五一结束后,本qiang~又投入了LLM的技术海洋中,本期将给大家带来LLM微调神器:Unsloth。
正如Unsloth官方的对外宣贯:Easily finetune & train LLMs; Get faster with unsloth。微调训练LLM,可以显著提升速度,其次显存占用也会显著减少。
但有一点需要说明:unsloth目前开源部分只支持单机版微调,更高效微调只能交费使用unsloth pro。
(1) 所有的内核均以OpenAI的Triton语言实现,并且手动实现反向传播引擎。Triton语言是面向LLM训练加速。
(2) 准确率0损失,没有近似方法,方法完全一致。
(3) 硬件层面无需变动。支持18年之后的Nvidia GPU(V100, T4, Titan V, RTX20,30,40x, A100, H100, L40等,GTX1070,1080也支撑,但比较慢),Cuda最低兼容版本是7.0
(4) 通过WSL适用于Linux和Windows
(5) 基于bisandbytes包,支持4bit和16bit的 QLoRA/LoRA微调
(6) 开源代码有5倍的训练效率提升, Unsloth Pro可以提升至30倍
由于底层算子需要使用triton重写,因此部分开源模型的适配工作周期可能较长。当前unsloth支持的模型包含Qwen 1.5(7B, 14B, 32B, 72B), Llama3-8B, Mistral-7B, Gemma-7B, ORPO, DPO Zephyr, Phi-3(3.8B), TinyLlama
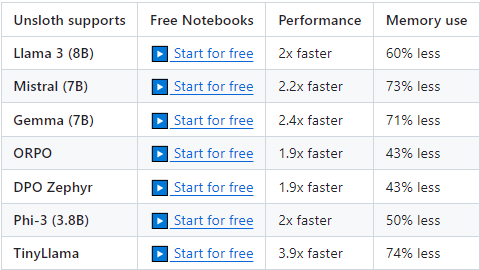
Qwen1.5-7B的集成是由Firefly作者封装并验证,性能提升30%+,显卡减少40%+,详见地址。
conda create --name unsloth_env python=3.10 conda activate unsloth_env conda install pytorch-cuda=<12.1/11.8> pytorch cudatoolkit xformers -c pytorch -c nvidia -c xformers pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git" pip install --no-deps trl peft accelerate bitsandbytes复制
本着眼过千遍不如手过一遍的宗旨,本qiang~针对Unsloth做了一个对比实现。对比的实验环境分别为:P40, A40, A800,对比的模型使用的是出锅热乎的Llama3(8B)。
|
维度 |
说明 |
|
显卡 |
是否支持bf16 |
|
最大文本长度 |
max_seq_length |
|
批次大小 |
per_device_train_batch_size |
|
梯度累加步长 |
gradient_accumulation_steps |
|
秩 |
LoRA的rank |
|
dropout |
lora_droput |
针对使用unsloth和非unsloth得显卡及训练加速的对比代码,可以参考地址:https://zhuanlan.zhihu.com/p/697557062

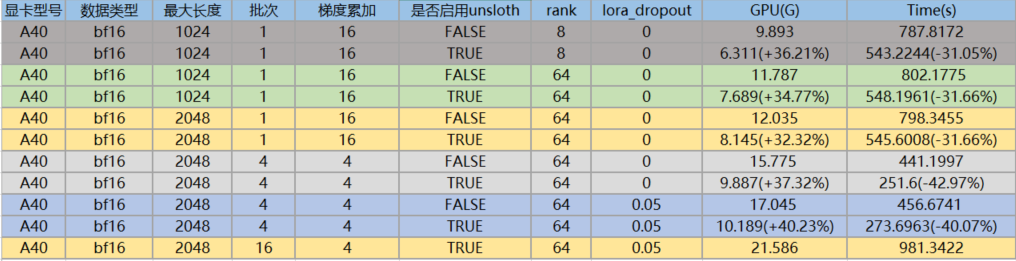
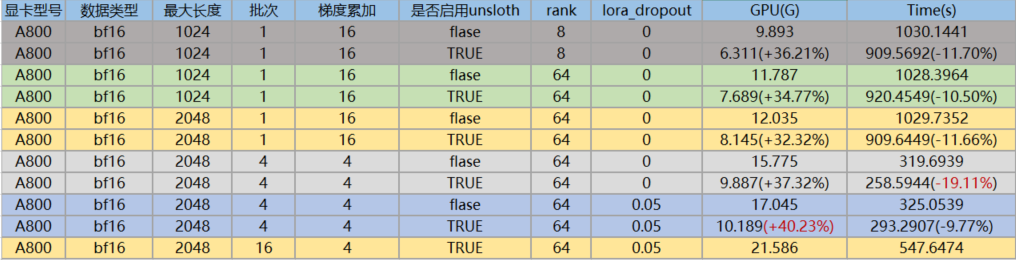
针对于llama3-8B进行unsloth训练,与基于transformers框架训练进行比对,结论如下:
(1) 集成unsloth后,显卡占用确实更少,训练效率确实更快,不管是哪种维度。
(2) P40增加batch_size后,显卡的内存占用提升,但训练的时间也更长,说明P40针对大批次的数据处理,性能会降低; 但A40, A800增加batch_size后,显卡内存占用虽然提升,但训练的时间更短。
(3) A800的batch_size为1时,训练效率不如A40,当batch_size增加到16时,A800的训练效率比A40快接近一倍。因此,A800更适合处理大批次的场景,对于小batch_size,杀鸡不能用牛刀。
一句话足矣~
本文主要是使用unsloth框架针对llama3的高效微调实验,提供了详细的对比代码以及不同维度的对比分析结果。
之后会写一篇关于Qwen1.5的对比实验,敬请期待~
1. unsloth: https://github.com/unslothai/unsloth
2. Qwen1.5+Unsloth: https://github.com/unslothai/unsloth/pull/428

本文主要是通过Scrapegraph-ai集成gpt3.5实现一个简单的网页爬取并解析的demo应用,其中涉及到gpt3.5免费申请,Scrapegraph-ai底层原理简介,demo应用源码等。
本文主要是针对KBQA方案基于LLM实现存在的问题进行优化,主要涉及到响应时间提升优化以及多轮对话效果优化,提供了具体的优化方案以及相应的prompt。
本文主要是针对KBQA方案基于LLM实现存在的问题进行优化,主要涉及到图谱存储至Es,且支持Es的向量检索,还有解决了一部分基于属性值倒查实体的场景,且效果相对提升。