这一章我们介绍能自主浏览操作网页的WebAgent们和相关的评估数据集,包含初级任务MiniWoB++,高级任务MIND2WEB,可交互任务WEBARENA,多模态WebVoyager,多轮对话WebLINX,和复杂任务AutoWebGLM。
- Reinforcement Learning on Web Interfaces using Workflow-Guided Exploration
- https://miniwob.farama.org/
这两年webagent的论文里几乎都能看到这个评测集的影子,但这篇论文其实是2018年就发表了。所以这里我们只介绍下数据集的信息~
MiniWoB++是基于gymnasium的模拟web环境,它在OpenAI的MiniWoB数据集上补充了更多复杂交互,可变页面等网页交互行为,最终得到的100个网页交互的评测集。一些组件的Demo示例如下
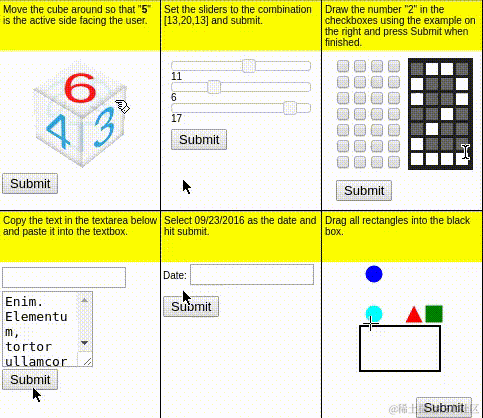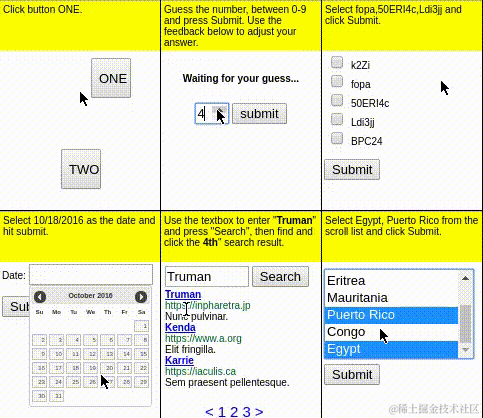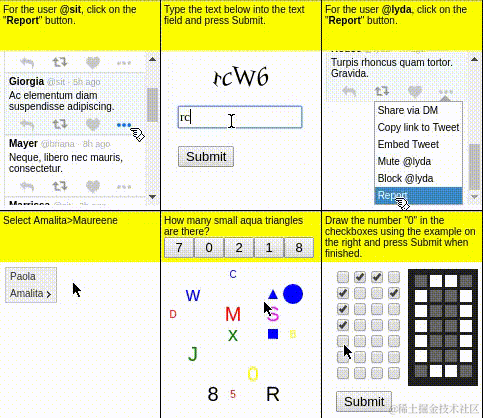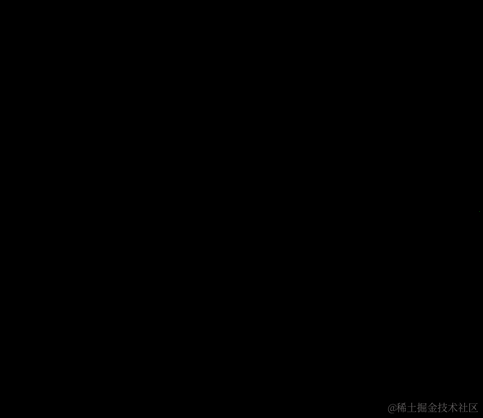
MiniWoB++数据集的局限性
- MIND2WEB: Towards a Generalist Agent for the Web
- https://osu-nlp-group.github.io/Mind2Web/
MIND2WEB数据集在MiniWoB++数据集上做了以下几点改良
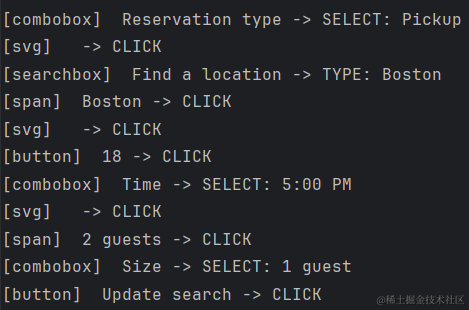
让我们来具体看一个样本,任务指令=Check for pickup restaurant available in Boston, NY on March 18, 5pm with just one guest,Label是完成该指令的行为序列,每一步行为由(Target Element, Operation)构成,这里支持三种最常用的OPCLICK, TYPE,SELECT,行为序列如下
MIND2WEB采用了4个评估指标
Mind2WEB数据集主要局限性是只有数据采集时的网页静态页面HTML,没有后续行为的动态交互数据
MINDAct框架因为是单一文本模态,因此使用HTML代码和DOM文件来作为网页的观测数据,框架比较简单由两个部分组成:元素排序生成候选,基于候选的多项选择生成行为
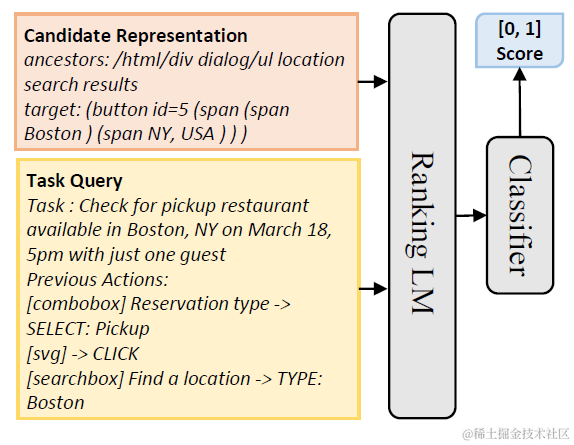
这里论文是通过随机负样本采样,训练了DeBERTa模型作为排序模型,测试集Top50召回在85%+。
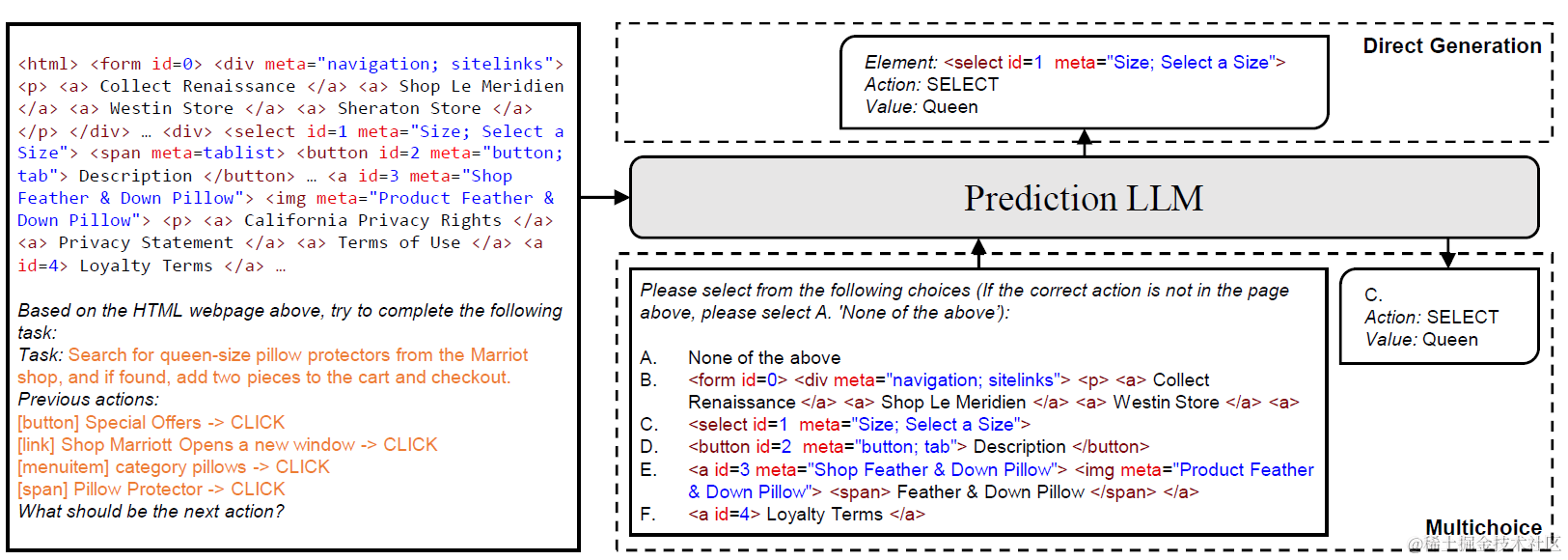
之后会基于Top-K 候选,裁剪HTML,和历史的Action,选择下一步的的Action和Value。于是基于复杂HTML直接生成Action和Value的复杂任务,被简化成了多项选择的QA任务。这里论文是微调了Flan-T5来完成多项选择任务,也同时对比了直接使用GPT3.5和GPT4。
- WEBARENA: A REALISTIC WEB ENVIRONMENT FOR BUILDING AUTONOMOUS AGENS
- https://webarena.dev/
针对Mind2WEB只和静态网站状态交互的问题,WEBARENA通过构建仿真网站,构建了真实,动态,并且可复现的网络环境来和智能体进行交互。论文选择了电商,论坛,github,CMS等四类网站类型,并使用网站真实数据来构建模拟环境。
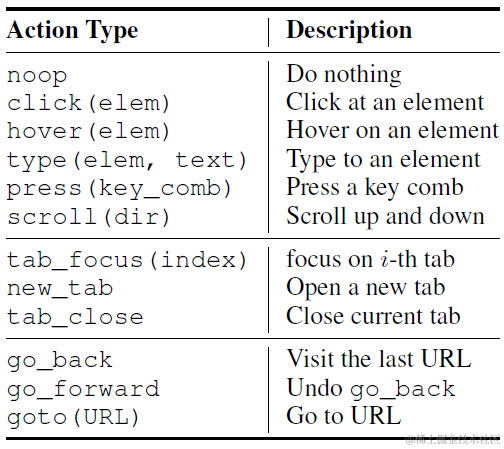
并且对比Mind2WEB的3种常见交互,支持更多的交互操作,并且因为是动态页面因此支持多tab切换的操作,支持的opeeration类型如下
数据集构成

评估指标上相比Mind2WEB,WEBARENA同样使用task success rate作为评估指标,把token-level的F1计算进行了优化,加入了operation是否正确的检测方案。核心就是部分操作需要键入内容,而这部分内容不能直接和标注做精准匹配,因此WEBARENA分成了需要精准匹配的答案(exact match),只要包括核心信息即可(must include)和基于大模型做语义相似判断的(fuzzy match)这三类评估类型,对不同的样本进行评估。
- WebVoyager: Building an End-to-end Web Agent with Large Multimodal Models
- https://github.com/MinorJerry/WebVoyager?tab=readme-ov-file
同样是动态网页交互,WebVoyager没有采用模拟网页数据,而是使用Selenium直接操控web浏览器行为和真实网页进行交互。于是同时满足了动态交互和真实网络环境的要求。
论文选取了15个有代表性的网站:Allrecipes, Amazon, Apple,ArXiv, BBC News, Booking, Cambridge Dictionary,Coursera, ESPN, GitHub, Google Flights,Google Map, Google Search, Huggingface, and Wolfram Alpha。
指令样本是基于Mind2Web的数据集作为种子,然后基于GPT4使用Self-Instruct来生成新的任务指令,最后使用人工校验和筛选。最终得到了每个网站40+的指令,总共643个评估任务。
评估指标和webARENA保持一致,都是采用任务成功率作为评估指标。
这里简单说下agent实现,WebVoyager和前面数据集的主要差异是加入了多模态模型GPT4—V的尝试。不再使用accessibility Tree的文本输入,而是直接和网页的snapshot进行交互。
这里论文采用了set-of-Mark Prompting的技术,来解决GPT4-V模型visual grounding的问题(模型对图片中细粒度物体的区分度有限,当输出是图片中局部物体例如按钮时准确率不高的问题)。SOM是先用SAM等分割模型对图片进行分割,这里主要是识别出图片上可交互的按钮和区域,使用bounding box进行圈选,并使用序号对区域进行标记。通过标记来帮助GPT4-V更精准的识别可交互区域。
这里论文使用了GPT-4V-ACT,JS DOM auto-labeler来识别网页中的所有可交互元素并进行标记,来作为GPT4-V的输入,如下
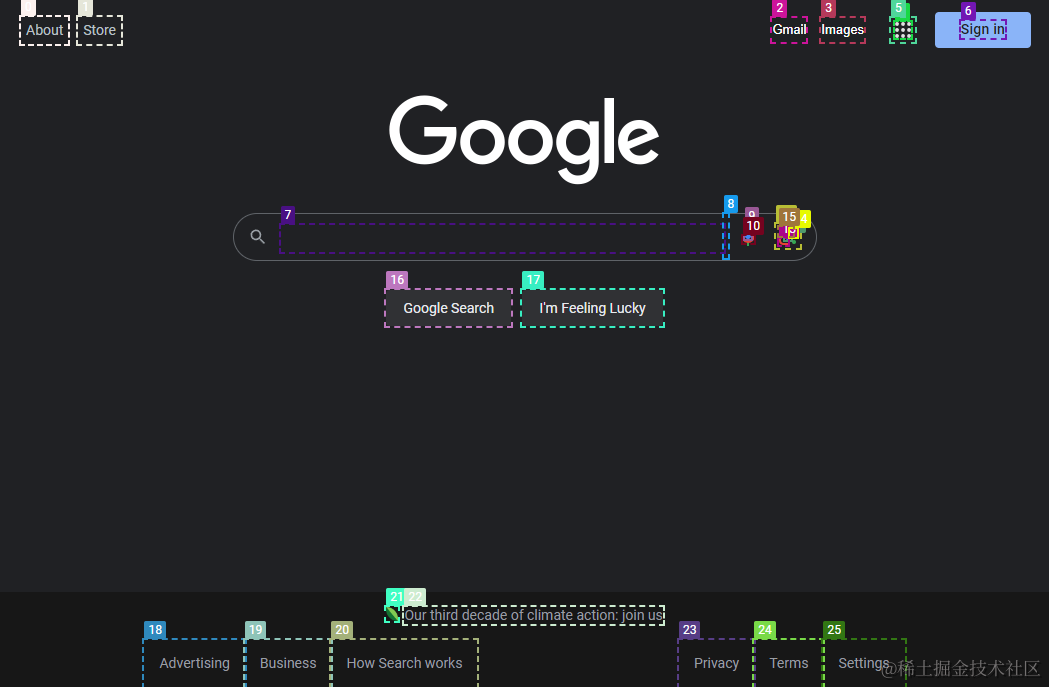
然后基于上面的标记图片输入,和以下ReACT的prompt指令,让GPT4V生成每一步的交互操作。基于模型推理结果会直接操作网页,并获取新的网页snapshot作为下一步的输入。

- WebLINX: Real-World Website Navigation with Multi-Turn Dialogue
- https://github.com/McGill-NLP/WebLINX
对比前面的MIND2WEB,WebArena和webVoyager,webLLINX加入了和用户的多轮对话交互,也就是从自主智能体向可交互智能体的转变。虽然放弃了自主,但有了人类的监督,可能可以达到更高的任务完成度。
WebLINX的数据集,包括8大类,50个小类总共155个真实网页,总共构建了2337个指令样本。 因为是对话式交互,所以指令类型会和以上的几个数据集存在明显的差异,不再是任务型指令而是步骤操作型的指令,如下图
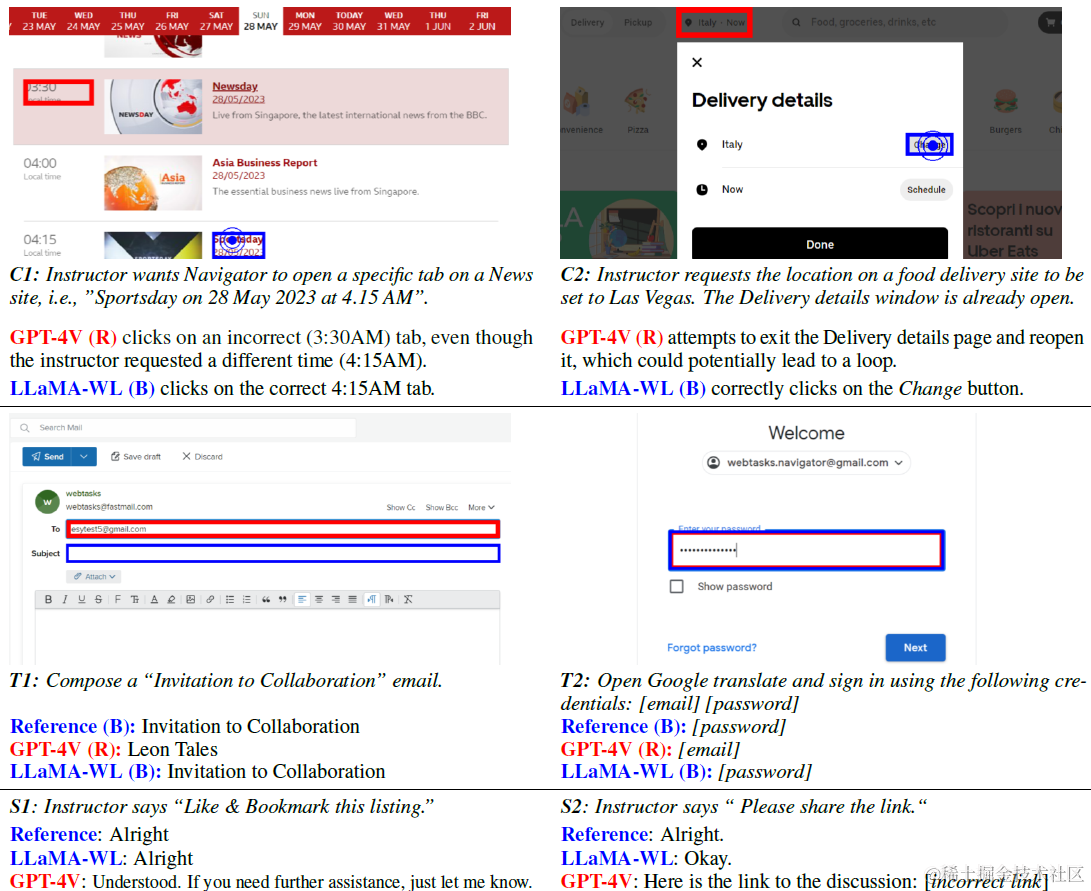

agent部分论文更多是对比了文本模态vs多模态,微调vsprompt的效果,实现细节不太多这里就不细说了
- AutoWebGLM: Bootstrap And Reinforce A Large Language Model-basedWeb Navigating Agent
- https://github.com/THUDM/AutoWebGLM
AutoWebGLM是智谱最近才发布的webagent论文,包括比较全面的微调数据集构建和微调方案,并发布了新的评测集。论文提出AutowebGLM的数据集有三个主要优点
AutoWebGLM的微调数据集包含由易到难的三种任务:web recognition,single-step task,multi-step task。这里也是纯HTML文本模态的数据集。除了以下全新的三类样本,论文还合并了MiniWoB++和Mind2Web的训练集。
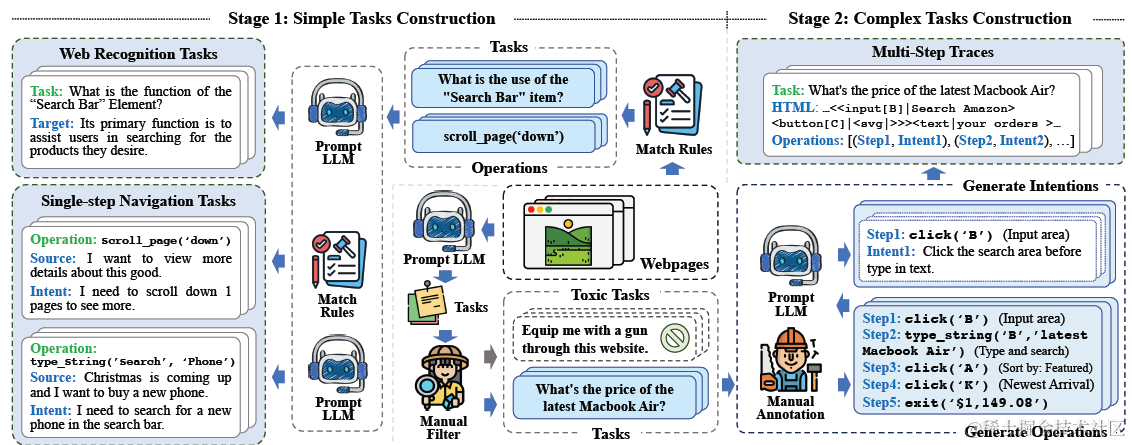
网页识别样本构建,是直接从HTML中提取可交互元素,然后基于元素构建简化的HTML输入。然后Input是网页元素功能的相关提问,输出是GPT的回答,例如"Search Bar是用来干什么的",模型回答“它是用来帮助用户搜索产品的”。这部分样本用来帮助模型理解HTML。
简单任务是单步操作的网页交互。这里论文的构建比较巧妙,考虑到之前的论文已经论证了即便是GPT4在webagent这个任务上的执行准确率也有限,那直接使用GPT4来构建样本肯定是不可行的。因此论文采用了反向标注,既基于HTML中抽取出的可交互元素例如“scroll_page('down')”,让GPT4来方向生成对应的意图和用户指令,例如我需要向下滑网页浏览更多。 这样可以得到准确率更高的样本,模型生成意图和指令的prompt如下

复杂任务涉及和网页的多步交互。这里论文使用了Evol-Instruct来构建复杂任务指令(不熟悉的同学看这里解密Prompt系列17.LLM对齐方案再升级), 每个网页模型生成50个指令,再人工筛选20个。
考虑模型生成准确率不高,这里得多步交互,论文使用人工执行,并用浏览器插件捕捉用户交互行为的方案。这里为了在行为链路之外,同时获得模型COT思考链路,用来提高后面的模型训练效果。论文使用以下prompt,让大模型基于人工完整的行为链路,生成每一步的执行意图。
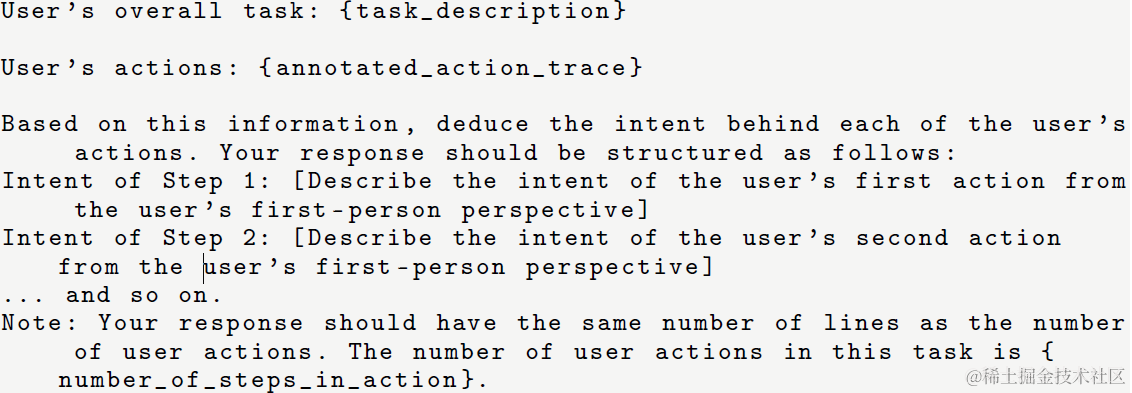
最终的AutoWebBench评测集只使用了多步任务的子集,也就是复杂指令来评测模型效果。
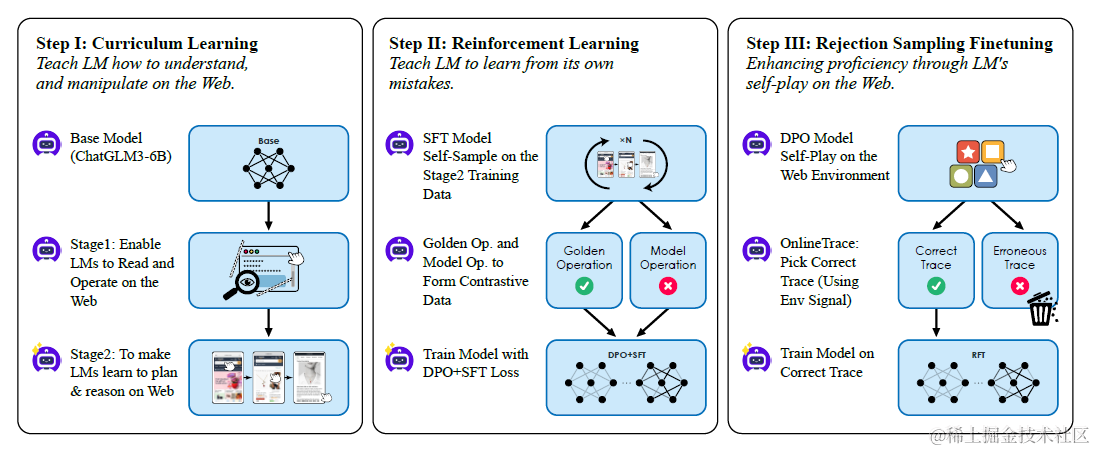
基于以上的训练数据,论文采用了多阶段训练微调ChatGLM3
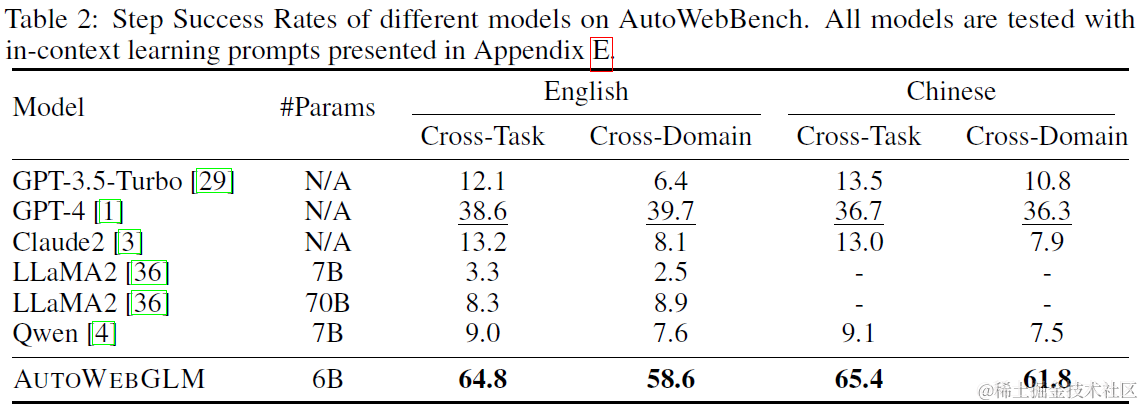
效果上在AutoWebBench上,微调后的6B模型可以显著超过GPT4,和更大的LLAMA2基座模型,拥有更高的任务单步执行成功率。
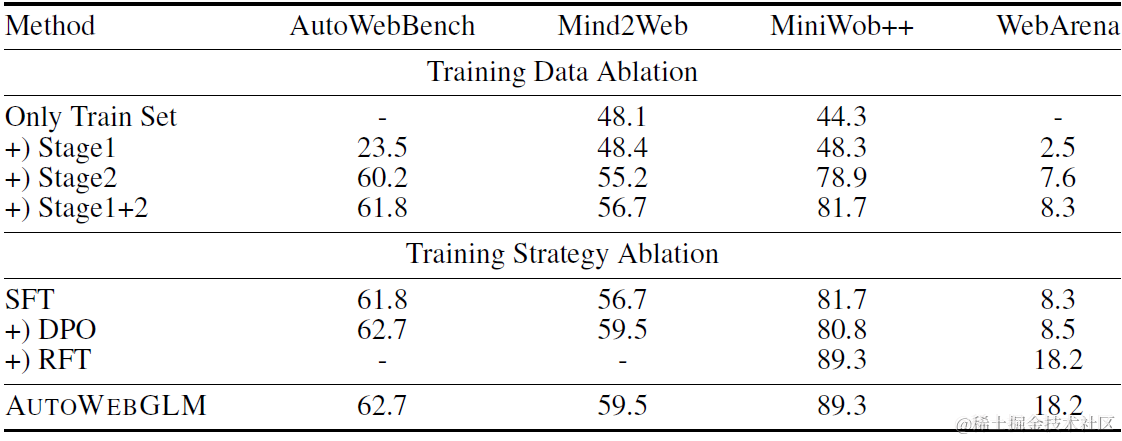
同时论文做了消融实验来验证以上多阶段微调和三种训练样本的效果。实验显示,由易到难的训练数据对模型有较大提升,RFT在进一步训练的miniWob++和WebArena上有显著提升,但RL-DPO的效果不太明显。
想看更全的大模型相关论文梳理·微调及预训练数据和框架·AIGC应用,移步Github >> DecryPrompt
这一章介绍自主浏览操作网页的WebAgent和数据集:初级MiniWoB++,高级MIND2WEB,可交互WEBARENA,多模态WebVoyager,多轮对话WebLINX,复杂AutoWebGLM
前几章我们讨论了RLHF的样本构建优化和训练策略优化,这一章我们讨论两种不同的RL训练方案,分别是基于过程训练,和使用弱Teacher来监督强Student 循序渐进:PRM & ORM 想要获得过程
这一章我们聚焦多模态图表数据。先讨论下单纯使用prompt的情况下,图片和文字模态哪种表格模型理解的效果更好更好,再说下和表格相关的图表理解任务的微调方案
这一章我们聊聊大模型表格理解任务,在大模型时代主要出现在包含表格的RAG任务,以及表格操作数据抽取文本对比等任务中。这一章先聊单一的文本模态,我们分别介绍微调和基于Prompt的两种方案。
模型想要完成自主能力进化和自主能力获得,需要通过Self-Reflection from Past Experience来实现。那如何获得经历,把经历转化成经验,并在推理中使用呢?本章介绍三种方案
这一章介绍通过扩写,改写,以及回译等半监督样本挖掘方案对种子样本进行扩充,提高种子指令样本的多样性和复杂度,这里我们分别介绍Microsoft,Meta和IBM提出的三个方案。
总结下指令微调、对齐样本筛选相关的方案包括LIMA,LTD等。论文都是以优化指令样本为核心,提出对齐阶段的数据质量优于数量,少量+多样+高质量的对齐数据,就能让你快速拥有效果杠杠的模型