在云计算、SDN、NFV 高速发展并普遍落地的今天,随着上云业务的用户数量越来越多、数据中心的规模越来越大,云计算规模成本效应越来越重要。因此,云计算的集约式系统架构逻辑就决定了网络的性能是一个永恒的话题。在云网络的技术体系中,对性能追求不仅是方方面面的,而且是极致严苛的。性能每提升一点,成本就降低一分,收益就提高一些,产品的竞争力就更上一层楼。
大致上,我们可以将云网络的性能追求划分为物理网络的带宽性能、虚拟网络的隧道转发性能、四层网络的负载均衡性能、应用层网络的 I/O 处理性能等几个方面。尤其是当下,随着数据中心和边缘设备的网络带宽需求越来越高,作为用户业务服务网络入口的负载均衡器的性能表现至关重要。而这正是本系列文章研究的主题 —— Intel HDSLB 一种基于软硬件融合加速技术实现的高性能四层负载均衡器。
在该系列文章中为了能够把 HDSLB 介绍清楚,笔者希望能够从 “感性认识、理性认识、深入剖析” 这 3 个层级逐步展开,计划逐一分享下列文章,敬请期待。:)
在深入了解 HDSLB 之前,我们有必要先回顾一下传统 LB(负载均衡)的基础概念、类型、作用和原理。在一个现代化的 IT 系统中,LB 的作用是为了构建一个满足高可用、高并发、且具有高度可扩展性的后端服务器集群,本质是一种流量分发网络单元。
在长久以来的技术演进中,LB 技术始终关注以下几个方面的发展:
NOTE:CPS(Connections-per-second)是负载均衡器的关键性能指标,它描述了负载均衡器每秒钟稳定处理 TCP 连接建立的能力。
在以往,我们常见的 LB 方案有以下几种,包括:
诚然,这些 LB 方案现如今依旧在用户业务层 LB 场景中被大量的应用。但相对的,它们在云基础设施层 LB 场景中则正在面临着性能瓶颈、可扩展性差、云化适应性低等等问题。
随着先进的异构计算和软硬件融合加速等技术的蓬勃发展,现在越来越多的新型网络项目正在围绕着 DPDK、DPVS、VPP、SmartNIC/DPU 等高性能数据面技术展开,开发出更适应于云计算等大规模系统平台的新一代负载均衡产品,本系列文章讨论的 Intel HDSLB 正是其中之一。
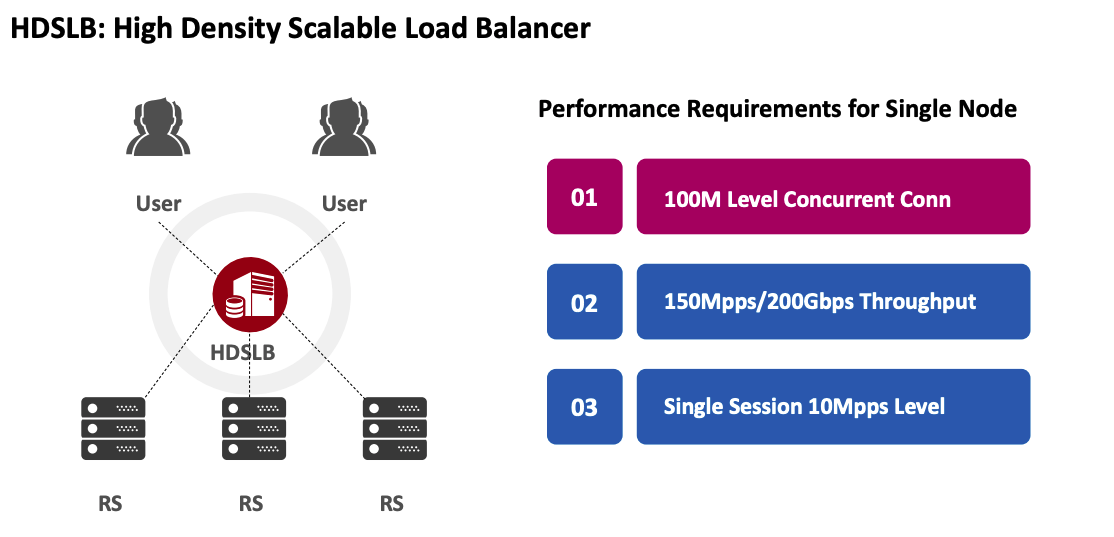
HDSLB(High Density Scalable Load Balancer,高密度可扩展的负载均衡器) 项目最初由 Intel 发起,旨在构建一个业界性能领先的四层(TCP/UDP)负载均衡器。其中:
值得注意的是,在一套完整的 LB 系统中,HDSLB 定位于四层负载均衡器,而七层负载均衡器(e.g. Nginx etc..)则作为 HDSLB 的一种特殊 RS,需要挂载到 HDSLB 的后端来提供更上一层的负载均衡能力。
目前,Intel HDSLB 已经补发了 v23.04 版,并且面向开发者提供了在 Github 上托管的开源 HDSLB-DPVS 版本,以及向商业合作伙伴开放的具有更多高级特性的 HDSLB-VPP 商业化版本。
作为新一代负载均衡器的典型,HDSLB 具有以下功能特性:
NOTE:在下文中,我们主要讨论 HDSLB-VPP 版本。
针对最重要的性能因素,我们可以从火山引擎 HDSLB 测试案例中找到了 Intel 官方认可的基准性能数据。
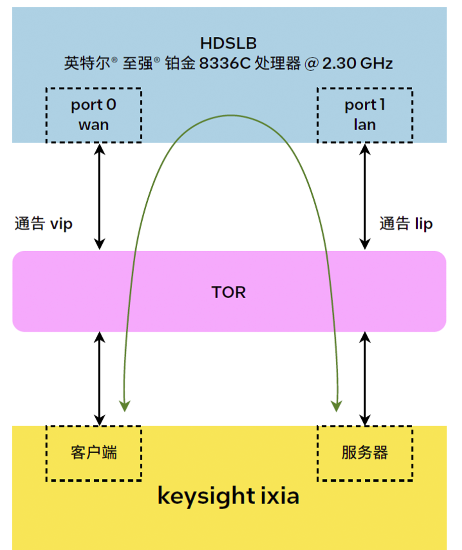
测试环境参数:

测试拓扑:
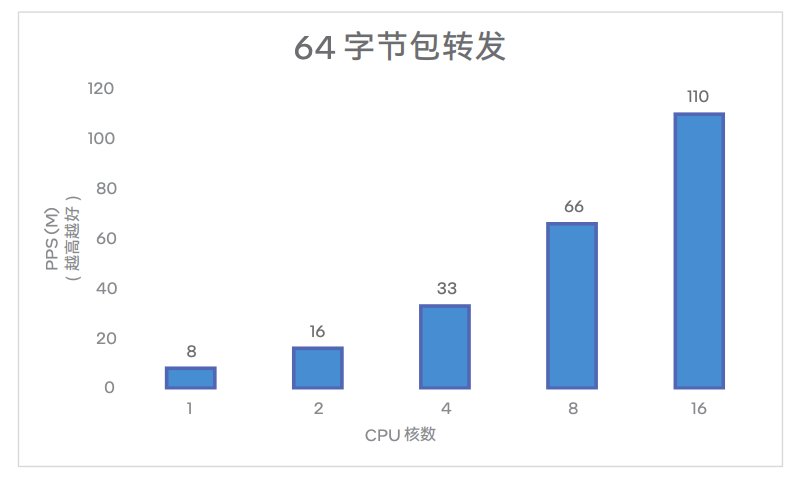
在 1~16 Core 场景中,64Bytes 转发吞吐量(单位 Mpps)测试结果如下图所示,结果越高越好。
在 1~4 Core 场景中,TCP CPS(单位 K)测试结果如下图所示,结果越高越好。

从上述结果可知,HDSLB-VPP 的单 Core 吞吐量性能达到了 8Mpps,且具有多核线性拓展特性。同时,HDSLB-VPP 的单核 TCP CPS 性能达到了 880K,且同样具有多核线性拓展特性。
而 HDSLB 在与某开源 L4 LB 方案最新公布的性能数据的横向对比中,我们也找到了官方的性能测试数据。
测试环境参数:
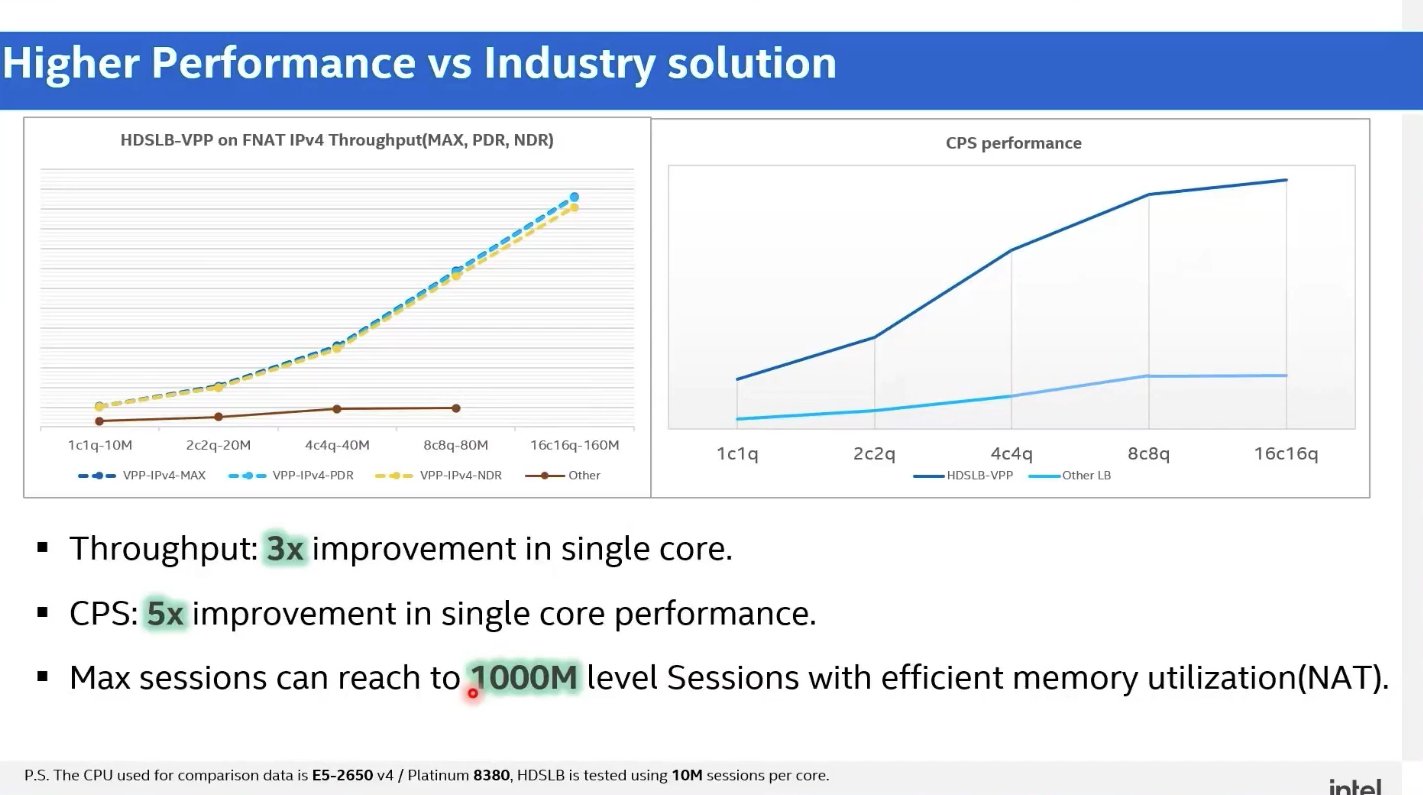
从下述第一张图可见,HDSLB-VPP 在 FNAT IPv4 吞吐量测试用例中,在每 Core 的并发 TCP 会话量增加了 10 倍的情况下,依旧能够取得了 3 倍以上的单 Core 吞吐量性能优势,且具有更好的多核线性扩展能力。
同时,在 FNAT 吞吐量场景中,从 MAX(尽力转发)、PDR(十万分之一丢包率)、NDR(零丢包率)这 3 种丢包模式的结果趋于一致上,也反应出了 HDSLB-VPP 具有优秀的转发稳定性。并且 NAT、DR、IPIP 等 LB 模式下的结果和 FNAT 模式趋势一致。
而第二张图则显示出,HDSLB-VPP 的 CPS(TCP 每秒新建连接数)性能相较而言有 5 倍的提升。
此外,HDSLB-VPP 基于 VPP 框架对数据结构内存进行了深度优化,使得在同等内存消耗的前提下,最大的并发 TCP 会话量突破预设的100M(1亿)级别,在 FNAT 模式下可扩大到 500M(5亿)级别,而在 NAT 模式下,甚至可以达到 1000M(10亿)级别。

HDSLB-VPP 对于内存方面做的优化以及并发 TCP 会话量的优势,使得 HDSLB-VPP 在 IPv6 的场景下会有更大的实用价值。在具备高性能优势的同时,还能够节省更多的系统资源用于其他业务的部署。
基于以上特性,HDSLB 目前的主要应用场景是在云计算和边缘计算中作为 L4 LB 网络单元。
针对资源集约式的云计算场景,需要面对以下 2 个关键的场景特点:
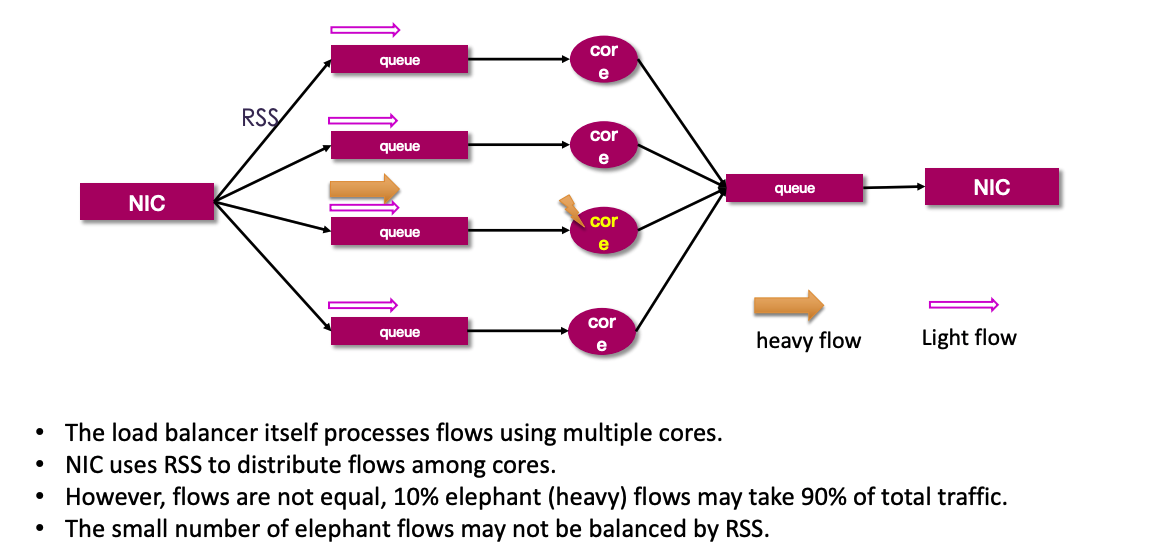
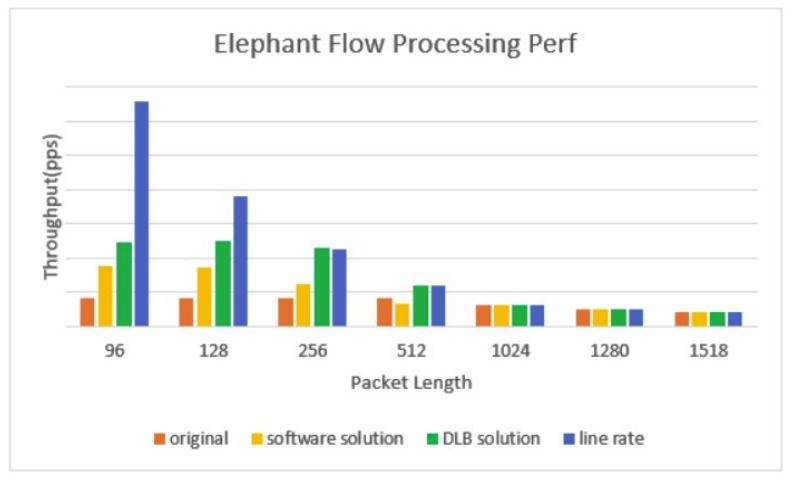
针对大象流的问题,HDSLB-VPP 基于 Intel DLB 硬件加速技术,可以在 96B、128B、256B、512B 包长的大象流场景中,相较于纯软方案具有更切近线速的提升。可以说,HDSLB 在 Intel CPU 指令集加速上的调教几乎可以说是做得最好的。
而针对面向垂直行业的、资源受限的边缘计算场景,则需要面对以下 2 个关键特点:
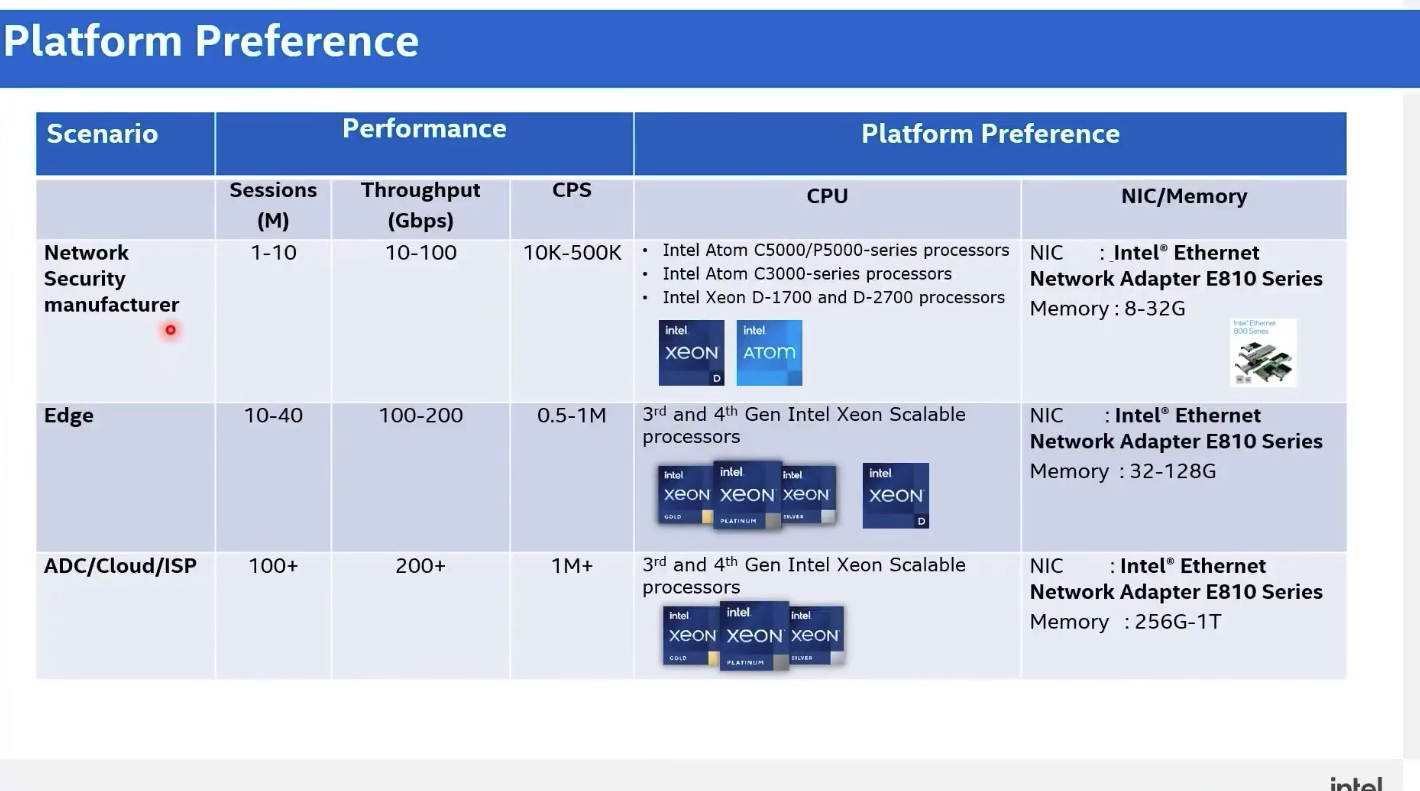
针对云计算、边缘计算、电信云、网络安全等多种不同应用场景下的性能调教组合,Intel 官方也提供了以下配置参考。
未来,HDSLB 的 Roadmap 中包括以下清单:
随着业务整体趋同的 “业务网关 NFV 化,边界网关硬件化” 的技术演进趋势,HDSLB 一方面背靠 Intel 的异构计算硬件生态,另一方面背靠 DPDK、VPP 等开源社区的创新能力。双管齐下,相信 HDSLB 有望在更多的应用场景中得到应用和推广。
其中我个人主要关注在 2 个方面,包括:
本篇主要介绍了 Intel HDSLB 的基本运行原理和部署配置的方式,希望能够帮助读者们顺利的把 HDSLB-DPVS 项目 “玩” 起来。