*简介:ollama-webUI是一个开源项目,简化了安装部署过程,并能直接管理各种大型语言模型(LLM)。本文将介绍如何在你的macOS上安装Ollama服务并配合webUI调用api来完成聊天。


打开终端,输入ollama -h,查看到所有的命令。
点击这里搜索你需要的模型,然后直接启动,例如:ollama run llama3,可看到下载速度非常快,取决于你的宽带。
下载完成,现在可以与他聊天了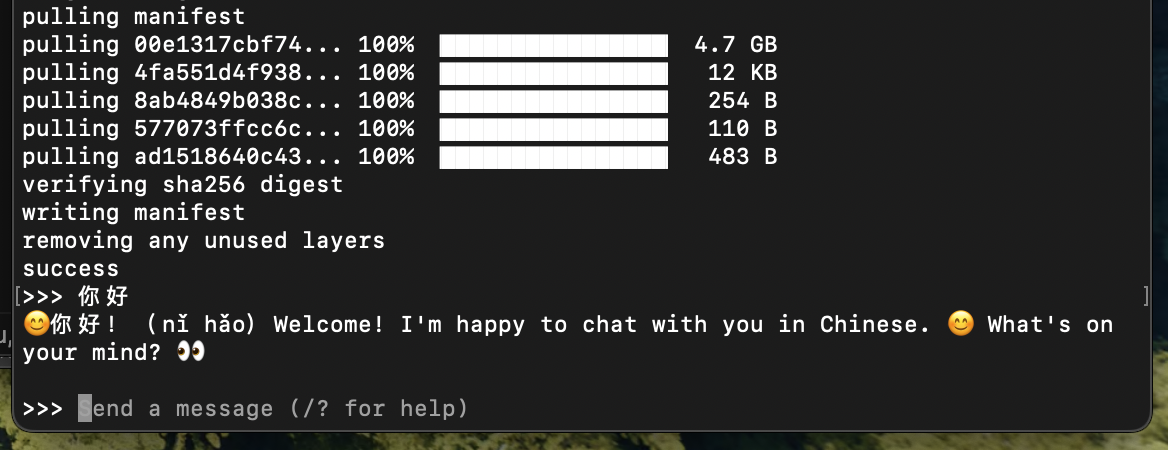
control + D退出聊天
ollama serve启动服务,发现端口被占用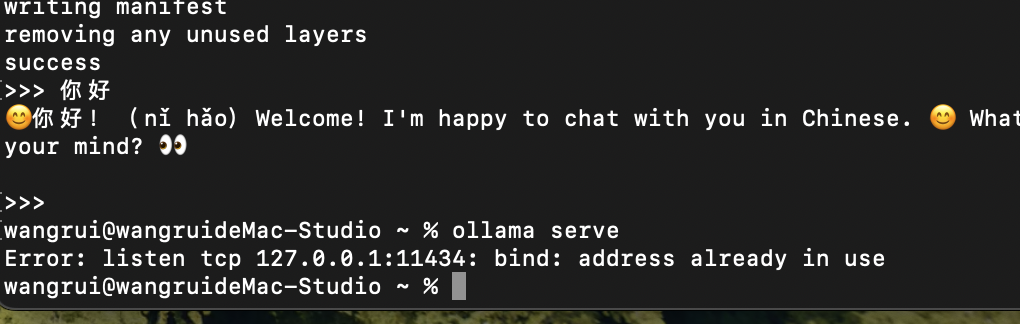
需要点击电脑右上角的ollama图标来退出ollama,再来运行ollama serve
git clone https://github.com/812781385/ollama-webUI.git
cd client
pnpm i
修改.env 里的VITE_APP_AXIOS_BASE_URL 为自己的ip地址
npm run dev 运行webUI
cd serve
npm i
npm run dev 运行服务端
浏览器访问http://localhost:8080/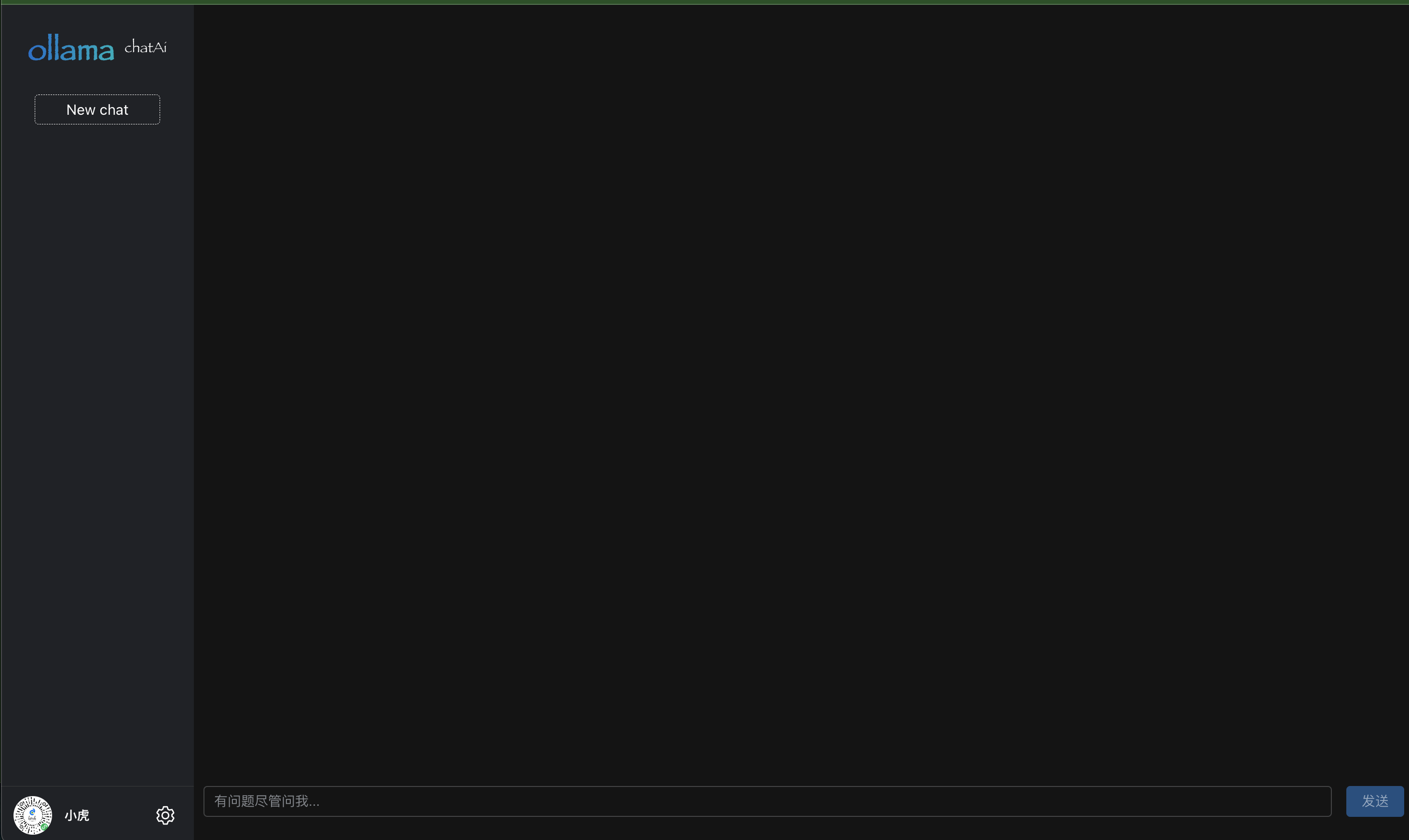
点击设置按钮,打开设置对话框,输入模型名称,例如:qwen:0.5b,点击按钮开始拉取模型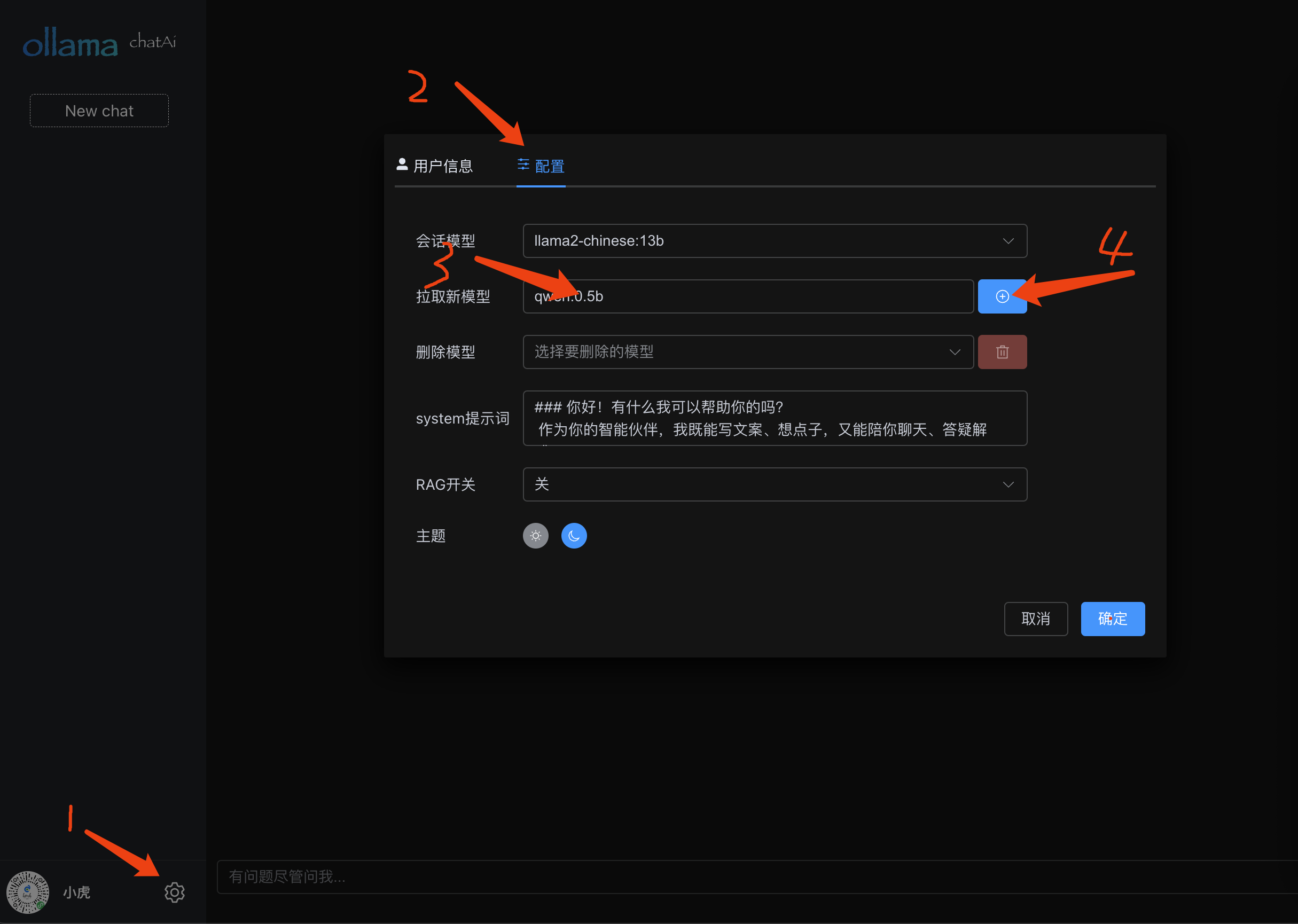

选择刚刚拉取好的模型后,点击确定。就可以开始聊天了
什么是RAG,例如你问AI:你的名字叫什么?,他会告诉你他是个ai模型...,这不是我想要的答案,怎么办?有两种方式,1.训练自己的模型。2.在prompt里嵌入自己的文案。例如:你的名字叫小虎,请参考这个问题来回答: 你的名字叫什么,这时候他会回答,他的名字叫小虎。
chroma run 启动数据库服务mxbai-embed-large,点击查看官网文档router.post('/addData', controller.chat.addDataForDB);