIRST_NAME, e.SALARY, e.HIRE_DATE, (select MIN_SALARY from (select DEPARTMENT_ID, MIN(SALARY) MIN_SALARY from (select DEPARTMENT_ID, SALARY, HIRE_DATE, dense_rank() over (PARTITION BY DEPARTMENT_ID ORDER BY HIRE_DATE) RN from EMPLOYEES) WHERE RN = 1 GROUP BY DEPARTMENT_ID) e1 where case when e1.DEPARTMENT_ID is null then 99999 else e1.DEPARTMENT_ID end = case when e.DEPARTMENT_ID is null then 99999 else e.DEPARTMENT_ID end) a_min, (select MAX_SALARY from (select DEPARTMENT_ID, MAX(SALARY) MAX_SALARY from (select DEPARTMENT_ID, SALARY, HIRE_DATE, dense_rank() over (PARTITION BY DEPARTMENT_ID ORDER BY HIRE_DATE DESC) RN from EMPLOYEES) WHERE RN = 1 GROUP BY DEPARTMENT_ID) e1 where case when e1.DEPARTMENT_ID is null then 99999 else e1.DEPARTMENT_ID end = case when e.DEPARTMENT_ID is null then 99999 else e.DEPARTMENT_ID end ) a_max FROM EMPLOYEES e;复制
差集比较后是等价的: