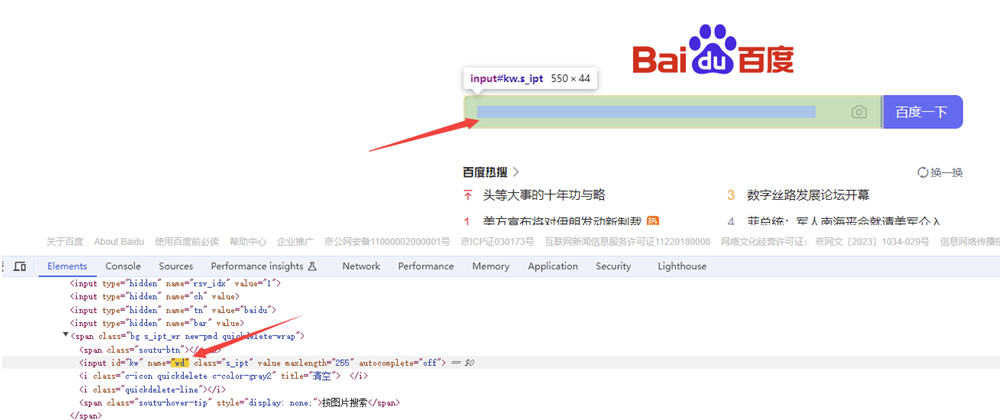
name属性为表单中客户端提交数据的标识,一个网页中name值可能不是唯一的。所以要根据实际情况进行判断
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 指定浏览器的位置,解决浏览器驱动和浏览器版本不匹配的问题
chrome_location = r'D:\pythonProject2023\SeleniumFirst\chrome-win64\chrome.exe'
options = webdriver.ChromeOptions()
options.binary_location = chrome_location
driver = webdriver.Chrome(options=options)
driver.get('https://www.baidu.com')
# 只获取属性的第一个元素
driver.find_element(By.NAME, 'wd').send_keys("万笑佛博客园")
# 获取属性的所有元素
driver.find_elements(By.NAME, 'wd')[0].send_keys("万笑佛博客园")
time.sleep(3)
复制
5-通过链接文本定位,By.LINK_TEXT 和通过链接部分文本定位,By.PARTIAL_LINK_TEXT
使用链接的全部文字定位元素

import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 指定浏览器的位置,解决浏览器驱动和浏览器版本不匹配的问题
chrome_location = r'D:\pythonProject2023\SeleniumFirst\chrome-win64\chrome.exe'
options = webdriver.ChromeOptions()
options.binary_location = chrome_location
driver = webdriver.Chrome(options=options)
driver.get('https://www.baidu.com')
driver.find_element(By.LINK_TEXT, '新闻').click()
#部分包含
#driver.find_element(By.PARTIAL_LINK_TEXT, '闻').click()
time.sleep(3)
复制
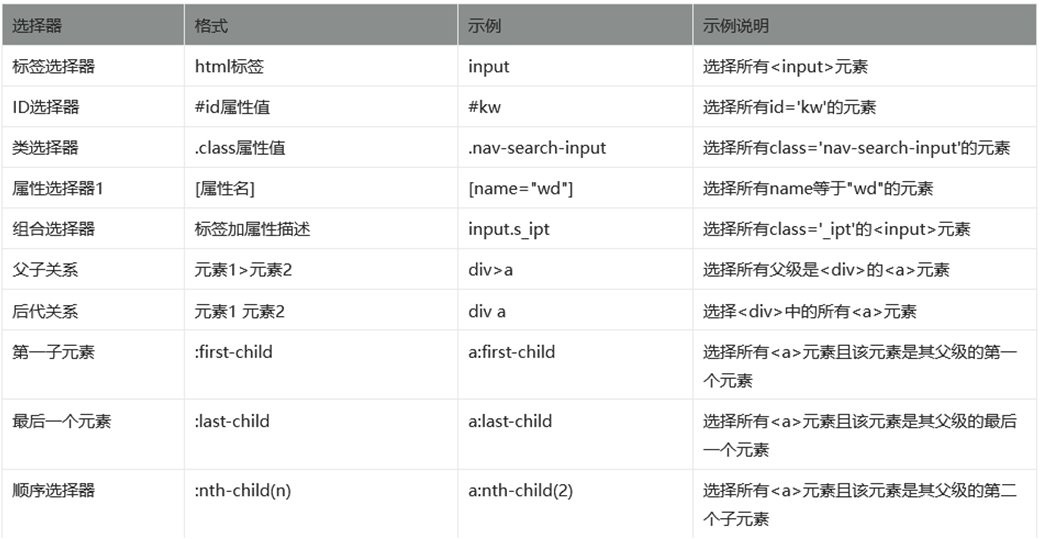
当一个元素无法直接定位,也就是没有id,name等确定标识,这个时候我们需要考虑使用css selector定位器。
它是一种通过CSS样式选择器来定位元素的方法
CSS常用汇总
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 指定浏览器的位置,解决浏览器驱动和浏览器版本不匹配的问题
chrome_location = r'D:\pythonProject2023\SeleniumFirst\chrome-win64\chrome.exe'
options = webdriver.ChromeOptions()
options.binary_location = chrome_location
driver = webdriver.Chrome(options=options)
driver.get('https://www.baidu.com')
#使用id属性定位,id前面要加#号
driver.find_element(By.CSS_SELECTOR, '#kw').send_keys("万笑佛博客园")
#通过class属性定位,class前面要加.
driver.get('https://www.bilibili.com')
driver.find_element(By.CSS_SELECTOR, '.nav-search-input').send_keys('万笑佛博客园')
# 根据name属性定位,属性值为[name="wd"]
driver.get('https://www.baidu.com')
driver.find_element(By.CSS_SELECTOR, '[name="wd"]').send_keys("万笑佛博客园")
# 根据标签属性定位
driver.get('https://www.baidu.com')
driver.find_element(By.CSS_SELECTOR, 'a[href="http://image.baidu.com/"]').click()
# 模糊匹配-包含
driver.find_element(By.CSS_SELECTOR, 'a[href*="image.baidu.com"]').click()
# 模糊匹配-匹配开头
driver.find_element(By.CSS_SELECTOR, 'a[href^="http://image.baidu"]').click()
# 模糊匹配-匹配结尾
driver.find_element(By.CSS_SELECTOR, 'a[href$="image.baidu.com/"]').click()
# 组合定位
driver.get('https://www.baidu.com')
# input+name
driver.find_element(By.CSS_SELECTOR, 'input[name="wd"]').send_keys("万笑佛博客园")
# input+class
driver.find_element(By.CSS_SELECTOR, 'input.s_ipt').send_keys("万笑佛博客园")
# 一般根据最近一个id属性往下找,可以根据class或者标签。
#s-top-left > a
#:nth-child(3)代表第几个子元素,下标从1开始
driver.get('https://www.baidu.com')
# 百度首页新闻,以下三种方式皆可
driver.find_element(By.CSS_SELECTOR, 'div.s-top-left-new.s-isindex-wrap a' ) # 根据class
driver.find_element(By.CSS_SELECTOR, 'div#s-top-left a') # 根据id
driver.find_element(By.CSS_SELECTOR, '#s-top-left a') # 简写
# 百度首页地图,以下2种方式皆可
driver.find_element(By.CSS_SELECTOR, '#s-top-left a:nth-child(3)')
driver.find_elements(By.CSS_SELECTOR, '#s-top-left a')[2]
# a:first-child 第一个标签
driver.find_element(By.CSS_SELECTOR, '#s-top-left a:first-child')
# a:last-child 最后一个标签
driver.find_element(By.CSS_SELECTOR, '#s-top-left a:last-child')
time.sleep(3)
复制