生成内容形式主要包含三种,PGC(Professionally Generated Content)、UGC(User Generated Content)、AIGC(Artificially Intelligent Generated Content)。也可以简单理解为生成内容形式的三个发展阶段。
专业生成内容是由专业人士创作编辑发布内容。
简单来说是文章要由作者创作,新闻要由记者创作,专业的人创作内容。
该形式起源于传统媒体时代,例如报纸、杂志、电视、电影等。
用户生成内容是由普通用户创作编辑发布内容。
简单来说就是每个人都可以创作内容,通过互联网发布文字、视频、音频等内容。
是互联网趋势下的一种内容生成方式,对传统营销、广告、媒体等产业产生了重大影响。比如自媒体博主等。 优点是创作门槛低,内容更加个性化,缺点是信息泛滥,质量不一,监管难度大等。
人工智能生成内容是AI创作生成内容。
简单来说就是已经发展到我们看到的内容可能就是AI制作的。
是人工智能发展阶段下的一种新型内容生成方式。利用自然语言处理技术与AI技术来生成内容。比如ChatGPT、PiKa、Sora、文心一言等。
应用范围广泛,发展到今天,已经支持多模态AI,允许输入文本、图片、视频等多种媒体素材,经由AIGC处理输出生成想要的文本、图片、视频、音频等内容。
2021年起,市场开始探索小说推文,通过爆火小说,借助抖音、小红书、bilibili等平台发布小说推文视频,推流达到吸粉,引导付费的模式实现盈利,逐步发展趋于稳定盈利。
2023年是小说推文的爆发期,加上火爆的ChatGPT、Midjounery、TTSMAKER、剪映等平台支撑,形成了一套完善的生成式AI链路。极大的降低了小说推文制作门槛,且据统计当时随便制作一个推文视频,播放量基本上在20W左右。
2024年Sora发布的文生视频大模型,给国内外带来了极大震撼,时长接近1分钟,视频画质接近电影级。让人感叹AI已经发展到,快要不易区分人工制作内容和AI制作内容。同时也让国内感受到和国外在人工智能领域的差距。
本期说下国内小说推文工具,不是那种素材混剪的工具,而是借助多模态生成式AI,具备文生图、图生视频、文生视频能力的工具。
比如腾讯动态漫画、AI剧本、瓦兔推文、极虎漫剪、推文助手、智影AI等工具。
这些工具大都支持文生图能力,但支持图生视频能力仅腾讯动态漫画、智影AI。动态漫画生成分镜图片后,有个一键动效功能,允许将图片生成2s时长的视频。智影AI有一个动态视频功能,允许将图片生成4s的视频。
一款小白也能轻松制作故事转视频的AI创作神器。
产品能够对故事文案进行拆分镜头,提取故事中的角色和场景;并自动绑定角色/场景和分镜镜头,达到角色场景一致性。
借助ChatGPT分析文案拆分分镜,提取角色场景。
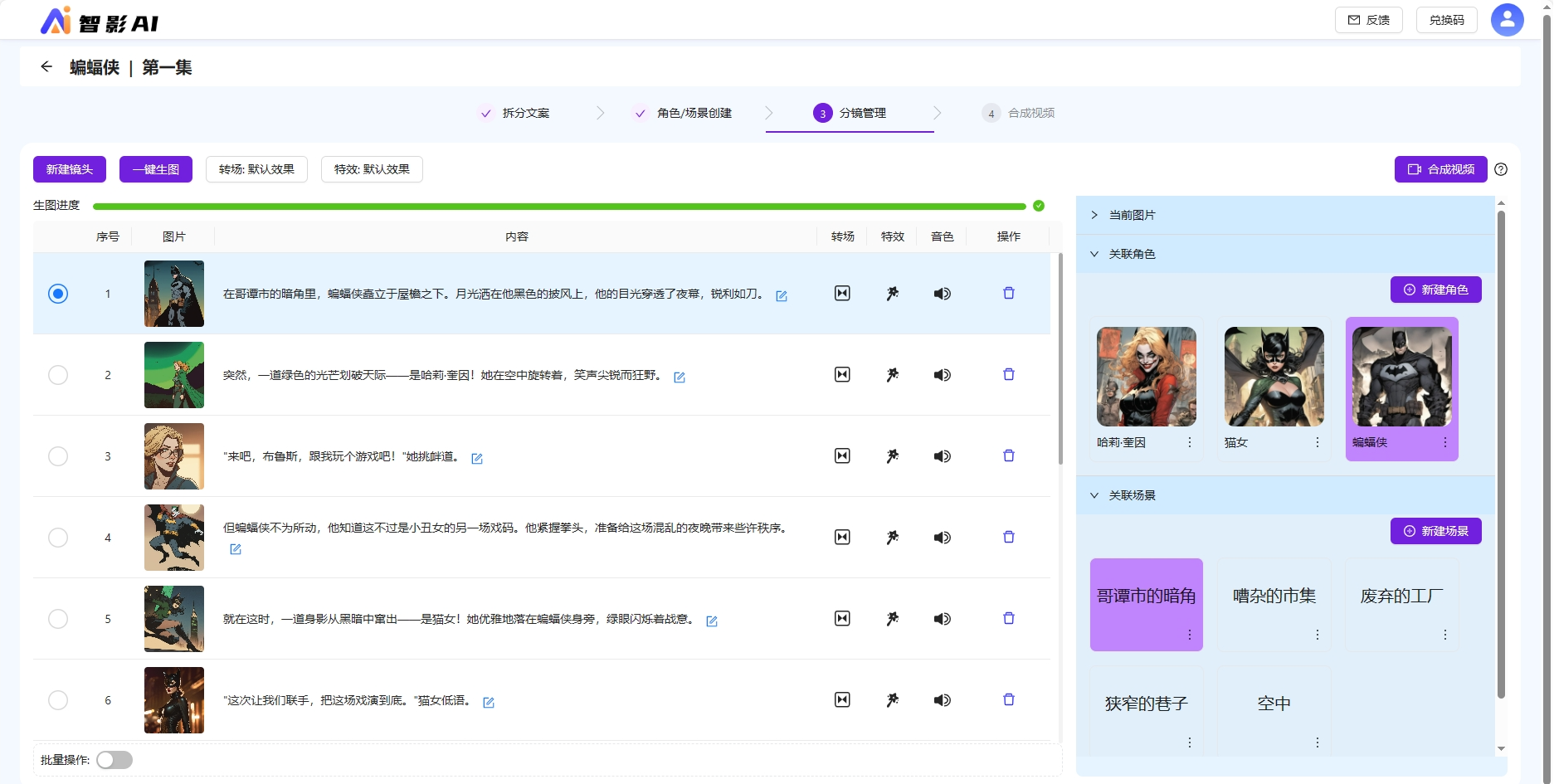
角色/场景支持新建编辑;支持调整角色描述重新生成角色图片。
支持对分镜批量绑定关联角色/场景;镜头支持新建编辑;支持修改分镜描述重新生成分镜图片;支持分镜图片生成4s的动态视频。
借助Fooocus(已支持)、Midjounery(规划中)文生图能力,根据文本描述AI绘图。
借助Stable Diffusion Video(已支持)、PiKa(规划中)图生视频能力,根据分镜图片AI生成视频。
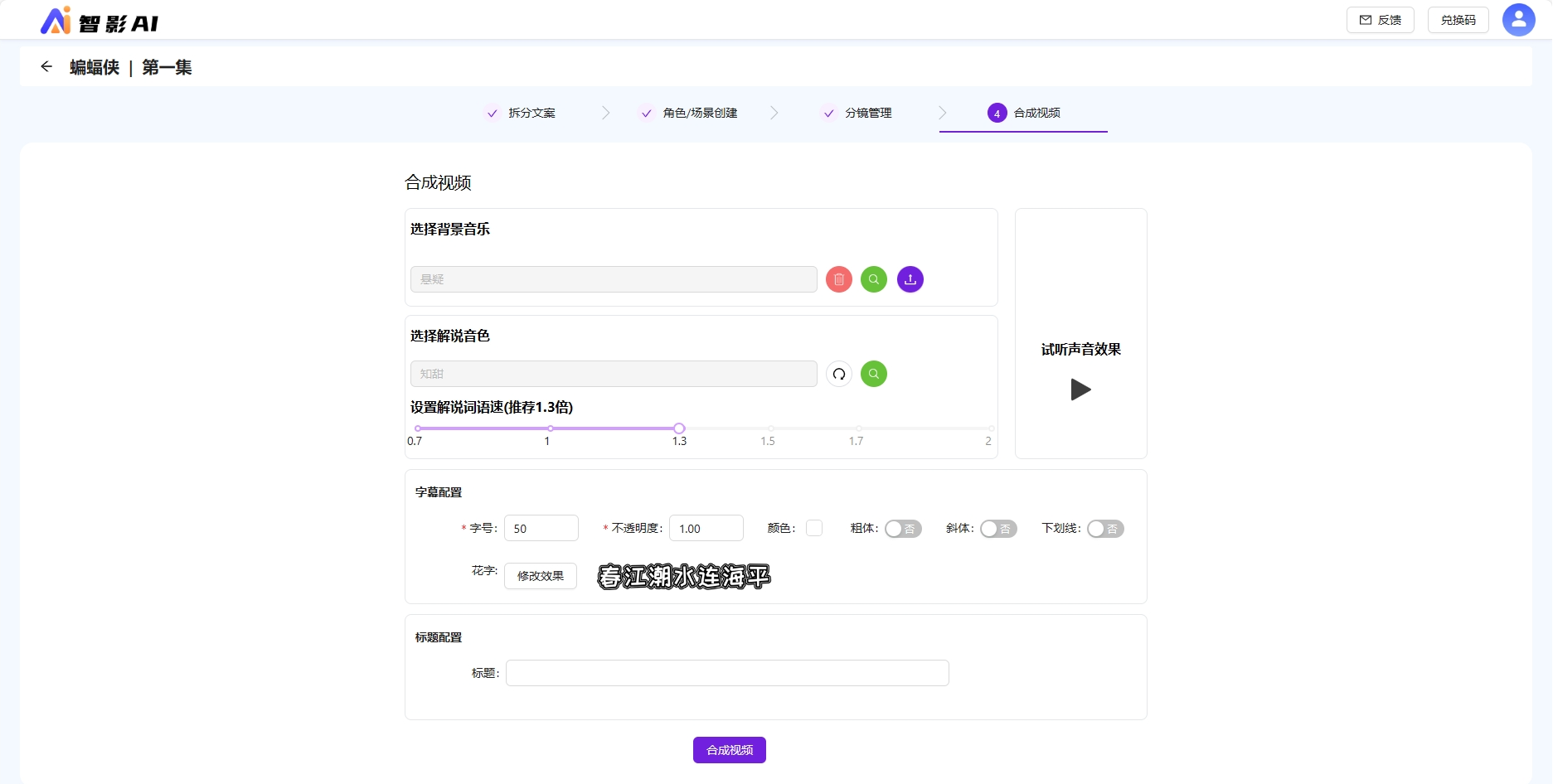
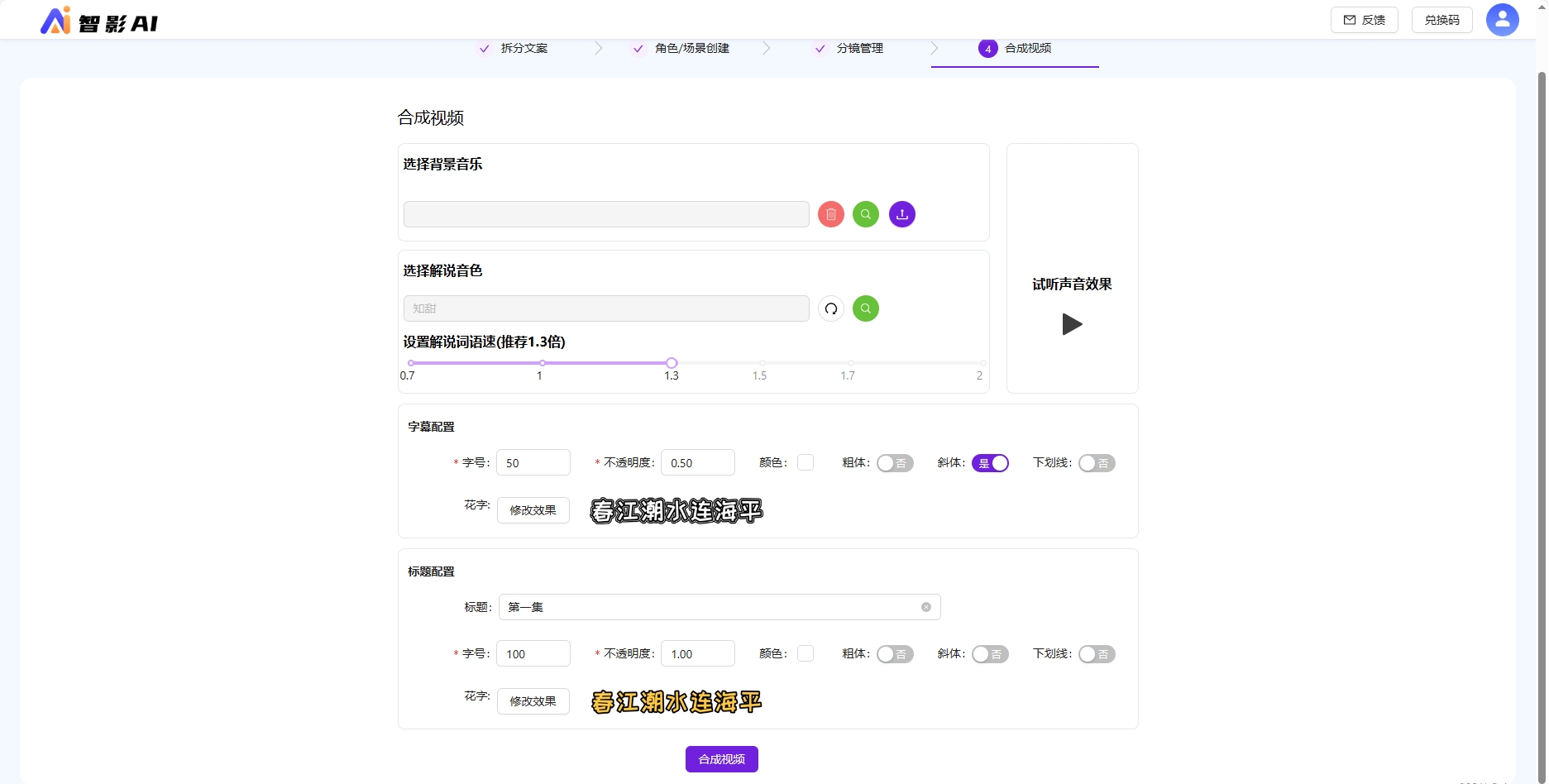
允许选择背景音乐,解说音色,解说语速等;允许对字幕、标题调整字号、粗体、下划线等、支持配置花字效果。
借助剪映、阿里云视频合成,拼接音频、字幕、视频、图片制作视频
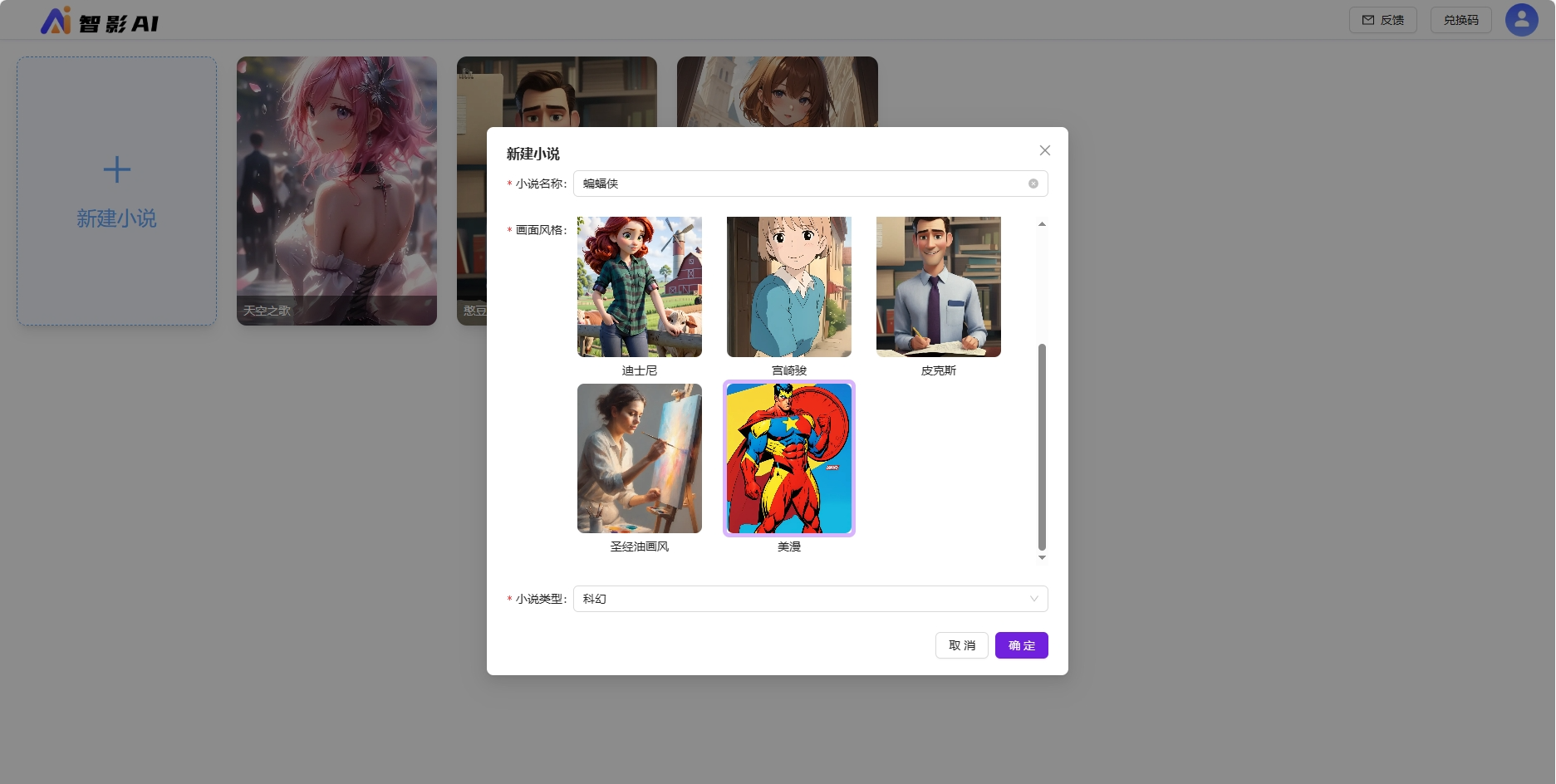
填写小说名称、选择画面风格、小说类型,点击确定新建小说。
一组镜头可以合成一个视频。这一组镜头构成一个作品。多个作品构成一个小说。
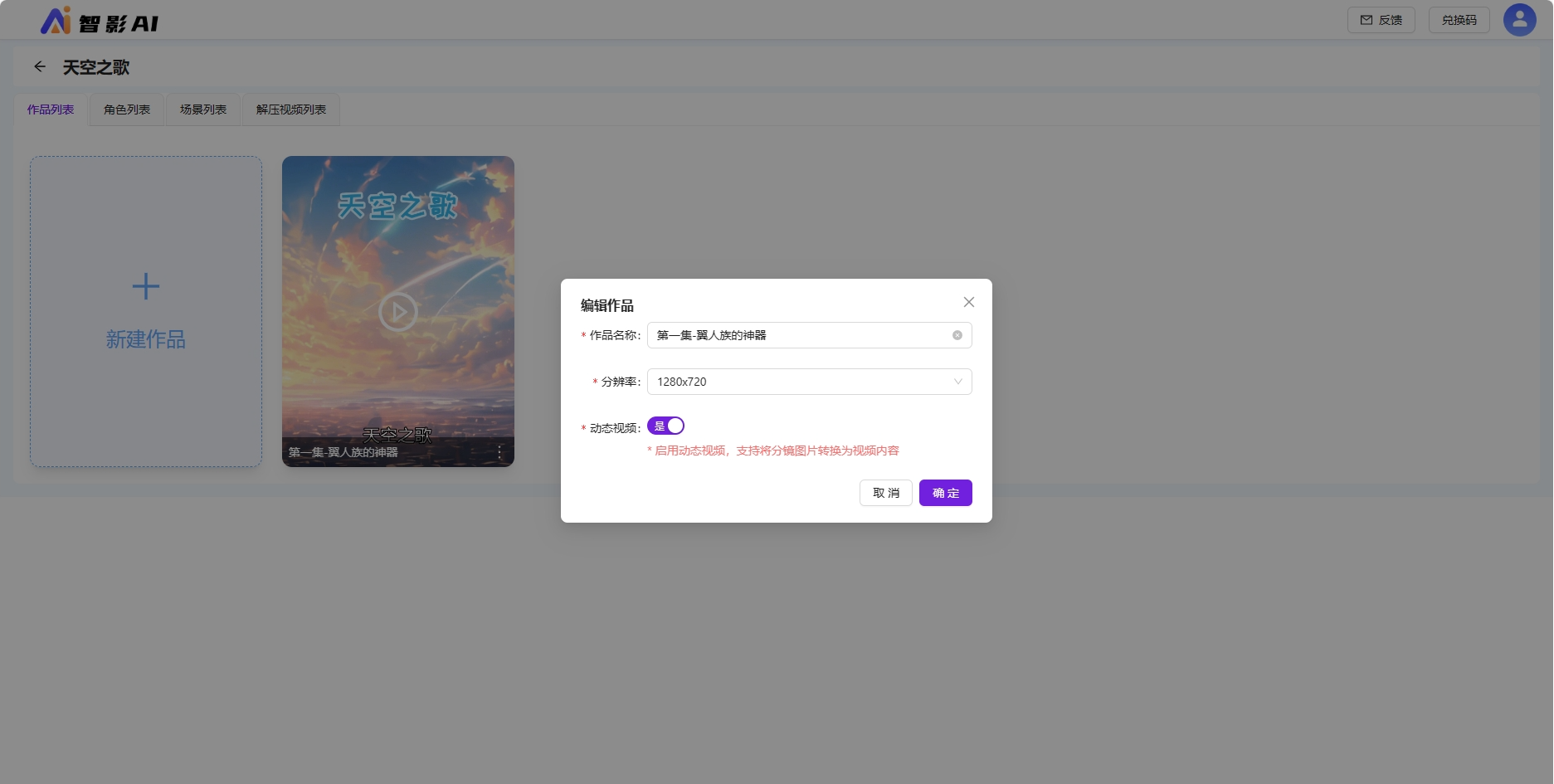
填写作品名称、选择分辨率、选择是否开启动态视频,默认不开启,点击确定新建作品。
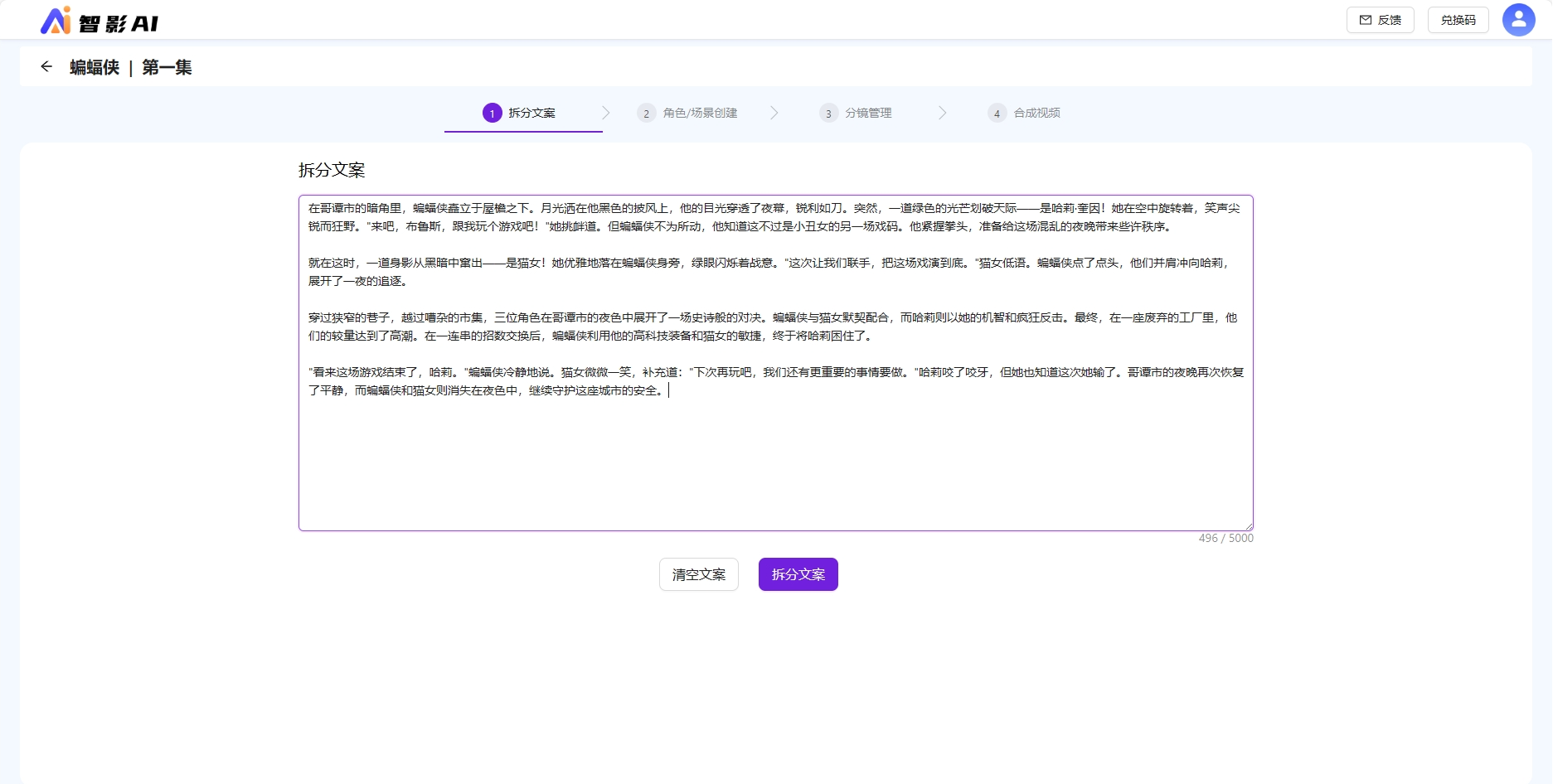
粘贴复制过来故事文案,此处是通过文心一言生成的300字左右的故事文案。点击拆分文案拆分分镜,自动提取角色场景,并自动绑定角色场景到分镜。
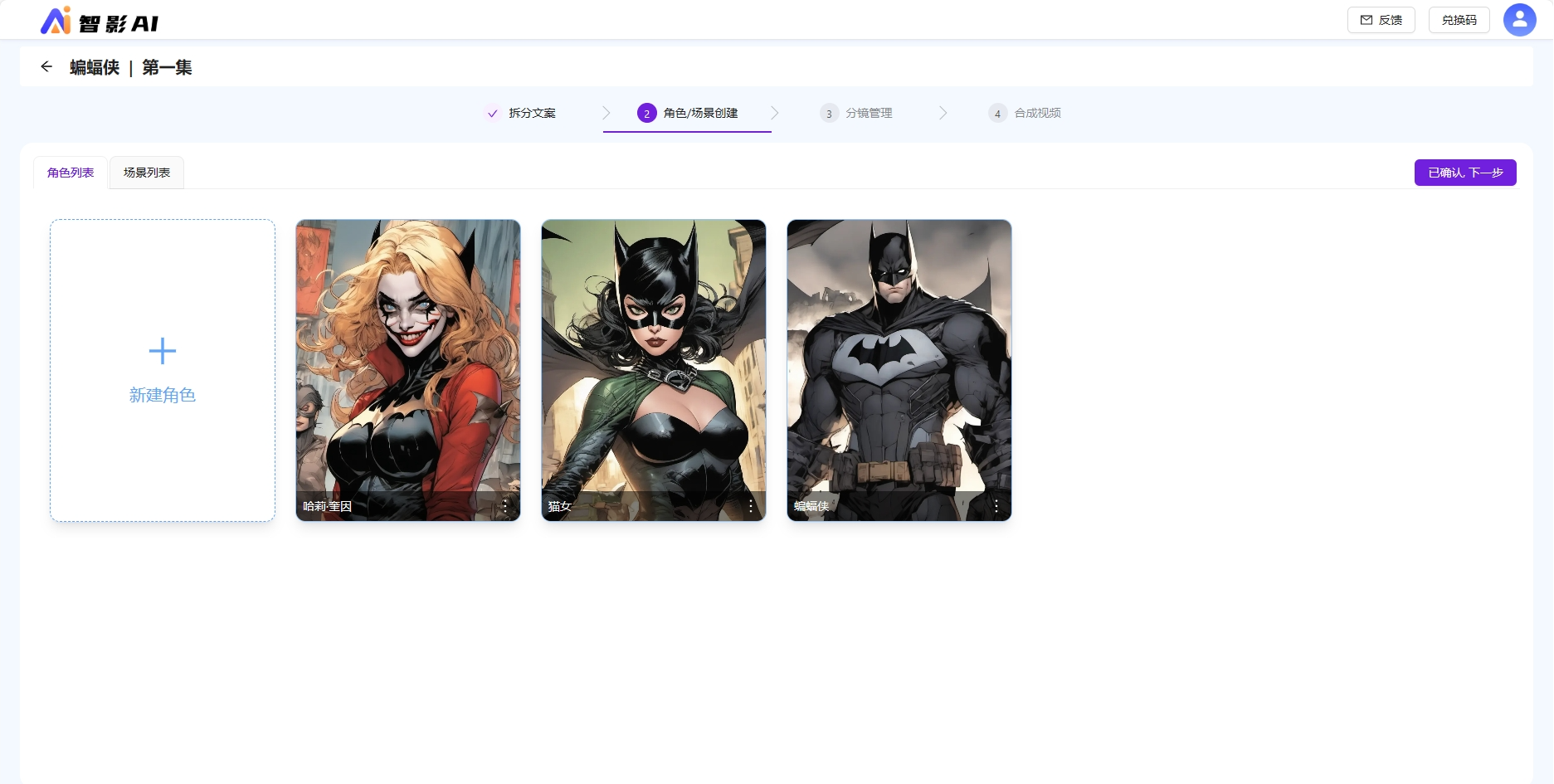
智影AI会自动提取角色场景,如果AI提取存在漏提或误提的情况,可以手工维护角色/场景,新建或重新生成角色图片。
确认角色场景后,可以点击下一步,提示是否跳过一键生图。不跳过则自动生成分镜图片。跳过则不自动生成分镜图片,手工生成。此处点击确定,使用一键生图功能,希望自动生图。
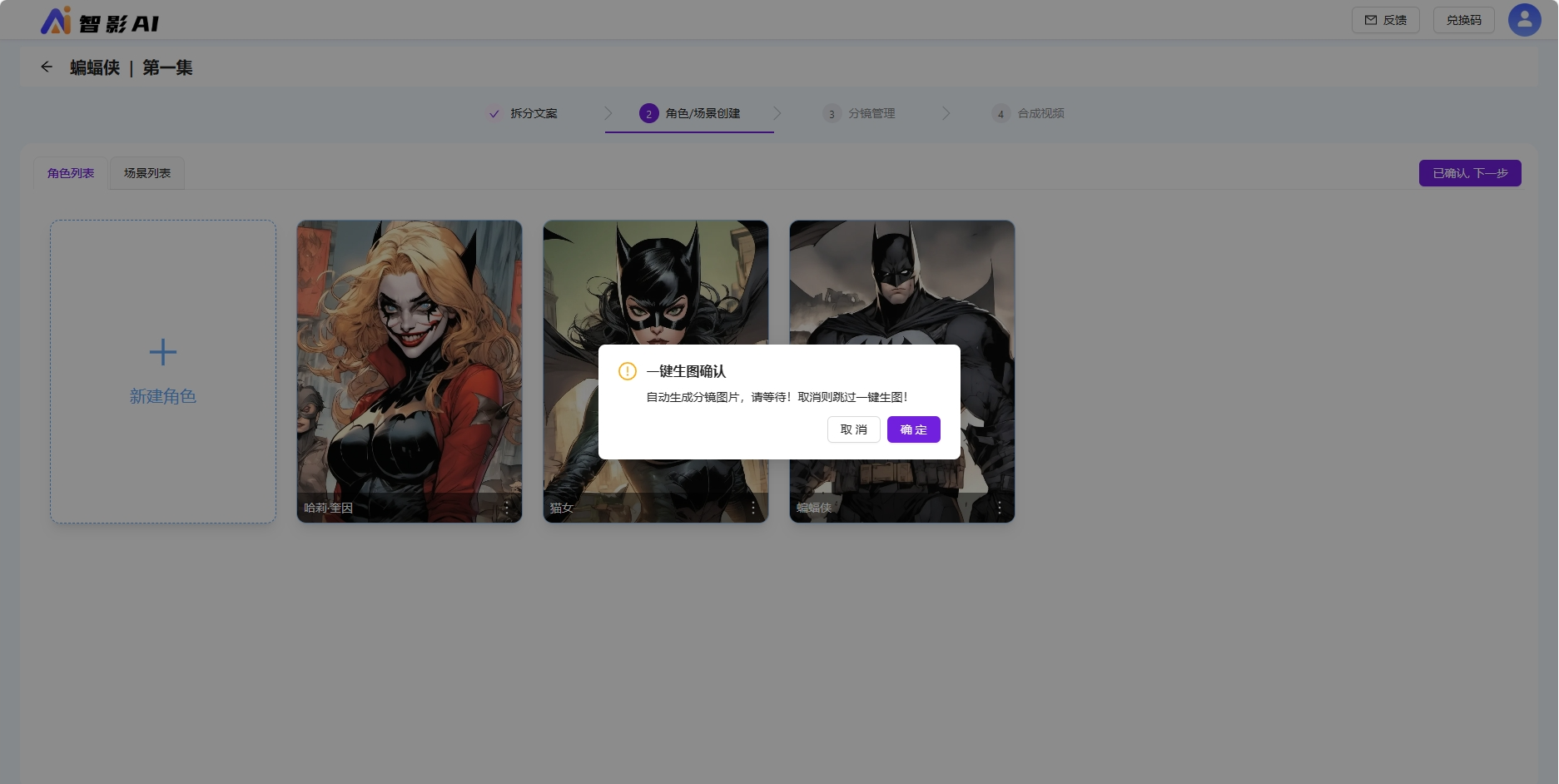
上一步不跳过一键生图,会自动对分镜提交生成图片任务。
如果上一步跳过一键生图,也可以进入到分镜管理步骤后,维护好分镜信息,再点击一键生图按钮即可。或者手工对单个镜头右侧编辑区域,点击重新生成图片按钮重新生图。
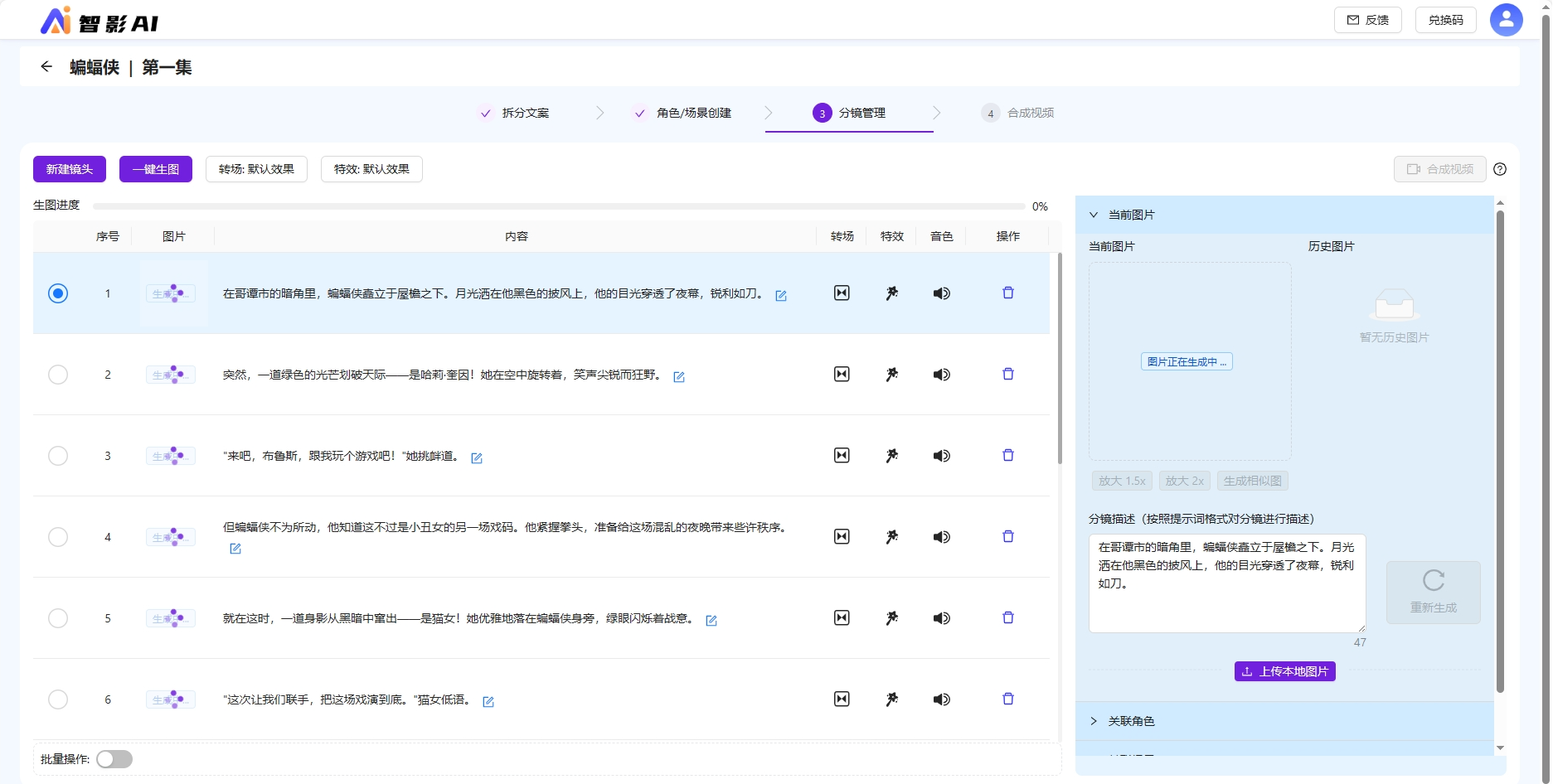
待图片任务全部生成完成,可以点击合成视频进入下一步。

合成视频可以选择背景音乐、解说音色、字幕标题等配置,点击合成视频等待视频合成。
在小说作品列表可以查看作品合成视频效果。
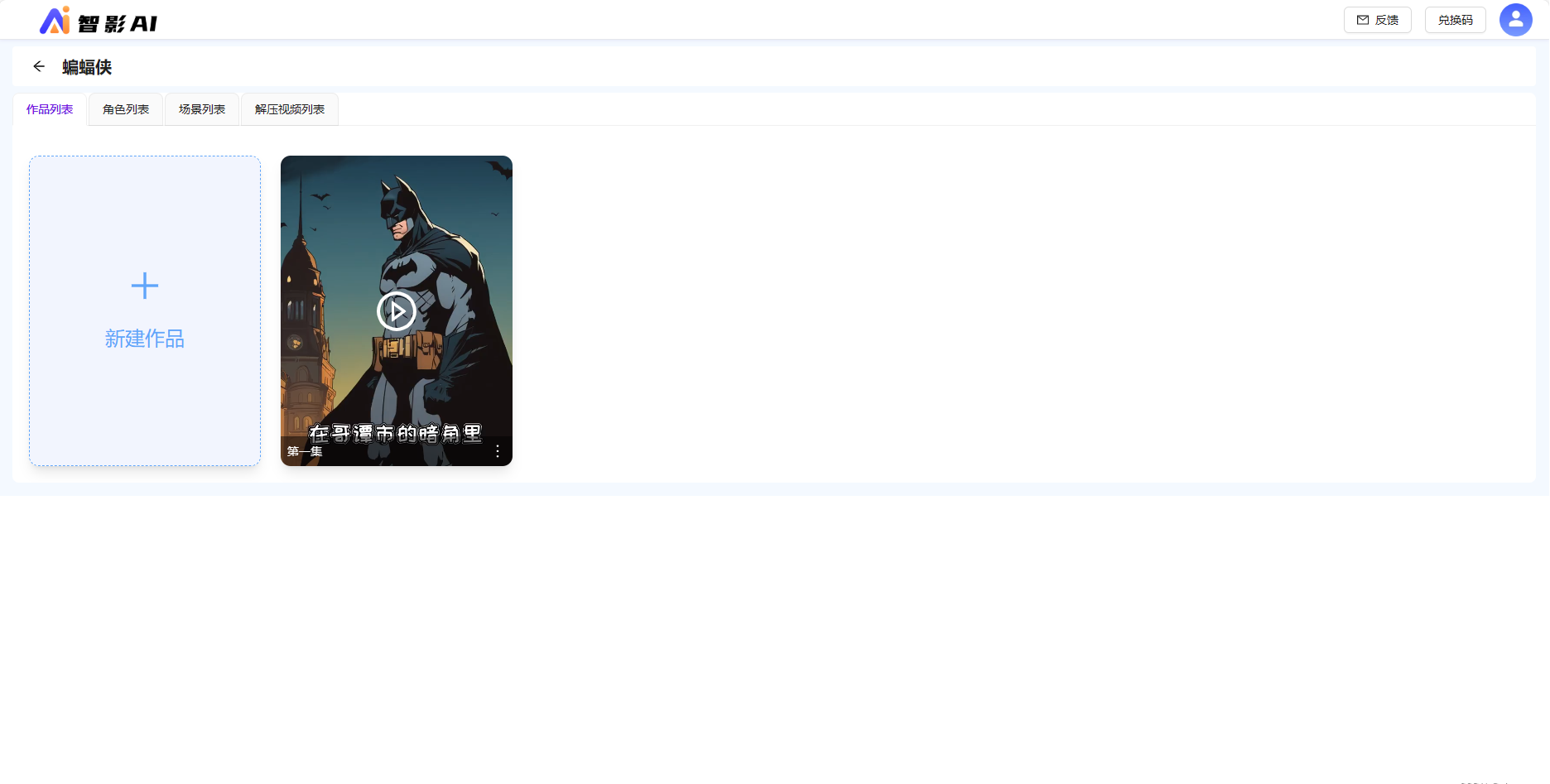

角色一致性,对于以上示例,因为用的形象是蝙蝠侠,AI对蝙蝠侠其实是有很多知识存储的,所以在角色一致性上表现良好。
对于AI不知道的角色,通过AI工具实现角色一致性就比较困难了。同样的文案描述,在多次生成结果上无法保证角色形象一致,场景一致。
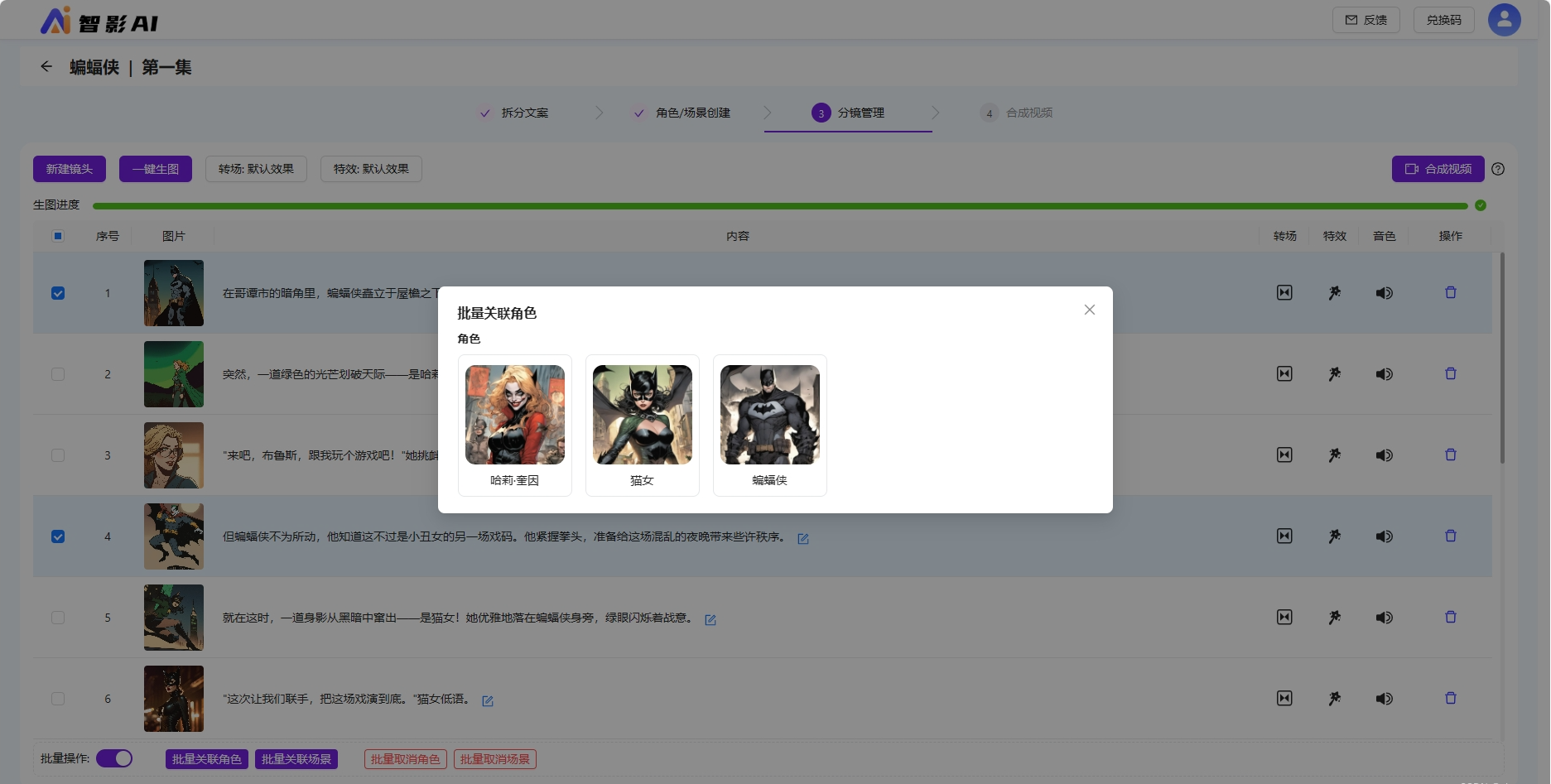
此处提供角色场景绑定功能,来间接实现角色场景一致性。
在分镜管理下,允许对单个镜头进行角色场景绑定。也提供了批量操作,对于分镜较多的作品,避免重复操作提升效率。
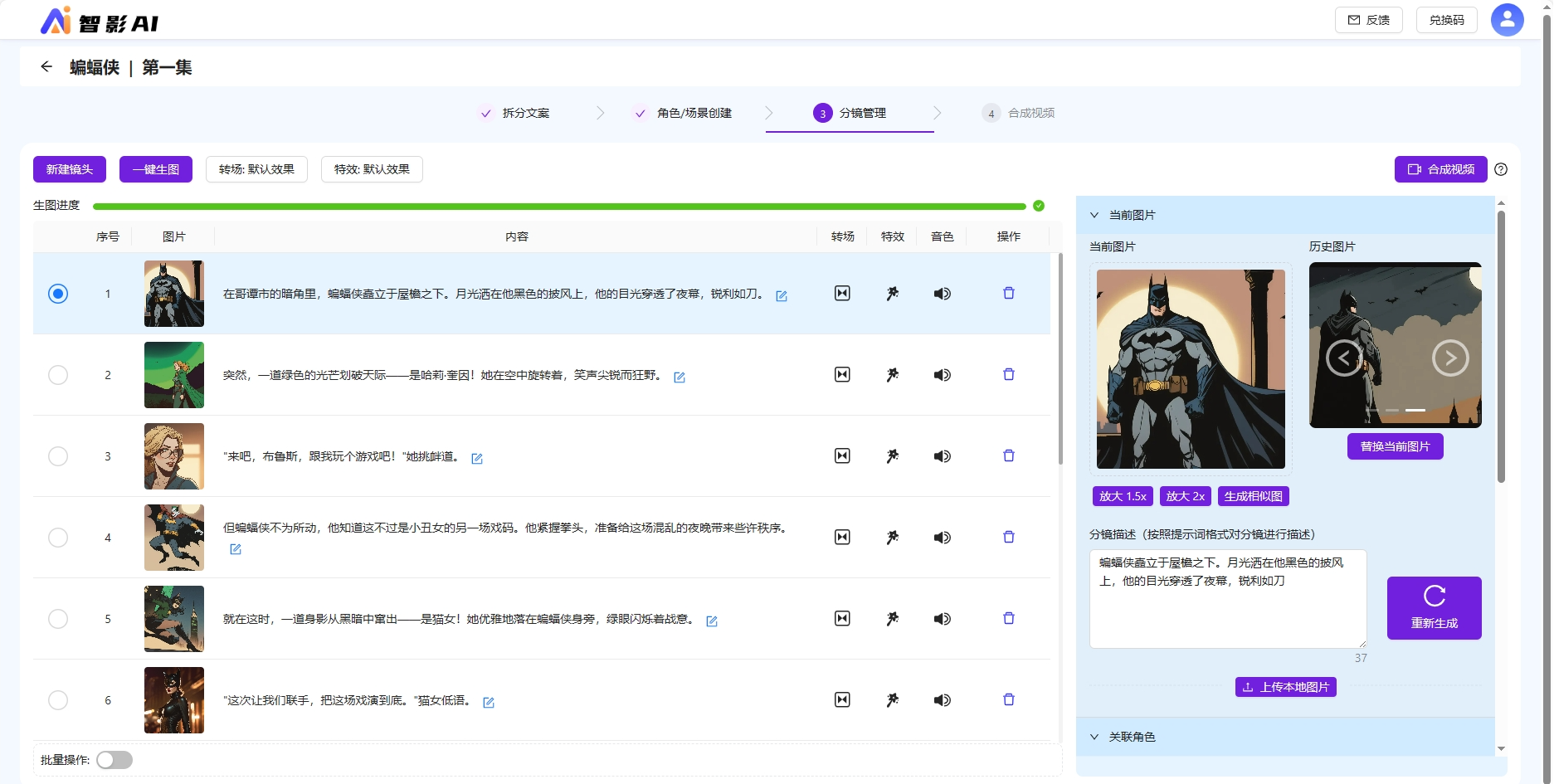
对于一键生图效果不好的情况下,或者重新调整关联角色场景后的分镜,可以修改分镜描述重新生图。
生成相似图,利用以图生图能力,生成相近效果的图片,可以用作微调。
开放了上传分镜图片的功能,更加的灵活,允许设计师上传自己做的图片,如果认为AI绘图效果不好,或者根据AI绘图本地调优后,可以上传覆盖。
历史图片可以看到生成过的图片,多次生图可以选择效果较好的一张,替换当前图片作为分镜图片。
支持放大1.5、放大2倍,使得图片分辨率清晰度更高。可以在选定分镜图片后,放大图片质量用于合成视频,保证视频质量。
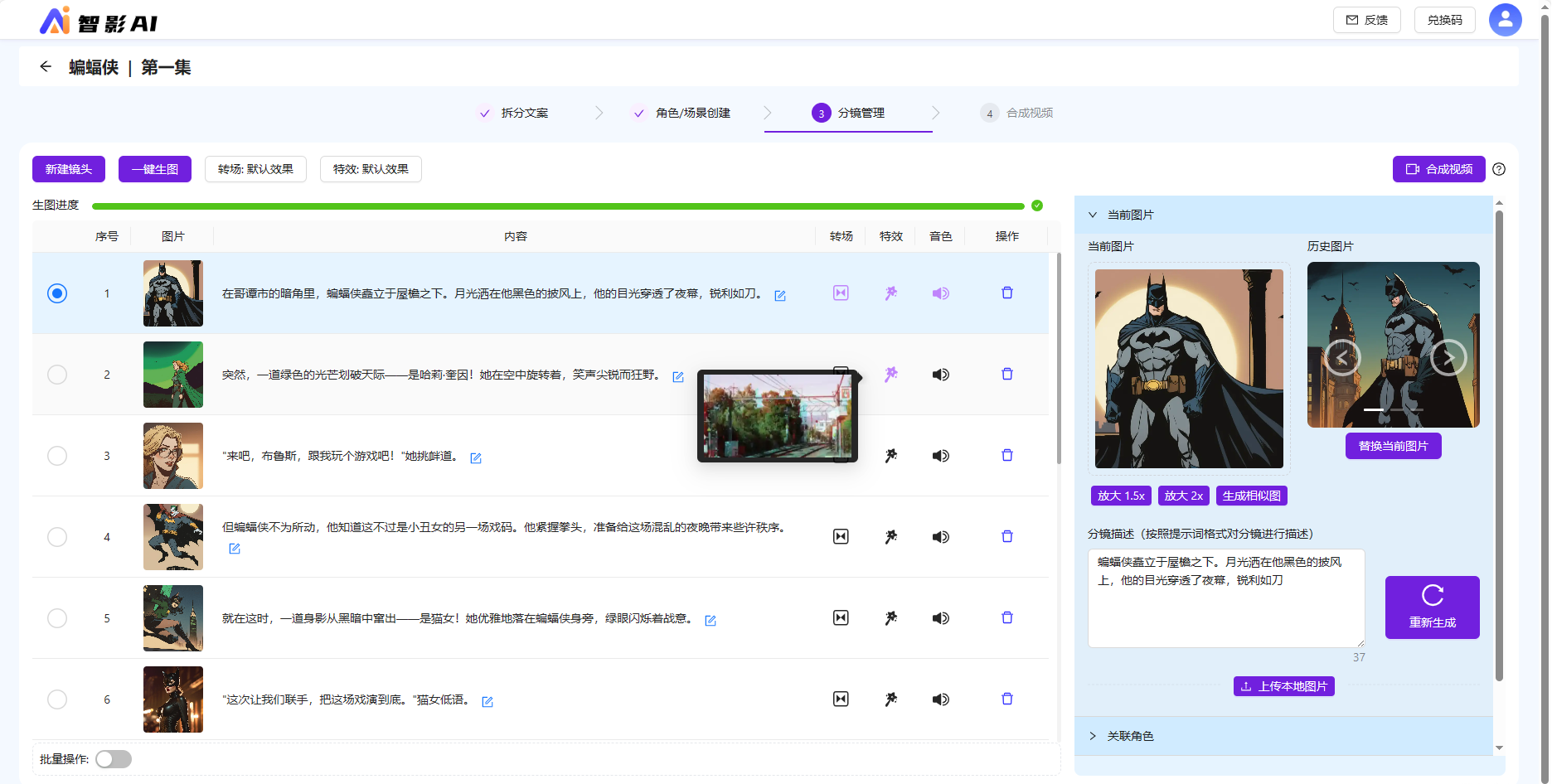
支持对分镜配置转场特效,也可以配置全局默认转场特效。单分镜支持配置多情感音色,间接实现了多角色多音色功能。
系统提供的背景音乐无法满足所有用户的真实需求,允许上传个性化的背景音乐。
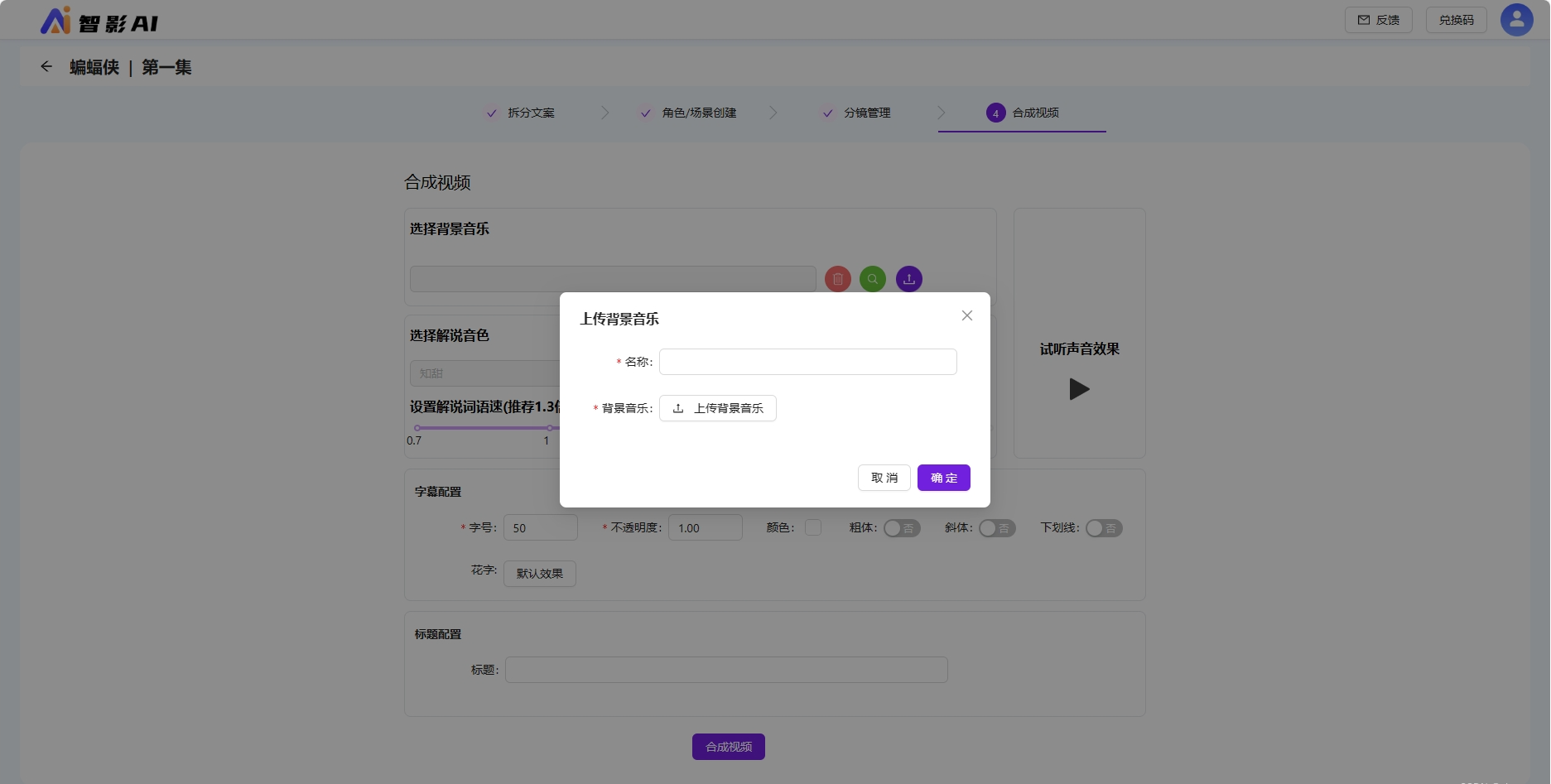
字幕标题支持花字、字号、粗体、斜体等配置。标题非必填。
启用动态视频,支持将分镜图片转换为视频内容。
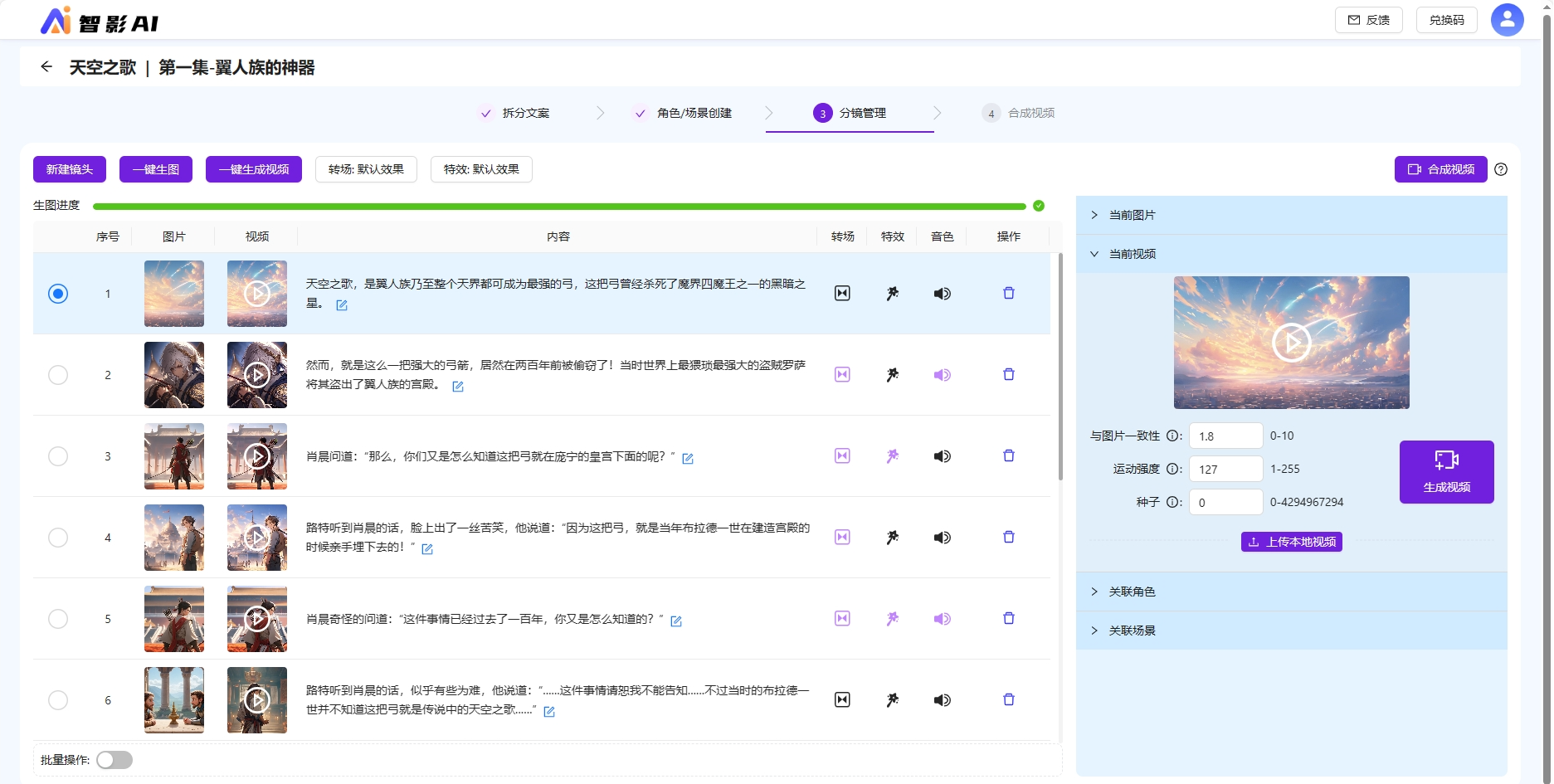
对于开启动态视频能力的作品,在分镜图片调整完成后,点击一键生成视频,可以对分镜图片生成4s的视频。
允许调试图生视频参数,与图片的一致性、运动强度、种子等参数,重新生成视频。
开启动态视频能力的作品,在合成视频时,将采用分镜视频素材代替分镜图片素材来合成视频,合成推文视频效果更佳。传统的图片就是PPT播放效果,动态视频就是真正意义上的视频了。
扩展:Sora、PiKa、Runway、SVD等AI视频能力,也是未来AI电影、AI广告、AI新闻等产业的发展方向。
Sora官网:openai.com/sora
PiKa官网:pika.art
Runway官网:runwayml.com
Stable Video官网:stablevideo.com
Fooocus官网:fooocus.cc
MidJounery官网:midjourney.com