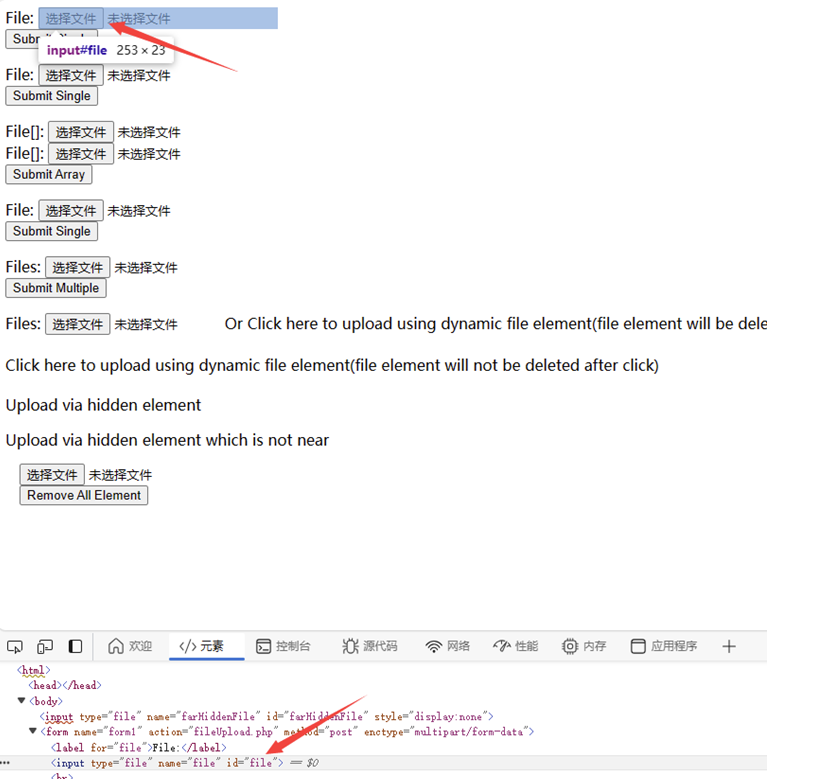
上传不能模拟用户在页面上选择本地文件,只能先把要上传的文件先准备好在代码里上传
import time
from selenium.webdriver.support.select import Select
#pip install selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
# 定义一个driver的变量,用来接收实例化后的浏览器
# 指定浏览器的位置,解决浏览器驱动和浏览器版本不匹配的问题
chrome_location = r'D:\pythonProject2023\SeleniumFirst\chrome-win64\chrome.exe'
options = webdriver.ChromeOptions()
options.binary_location = chrome_location
driver = webdriver.Chrome(options=options)
# 使用get方法,访问网址
driver.get("https://sahitest.com/demo/php/fileUpload.htm")
# 获取input文件上传元素
upload = driver.find_element(By.ID,'file')
upload.send_keys(r"D:\pythonProject2023\SeleniumFirst\file\1.jpg")
time.sleep(2)
driver.find_element(By.NAME,'submit').click()
time.sleep(3)
driver.quit()
复制
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
#指定下载路径
chromeOptions = webdriver.ChromeOptions()
prefs = {"download.default_directory":"D:\\pythonProject2023\\SeleniumFirst\\file"}
chromeOptions.add_experimental_option("prefs",prefs)
# 定义一个driver的变量,用来接收实例化后的浏览器
# 指定浏览器的位置,解决浏览器驱动和浏览器版本不匹配的问题
chrome_location = r'D:\pythonProject2023\SeleniumFirst\chrome-win64\chrome.exe'
options = webdriver.ChromeOptions()
options.binary_location = chrome_location
driver = webdriver.Chrome(options=options)
#窗口最大化
driver.maximize_window()
# 使用get方法,访问网址
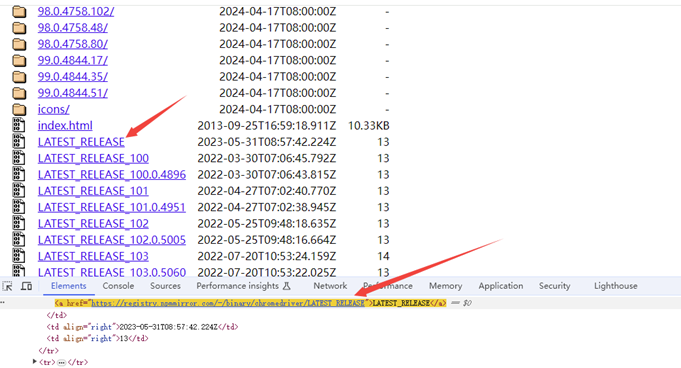
driver.get("https://registry.npmmirror.com/binary.html?path=chromedriver/")
time.sleep(3)
driver.find_element(By.XPATH,'/html/body/table/tbody/tr[156]/td[2]/a').click()
time.sleep(3)
driver.quit()
复制
下载如何判断下载完成了,这个在页面上不能直接判断有个可行的思路提供给大家,谷歌浏览器下载中的文件后缀是.crdownload,可以去下载的路径判断有没有后缀为.crdownload的文件来判断是否下载完成。
指定谷歌浏览器下载路径的代码如下:
# 指定浏览器的位置,解决浏览器驱动和浏览器版本不匹配的问题 chrome_location = r'D:\ProgramData\pythonProject\auto\chrome-win64\chrome.exe' options = webdriver.ChromeOptions()
#这里的作用如果是https的服务,跳过点击继续的那个步骤直接进入页面。 options.add_argument('--ignore-certificate-errors') #指定下载路径 prefs = {"download.default_directory":"D:\\bcpDown"} options.add_experimental_option("prefs",prefs) options.binary_location = chrome_location driver = webdriver.Chrome(options=options)复制
有的页面点击后会打开一个新的页面,切换页面的带入如下:
注:不切换分页后续所有的操作就都失败了,这是一个容易出问题的点
#分页了跳到另一个浏览器分页 driver.switch_to.window(driver.window_handles[1])复制