写在前面: 其实之前一直想汇总一篇关于自己对于面向对象的思考以及实践的文章,但是苦于自己的“墨迹”,一延再延,最近机缘巧合下仔细了解了一下COLA的内容,这个想法再次被勾起,所以这次一鼓作气,准备好好梳理一篇。至于标题,因为是被DDD和COLA唤起的,索性就叫这个吧。
领域驱动设计本质上是讲的面向对象,但是谈面向对象,始终无法绕开面向过程,所以我们先好好说一下面向过程和面向对象这两个概念。
什么是面向过程呢,其实就是我们学习编程时最初被植入的逻辑,这也是很多人即便学了面向对象后,写的代码却四不像的原因,因为这个思维是根深蒂固的。我想大多数院校科班生,第一次接触编程都是C语言,从一个hello word开始,然后便是if else、for循环,其实if else 思维便是面向过程的基本逻辑,就是做事的 “步骤”,比如经典的图书管理系统的课设,基于面向过程去设计编码,想的是新增图书、修改图书名字、描述;是根据输入的参数,进行if else的选择,然后进入对应的流程,在流程里去先做什么,再做什么,关注点在图书的操作上, 是专注于事情本身,专注于做事的流程;所以面向过程更适合去做一些底层的,基于硬逻辑的内容。当需要做的东西规模过大且频繁变化时,代码量和改动成本也会增加。
面向对象相对于面向过程,它更偏向于概念的抽象和建设模型。同样图书管理系统,面向对象考虑的重点则变成了图书(而不是操作图书数据这件事),一条条的图书数据,在内存里就是一个个的个体对象,至于图书的各种操作那是细节的内容,它不会去关心,只要定义了图书这个对象,那对于图书的操作那都在对象自身的事情,面向对象专注于事情的主体,是以主体以及它们之间的行为组合去构建程序。当然对象自身内部的行为又是一个个的面向过程组成,这就是在编码的时候最容易让人模糊和把握不准的地方。面向对象把程序设计又拔高了一层,把细节忽略,站在更高维度去构建程序。
通过一个简单的例子来对比一下这两种思想:数据库中存在所有学生的数据,比如姓名、学校、专业,下面需要实现一个自我介绍的功能,描述方式为:我是XX,毕业于XXX学校,用面向过程的思维实现是这样的:
public class test{ public static void main(String[] args){ desc("张三"); } public static void desc(String name){ //查询数据库 connection = DbManager.createConnection(root,XXX,3306); //查询数据 Map<String,Object> a = connection.query("SELECT name,school FROM tb_student WHERE name = #{name}",name); System.out.print("我是"+a.get('name')+",毕业于"+a.get("school"); } }复制
拿到需求,我们关注的自我介绍这件事,只要完成这件事就好了,所以直接定义一个过程(方法、函数)然后过程里去根据需求把这件事完成;
而使用面向对象的话,面对需求,首先需要确定主体,也就是学生对象,然后学生对象有姓名、学校、专业这些属性和一个自我描述的能力。
public class Student{ private String name; private String school; private String discipline public Student(Map map){//省略构造函数内容} public void introduce(){ System.out.print("我是"+this.name+",毕业于"+this.school); } }复制
然后定义另一个对象,数据库对象,数据库对象有一个可以查询学生对象的能力
public class Db{ private String url; private String username; //其他属性…… public Student searchStudent(String name){ Map a = connection.query("SELECT name,school FROM tb_student WHERE name = #{name}",name); return new Student(a); } }复制
最后通过使用两个对象,来完成这件事
public class test{ public static void main(String[] args){ Student object = Db.searchStudent("张三") object.introduce(); } }复制
通过上面的代码,可以发现,面向对象的实现似乎需要更多的代码来完成这件事,没错,这是事实,虽然在设计上我们忽略细节,可是编码上是无法忽略的,甚至使用面向对象成本更高,但是注意我这里说的是针对咱们这个场景需求,当前场景如果戛然而止,确实面向过程方式更精简,但是如果需求继续增加,随着业务增加、需求变大、边界变宽,面向过程可能就需要追加更多的过程代码去完成,而面向对象可能需要的是调整对象的组合方式或者对象本身的扩展去完成,所以,面向对象在代码层面最大的优势就是 复用和扩展
说完面向过程和面向对象,再说一下关于面向对象的集成方法论—领域驱动,它的本质是统一语言、边界划分和面向对象分析的方法。简单点来讲就是将OOA、OOD和OOP融汇贯通到系统开发中,充分发挥面向对象的优势和特点,去降低系统开发过程中的熵增。狭义一点解释就是如何用 java 在业务开发中写出“真正面向对象”的系统代码。
在概念上,领域驱动又分为贫血模式和充血模式。
贫血模式很多人不陌生, 也是大多数Java开发使用的MVC架构,实体类仅有get和set方法,在整个系统中,领域对象几乎只作传输介质的作用,不会影响到层次的划分,业务逻辑多集中在Service中,也就是绝大多数使用Spring框架进行开发的Web项目的标准形态,即Controller、Service、Dao、POJO;
这里看一个例子:
/** * 账户业务对象 */ public class AccountBO { /** * 账户ID */ private String accountId; /** * 账户余额 */ private Long balance; /** * 是否冻结 */ private boolean isFrozen; public String getAccountId() { return accountId; } public void setAccountId(String accountId) { this.accountId = accountId; } public Long getBalance() { return balance; } public void setBalance(Long balance) { this.balance = balance; } public boolean isFrozen() { return isFrozen; } public void setFrozen(boolean isFrozen) { this.isFrozen = isFrozen; } } /** * 转账业务服务实现 */ @Service public class TransferServiceImpl implements TransferService { @Autowired private AccountMapper accountMapper; @Override public boolean transfer(String fromAccountId, String toAccountId, Long amount) { AccountBO fromAccount = accountMapper.getAccountById(fromAccountId); AccountBO toAccount = accountMapper.getAccountById(toAccountId); /** 检查转出账户 **/ if (fromAccount.isFrozen()) { throw new MyBizException(ErrorCodeBiz.ACCOUNT_FROZEN); } if (fromAccount.getBalance() < amount) { throw new MyBizException(ErrorCodeBiz.INSUFFICIENT_BALANCE); } fromAccount.setBalance(fromAccount.getBalance() - amount); /** 检查转入账户 **/ if (toAccount.isFrozen()) { throw new MyBizException(ErrorCodeBiz.ACCOUNT_FROZEN); } toAccount.setBalance(toAccount.getBalance() + amount); /** 更新数据库 **/ accountMapper.updateAccount(fromAccount); accountMapper.updateAccount(toAccount); return Boolean.TRUE; } }复制
贫血模型的问题和难点在于,在面对较为庞大体量的业务系统时,业务逻辑层的膨胀导致代码的混乱。因为贫血的特性(POJO仅仅是数据),导致业务代码本身就不“面向对象”化,随着业务的积累和缝缝补补,Service层更像是面向过程,堆满了if else ,会不断膨胀和混乱,边界不易控制,内部的各模块、包之间的依赖会变得不易管理。
充血模式更符合领域设计,简单来讲就是OOA和OOP的最佳实践,将业务逻辑和持久化等内容均内聚到实体类中,Service层仅仅充当组合实体对象的画布,负责简单封装部分业务和事务权限管理等;
如果使用充血模式完成上面的例子则是这样:
/** * 账户业务对象 */ public class AccountBO { /** * 账户ID */ private String accountId; /** * 账户余额 */ private Long balance; /** * 是否冻结 */ private boolean isFrozen; /** * 出借策略 */ private DebitPolicy debitPolicy; /** * 入账策略 */ private CreditPolicy creditPolicy; /** * 出借方法 * * @param amount 金额 */ public void debit(Long amount) { debitPolicy.preDebit(this, amount); this.balance -= amount; debitPolicy.afterDebit(this, amount); } /** * 转入方法 * * @param amount 金额 */ public void credit(Long amount) { creditPolicy.preCredit(this, amount); this.balance += amount; creditPolicy.afterCredit(this, amount); } public boolean isFrozen() { return isFrozen; } public void setFrozen(boolean isFrozen) { this.isFrozen = isFrozen; } public String getAccountId() { return accountId; } public void setAccountId(String accountId) { this.accountId = accountId; } public Long getBalance() { return balance; } /** * BO和DO转换必须加set方法这是一种权衡 */ public void setBalance(Long balance) { this.balance = balance; } public DebitPolicy getDebitPolicy() { return debitPolicy; } public void setDebitPolicy(DebitPolicy debitPolicy) { this.debitPolicy = debitPolicy; } public CreditPolicy getCreditPolicy() { return creditPolicy; } public void setCreditPolicy(CreditPolicy creditPolicy) { this.creditPolicy = creditPolicy; } } /** * 入账策略实现 */ @Service public class CreditPolicyImpl implements CreditPolicy { @Override public void preCredit(AccountBO account, Long amount) { if (account.isFrozen()) { throw new MyBizException(ErrorCodeBiz.ACCOUNT_FROZEN); } } @Override public void afterCredit(AccountBO account, Long amount) { System.out.println("afterCredit"); } } /** * 出借策略实现 */ @Service public class DebitPolicyImpl implements DebitPolicy { @Override public void preDebit(AccountBO account, Long amount) { if (account.isFrozen()) { throw new MyBizException(ErrorCodeBiz.ACCOUNT_FROZEN); } if (account.getBalance() < amount) { throw new MyBizException(ErrorCodeBiz.INSUFFICIENT_BALANCE); } } @Override public void afterDebit(AccountBO account, Long amount) { System.out.println("afterDebit"); } } /** * 转账业务服务实现 */ @Service public class TransferServiceImpl implements TransferService { @Resource private AccountMapper accountMapper; @Resource private CreditPolicy creditPolicy; @Resource private DebitPolicy debitPolicy; @Override public boolean transfer(String fromAccountId, String toAccountId, Long amount) { AccountBO fromAccount = accountMapper.getAccountById(fromAccountId); AccountBO toAccount = accountMapper.getAccountById(toAccountId); //此处采用轻量化地方式解决了自身面向对象和Spring的bean管理权矛盾 fromAccount.setDebitPolicy(debitPolicy); toAccount.setCreditPolicy(creditPolicy); fromAccount.debit(amount); toAccount.credit(amount); accountMapper.updateAccount(fromAccount); accountMapper.updateAccount(toAccount); return Boolean.TRUE; } }复制
充血模型的问题和难点在于:
Spring框架本身的限制
业务复杂程度是否匹配
如何把握domain层的边界以及各层间的关系
先说Spring框架本身的限制问题,使用Spring其实默认了使用贫血模型,这是由Spring本身框架特点决定的,首先Spring家族作为Java系的行业老大哥框架,积累和沉淀非常丰富,各方面已经封装的很全面,所以留出的“自由度”就比较少,它的宗旨就是让开发人员减少重复造轮子,仅仅专注功能的开发就好,所以Spring官方的demo以及一些使用导向都是贫血模式;例如Spring的根基Bean管理机制,把对象的管控牢牢把握在框架中,这种将实体类的管理也交由Spring本身也降低了二次开发时面向对象的属性,导致在Spring中进行bean之间的引用改造会面临大范围的bean嵌套构造器的调用问题。
其次是业务的复杂程度是否适配,绝大多数的项目,说难听点,都是面向数据的概念意淫、CRUD的“建筑行业工地式”项目而已,使用Spring+贫血的经典模式足够满足,而且贫血模式在开发成本上更适合面向数据开发(需求变更的驱动成因、团队的管理方式、研发团队的素质),如果过分追求面向对象反而有些舍近求远,所以能否根据业务场景决定是否使用充血的领域驱动是挺难的(毕竟很多优秀的面向对象研发是很难舍弃面向对象的诱惑)
最后就是最难的,如何划分业务逻辑到domain层,即什么样的逻辑应该放在Domain Object中,什么样的业务逻辑应该放在Service中,这是很含糊的,如果没有面向领域开发流程以 OO思想的充分沉淀积累,很难做到;即使划分好了业务逻辑,由于分散在Service和DomainObject层中,不能更好的分模块开发。熟悉业务逻辑的开发人员需要渗透到Domain中去,而在Domian层又包含了持久化,对于开发者(习惯于贫血模型的团队)来说这十分混乱。
COLA 是 Clean Object-Oriented and Layered Architecture的缩写,代表“整洁面向对象分层架构”。由阿里大佬张建飞所提出的一种基于DDD和代码整洁理论所诞生的实践理论框架,详细内容可阅读《程序员的底层思维》和相关git代码去了解
项目地址:GitHub - alibaba/COLA: 🥤 COLA: Clean Object-oriented & Layered Architecture
下面简单把COLA框架的主要架构梳理一下,这里的框架图采用COLA4.0版本(当前作者认为的最优形态)
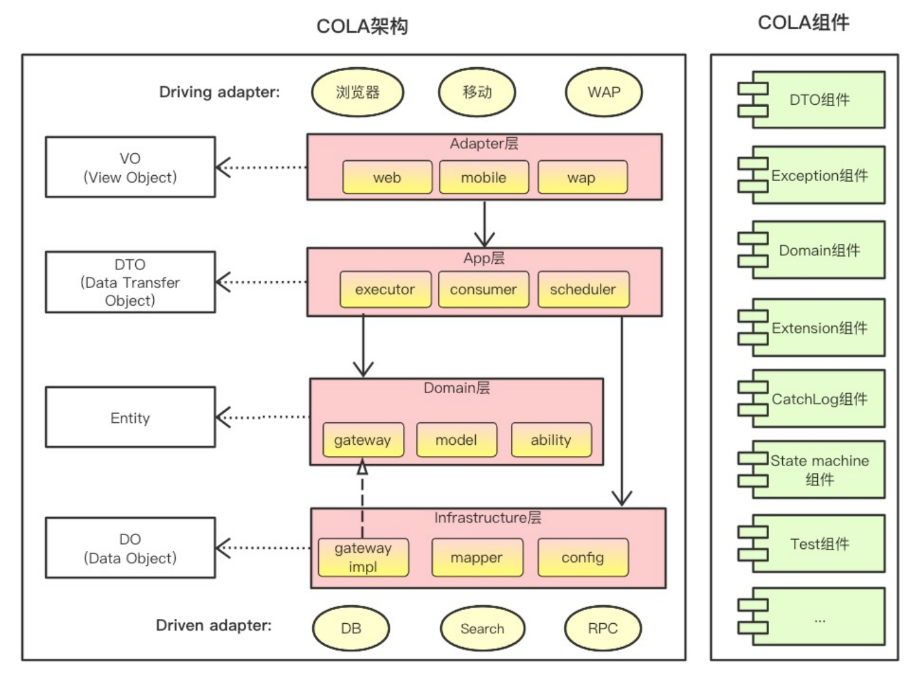
COLA整体上由两部分组成,代码架构和通用组件,两者并非强绑定,代码架构是一套基于maven的代码模板,通用组件则是可选项,可以理解为Common组件包。
Adapter层(适配层)
负责对前端展示(Web、Wireless、WAP)的路由和适配。对于传统B/S系统而言,Adapter层就相当于MVC中的Controller。
主要负责获取输入、组装上下文、参数校验、调用领域层做业务处理,以及发送消息通知(如有需要)等。层次是开放的,应用层也可以绕过领域层,直接访问基础设施层。
用于封装核心业务逻辑,并利用领域服务(Domain Service)和领域对象(Domain Entity)的方法对App层提供业务实体和业务逻辑计算。领域层是应用的核心,不依赖任何其他层次。
主要负责技术细节问题的处理,比如数据库的CRUD、搜索引擎、文件系统、分布式服务的RPC等。此外,Infrastructure层还肩负着领域防腐的重任,外部依赖需要通过Gateway的转义处理,才能被App层和Domain层使用。
非业务相关的功能组件包
使用OO理论及COLA,首先就是要明确各类对象的概念,统一认知并且严格执行。
DO(Data Object):数据对象
DO应该跟其名字一样,仅作为数据库中表的1:1映射,不参与到业务逻辑操作中,仅仅负责Infrastructure层的数据持久化以及读取的实体对象
Entity:实体对象
对应业务模型中的业务对象,字段及方法应该与业务语言抱持一致,原则上Entity和Do应该是包含嵌套的关系,且Entity的生命周期仅存在在系统的内存中,不需要序列化以及持久化,业务流程结束,Entity也应该跟随消亡
DTO(Data Transfer Object): 数据传输对象
主要作为和系统外部交互的对象,DTO主要是数据传输的载体,期间可以承载一部分领域能力(业务相关的判定职责等);
VO(view Object):展示层对象
性质和DTO相差不多,也是数据传输载体,主要是作为对外交付数据的载体,承载部分数据隐藏、数据保护、数据结构化展示的作用。
其中,Do存在于Infra层,Entity主要在Domain层中,而DTO和VO则被COLA归类到了组件包中。
使用作者推荐的maven Archetypes模板后,能发现COLA整体采用maven module的结构来构建代码,划分原则是结合技术维度和领域维度综合划分:

相应的分层则对应到不同的module中(技术维度划分),由此形成了这样的依赖关系:
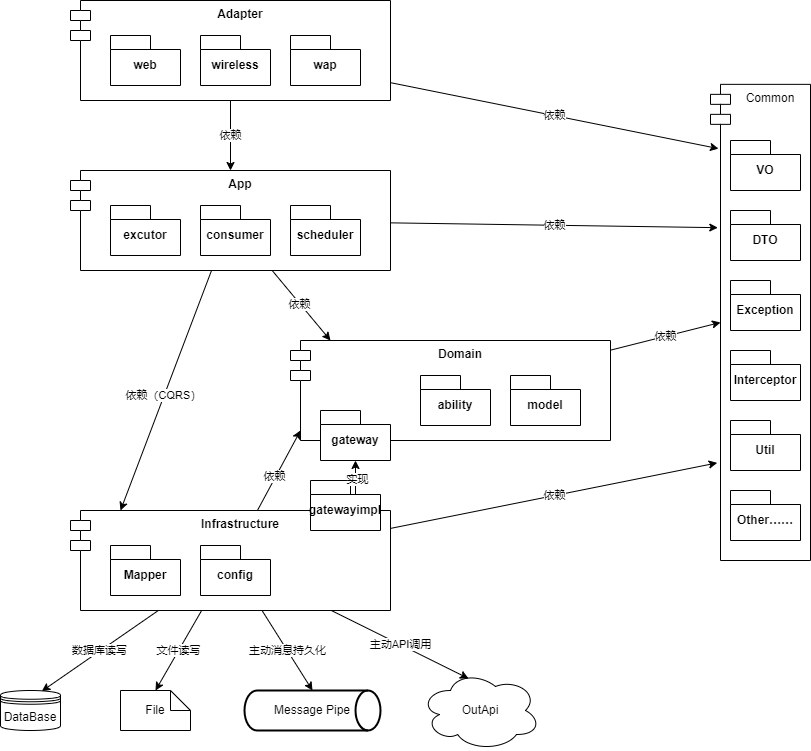
Comm本身作为公共内容被所有module依赖,Adapter作为系统唯一外部输出仅依赖APP,App本身除了依赖领域层外还因为CQRS相关内容依赖Infras;Domain层巧妙地使用依赖倒置让Infras层反向依赖它,以保证了Domain的独立和完整。整体是按照技术维度进行划分的。
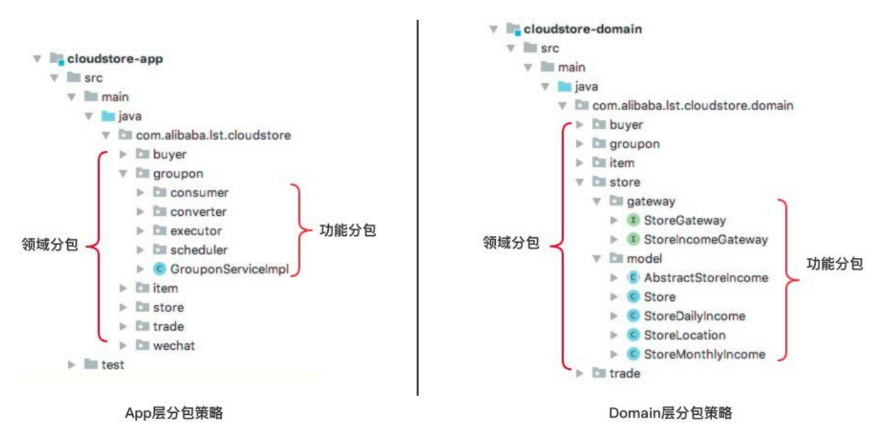
然后就是关于每个module的代码目录划分原则(基于领域维度进行划分),即每个module中对应的概念都划分到具体某一功能领域包中:
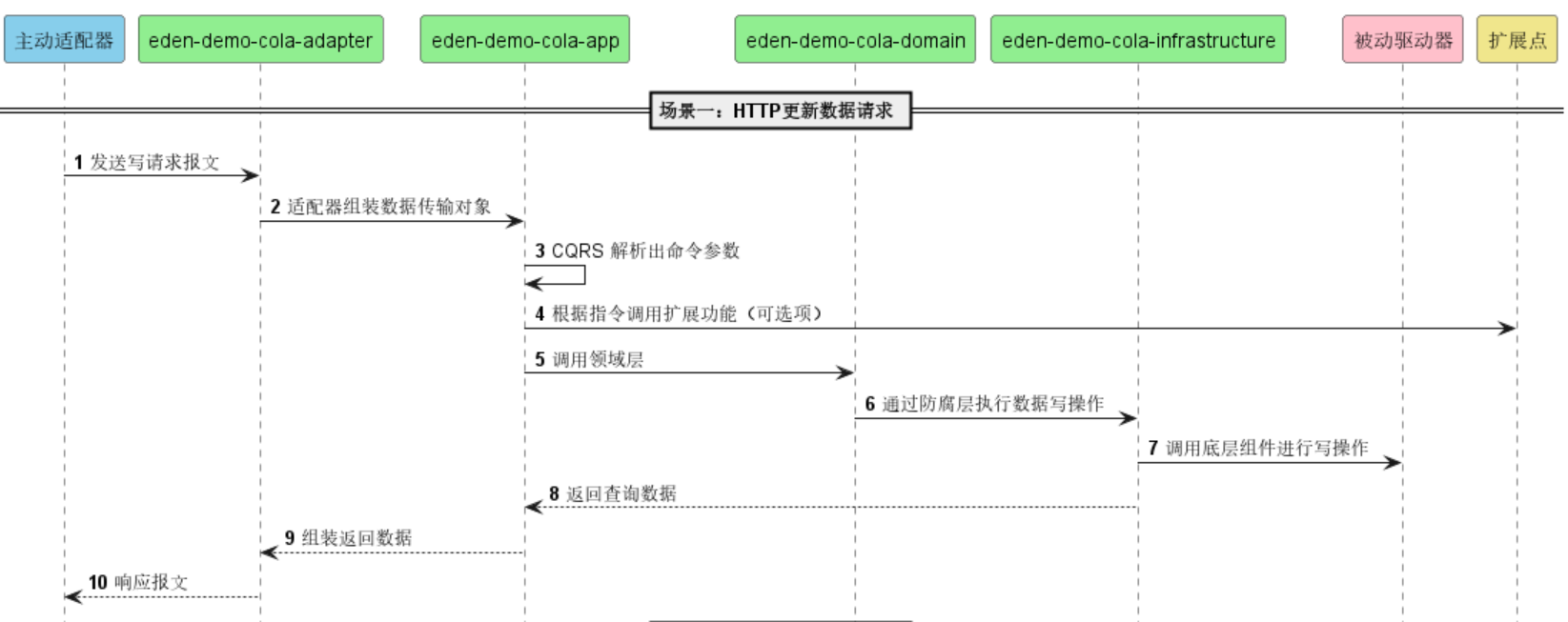
场景1(包含业务诉求):
由客户端发起请求,首先Adapter层接收请求,进行相关的校验后进行数据封装(Coverter操作:由请求参数封装为App层所需要的DTO结构),根据预设的逻辑去调用App的内容;DTO数据进入App后, App根据业务诉求,然后调用Domain的ability和module进行业务组装(Converter操作:将DTO转换为Entity对象);被调用的Domian在进行业务处理过程中调用Infras层去进行相关持久化和查询;Infras在被Domain调用时,需要把传入的Entity转换为内部对应数据的DO对象。最后逐层返回,相应的在Adapter层将DTO转为VO

场景2(CQRS诉求):
由外部客户端发起的不携带业务处理的查询操作,例如:某某数据列表查看、某某内容统计,则由Adapter接收请求后,封装参数对象后,调用相关App内容,App内部进行DTO和DO的相互coverter操作后,直接调用Infras层进行数据的查询操作。
从上面的运行流程不难看出,COLA在代码上有两个特点
Domain层足够独立且直至业务核心,通过巧妙的依赖倒置(gateway的接口与实现切割至两个module中),完成了与基础数据持久层的耦合,变成了最基础的被依赖者,内部分的model和ability这两部分是平等的, model是针对业务场景进行抽象的业务对象Entity、ability是抽象的业务直接的操作,相当于上文充血模式例子中AccountBO类和CreditPolicy、DebitPolicy的关系;优势就是可以专注于复杂的业务开发,并且保证业务代码的整洁性和可重构性。
制定了明确地规范,将部分非业务内容(数据转换、校验、适配等)均摊至不同的层次里,降低了原本贫血模式中Service持续积累过程中不可避免地臃肿;但是另一方面,为了实现面向对象与解耦,不可避免地追加了许多转换操作,存在DTO和Conver操作代码膨胀的风险
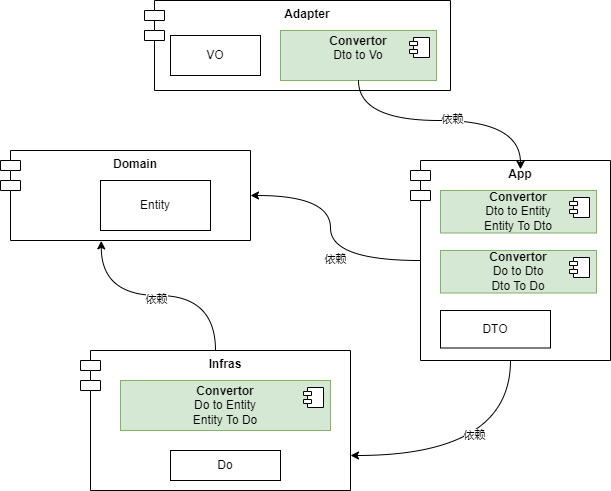
COLA框架相较于传统MVC(贫血模式)的三层结构要复杂一些,而复杂出来的内容(convertor、executor、extension、domainservice)的根本目的是在复杂的业务场景下,去践行面向对象的设计和编码,充分发挥面向对象的优势(保证代码的整洁、可维护等);但是同时也是要付出DTO对象和数据转换代码存在冗余激增风险的代价。
所以考虑使用COLA之前先谨慎考虑一下自己项目的特点,实际情况却是绝大多数业务并没有很复杂,都是基于数据的CRUD,且团队整体采用面向数据的开发方式去开发,没必要 “为了引入而引入”;其次使用COLA框架去开发是有技术成本的,至少对于团队研发工程师的要求较高(必须精通OOA、OOD、OOP),保证每个功能和需求的设计到落地都是连贯且完整的面向对象设计。
下面是针对COLA框架设计时依据的一些思想的提炼:
规范的代码框架:井井有条的包和目录分类以及统一的命名规范会像代码地图一样形成无形的约束
核心业务逻辑和技术细节分离:区分业务部分和非业务部分,并进行分离,让“上帝归上帝,凯撒归凯撒”
奥卡姆剃刀:让事情简单化,如无必须,勿增实体
合理使用领域对象模型设计domain和面向对象设计:让代码更加“面向对象”(个人比较喜欢,代码满足面向对象的一些设计原则),从而充分发挥面向对象的高扩展,易维护,实现高内聚、低耦合的究极目的。
通过小demo的方式跟大家分享一下我对DDD中战术层级的理解,算是抛砖引玉,该理解仅代表我个人在现阶段的一个理解,也可能未来随着业务经验深入,还会有不同的理解。
ELBO 用于最小化 q(z|s) 和 p(z|s) 的 KL 散度,变成最大化 p(x|z) 的 log likelihood + 最小化 q(z|s) 和先验 p(z) 的 KL 散度。