虽然头条现在非常强大,但是我还是不得不吐槽一下头条的博客发布,居然不支持markdown格式。
并且在某些浏览器上还会出现编辑页面打不开的情况,让我一度怀疑是我浏览器的问题。
不过,这都不重要,重要的是blog-auto-publishing-tools这个工具可以实现头条的自动化。
前提条件当然是先下载 blog-auto-publishing-tools这个博客自动发布工具,地址如下:https://github.com/ddean2009/blog-auto-publishing-tools
头条需要填写的内容也是挺多的。
我们接下来一个个来实现。
虽然头条的标题是一个textarea,但是没有id或者name,所以我们只能通过placeholder来获得这个标题:
# 文章标题
title = driver.find_element(By.XPATH, '//div[@class="publish-editor-title-inner"]//textarea[contains(@placeholder,"请输入文章标题")]')
title.clear()
if 'title' in front_matter['title'] and front_matter['title']:
title.send_keys(front_matter['title'])
else:
title.send_keys(common_config['title'])
复制头条的正文用的也是ProseMirror,这是一个动态的文本编辑器,会随着你输入的内容动态更新html。所以不能用传统的textArea的方式来实现。
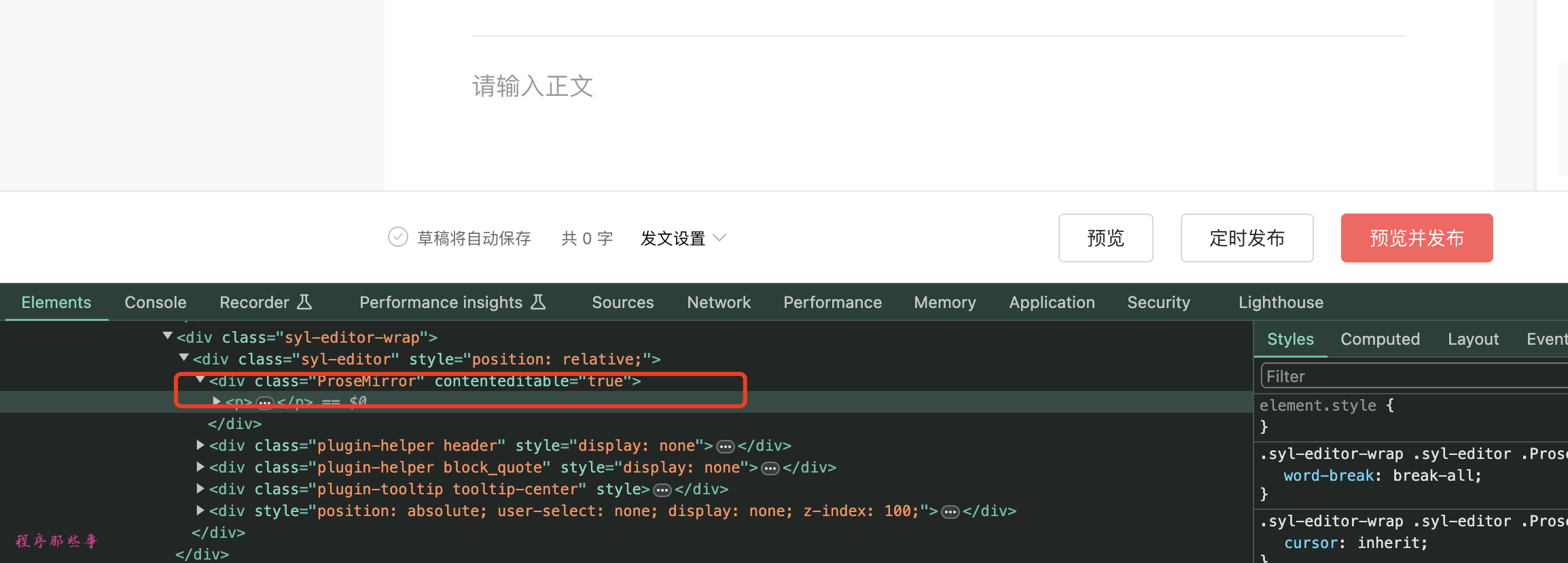
在实现上我们可以使用拷贝粘贴的方式来实现。
现在还剩一个大问题,就是头条不支持markdown格式。
我们还需要考虑先把markdown格式转换成html,然后直接拷贝html到正文的内容里面。
网上有很多把markdown转换成html的工具,其中一个比较出名的就是pandoc。
pandoc的功能很强大,可以转换很多格式的文本。
对于markdown转换成html,可以使用下面的命令:
pandoc -f markdown -t html5 input.md -o output.html复制
当然为了拷贝出来的样式好看一些,这里我还添加了css文件。
实现方法都写在了convert_md_to_html方法里面了。
感兴趣的朋友可以去看看。
最后我们的实现代码如下:
# 文章内容 html版本
content_file = common_config['content']
content_file_html = convert_md_to_html(content_file)
get_html_web_content(driver, content_file_html)
time.sleep(2) # 等待2秒
driver.switch_to.window(driver.window_handles[-1])
time.sleep(1) # 等待1秒
# 用tab定位,然后拷贝
cmd_ctrl = Keys.COMMAND if sys.platform == 'darwin' else Keys.CONTROL
# 模拟实际的粘贴操作(在某些情况下可能更合适):
action_chains = webdriver.ActionChains(driver)
# 定位到要粘贴的位置
content_element = driver.find_element(By.XPATH, '//div[@class="publish-editor"]//div[@class="ProseMirror"]')
content_element.click()
time.sleep(1)
action_chains.key_down(cmd_ctrl).send_keys('v').key_up(cmd_ctrl).perform()
time.sleep(3) # 等待3秒
复制解释下实现的逻辑。
convert_md_to_html是把markdown转换成了html。
get_html_web_content是在新的web tab中打开这个html文件,然后使用系统的复制功能把html内容拷贝到剪贴板上。
然后再定位到要粘贴的位置,使用系统的粘贴功能把内容粘贴到内容框中。
是不是很复杂?
一般来说头条会自动为我们设置标题。所以这里就不选择了。
目前还没看到头条的封面上传的input标签,所以这个功能展示还没实现。
大家就手动上传封面吧~~~
摘要是一个textarea,我们根据placeholder来定位到这个元素:
summary_input = driver.find_element(By.XPATH, '//div[@class="multi-abstract-cell-content-input"]//textarea[contains(@placeholder,"好的摘要比标题更吸引读者")]')
summary_input.send_keys(summary)
复制当然,我们要设置成原创:
original_button = driver.find_element(By.XPATH, '//div[@class="original-tag"]//span[contains(text(),"声明原创")]')
original_button.click()
time.sleep(2)
复制这里用xpath定位,判断text中是否包含声明原创这几个字。
最后就是最终的发布按钮了,我们通过class中是否包含publish-btn-last来判断。
publish_button = driver.find_element(By.XPATH, '//div[contains(@class,"publish-btn-last")]')
publish_button.click()
复制头条页面设计的基本上没啥规范,所以获取元素比较困难,大部分都是需要通过xpath来定位才行。