MVCC 是 Multi-Version Concurrency Control 的缩写,即多版本并发控制。它是一种并发控制的方法,用于在数据库系统中实现事务的隔离性。MVCC 是一种乐观锁机制,它通过保存数据的多个版本来实现事务的隔禽性。在 etcd 中,MVCC 是用于实现数据的版本控制的。而且可以查看历史版本的数据。
# 添加数据
etcdctl put /test t1
OK
etcdctl put /test t2
OK
# 查看数据
etcdctl get /test
/test
t2
# 查看 json 格式数据
etcdctl get /test --write-out=json
# {"header":{"cluster_id":8735285696067307020,"member_id":7131777314758672153,"revision":15,"raft_term":4},"kvs":[{"key":"L3Rlc3Q=","create_revision":14,"mod_revision":15,"version":2,"value":"dDI="}],"count":1}
# 查看历史版本
etcdctl get /test --rev=14
/test
t1
可以看到,通过 --rev 参数可以查看历史版本的数据。也就是我第一次添加的数据。那么 json 中 revision 是什么意思呢?
reversion 中是 etcd 中的一个概念,它是一个递增的整数,用于标识 etcd 中的数据版本。他是一个 int64 类型。没操作一次 etcd 数据(增,删,改),reversion 就会递增。
# 删除数据
etcdctl del /test
1
# 查看 revision
etcdctl get / -wjson
# {"header":{"cluster_id":8735285696067307020,"member_id":7131777314758672153,"revision":16,"raft_term":4}}
# 刚才是 15 现在是 16
# 添加 /test2 数据
etcdctl put /test2 t3
OK
# 查看 revision
etcdctl get / -wjson
# {"header":{"cluster_id":8735285696067307020,"member_id":7131777314758672153,"revision":17,"raft_term":4}}
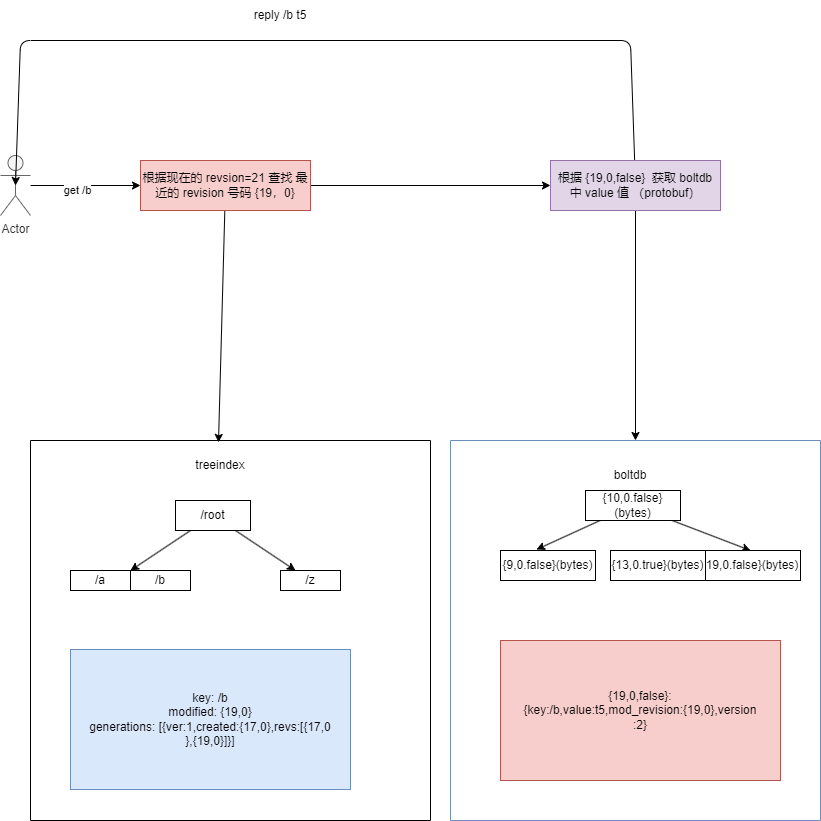
etcd mvcc 中,维护了两个数据结构,分别是 treeindex 和 boltDB。treeindex 是一个 B 树,用于存储 key 和 revision 之间的映射关系,它主要维护在内存中。而 boltDB 是一个 key-value 数据库,用于存储 key 和 value 之间的映射关系, 它主要维护在磁盘中, 用于持久化数据,虽然 boltdb 使用了 mmap 机制,但是它还是一个磁盘数据库。
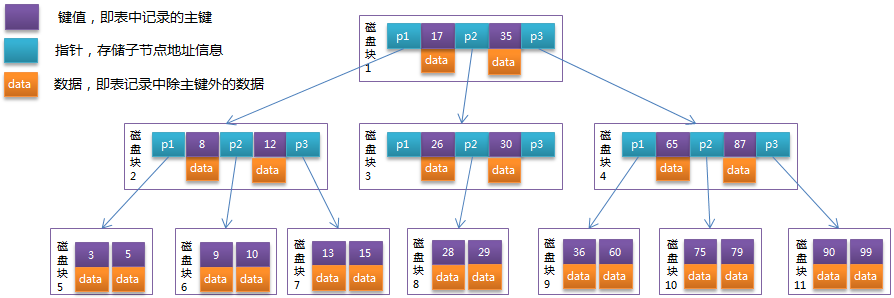
为什么 etcd 的 treeindex 使用 B-tree 而不使用哈希表、平衡二叉树?
因为 etcd 需要范围查询,所以哈希表不适合。而且etcd 中的 key 过多,平衡二叉树的查询效率不高,所以使用 B tree。
b-tree:
在 treeindex 中,数据的每个 key 是一个 keyIndex 结构,它保存了 key 和 revision 之间的映射关系。keyIndex 结构如下:
type keyIndex struct {
key []byte // key 的值
modified Revision // 最后一次修改的 main revision
generations []generation // 保存了 key 的历史版本 没删除一次然后添加一次就是一个 generation
}
type Revision struct {
// 就是 revision 的值,比如上边的 15 等
Main int64
// 子 revision 的值 主要是在事务中使用 比如事务中多个操作 那么就是 0 1 2 3 等
Sub int64
}
// generation 保存了 key 的历史版本
type generation struct {
ver int64 // 版本号
created Revision // 最后一次被创建的 revision
revs []Revision // 保存了 key 的历史 revision
}
在 treeindex 中,每个 keyIndex 保存了 key 的历史版本,而且每个 keyIndex 中的 generations 保存了 key 的历史版本。而且每个 generation 中的 revs 保存了 key 的历史 revision。这样就可以实现历史版本的查询。
获取 resersion 的值
func (ti *treeIndex) Get(key []byte, atRev int64) (modified, created Revision, ver int64, err error) {
ti.RLock()
defer ti.RUnlock()
return ti.unsafeGet(key, atRev)
}
func (ti *treeIndex) unsafeGet(key []byte, atRev int64) (modified, created Revision, ver int64, err error) {
keyi := &keyIndex{key: key}
// 从 B 树中获取 keyIndex
if keyi = ti.keyIndex(keyi); keyi == nil {
return Revision{}, Revision{}, 0, ErrRevisionNotFound
}
// 从 keyIndex 中获取 revision
return keyi.get(ti.lg, atRev)
}
func (ti *treeIndex) keyIndex(keyi *keyIndex) *keyIndex {
if ki, ok := ti.tree.Get(keyi); ok {
return ki
}
return nil
}
func (ki *keyIndex) get(lg *zap.Logger, atRev int64) (modified, created Revision, ver int64, err error) {
if ki.isEmpty() {
lg.Panic(
"'get' got an unexpected empty keyIndex",
zap.String("key", string(ki.key)),
)
}
// 找到 key 的 generation
g := ki.findGeneration(atRev)
if g.isEmpty() {
return Revision{}, Revision{}, 0, ErrRevisionNotFound
}
// 从 generation 中获取 revision 找到第一次小于 atRev 的 revision
n := g.walk(func(rev Revision) bool { return rev.Main > atRev })
if n != -1 {
return g.revs[n], g.created, g.ver - int64(len(g.revs)-n-1), nil
}
return Revision{}, Revision{}, 0, ErrRevisionNotFound
}
// 基本的意思就是从后往前找到第一个 revision 小于 atRev 的 generation
func (ki *keyIndex) findGeneration(rev int64) *generation {
lastg := len(ki.generations) - 1
cg := lastg
for cg >= 0 {
if len(ki.generations[cg].revs) == 0 {
cg--
continue
}
g := ki.generations[cg]
if cg != lastg {
// 如果当前 generation 的最后一个 revision 小于等于 rev 那么就返回 nil
if tomb := g.revs[len(g.revs)-1].Main; tomb <= rev {
return nil
}
}
if g.revs[0].Main <= rev {
return &ki.generations[cg]
}
cg--
}
return nil
}
// walk 从后往前遍历 generation
func (g *generation) walk(f func(rev Revision) bool) int {
l := len(g.revs)
for i := range g.revs {
ok := f(g.revs[l-i-1])
if !ok {
return l - i - 1
}
}
return -1
}
上边的 treeindex 拿到 revision 之后,并没有拿到 value,那么如何拿到 value 呢?这就需要用到 boltdb 了。boltdb 是一个 key-value 数据库,用于存储 key 和 value 之间的映射关系。在 etcd 中,boltdb 主要用于持久化数据。
在 etcd 中,boltdb 报错的不是 etcd key-value 数据,而他的 ket 是 revision,value 是元数据。
func (tr *storeTxnCommon) rangeKeys(ctx context.Context, key, end []byte, curRev int64, ro RangeOptions) (*RangeResult, error) {
rev := ro.Rev
// 如果 rev 大于当前的 revision 那么就返回 ErrFutureRev
if rev > curRev {
return &RangeResult{KVs: nil, Count: -1, Rev: curRev}, ErrFutureRev
}
// 如果 rev 小于等于 0 那么就是当前的 revision
if rev <= 0 {
rev = curRev
}
// 如果 rev 小于 compactMainRev 那么就返回 ErrCompacted
if rev < tr.s.compactMainRev {
return &RangeResult{KVs: nil, Count: -1, Rev: 0}, ErrCompacted
}
// 如果 re.Count 代表 count 操作 查出来直接返回数量就可以了 不需要在查 value
if ro.Count {
total := tr.s.kvindex.CountRevisions(key, end, rev)
tr.trace.Step("count revisions from in-memory index tree")
return &RangeResult{KVs: nil, Count: total, Rev: curRev}, nil
}
// 查好需要的 revision 之后,从 boltdb 中查出 value ,revpairs 是从 treeindex 中查出来的 revisions
revpairs, total := tr.s.kvindex.Revisions(key, end, rev, int(ro.Limit))
tr.trace.Step("range keys from in-memory index tree")
if len(revpairs) == 0 {
return &RangeResult{KVs: nil, Count: total, Rev: curRev}, nil
}
limit := int(ro.Limit)
if limit <= 0 || limit > len(revpairs) {
limit = len(revpairs)
}
kvs := make([]mvccpb.KeyValue, limit)
revBytes := NewRevBytes()
// 对于每个 revision 从 boltdb 中查出 value
for i, revpair := range revpairs[:len(kvs)] {
select {
case <-ctx.Done():
return nil, fmt.Errorf("rangeKeys: context cancelled: %w", ctx.Err())
default:
}
// 把 revision 转换成 bytes
revBytes = RevToBytes(revpair, revBytes)
// 从 boltdb 中查出 value
_, vs := tr.tx.UnsafeRange(schema.Key, revBytes, nil, 0)
if len(vs) != 1 {
tr.s.lg.Fatal(
"range failed to find revision pair",
zap.Int64("revision-main", revpair.Main),
zap.Int64("revision-sub", revpair.Sub),
zap.Int64("revision-current", curRev),
zap.Int64("range-option-rev", ro.Rev),
zap.Int64("range-option-limit", ro.Limit),
zap.Binary("key", key),
zap.Binary("end", end),
zap.Int("len-revpairs", len(revpairs)),
zap.Int("len-values", len(vs)),
)
}
// 把 value 转换成 mvccpb.KeyValue
if err := kvs[i].Unmarshal(vs[0]); err != nil {
tr.s.lg.Fatal(
"failed to unmarshal mvccpb.KeyValue",
zap.Error(err),
)
}
}
tr.trace.Step("range keys from bolt db")
return &RangeResult{KVs: kvs, Count: total, Rev: curRev}, nil
}
// boltdb 的 key 结构
type BucketKey struct {
Revision
// 墓碑标志 当删除的时候 先标记一下
tombstone bool
}
func (baseReadTx *baseReadTx) UnsafeRange(bucketType Bucket, key, endKey []byte, limit int64) ([][]byte, [][]byte) {
if endKey == nil {
// forbid duplicates for single keys
limit = 1
}
if limit <= 0 {
limit = math.MaxInt64
}
if limit > 1 && !bucketType.IsSafeRangeBucket() {
panic("do not use unsafeRange on non-keys bucket")
}
// 从缓存中拿出数据
keys, vals := baseReadTx.buf.Range(bucketType, key, endKey, limit)
if int64(len(keys)) == limit {
return keys, vals
}
// find/cache bucket
bn := bucketType.ID()
baseReadTx.txMu.RLock()
bucket, ok := baseReadTx.buckets[bn]
baseReadTx.txMu.RUnlock()
lockHeld := false
if !ok {
baseReadTx.txMu.Lock()
lockHeld = true
bucket = baseReadTx.tx.Bucket(bucketType.Name())
baseReadTx.buckets[bn] = bucket
}
// ignore missing bucket since may have been created in this batch
if bucket == nil {
if lockHeld {
baseReadTx.txMu.Unlock()
}
return keys, vals
}
if !lockHeld {
baseReadTx.txMu.Lock()
}
c := bucket.Cursor()
baseReadTx.txMu.Unlock()
// 从 boltdb 中查出数据
k2, v2 := unsafeRange(c, key, endKey, limit-int64(len(keys)))
return append(k2, keys...), append(v2, vals...)
}
etcdctl get /b 命令获取数据{man: 19, sub: 0}{man: 19, sub: 0, tombstone: false} 从 boltdb 中获取 value 值 他是一个protobuf 序列化的数据