通过icost软件可以定位raealm数据库
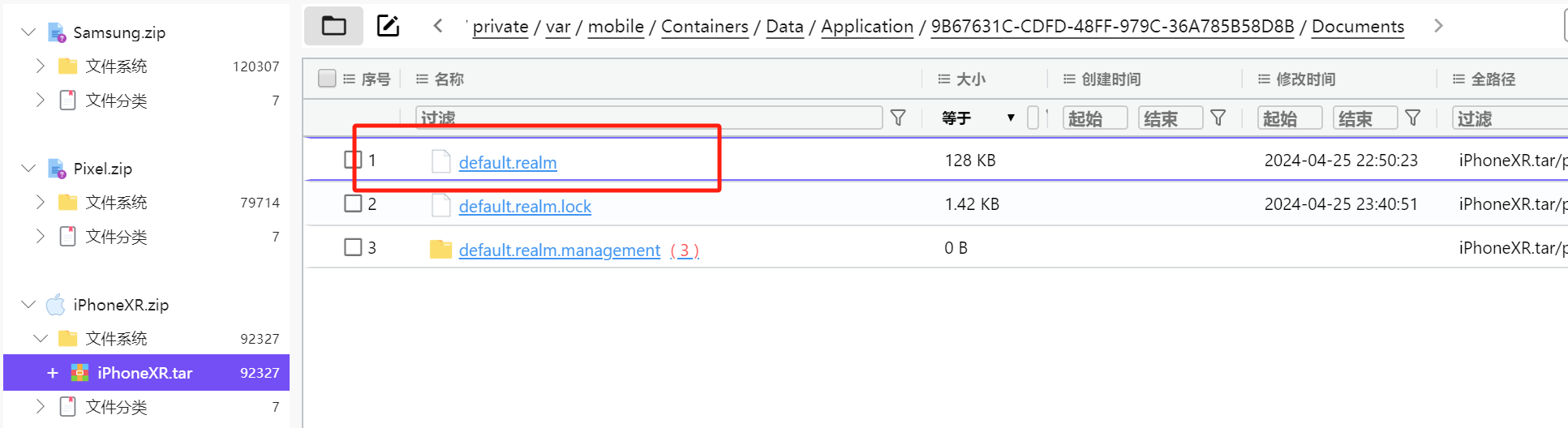
default.realm
下载realm studio打开数据库
https://github.com/realm/realm-studio?tab=readme-ov-file
使用Realm Studio查看,过滤器:type=1 and timestamp >= 1706716800000 and timestamp <= 1709222400000(含义:类型为收入+2~3月)
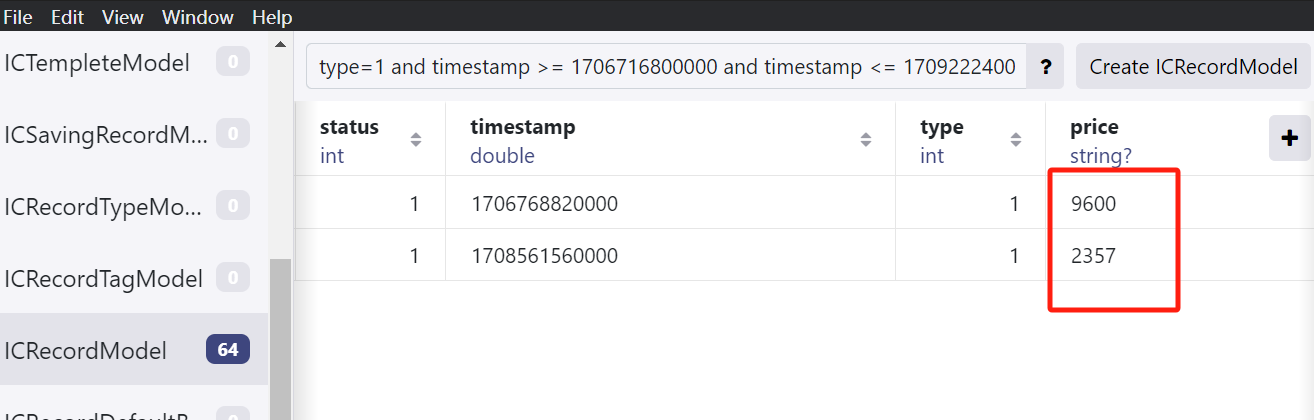
11957
服务器顺下来就知道,也不用看数据库
gxyt@163.com
知道通讯软件是mattermost,之前有导出过数据库
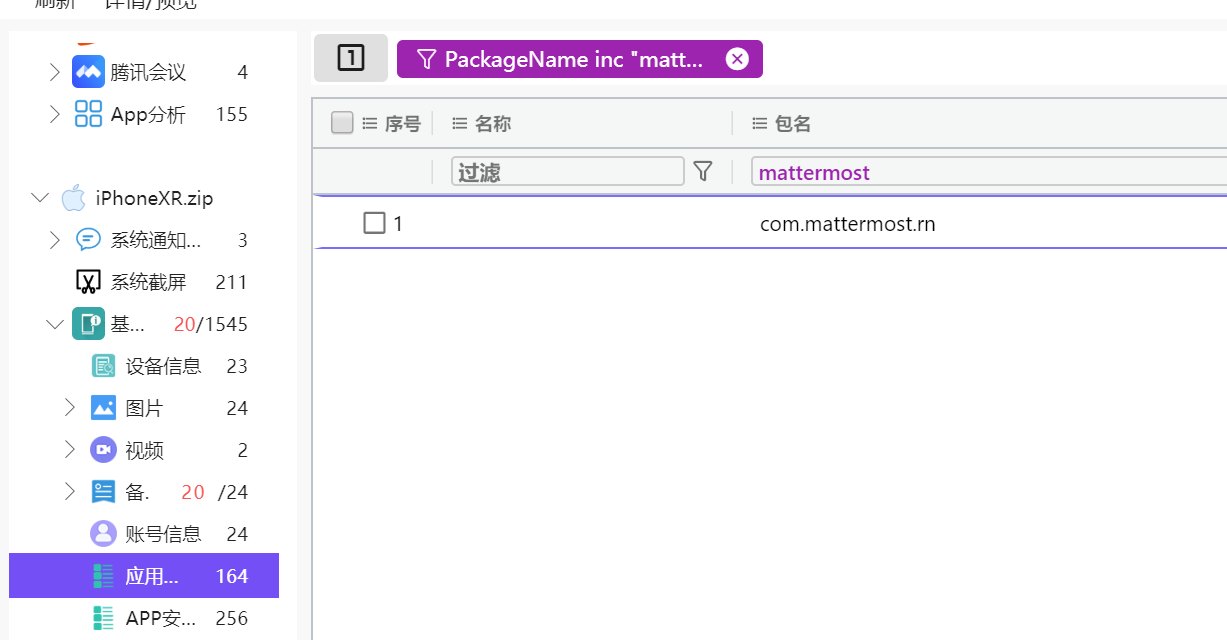
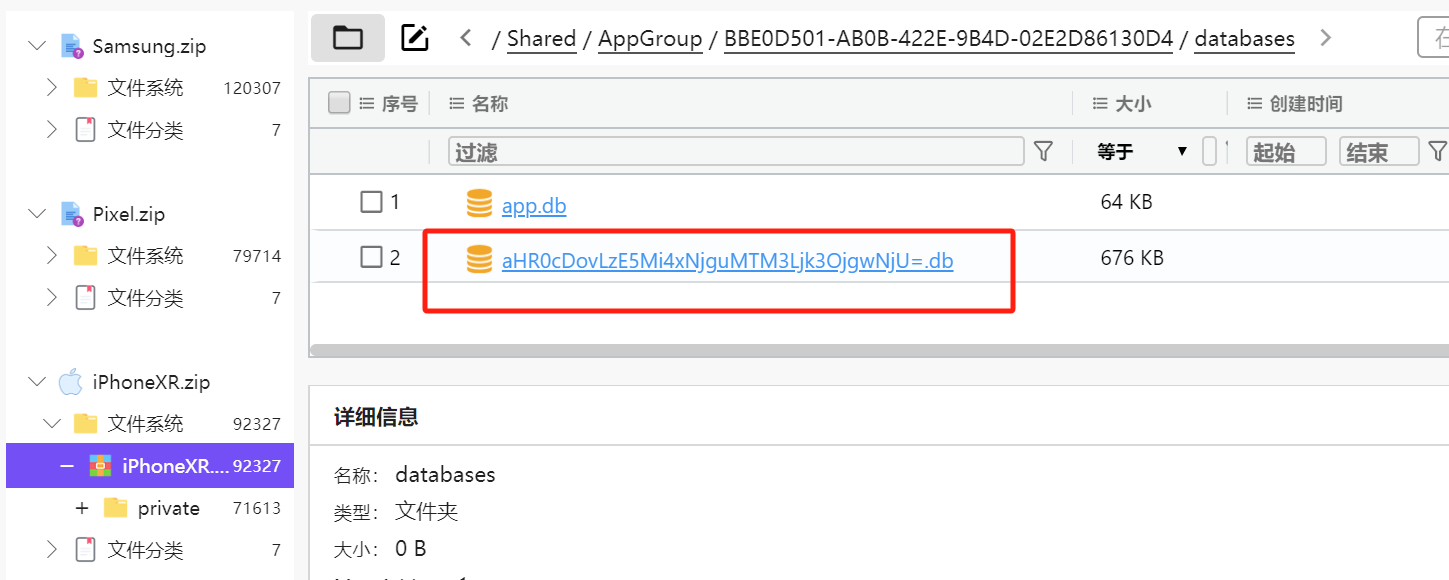

ctool转换
https://ctool.dev/tool.html#/tool/time/timestamp
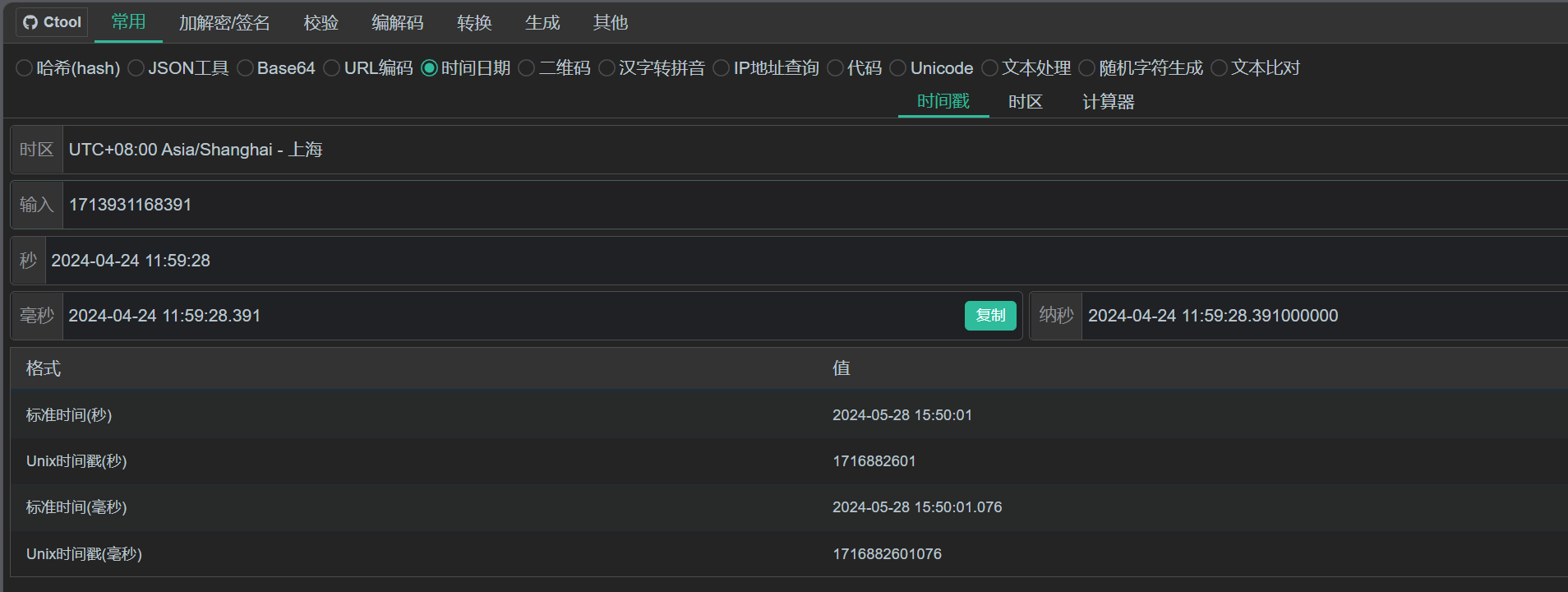
2024-04-24-11-59-28

2024-04-25-10-24-50
火眼分析yiyan计算机发现有4个GPT声音模型
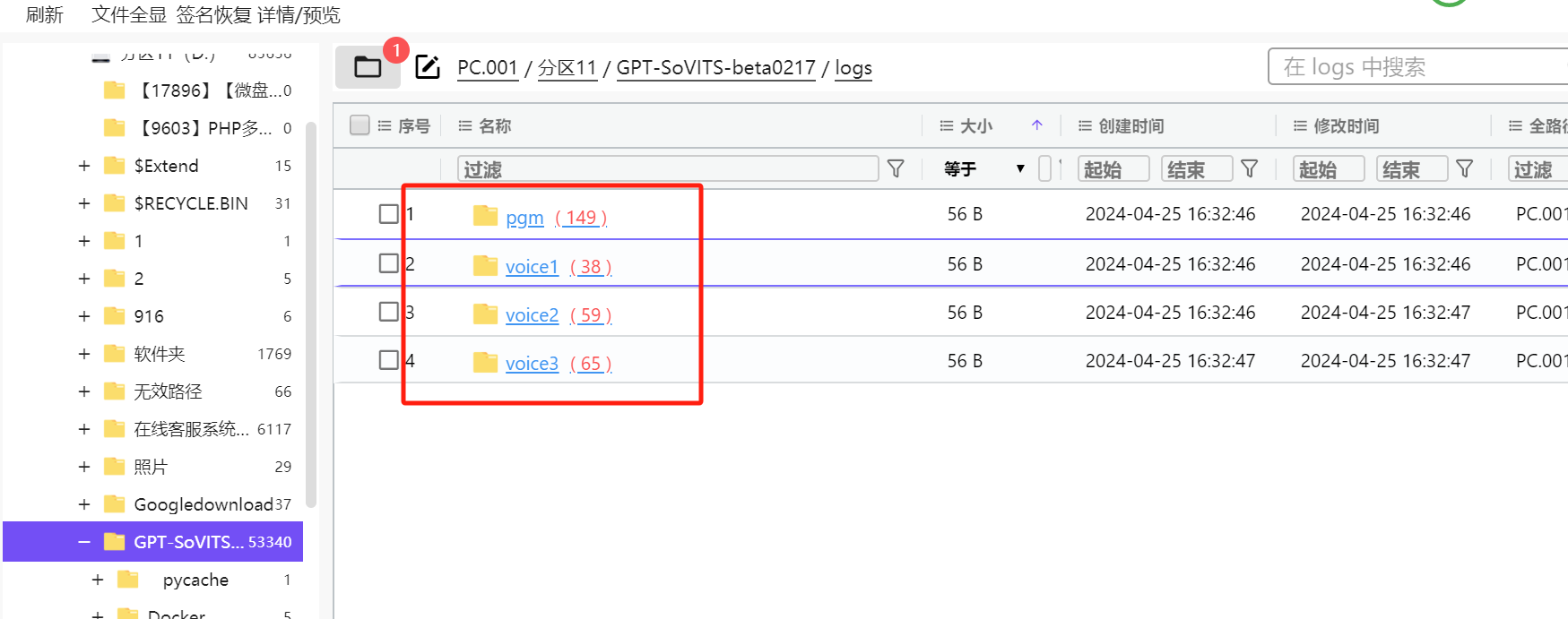
每一个模型都有一个train.log
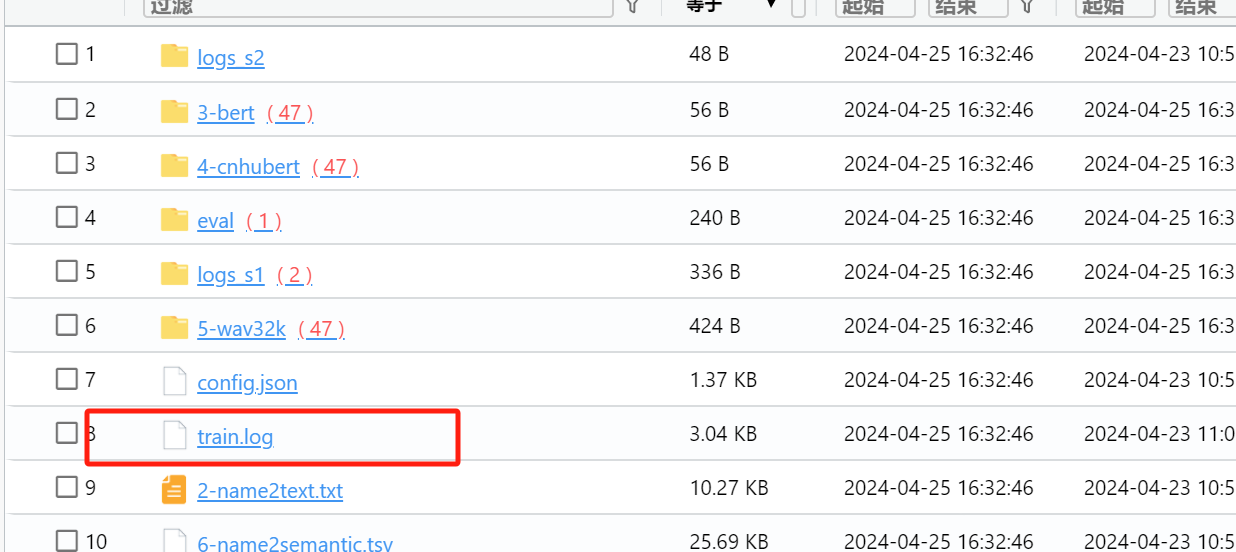
进入虚拟机也可以看到对应文件
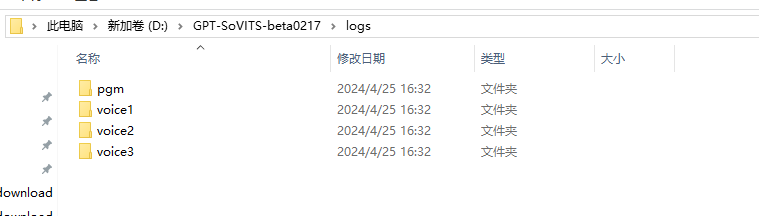
4
文件路径:PC.001/分区11/GPT-SoVITS-beta0217/logs/voice2/3-bert
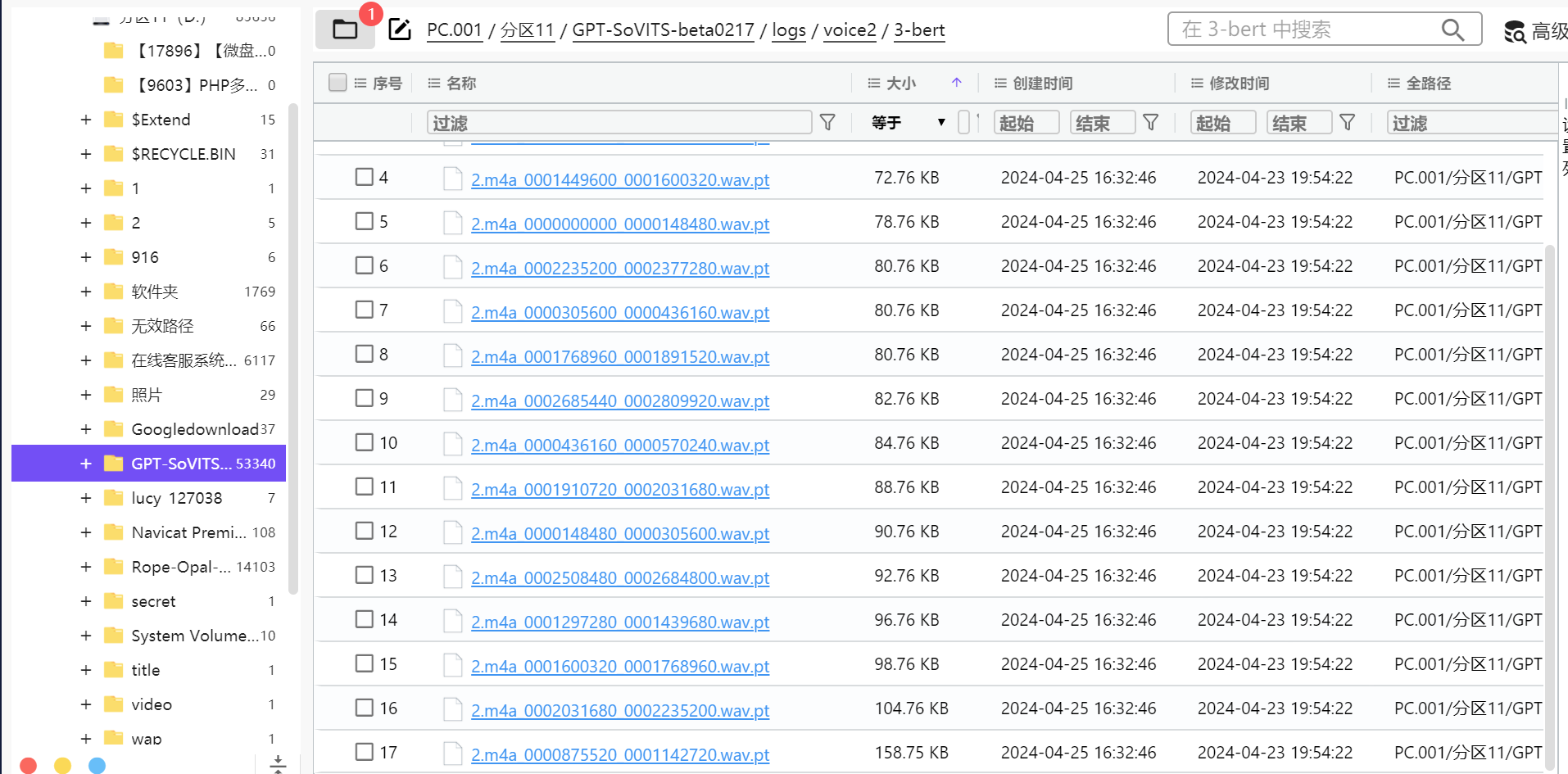
17
查看train.log
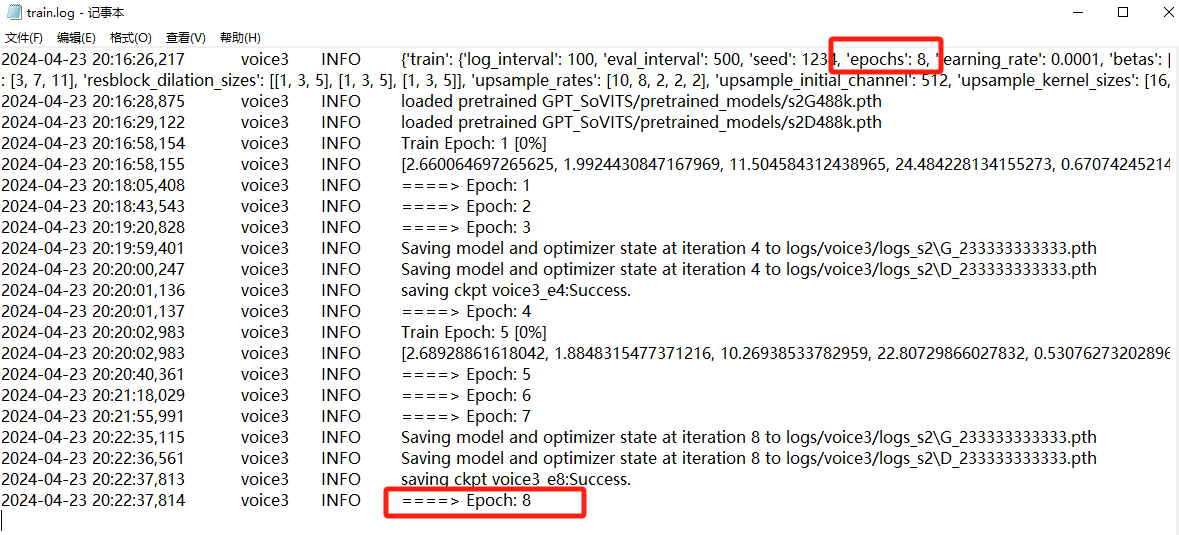
8
查找GPT-SoVITS-beta0217的配置文件

9874
非常有意思,这题又遇到逆向了(上次是bitlocker)
1.在输出文件里只能看到一个视频被换过脸
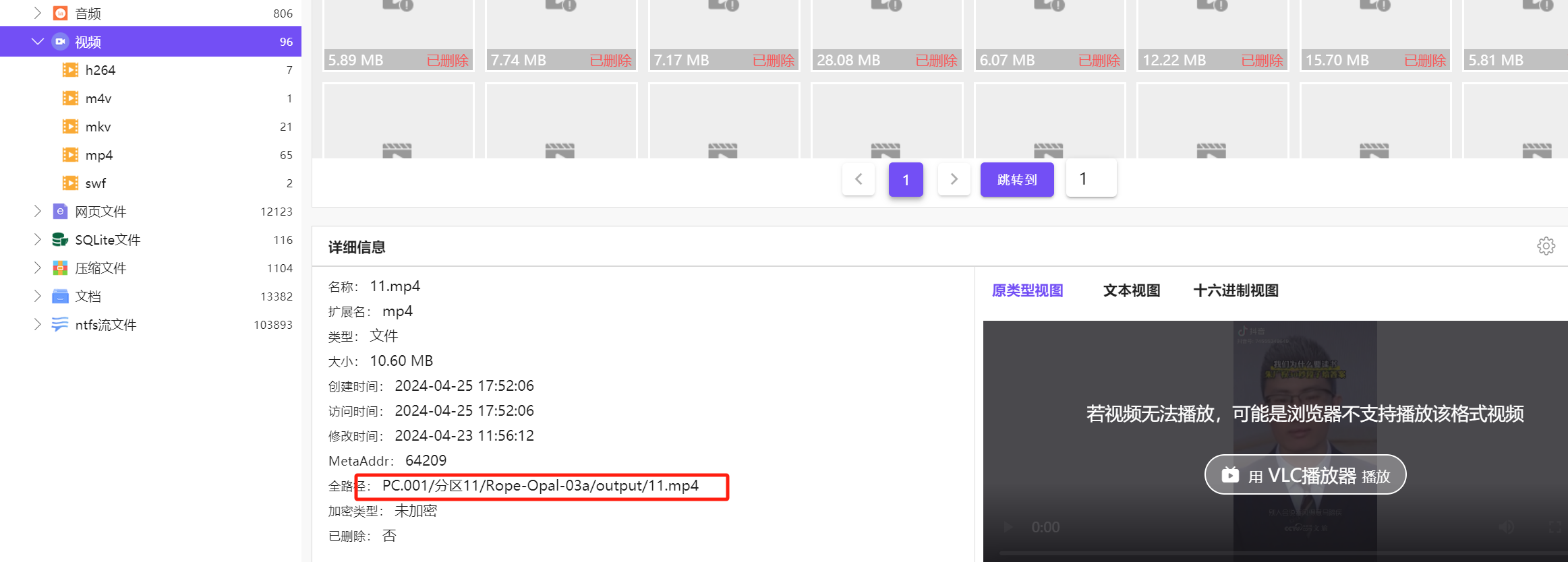
2.另外的视频通过wncrypt.exe加密过,要对该软件进行反编译和反混淆,了解具体加密算法后,自行编写脚本对加密文件解密
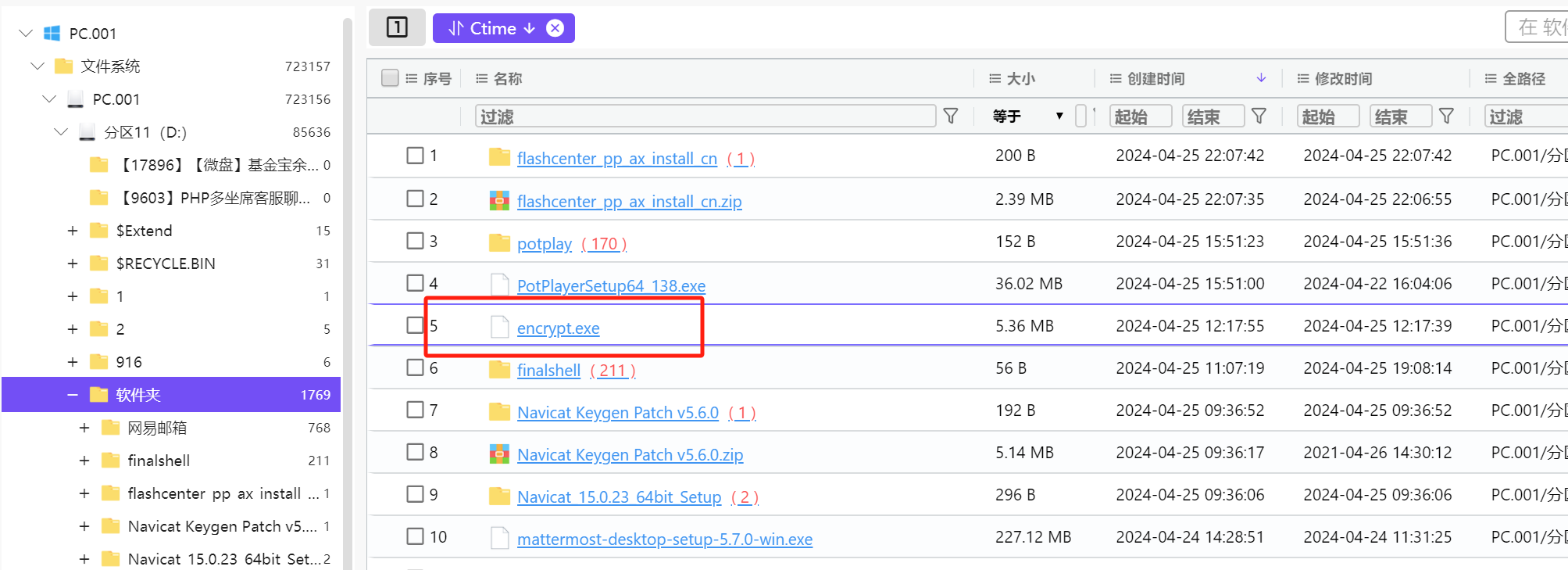
导出文件,用pyinstxtractor进行反编译,获得encrypt.exe_extracted文件夹
对应加密方式在z.pyc文件里,要转化为py文件。但是文件改名为z.pyc后有点问题,不能直接转换,要用WinHex修改文件头后,再放入在线网站(https://www.lddgo.net/string/pyc-compile-decompile) 或者工具(uncompyle6/pycdc)反编译
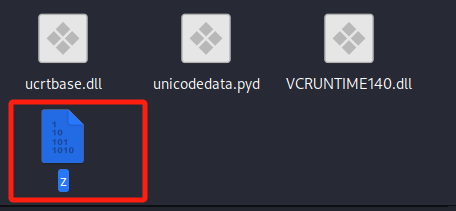
可以看到文件头有缺失,进行python版本补全
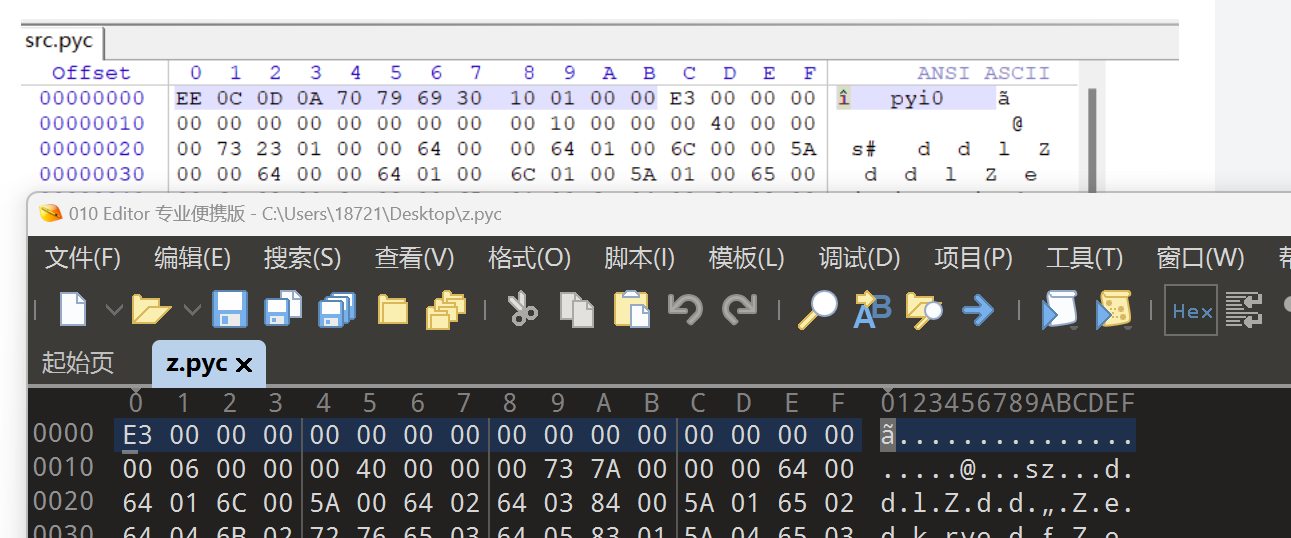
MAGIC_NUMBER = (3413).to_bytes(2, 'little') + b'\r\n'
_RAW_MAGIC_NUMBER = int.from_bytes(MAGIC_NUMBER, 'little') # For import.c
复制
# -*- coding: utf8 -*-
#! /usr/bin/env 3.8.0 (3413)
#coding=utf-8
#source path: z.py
#Compiled at: 1970-01-01 00:00:00
#Powered by BugScaner
#http://tools.bugscaner.com/
#如果觉得不错,请分享给你朋友使用吧!
import os
def xor_process(O0OOO0O0000O000O0, O0OOOOO0OOOO00000):
try:
with open(O0OOO0O0000O000O0, 'rb') as (O0000O0O0000O000O):
O0O0OOO0OOO00OOOO = O0000O0O0000O000O.read()
O00000O00OOOO0O00 = os.path.splitext(os.path.basename(O0OOO0O0000O000O0))[0]
O0000O0OOO00OO000 = bytearray()
for OOO0O0000OOOO0O0O in range(len(O0O0OOO0OOO00OOOO)):
O0000O0OOO00OO000.append(O0O0OOO0OOO00OOOO[OOO0O0000OOOO0O0O] ^ ord(O00000O00OOOO0O00[OOO0O0000OOOO0O0O % len(O00000O00OOOO0O00)]))
else:
O00000O00OO0OOO0O = os.path.join(O0OOOOO0OOOO00000, f"{O00000O00OOOO0O00}-cn{os.path.splitext(O0OOO0O0000O000O0)[1]}")
with open(O00000O00OO0OOO0O, 'wb') as (OO00000O000O00OO0):
OO00000O000O00OO0.write(O0000O0OOO00OO000)
print(f"文件 {O0OOO0O0000O000O0} 处理成功!")
except Exception as OOO0000OOO0O0O0O0:
try:
print(f"处理文件 {O0OOO0O0000O000O0} 出错:{OOO0000OOO0O0O0O0}")
finally:
OOO0000OOO0O0O0O0 = None
del OOO0000OOO0O0O0O0
if __name__ == '__main__':
folder_path = input('请输入要处理的文件夹路径:')
output_folder = input('请输入要保存处理结果的文件夹路径:')
if not os.path.exists(output_folder):
os.makedirs(output_folder)
for root, _, files in os.walk(folder_path):
for file in files:
file_path = os.path.join(root, file)
xor_process(file_path, output_folder)
复制
def xor_process(file_path, output_folder):
try:
with open(file_path, 'rb') as (fr):
file_data = fr.read()
file_name = os.path.splitext(os.path.basename(file_path))[0]
#file_name = file_name.replace('-cn','')
xor_data = bytearray()
for i in range(len(file_data)):
xor_data.append(file_data[i] ^ ord(file_name[i % len(file_name)]))
else:
output_file = os.path.join(output_folder, f"{file_name}-cn{os.path.splitext(file_path)[1]}")
with open(output_file, 'wb') as (fw):
fw.write(xor_data)
print(f"文件 {file_path} 处理成功!")
except Exception as e:
try:
print(f"处理文件 {file_path} 出错:{e}")
finally:
e = None
del e
复制import os
def xor_decrypt(file_path, output_folder):
try:
# 读取加密文件内容
with open(file_path, 'rb') as file:
encrypted_data = file.read()
# 从文件名中移除 '-cn' 并作为解密密钥
filename = os.path.splitext(os.path.basename(file_path))[0].replace('-cn', '')
# 初始化解密数据缓存
decrypted_data = bytearray()
# 对数据进行逐字节解密
for index in range(len(encrypted_data)):
decrypted_data.append(encrypted_data[index] ^ ord(filename[index % len(filename)]))
# 构建解密后文件的输出路径
output_file_path = os.path.join(output_folder, f"{filename}{os.path.splitext(file_path)[1]}")
# 写入解密数据到新文件
with open(output_file_path, 'wb') as output_file:
output_file.write(decrypted_data)
print(f"文件 {file_path} 解密成功!")
except Exception as e:
print(f"处理文件 {file_path} 出错:{e}")
if __name__ == '__main__':
# 获取用户输入
folder_path = input('请输入要解密的文件夹路径:')
output_folder = input('请输入要保存解密结果的文件夹路径:')
# 确保输出文件夹存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 遍历文件夹并解密文件
for root, _, files in os.walk(folder_path):
for file in files:
file_path = os.path.join(root, file)
xor_decrypt(file_path, output_folder)
复制参考文章
https://blog.csdn.net/m0_73393932/article/details/130161331
https://blog.csdn.net/Zheng__Huang/article/details/112380221
https://blog.csdn.net/qq_63585949/article/details/126706526
pyinstxtractor下载
https://sourceforge.net/projects/pyinstallerextractor/
最后发现一共 1 + 41 个换脸后的视频.
42
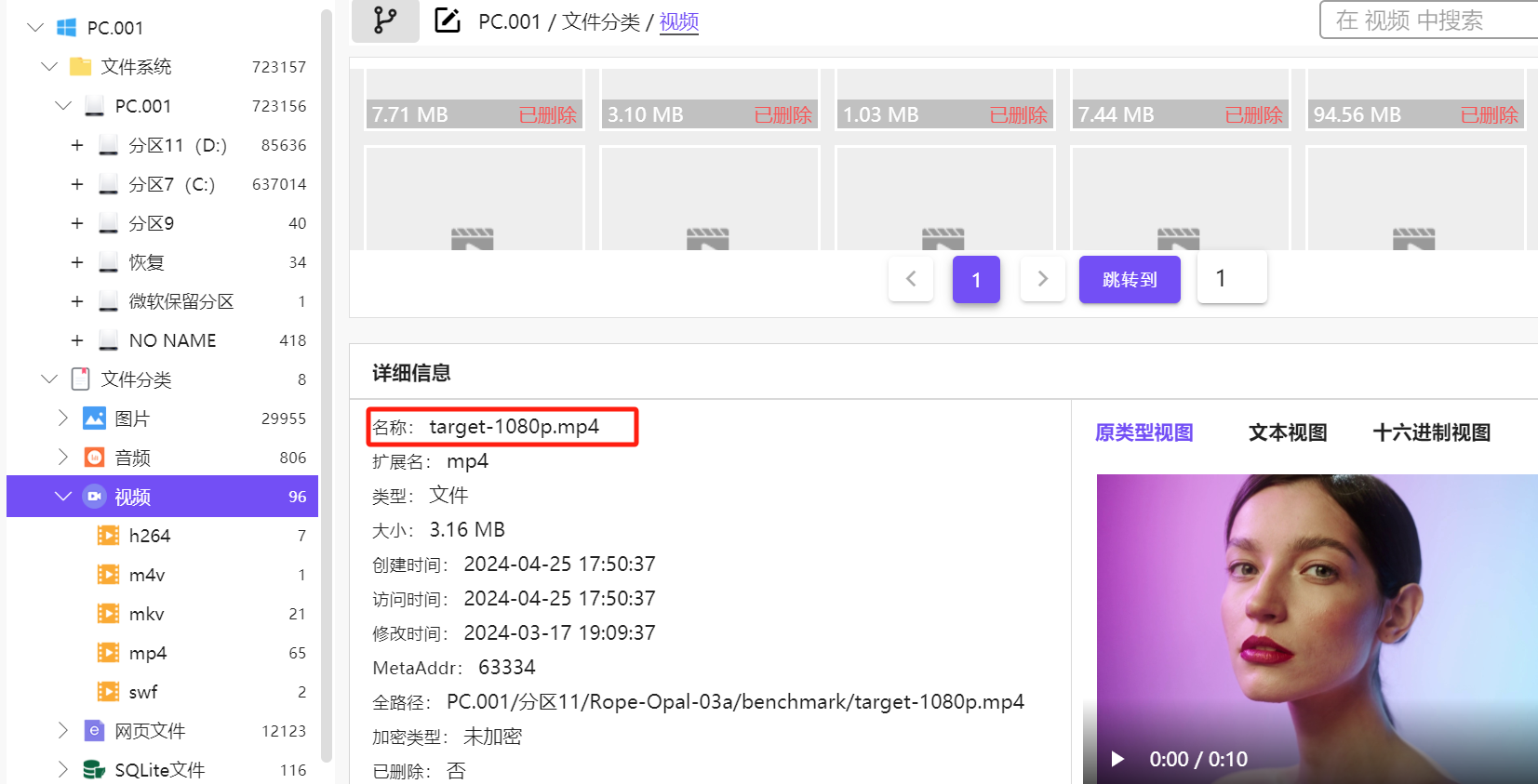
target-1080p.mp4
根据视频路径去虚拟机里找
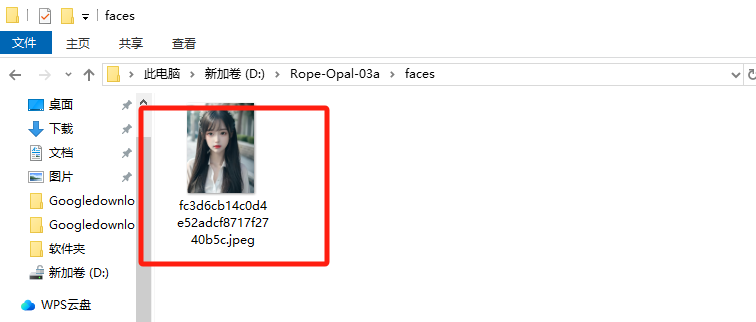
fc3d6cb14c0d4e52adcf8717f2740b5c.jpeg
同样在上述路径下
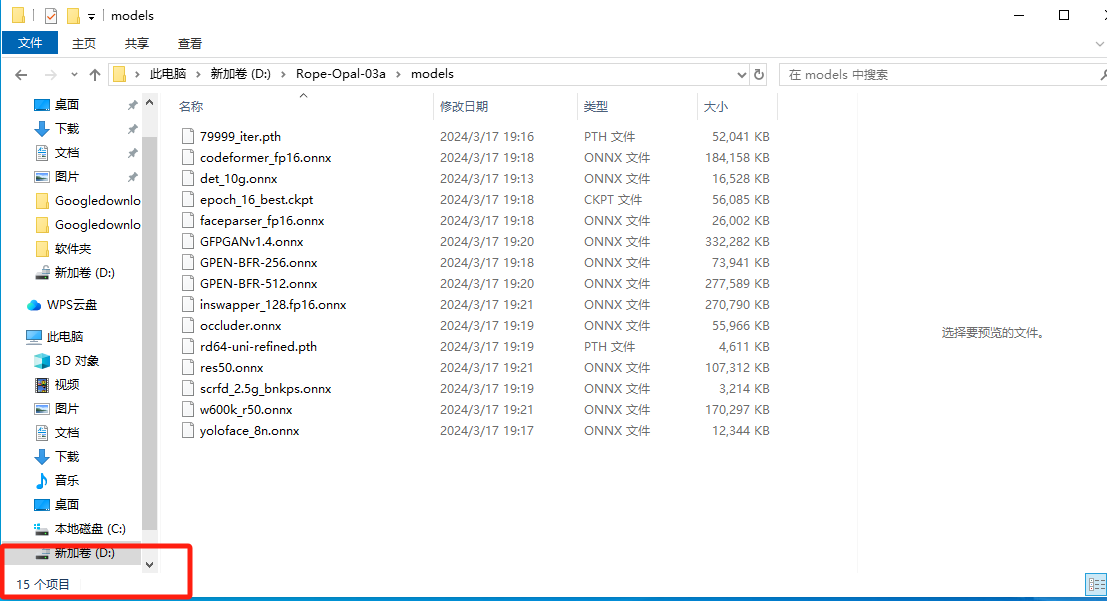
15
人工智能部分
分为声音模型和AI换脸,在火眼中如果找到对应路径,在虚拟机中可以较容易找到答案,主要考察信息检索能力。难点在于第五题的逆向分析,要考虑如何还原换脸视频。这题感觉和ctf比赛的逆向题目流程一模一样——反编译,反混淆,修改文件头进行修复……
IPA部分
IPA这些题目和手机取证差不多,都是在数据库里找信息。第三题可以通过其他题目找到的信息回答。主要学习了realm数据库的查找,以及realm studio的安装和使用。
又是收获满满的一天!