数据库索引对于优化数据库性能至关重要。它们通过提供表中行的快速访问路径来帮助加快数据检索速度。了解索引的工作原理、类型及其最佳实践可以显著提高数据库查询的效率。
索引是一种数据结构,可以提高数据库表上数据检索操作的速度。它就像书中的索引一样,让您无需扫描整个文本即可快速找到信息。
想象一下一本 1000 页的大书,假设您正在尝试查找包含与某个词相关的信息的页面。如果没有索引页,您将必须浏览每一页,这可能要花费几个小时甚至几天的时间。但是有了索引页,您就知道该去哪里找!一旦找到正确的索引,您就可以有效地跳转到该页面。
索引是按字母顺序排列的,并且为特定信息提供了页码,这样就节省了我们翻阅每一页的时间。

数据库索引的工作方式类似。它们引导数据库找到数据的准确位置,从而实现更快、更高效的数据检索。
在本文中,我们将探讨:
什么是数据库索引?
它们如何工作?
使用它们的好处。
不同类型的索引。
他们使用哪种数据结构?
如何巧妙地使用它们?
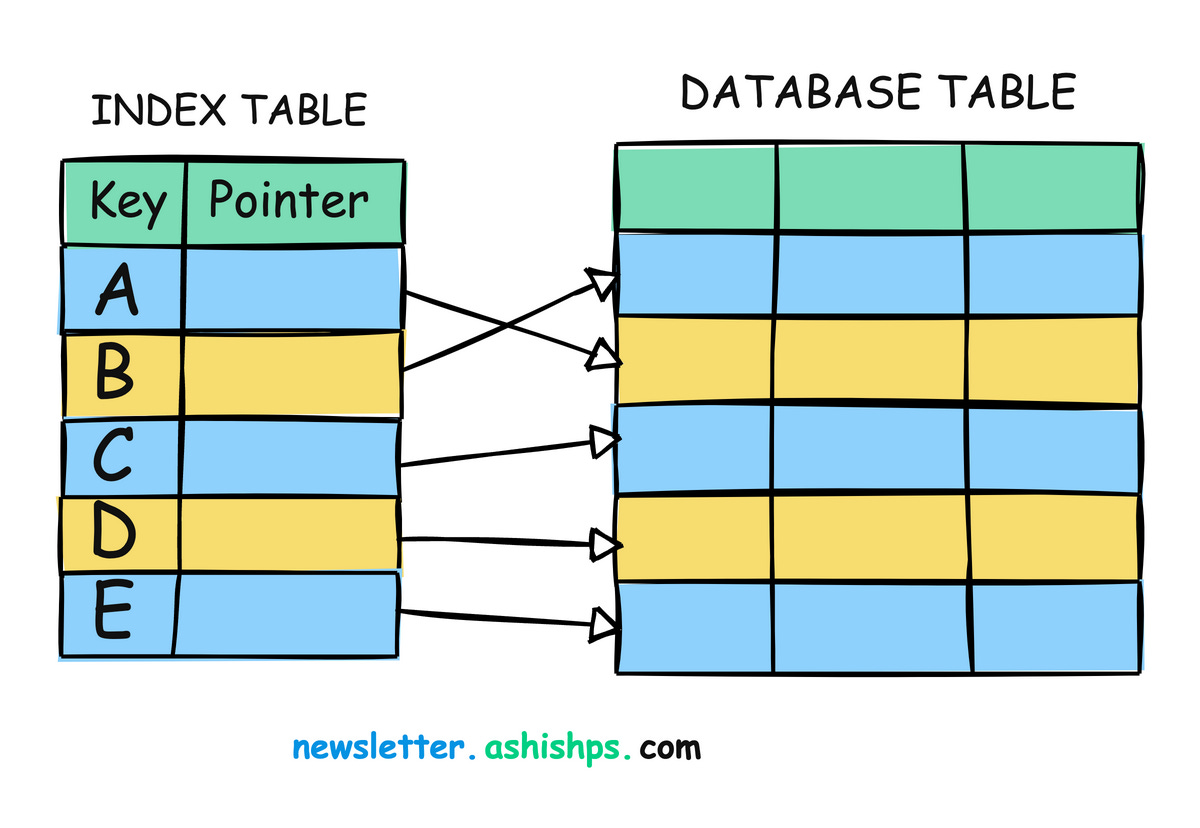
数据库索引是一种超高效的查找表,可以让数据库更快地找到数据。
它保存索引列值以及指向表中相应行的指针。
如果没有索引,数据库可能必须扫描海量表中的每一行才能找到所需内容——这是一个非常缓慢的过程。
但是,有了索引,数据库就可以使用索引的指针精确地找到所需数据的准确位置。
以下是在 MySQL 数据库中创建索引的示例。
假设我们有一个名为employees以下结构的表:

现在,让我们在该last_name列上创建一个索引,以提高根据姓氏经常搜索或排序的查询的性能。

在本例中,我们使用语句在表上CREATE INDEX创建一个名为的索引。索引是在列上创建的。idx_last_name``employees``last_name
创建索引后,涉及条件或对该last_name列进行排序的查询将被优化。例如:

该查询将使用idx_last_name索引快速定位为“Smith”的行last_name,避免全表扫描。
如果您的查询经常同时涉及多个列上的条件,您还可以在多个列上创建索引(复合索引)。例如:

first_name这会在和列上创建一个复合索引last_name,这对于基于两列进行搜索或排序的查询很有用。
以下是数据库索引如何工作的逐步说明:
索引创建:数据库管理员在特定列或一组列上创建索引。
索引构建:数据库管理系统通过扫描表并存储索引列的值以及指向相应数据的指针来构建索引。
查询执行:执行查询时,数据库引擎会检查所请求的列是否存在索引。
索引搜索:如果存在索引,数据库将在索引中搜索所请求的数据,并使用指针快速定位数据。
数据检索:数据库使用索引中的指针检索请求的数据。
数据库索引有几个好处,包括:
更快的查询性能:索引可以通过减少需要扫描的数据量来显著提高查询性能,特别是对于大型数据集。
减少 CPU 使用率:通过减少需要扫描的行数,索引可以降低 CPU 使用率并优化资源利用率。
快速数据检索:索引可以对涉及索引列上的相等性或范围条件的查询进行快速数据检索。
高效排序:索引还可用于根据索引列对数据进行高效排序,从而无需昂贵的排序操作。
更好的数据组织:索引可以帮助维护数据组织和结构,使数据库更易于管理和维护。
主索引:在表上定义主键约束时自动创建。确保唯一性并帮助使用主键进行超快速查找。
聚集索引:确定数据在表中的物理存储顺序。当我们在某个范围内搜索时,聚集索引最有用。每个表只能有一个聚集索引。
非聚集索引或二级索引:这种索引不按索引顺序存储数据。相反,它提供指向数据实际存储位置的虚拟指针或引用列表。
密集索引:表中每个搜索键值都有一个条目。适用于数据具有少量不同搜索键值或需要快速访问单个记录的情况。
稀疏索引:仅包含部分搜索键值的条目。适用于数据具有大量不同搜索键值的情况。
位图索引:非常适合基数较低的列(不同值较少)。在数据仓库中很常见。
哈希索引:使用哈希函数将值映射到特定位置的索引。非常适合精确匹配查询。
过滤索引:根据特定过滤条件对行子集进行索引。有助于提高常见过滤列的查询速度。
覆盖索引:索引本身包含查询所需的所有列,无需访问底层表数据。
基于函数的索引:根据对表的一个或多个列应用函数或表达式的结果创建的索引。
全文索引:专为全文搜索而设计的索引,可以有效地搜索文本数据。
空间索引:用于索引地理数据类型。
最常用的索引数据结构是 B 树、哈希表和位图。
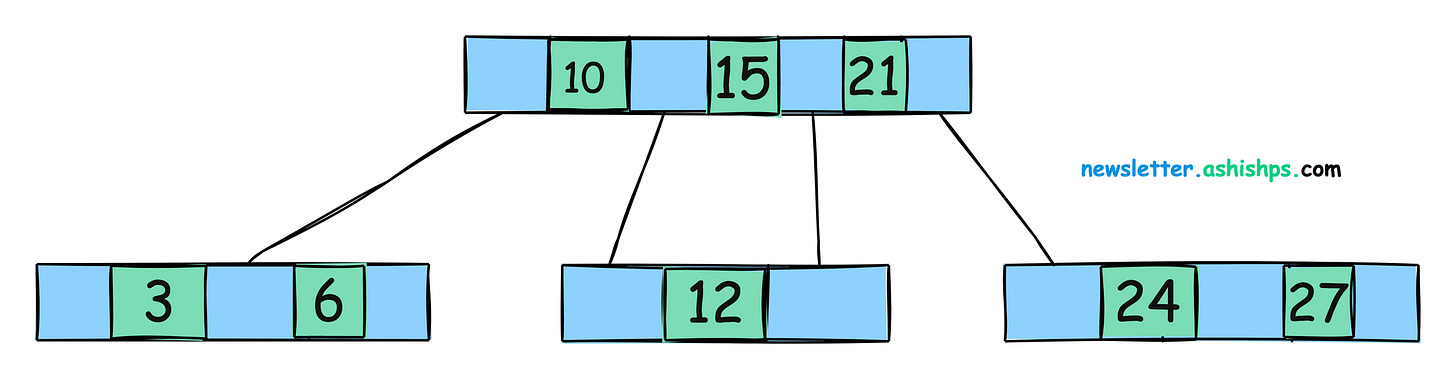
大多数数据库引擎都使用 B 树或 B 树的变体,例如 B+ 树。
B 树具有层次结构,包括根节点、内部节点(索引节点)和叶节点。
B 树中的每个节点都包含一个已排序的键数组和指向子节点的指针。
它们如此适合的原因如下:
自平衡:B 树确保树的“高度”即使在插入或删除数据时也能保持平衡。这确保了logarithmic time complexity插入、删除和搜索。
有序:B 树保持数据排序,使得范围查询(“查找日期 X 和 Y 之间的所有订单”)和不等式比较非常快。
磁盘友好:B 树的设计旨在与基于磁盘的存储配合使用。B 树的单个节点通常对应一个磁盘块,从而最大限度地减少磁盘访问操作。
许多数据库使用经过稍微修改的 B 树变体,称为 B+ 树。
在 B+ 树中,所有数据值都仅存储在叶节点中,这可以进一步提高范围查询等某些用例的性能。
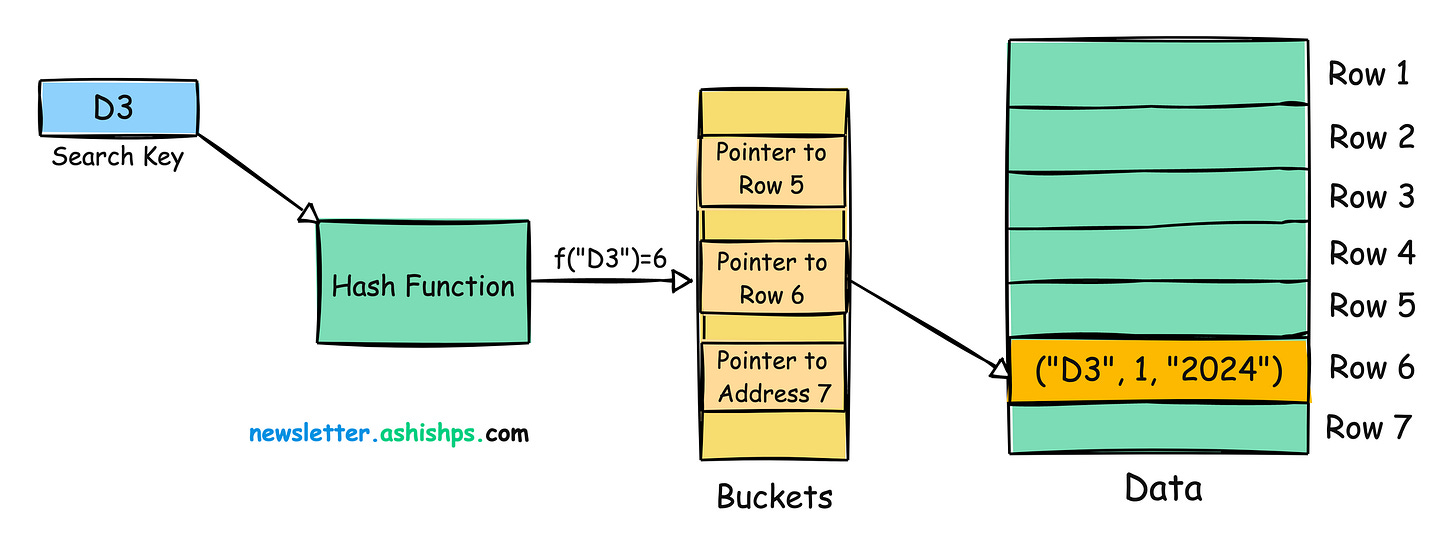
哈希表用于哈希索引,它基于哈希函数。
哈希表由一组桶组成,每个桶包含数据中行的地址。
哈希索引使用哈希函数将键映射到哈希表中对应的存储桶,从而实现恒定时间的查找操作。
哈希索引提供快速的相等查找,因为哈希函数根据键确定数据的确切位置。
但是,哈希索引不能有效地支持范围查询或排序。
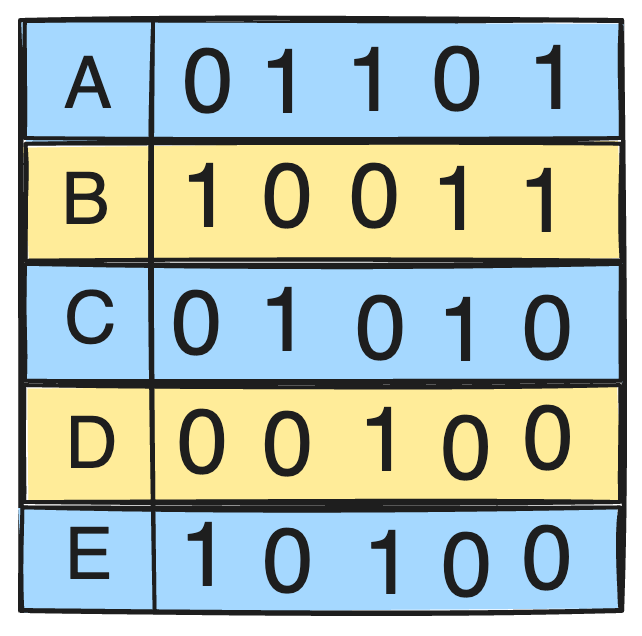
位图中的每个位对应一行,位的值表示该键值是否存在于该行中。
位图索引使用位图(二进制数组)来表示表的每一行中特定键值的存在或不存在。
位图索引非常适合基数较低(少量不同值)的列以及执行涉及多个条件的复杂查询。
位图运算(例如 AND、OR 和 NOT)可以通过按位运算高效执行,从而使位图索引适合涉及多列的分析查询。
为了充分利用数据库索引,请考虑以下最佳做法:
识别查询模式:分析针对数据库执行的最常见和最关键的查询,以确定要索引哪些列以及使用哪种类型的索引。
索引常用列:考虑索引在 WHERE、JOIN 和 ORDER BY 子句中经常使用的列。
索引选择性列:索引对数据值分布良好(高基数)的列最有效。索引gender列的益处可能不如具有唯一值的列customer_id。
使用适当的索引类型:为您的数据和查询选择正确的索引类型。
考虑复合索引:对于涉及多列的查询,请考虑创建包含所有相关列的复合索引。这减少了对多个单列索引的需求并提高了查询性能。
监控索引性能:定期监控索引性能,删除未使用的索引并随着数据库工作负载的变化调整索引策略。
避免过度索引:避免创建过多的索引,因为这会导致存储需求增加和写入性能降低。
索引占用额外的磁盘空间,因为它们是需要与表一起存储的附加数据结构。
每次在有索引的表中插入、更新或删除数据时,索引也需要更新。这会稍微减慢写入操作的速度。
