Master公式,又称为Master定理或主定理,是分析递归算法时间复杂度的一种重要工具,尤其适用于具有分治结构的递归算法。
Master公式本身就是递归的形式,是递归方法时间复杂度的一种表示法。T(n) 代表递归方法处理规模为n的数据量的时间复杂度,T(n/b) 代表调用子递归方法的总体时间复杂度,O(nd) 代表调用子递归方法这行代码外其他代码(下面简称递归外代码)的时间复杂度。
T(n) 是时间复杂度的函数表示法(T=Time)。O(n) 是时间复杂度的表示法,可以理解成一个方法要处理
n条数据时,最坏的情况下需要循环执行n次代码所带来的时间成本。
注意:如果一个递归方法每次子问题递归的规模缩小的比例不等,那么无法使用上面的公式。
只要一个递归方法满足Master公式,那么它的时间复杂度就可以确定:
logba 指的是以
b为底的a的对数,且有 blogba=a,例如 32=9,则log39=2。logn 指的是以2为底的n的对数。
这里时间复杂度实际上就是看 d 和 logba 谁大,取大的那个值为n的指数。如果一样大,任意取一个作为指数,再乘以 logn 即可。这样就好记多了。
二分查找(Binary Search),这是一种在有序数组中查找特定元素的高效算法。它每次将数组分为2半,将要查找的元素与中位值比较,如果小于中位值,则在左边这一半查找,反之则去右边查找。众所周知,二分查找的时间复杂度是 O(logn),下面就来看看它是怎么得来的。
public class BinarySearch {
private static int binarySearch(int[] array, int target, int low, int high) {
if (low > high) {
// 如果搜索范围为空,表示未找到目标
return -1;
}
// 计算中间索引
int mid = low + (high - low) / 2;
// 如果中间元素等于目标,返回索引
if (array[mid] == target) {
return mid;
}
// 如果中间元素大于目标,递归搜索左半部分
else if (array[mid] > target) {
return binarySearch(array, target, low, mid - 1);
}
// 如果中间元素小于目标,递归搜索右半部分
else {
return binarySearch(array, target, mid + 1, high);
}
}
}
复制确定a/b/d的值
a=1:每次递归执行binarySearch()方法时,只会执行1次,要么递归搜索左半部分,要么递归搜索右半部分
b=2:每次递归处理的数据量是原来的1/2
d=0:除了调用递归方法外,没有复杂的循环逻辑,因此时间复杂度是常量级O(1),即 nd=1
推导时间复杂度
logba = log21 = 0 = d,因此满足 d=logba,那么时间复杂度为:O(nd * logn) = O(n0 * logn) = O(logn)。
下面的示例是考虑最坏的情况,即递归到只剩下最后1个数时才能找到。
前提:根据代码可知,调用递归方法这行代码(不考虑方法内的实现)的时间复杂度为O(1),执行递归方法外代码(包括计算中间索引和判断中间元素是否等于目标等代码)的时间复杂度为O(1)。
n=1 子递归方法执行次数:0 递归外代码执行次数:1 时间复杂度:O(1)复制
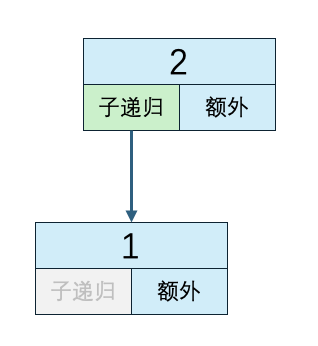
灰色的块表示不会执行
子递归方法执行次数=箭头的数量
递归外代码执行次数=非灰色的额外块数量
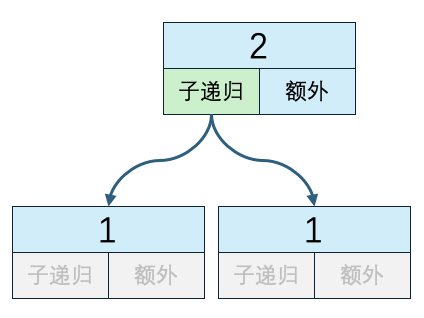
n=2 子递归方法执行次数:1 递归外代码执行次数:2 时间复杂度:1*O(1) + 2*O(1)复制
除了每个子递归方法里执行了额外代码外,主递归方法里也执行了一次,因此递归外代码执行次数是子递归方法执行次数+1
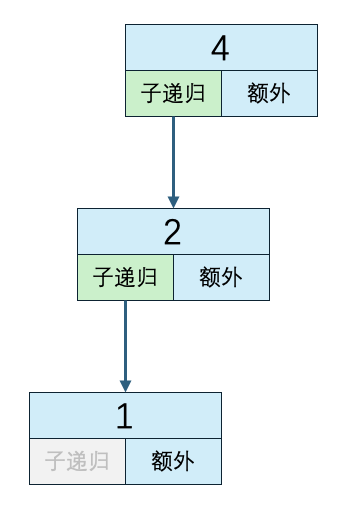
n=4 子递归方法执行次数:2 递归外代码执行次数:3 时间复杂度:2*O(1) + 3*O(1)复制
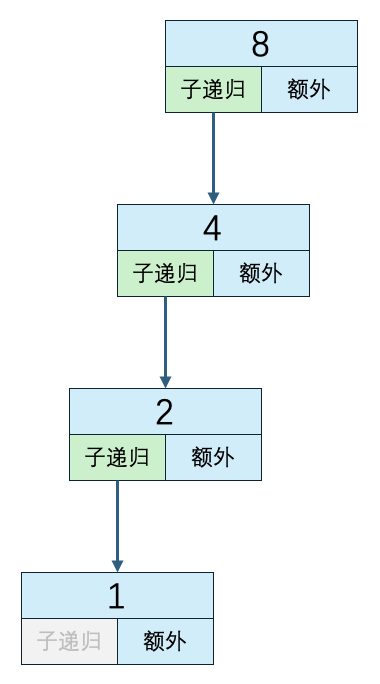
n=8 子递归方法执行次数:3 递归外代码执行次数:4 时间复杂度:3*O(1) + 4*O(1)复制
可以看出,每次执行子递归方法时,数组的大小都是除以2缩至原来的一半,一直到缩至1为止。设递归深度为x,那么 2x=n,因此递归深度就是 x=logn。
因为每一层递归只会执行1次子递归方法,因此递归方法执行次数和递归的深度一样,是:
每个子递归方法都要执行1次递归外代码,父递归方法也要执行1次递归外代码,因此递归外代码的执行次数是:
执行所有子递归方法(不考虑方法内的实现)的时间复杂度:
所有递归外代码的时间复杂度:
忽略常量 1
整体的时间复杂度
忽略常量 2
可以看出,二分查找的时间复杂度主要取决于递归的深度。
再回头看Master公式推导时间复杂度的第2种情况:当 d=logba 时,递归时间复杂度为:O(nd * logn)
归并排序(Merge Sort)是一种分而治之的算法,它将数组分成越来越小的部分直到每个部分只有一个元素,然后将这些部分两两合并成有序的数组。归并排序的时间复杂度是 O(n * logn),下面就来看看它是怎么得来的。
public class MergeSort {
// 递归排序函数
private static void mergeSort(int[] array, int left, int right) {
if (left < right) {
// 找到中间点
int mid = (left + right) / 2;
// 分别对左右两边进行排序
mergeSort(array, left, mid);
mergeSort(array, mid + 1, right);
// 合并两个有序数组
merge(array, left, mid, right);
}
}
// 合并两个有序数组
private static void merge(int[] array, int left, int mid, int right) {
// 创建临时数组存放合并后的结果
int[] temp = new int[right - left + 1];
int i = left, j = mid + 1, k = 0;
// 比较左右两部分的元素,依次放入temp数组
while (i <= mid && j <= right) {
if (array[i] <= array[j]) {
temp[k++] = array[i++];
} else {
temp[k++] = array[j++];
}
}
// 将剩余部分依次放入temp
while (i <= mid) {
temp[k++] = array[i++];
}
while (j <= right) {
temp[k++] = array[j++];
}
// 将temp数组复制回原数组
System.arraycopy(temp, 0, array, left, temp.length);
}
}
复制确定a/b/d的值
a=2:每次递归执行mergeSort()方法时,会执行2次
b=2:每次递归处理的数据量是原来的1/2
d=1:每次递归都需要遍历传入的下标范围内每一个元素,因此时间复杂度是O(n),即n1=n
推导时间复杂度
logba = log22 = 1 = d,因此满足 d=logba,那么时间复杂度为:O(nd * logn) = O(n1 * logn) = O(n * logn)。
前提:根据代码可知,调用递归方法这行代码(不考虑方法内的实现)的时间复杂度为O(1),执行递归方法外代码(包括计算中间索引和合并有序数组等代码)的时间复杂度为O(n)。
n=1 子递归方法执行次数:0 递归外代码执行次数:0 时间复杂度:O(1)复制
此时
left=right=0,进不去if条件。执行空方法的时间复杂度就是O(1),常量级的
n=2 子递归方法执行次数:2 递归外代码执行次数:1 时间复杂度:2*O(1) + 1*O(2)复制
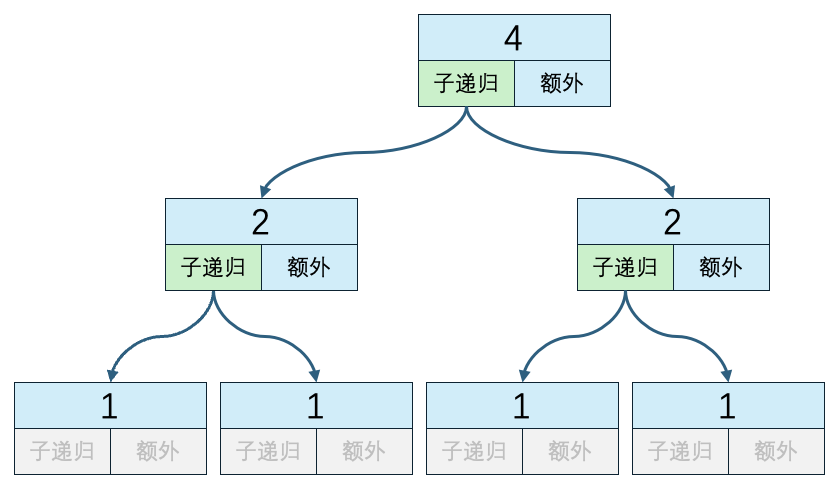
n=4 子递归方法执行次数:6 递归外代码执行次数:3 时间复杂度:6*O(1) + O(4) + 2*O(2)复制
因为每次执行递归方法外代码的时间复杂度为
O(n),所以这里3次递归外代码的时间复杂度不一样。主递归方法中会遍历4次,是O(4);2个子递归方法中会遍历2次,都是O(2)
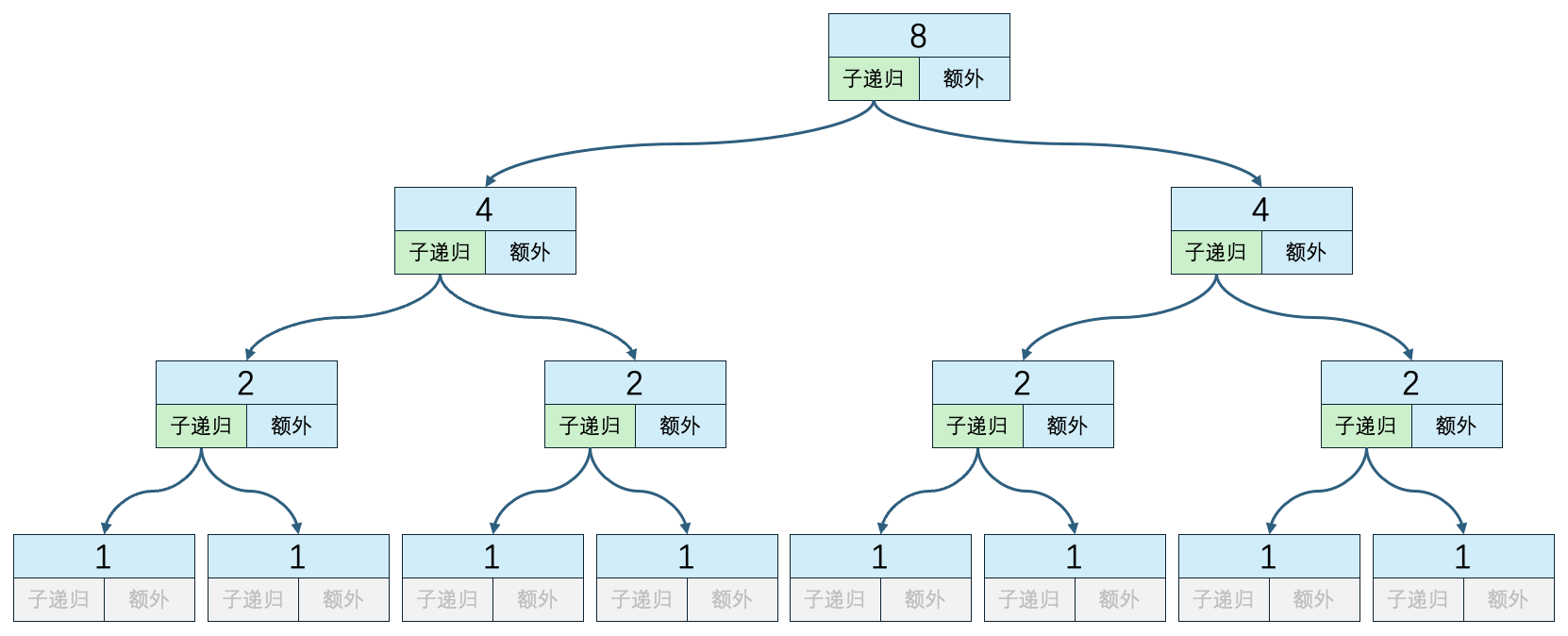
n=8 子递归方法执行次数:14 递归外代码执行次数:7 时间复杂度:14*O(1) + O(8) + 2*O(4) + 4*O(2)复制
子递归方法执行次数=箭头的数量
递归外代码执行次数=非灰色的额外块数量
每次执行子递归方法时,数组的大小也是缩至原来的一半,一直到缩至1为止。同理递归的深度就是 logn。
上图中子递归方法执行次数依次为:0、2、6、14...
找一下规律:假设父递归方法中所有子递归次数对应的函数为f(n),由于父递归处理的数据规模是子递归的2倍,因此子递归方法中所所有子递归次数对应的函数为f(n/2),父递归方法会执行2次子递归方法,那么这2次子递归方法中的所有子递归次数就是2*f(n/2),父递归方法中执行的2次子递归方法,也要加进去,那么可得:f(n)=2*f(n/2)+2。
验证一下:
f(1)=0。
f(2)=2*0 + 2 = 2。
f(4)=2*2*0 + 2*2 + 2 = 6。
f(8)=2*2*2*0 + 2*2*2 + 2*2 + 2 = 14。
可以推导出:f(2x) = 2x + 2x-1 + ... + 21(x=logn)。
可以看出,每一项都是后一项的2倍,所以这些因子项就是一个等比数列。等比数列的通项为:
那么可推导出这个等比数列是:
根据等比数列求和公式:
可以推导出:
由于 f(2x)=S(x),因此 f(n) = S(logn),代入可得子递归方法执行次数:
每个子递归方法都要执行1次递归外代码,父递归方法也要执行1次递归外代码,但是叶子递归节点(n=1)不需要执行递归外代码,从图中可以看出一共有n个叶子递归节点,所以递归方法外代码的执行次数就是:
执行所有子递归方法(不考虑方法内的实现)的时间复杂度:
忽略常量项2和1
所有递归外代码的时间复杂度:
这里还不能简单的用(n-1) * O(n)得到时间复杂度,这种方式仅适用于时间复杂度为O(1)的情况。从上图里可以看出,每一层执行递归外代码的时间复杂度都不一样,和这一层的n有关。将每一层的时间复杂度累加,可得:
可以看出每一项的结果都是O(n),只要得出有多少项即可。这里的每一项其实就对应着上图中的每一层,因此这里的项数其实就是递归的深度 logn。因此递归外代码的时间复杂度就是:
整体的时间复杂度:
O(n) 远小于 O(n * logn),可以直接忽略
再回头看Master公式推导时间复杂度的第2种情况:当 d=logba 时,递归时间复杂度为:O(nd * logn)
因为上面两个例子都匹配上 d=logba 这个条件,这里再举一个不一样的例子。这个例子可以快速地浏览。
疯子版二分查找,是在原来的基础上,增加一个for循环,仅仅是为了增加递归外代码的时间复杂度,改变Master公式中d的值。
public class BinarySearch {
private static int binarySearch(int[] array, int target, int low, int high) {
if (low > high) {
// 如果搜索范围为空,表示未找到目标
return -1;
}
// 无意义的for循环,为了提升递归外代码的时间复杂度
for (int i = low; i < high + 1; i++) {
System.out.println(array[i]);
}
// 计算中间索引
int mid = low + (high - low) / 2;
// 如果中间元素等于目标,返回索引
if (array[mid] == target) {
return mid;
}
// 如果中间元素大于目标,递归搜索左半部分
else if (array[mid] > target) {
return binarySearch(array, target, low, mid - 1);
}
// 如果中间元素小于目标,递归搜索右半部分
else {
return binarySearch(array, target, mid + 1, high);
}
}
}
复制确定a/b/d的值
a=1:每次递归执行binarySearch()方法时,只会执行1次,要么递归搜索左半部分,要么递归搜索右半部分
b=2:每次递归处理的数据量是原来的1/2
d=1:除了调用递归方法外,还有个for循环逻辑,因此时间复杂度是O(n),即 nd=1
推导时间复杂度
logba = log21 = 0 < d,因此满足 d>logba,那么时间复杂度为:O(nd) = O(n)
下面的示例是考虑最坏的情况,即递归到只剩下最后1个数时才能找到。
前提:根据代码可知,调用递归方法这行代码(不考虑方法内的实现)的时间复杂度为O(1),执行递归方法外代码(包括for循环打印等代码)的时间复杂度为O(n)。
n=1 子递归方法执行次数:0 递归外代码执行次数:1 时间复杂度:O(1)复制
n=2 子递归方法执行次数:1 递归外代码执行次数:2 时间复杂度:1*O(1) + O(2) + O(1)复制
n=4 子递归方法执行次数:2 递归外代码执行次数:3 时间复杂度:2*O(1) + O(4) + O(2) + O(1)复制
n=8 子递归方法执行次数:3 递归外代码执行次数:4 时间复杂度:3*O(1) + O(8) + O(4) + O(2) + O(1)复制
这里递归深度还是 x=logn。
子递归方法执行次数和递归的深度一样,是 logn。
递归外代码的执行次数是 logn + 1。
执行所有子递归方法(不考虑方法内的实现)的时间复杂度:
所有递归外代码的时间复杂度:
这里也不能简单的用 (logn + 1) * O(n) 得到时间复杂度,从上图里可以看出,每一层执行递归外代码的时间复杂度都不一样,和这一层的n有关。时间复杂度应该是:
可以看出前后项之间都是2倍的关系,其实就是对等比数列求和。前面的3.4.3 递归方法执行次数的推导结论可以直接复用,即这里的时间复杂度就是:
整体的时间复杂度:
因为 logn 在 n 面前就是个弟弟,可以直接忽略
可以看出,这个例子的时间复杂度主要取决于执行所有子递归方法和所有递归外代码的时间复杂度谁大。
再回头看Master公式推导时间复杂度的第3种情况:当 d>logba 时,递归时间复杂度为:O(nd)
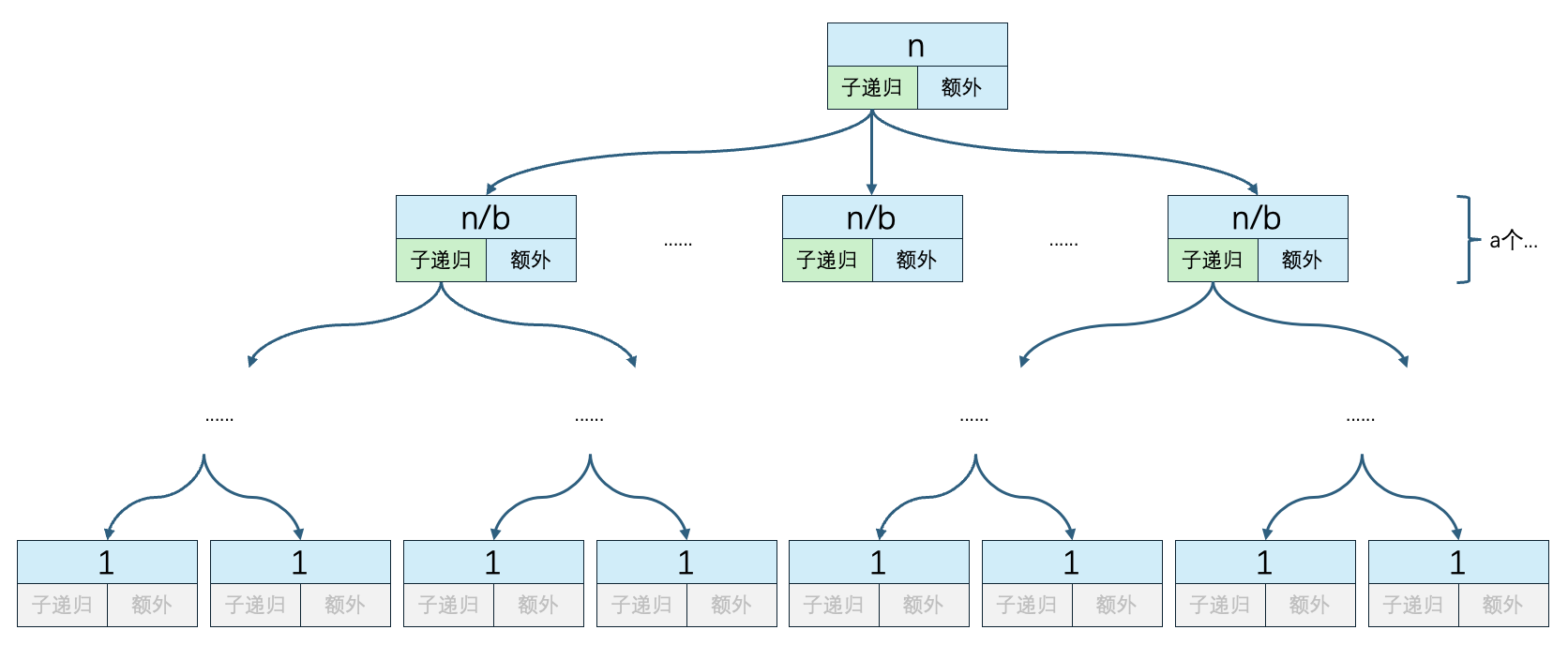
b是子问题的规模缩小的比例,因此递归的深度和b有关。每一次递归都需要除以b,一直除到等于1为止。反过来说,就是b * b * b...一直乘到等于n为止,b相乘的个数就是递归的深度。设深度为x,那么n=bx,x=logbn。
因此递归的深度就是 logbn。
递归方法执行次数其实和两个变量有关,递归的深度和每次递归时调用子递归的次数。
当每次递归时调用子递归的次数等于1时:
递归方法执行次数就是递归的深度,即:
当每次递归时调用子递归的次数大于1时:
(1)假设父递归方法中递归次数对应的函数为f(n),由于父递归处理的数据规模是子递归的b倍,因此子递归方法中递归次数对应的函数为f(n/b),执行a次子递归方法,这a次子递归方法中的总递归次数就是a*f(n/b),父递归方法中执行的a次子递归方法也要加进去,那么可得:f(n)=a*f(n/b)+a。
(2)枚举n的值来找规律:
正常情况下,当n=1时,f(1)=0(当数据规模只有1个时,不需要执行子递归方法)。
当n=b时,f(b)= a * 0 + a。
当n=b2时,f(b2)= a2 * 0 + a2 + a。
当n=b3时,f(b3)= a3 * 0 + a3 + a2 + a。
当n=bx时,f(bx)= ax + ax-1 + ... + a。
去掉求和因子中的第一项(因为第一项等于0),剩下的那些项(a3/a2/a)其实就是个等比数列。可推导出这个等比数列是:
这个等比数列对应的求和公式是:
由于 f(bx)=S(x),因此 f(n) = S(logbn),代入可得:
(3)化简公式:
这里主要简化一下 alogbn,因为它包含n。根据对数的换底公式:
可得:
根据指数运算法则:
可得:
推到这里,醍醐灌顶!恍然大悟!!原来 logba 藏在这里!!!
(4)综上,子递归方法执行次数为:
每个子递归方法都要执行1次递归外代码,父递归方法也要执行1次递归外代码,因此递归外代码的执行次数是递归方法执行次数+1。
不过呢,递归方法外代码的时间复杂度并不能简单地用执行次数乘以单次的时间复杂度,这一点从归并排序的例子中可以看出来。但是如果单次递归外代码的时间复杂度是O(1)时,则递归方法外代码的时间复杂度就取决于归外代码的执行次数了。这一点在下面的5.4.2小节中分成2种情况来讨论。
不考虑递归方法内部的实现,仅考虑所有只调用子递归方法这一行代码的时间复杂度时,调用单行代码的时间复杂度为:O(1)。所有子递归方法(不考虑递归方法内部的实现)的时间复杂度=单行子递归方法的时间复杂度*子递归方法执行次数。因此可得:
常数项a和1可以忽略
当d=0时,单次递归外代码的时间复杂度是 O(nd) = O(1),因此时间复杂度主要取决于递归外代码执行次数(和所有子递归方法的时间复杂度一样):
根据对数的换底公式可知, logbn=logn/logb,而常数项 logb 可以忽略,因此可以 O(logbn) 直接写成 O(logn)。
当d=0时,nd=1,因此第一项时间复杂度乘以 nd 也不影响整体结果,且离推导结果更近了一步。
当d>0时,单次递归外代码的时间复杂度是 O(nd),下一层的单次子递归外代码的时间复杂度是 O((n/d)d),将每一层累加可得到时间复杂度:
推导一下最后一项的值:从上往下,第二层有a个子递归方法,第三层有a*a个子递归方法,因此第x层有ax个子递归方法。第二层n除以了b,第三层n除以了b2,和a的指数一样,因此第x层n除以了bx。
那么最后一层对应的x是多少呢?每向下一层,x就+1,因此这个x其实就是递归的深度 log n。那么最后一项就是:alogn * O((n/blogn)d)。综上可得:
最后一项,因为相乘的两个因子中都包含n,为了消去其中一个n,分为以下两种情况来讨论:
(1)当 (a/bd)=1 时,即 logba=d 时,上式中所有的 (a/bd)x 结果都为1,可以消掉。累加的因子数量其实就是递归的深度:logbn。因此时间复杂度就是:
因为d>0,所以一定有a>1。因为a=1时,logba=0,那么logba=d就不成立了。
(2)当 (a/bd)!=1 时,再化简下上面的公式:
可以看出这些项(1、a/bd、(a/bd)2、(a/bd)logbn)其实就是个等比数列。等比数列的第一项是 a1=1,可推导出这个等比数列是:
这个等比数列对应的求和公式是:
从(2)中化简后的公式可以看出,T(n) 中求和的因子个数是 logbn,因此 T(n) = nd * S(logbn)。
前面已经论证过:alogbn=nlogba
代入可得:
根据 (a/bd)<1 和 (a/bd)>1,将上式分为两种情况,可得:
综合上面两种情况 (a/bd)=1 和 (a/bd)!=1 ,d>0 时的时间复杂度为:
将d=0和d>0合并,所有递归外代码的时间复杂度为:
可以看出,这就是根据Master公式推导的递归方法的时间复杂度。
递归方法的整体时间复杂度=所有子递归方法的时间复杂度+所有递归外代码的时间复杂度(两个时间复杂度相加,小的那一个可以直接忽略)。
上面是所有子递归方法的时间复杂度,它的时间复杂度比递归外代码的时间复杂度差远了,可以忽略。因此递归方法的整体时间复杂度主要取决于所有递归外代码的时间复杂度。
递归方法的整体时间复杂度:
这就和Master公式推导的递归方法的时间复杂度完全吻合了: