本文分析的问题:
synchronized 字节码文件分析之 monitorenter、monitorexit 指令
为什么任何一个Java对象都可以成为一把锁?
对象的内存结构
锁升级过程
Monitor 是什么、源码查看
作用于实例方法,对对象加锁
作用于静态方法,对类加锁
作用于代码块,对 () 里的对象加锁
先说结论:通过 monitorenter、monitorexit 指令来做
synchronized 关键字底层原理属于 JVM 层面的东西。
monitorenter、monitorexit 指令来做
代码:
public void m1(){
synchronized (this){
}
}
复制编译后使用 javap -v xxx.class 命令查看:

一般情况下就是 1 个 monitorenter 对应 2 个 monitorexit
极端情况下:如果方法里抛出异常了,就只会有一个 monitorexit 指令
包含一个 monitorenter 指令以及两个 monitorexit 指令,这是为了保证锁在同步代码块正常执行以及出现异常
的这两种情况下都能被正确释放
异常情况下:只有一个 monitorexit 指令
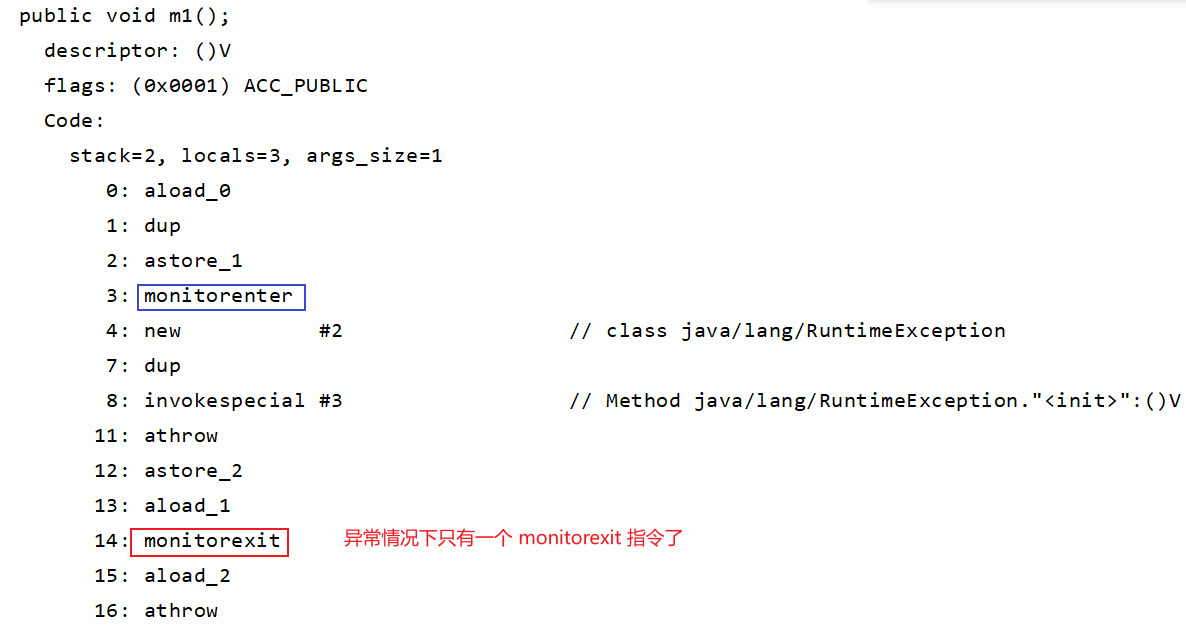
ACC_SYNCHRONIZED 这个标识来做
代码:
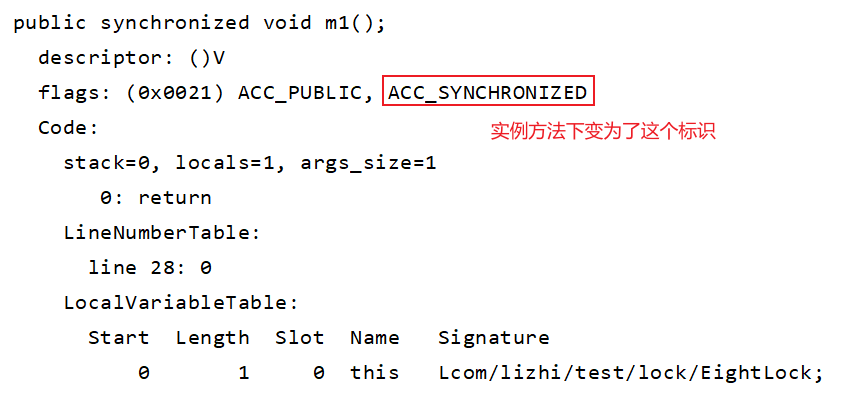
public synchronized void m1(){
}
复制结果:在方法下没有那两个指令,取而代之的是 ACC_SYNCHRONIZED 这个标识。该标识指明了该方法是一个同步方法
JVM通过该 ACC_SYNCHRONIZED 标识来辨别一个方法是否是一个同步方法,从而执行相应的同步调用
ACC_SYNCHRONIZED这个标识来做
代码:
public static synchronized void m1(){
}
复制结果:可以看到还是通过 ACC_SYNCHRONIZED 这个标识来做。
ACC_STATIC 这个标识是用来区分实例方法和静态方法的,就算不加 synchronized 也会有。

为了可以更加直观的看到对象结构,我们可以借助 openjdk 提供的 JOL 工具进行分析。
JOL(Java 对象布局)用于分析对象在JVM的大小和分布
官网:https://openjdk.org/projects/code-tools/jol/
<!--
https://mvnrepository.com/artifact/org.openjdk.jol/jol-cli
定位:分析对象在JVM的大小和分布
-->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-cli</artifactId>
<version>0.14</version>
</dependency>
复制可以看到总共分为三部分:对象头、实例数据、对齐填充

在64位系统中,Mark Word 占了 8 个字节,类型指针占了 8 个字节,一共是 16 个字节
MarkWord 中存了一些信息:hashCode的值、gc相关、锁相关
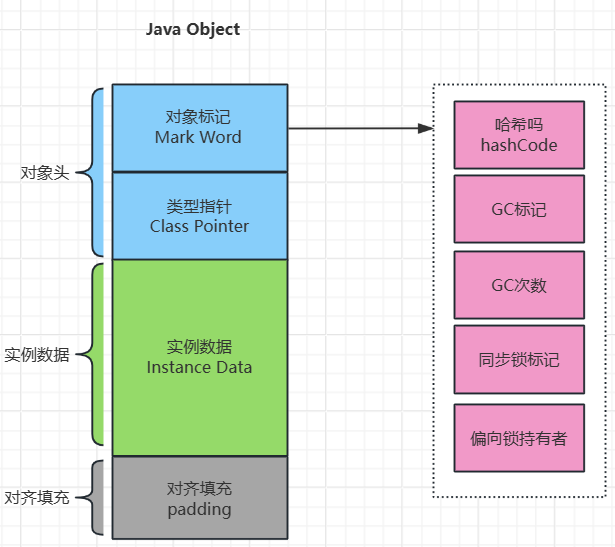

unused:未使用的位置
hashcode:hashcode 的值
age:GC年龄(4位最大只能表示15)
biased_lock:是否是偏向锁(0不是;1是)
thread:线程id
epoch:偏向时间戳
ptr_to_lock_record:存储指向栈帧中的锁记录(LockRecord)的指针
ptr_to_heavyweight_monitor:指向重量级锁的指针(也就是指向 ObjectMonitor 的指针)
锁标志位:01 代表有锁;00 代表偏向锁;10 代表轻量级锁;11 代表重量级锁
markOop.hpp 中的 C++ 源码查看:
// 32 bits: 32位的
// --------
// hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)
// size:32 ------------------------------------------>| (CMS free block)
// PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)
//
// 64 bits: 64位的
// --------
// unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
// PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
// size:64 ----------------------------------------------------->| (CMS free block)
//
// unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object)
// JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object)
// narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object)
// unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)
复制源码地址:https://hg.openjdk.org/jdk8/jdk8/hotspot/file/87ee5ee27509/src/share/vm/runtime/objectMonitor.hpp

对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象哪个类的实例
我们怎么知道创建的这个对象是什么类型的,就通过这个指针指向方法区的类元信息(kclass pointer)。
可能会进行指针压缩。
存放类的属性(Field)数据信息,包括父类的属性信息
虚拟机要求对象起始地址必须是 8 字节的整数倍,所以填充数据不是必须存在的,仅仅是为了字节对齐,这部分内存按 8 字节补充对齐
比如:
class Person {
int age;
boolean isFlag;
}
复制简单使用:
public static void main(String[] args) {
// 获取JVM详细信息
System.out.println(VM.current().details());
// 对象头大小 开启指针压缩是12=MarkWord(8)+ClassPointer(4),没开启是16=MarkWord(8)+ClassPointer(8)
System.out.println(VM.current().objectHeaderSize());
// 对齐填充 为什么都是8的倍数?
System.out.println(VM.current().objectAlignment());
}
复制代码:
public static void main(String[] args) {
Object obj = new Object();
System.out.println(obj + " 十六进制哈希:" + Integer.toHexString(obj.hashCode()));
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
}
复制结果:

不是说类型指针是8字节吗,到这里怎么变为4字节了?
那是因为被 指针压缩 了(开启后性能会更好)
命令查看: java -XX:+PrintCommandLineFlags -version

这个参数就是压缩指针的参数:-XX:+UseCompressedClassPointers +代表开启,- 代表关闭
关闭后,运行后,再次查看:-XX:-UseCompressedClassPointers

这次就没有对齐填充了。
无锁 ---> 偏向锁 ---> 轻量级锁 -> 重量级锁
之前 synchronized 是重量级锁,依靠 Monitor 机制实现。
Monitor 是依赖于底层的操作系统的 Mutex Lock(互斥锁)来实现的线程同步。这种机制需要用户态和内核态之
间来切换。但Mutex是系统方法,由于权限的关系,应用程序调用系统方法时需要切换到内核态来执行。
所以为了是减少用户态和内核态之间的切换。因为这两种状态之间的切换的开销比较高。
先来一个 狗 的类,用来创建对象
class Dog {
}
复制创建一个对象,没有一个线程来占有它,这时就是无锁
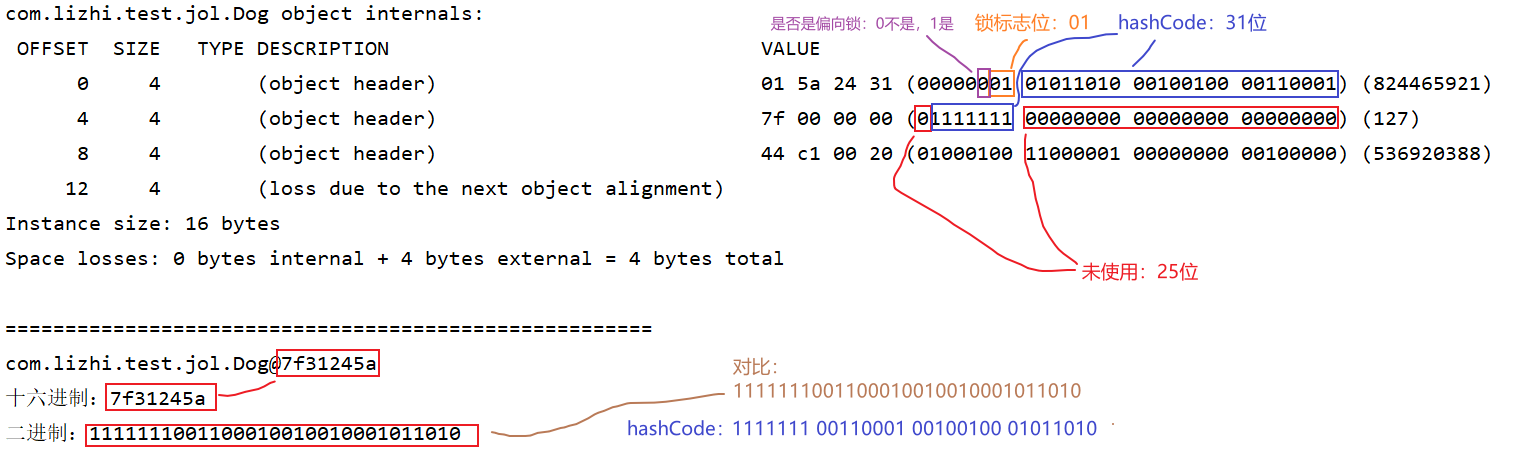
无锁时 Mark Word 的结构:
| unused:25 | hashcode:31 | unused:1 | age:4 | biased_lock:0 | 01 | Normal |复制
测试代码:
public static void main(String[] args) {
Dog dog = new Dog();
dog.hashCode();
System.out.println(ClassLayout.parseInstance(dog).toPrintable());
System.out.println("======================================================");
System.out.println(dog);
System.out.println("十六进制:" + Integer.toHexString(dog.hashCode()));
System.out.println("二进制:" + Integer.toBinaryString(dog.hashCode()));
}
复制对照上面的结构来看:从后往前按照 Mark Word 结构来看。每8bit从前往后看。
当第一个线程来获取到它时(没有竞争/一次就竞争成功),这时它就是偏向锁,只偏向于这一个线程(CAS)
偏向锁、轻量级锁的 Mark Word 的结构:
|--------------------------------------------------------------------|--------------------|
| thread:54 | epoch:2 | unused:1 | age:4 | biased_lock:1 | 01 | Biased |
|--------------------------------------------------------------------|--------------------|
| ptr_to_lock_record:62 | 00 | Lightweight Locked |
|--------------------------------------------------------------------|--------------------|
复制测试代码:
public static void main(String[] args) {
Dog dog = new Dog();
synchronized (dog){
System.out.println(ClassLayout.parseInstance(dog).toPrintable());
}
}
复制结果:

因为偏向锁默认是延迟开启的,所以进入了轻量级锁状态。
使用 java -XX:+PrintFlagsInitial | grep BiasedLock 命令在 Git Bash 下执行:

所以需要添加参数 -XX:BiasedLockingStartupDelay=0,让其在程序启动时立刻启动。或者让程序睡了 5 秒后再执行。
添加参数/睡5秒后执行,发现偏向锁出现了:

1 代表是偏向锁,01 代表有锁
其实就是自旋锁(底层是CAS)
其它线程来竞争锁,并且竞争失败,会到一个全局安全点来把这个锁升级为轻量级锁
轻量级锁的 Mark Word 结构:
| ptr_to_lock_record:62 | 00 | Lightweight Locked |复制
测试代码:通过调用 hashCode() 来得到轻量级锁(因为偏向锁里没有地方存储 hashCode 的值)
public static void main(String[] args) throws InterruptedException {
Dog dog = new Dog();
dog.hashCode();
synchronized (dog) {
System.out.println(ClassLayout.parseInstance(dog).toPrintable());
}
}
复制结果:

JDK6之前
JDK6之后 自适应自旋锁
线程如果自旋成功了,那下次自旋的最大次数会增加,因为JVM认为既然上次成功了,那么这一次也很大概率会成功。
反之,如果很少会自旋成功,那么下次会减少自旋的次数其至不自旋,避免CPU空转。
自适应意味着自旋的次数不是固定不变的,而是根据:同一个锁上一次自旋的时间。拥有锁线程的状态来决定。
自旋到一定次数后,还没获取到锁,会将其升级为重量级锁。那就是阻塞了,用户态和内核态之间的切换
基于 Monitor 的实现,monitorenter 和 monitorexit 指令来实现
重量级锁的 Mark Word 的结构:
| ptr_to_heavyweight_monitor:62 | 10 | Heavyweight Locked |复制
测试代码:
结果:

无锁:就存在 Mark Word 里
偏向锁:没有地方存 hash 值了
如果在 synchronized 前调用了 hashCOde() ,此时偏向锁会升级为轻量级锁
如果在 synchronized 中调用了 hashCode() ,此时偏向锁会升级为重量级锁
轻量级锁:栈帧中的锁记录(Lock Record)里
重量级锁:Mark Word 保存重量级锁的指针,底层实现 ObjectMonitor 类里有字段记录加锁状态的 Mark Word 信息
在 HotSpot 虚拟机中,monitor 是由 C++ 中的 ObjectMonitor 实现。
Monitor 是管程,是同步监视器,是一种同步机制。为了保证数据的安全性
提供了一种互斥机制。限制同一时刻只能有一个线程进入 Monitor 的临界区,保护数据安全。
用于保护共享数据,避免多线程并发访问导致数据不一致。
synchronized 的重量级锁就是用 Monitor 来实现的
每个 Java 对象都自带了一个 monitor 对象,所以每个 Java 对象都可以成为锁。
源码:Java 中的每个对象都继承自 Object 类,而每个 Java 对象在 JVM 内部都有一个 C++ 对象 oopDesc 与其对应,而对应的 oopDesc 内有一个属性是 markOopDesc 对象(这个对象就是 Java 里的 Mark Word),这个 markOopDesc 内有一个 monitor() 方法返回了 ObjectMonitor 对象(hotspot中,这个对象实现了 monitor )
翻译过来就是:Java 中的每个对象都继承自 Object 类,oopDesc 是每个 Java 对象的顶层父类,这个父类内有个属性是 markOopDesc 对象,也就是对象头。这个对象头是存储锁的地方,里面有一个 ObjectMonitor。
每一个被锁住的对象又都会和 Monitor 关联起来,通过对象头里的指针。
这个类是每个 Java 对象的基类。每个 Java 对象在虚拟机内部都会继承这个 C++ 对象。
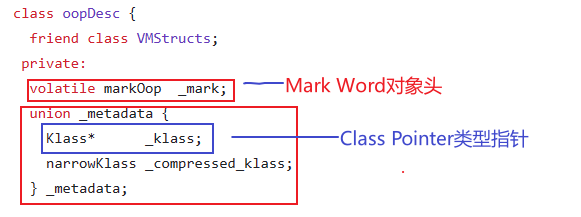
源码地址:https://hg.openjdk.org/jdk8/jdk8/hotspot/file/87ee5ee27509/src/share/vm/oops/oop.hpp
这个类也是 oopDesc 的子类。这个类就是 Mark Word 对象头。
里面有一个 monitor() 方法返回了 ObjectMonitor 对象。
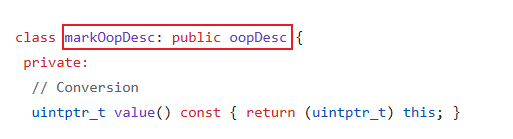
monitor():

源码地址:https://hg.openjdk.org/jdk8/jdk8/hotspot/file/87ee5ee27509/src/share/vm/oops/markOop.hpp
在 hotspot 虚拟机中,ObjectMonitor 是 Monitor 的实现。

源码地址:https://hg.openjdk.org/jdk8/jdk8/hotspot/file/87ee5ee27509/src/share/vm/runtime/objectMonitor.hpp
Java 中的每个对象都继承自 Object 类,虚拟机源码中 oopDesc 是每个 Java 对象的顶层父类,这个父类内有个属性是 markOopDesc 对象,也就是对象头。这个对象头是存储锁的地方,里面有一个 ObjectMonitor 。而 monitor 的实现就是 ObjectMonitor 对象监视器。
大部分参考:
Mark Word 代码块里的结构参考视频的笔记(图为自画):
少部分参考:
oopDesc、markOopDesc 和 Java 对象之间的关系参考:
openjdk 源码位置参考:里面也有 ObjectMonitor 原理