https://zhuanlan.zhihu.com/p/367683572
先给一张概览图:
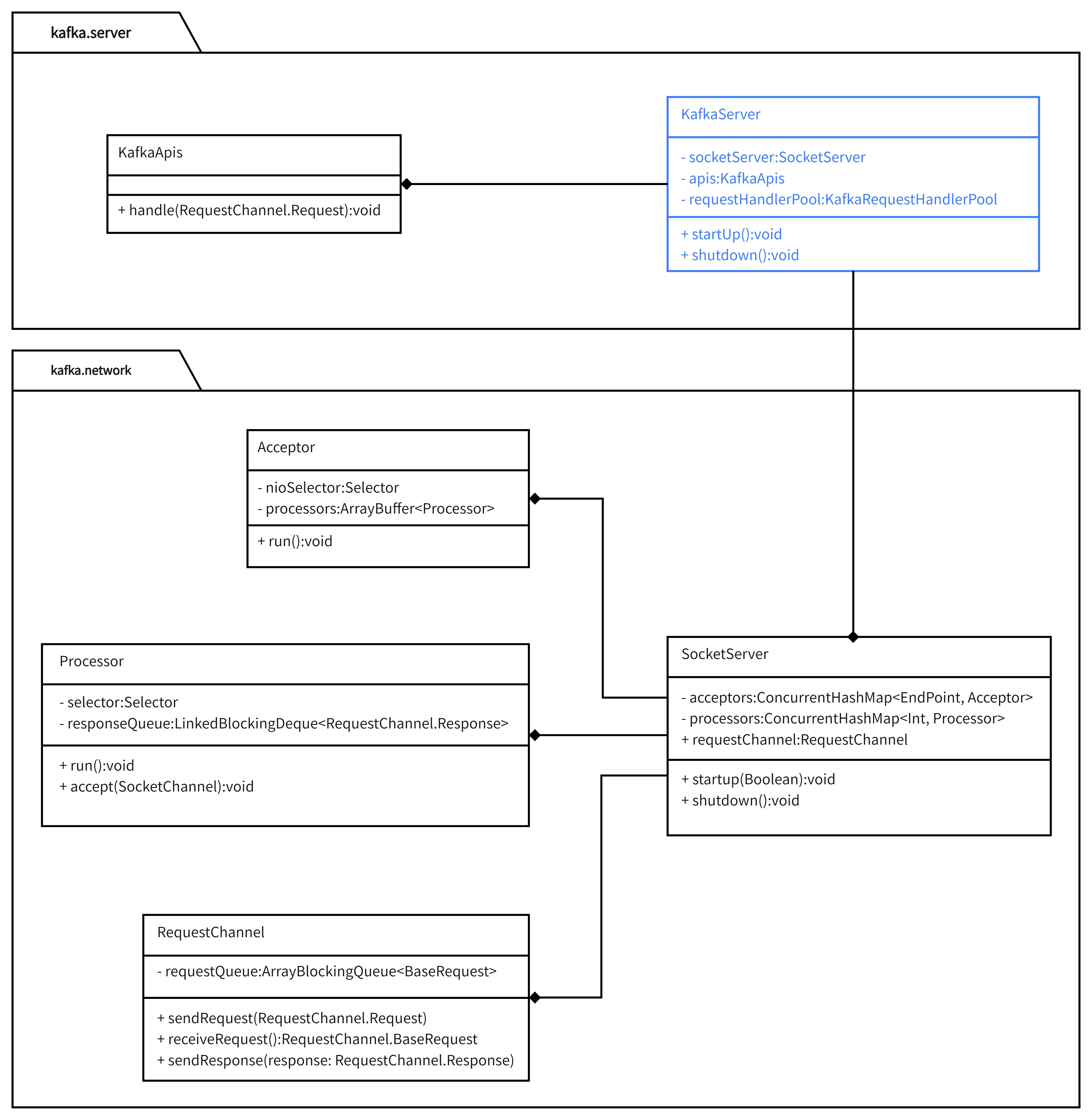
服务端请求处理过程涉及到两个模块:kafka.network和kafka.server。
该包是kafka底层模块,提供了服务端NIO通信能力基础。
有4个核心类:SocketServer、Acceptor、Processor、RequestChannel。各自角色如下:
SocketServer:服务端的抽象,是服务端通信的入口;
Acceptor:Reactor通信模式中处理连接ACCEPT事件的线程/线程池所执行的任务;
Processor:Reactor通信模式中处理连接可读/可写事件的线程/线程池所执行的任务;
RequestChannel:请求队列,存储已经解析好的请求以等待处理;
对于上层模块而言,该基础模块有两个输入和一个输出
输入:IP+端口号,该模块会对目标端口实现监听;
输出:解析好的请求,通过RequestChannel进行输出;
输入:待发送的Response,通过Processor.responseQueue来完成输入;
该包在kafka.network的基础上实现各种请求的处理逻辑,主要包含KafkaServer和KafkaApis两个类。其中:
KafkaServer:Kafka服务端的抽象,统一维护Kafka服务端的各流程和状态;
KakfaApis:维护了各类请求对应的业务逻辑,通过KafkaServer.apis字段组合到KafkaServer之中;
整体流程如图:
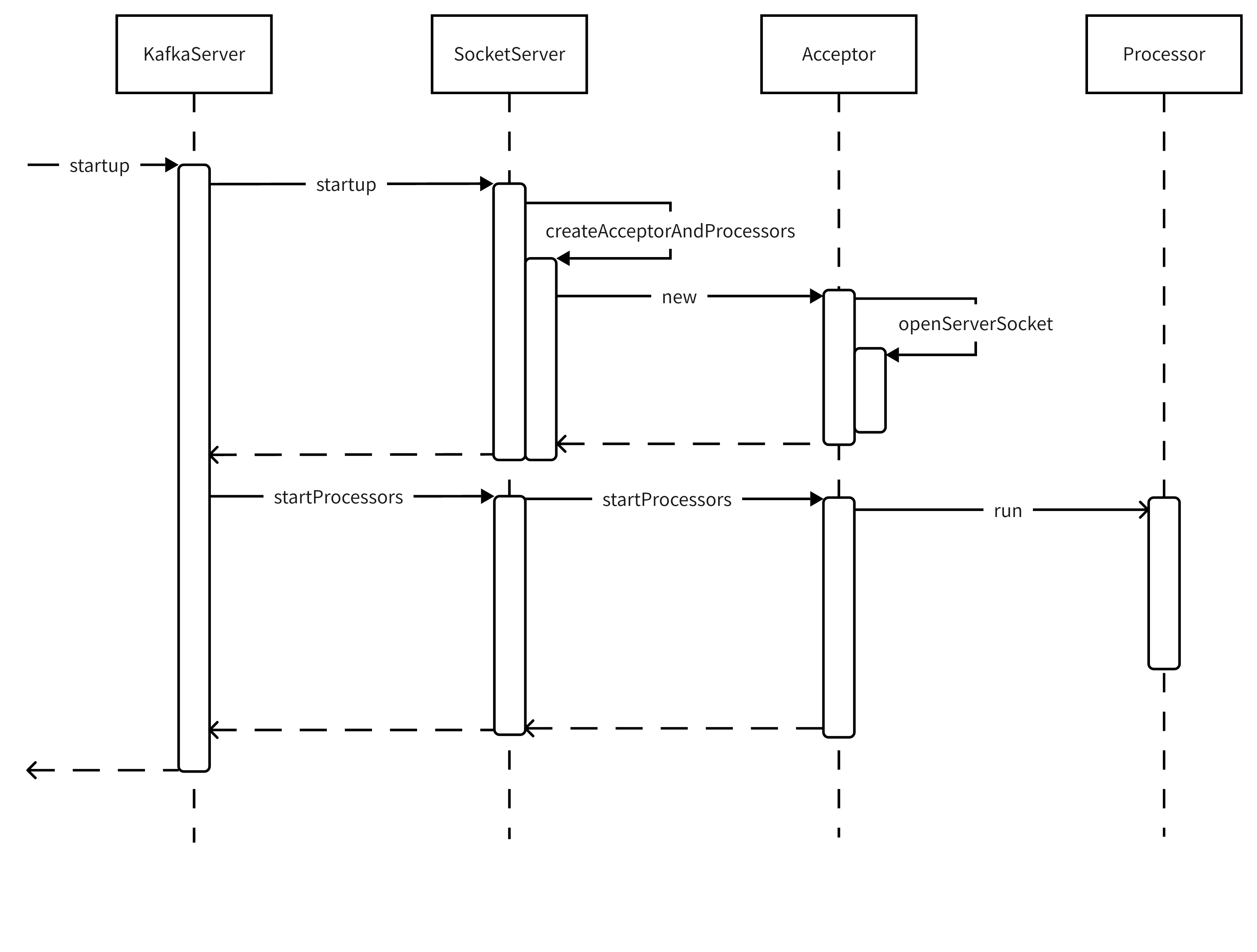
接下来按调用顺序依次分析各方法
关于端口监听的核心逻辑分4步,代码如下(用注释说明各部分的目的):
def startup() { // 省略无关代码 ... ... // 1. 创建SocketServer socketServer = new SocketServer(config, metrics, time, credentialProvider) // 2. 启动端口监听 // (在这里完成了Acceptor的创建和端口ACCEPT事件的监听) // (startupProcessors = false表示暂不启动Processor处理线程) socketServer.startup(startupProcessors = false) // 3. 启动请求处理过程中的相关依赖 // (这也是第2步中不启动Processor处理线程的原因,有依赖项需要处理) ... ... // 4. 启动端口可读/可写事件处理线程(即Processor线程) socketServer.startProcessors() // 省略无关代码 ... ... }复制
代码及说明性注释如下:
def startup(startupProcessors: Boolean = true) { this.synchronized { // 省略无关代码 ... ... // 1. 创建Accetpor和Processor的实例, // 同时页完成了Acceptor对端口ACCEPT事件的监听 createAcceptorAndProcessors(config.numNetworkThreads, config.listeners) // 2. [可选]启动各Acceptor对应的Processor线程 if (startupProcessors) { startProcessors() } } }复制
直接上注释版的代码,流程分3步:
// 入参解释 // processorsPerListener: 对于每个IP:Port, 指定Reactor模式子线程池大小, // 即处理端口可读/可写事件的线程数(Processor线程); // endpoints: 接收请求的IP:Port列表; def createAcceptorAndProcessors(processorsPerListener: Int, endpoints: Seq[EndPoint]): Unit = synchronized { // 省略无关代码 ... ... endpoints.foreach { endpoint => // 省略无关代码 ... ... // 1. 创建Acceptor对象 // 在此步骤中调用Acceptor.openServerSocket, 完成了对端口ACCEPT事件的监听 val acceptor = new Acceptor(endpoint, sendBufferSize, recvBufferSize, brokerId, connectionQuotas) // 2. 创建了与acceptor对应的Processor对象列表 // (这里并未真正启动Processor线程) addProcessors(acceptor, endpoint, processorsPerListener) // 3. 启动Acceptor线程 KafkaThread.nonDaemon(s"kafka-socket-acceptor-$listenerName-$securityProtocol-${endpoint.port}", acceptor).start() // 省略无关代码 ... ... } }复制
该方法中没什么特殊点,就是java NIO的标准流程:
def openServerSocket(host: String, port: Int): ServerSocketChannel = { // 1. 构建InetSocketAddress对象 val socketAddress = if (host == null || host.trim.isEmpty) new InetSocketAddress(port) else new InetSocketAddress(host, port) // 2. 构建ServerSocketChannel对象, 并设置必要参数值 val serverChannel = ServerSocketChannel.open() serverChannel.configureBlocking(false) if (recvBufferSize != Selectable.USE_DEFAULT_BUFFER_SIZE) serverChannel.socket().setReceiveBufferSize(recvBufferSize) // 3. 端口绑定, 实现事件监听 try { serverChannel.socket.bind(socketAddress) info("Awaiting socket connections on %s:%d.".format(socketAddress.getHostString, serverChannel.socket.getLocalPort)) } catch { case e: SocketException => throw new KafkaException("Socket server failed to bind to %s:%d: %s.".format(socketAddress.getHostString, port, e.getMessage), e) } // 4. 返回ServerSocketChannel对象, 用于后续register到Selector中 serverChannel }复制
从这步开始,仅剩的工作就是启动Processor线程,代码都非常简单。比如本方法只是遍历Acceptor列表,并调用Acceptor.startProcessors()
def startProcessors(): Unit = synchronized { acceptors.values.asScala.foreach { _.startProcessors() } info(s"Started processors for ${acceptors.size} acceptors") }复制
该方法很简明,直接上代码
def startProcessors(): Unit = synchronized { if (!processorsStarted.getAndSet(true)) { startProcessors(processors) } } def startProcessors(processors: Seq[Processor]): Unit = synchronized { processors.foreach { processor => KafkaThread.nonDaemon(s"kafka-network-thread-$brokerId-${endPoint.listenerName}-${endPoint.securityProtocol}-${processor.id}", processor).start() } }复制
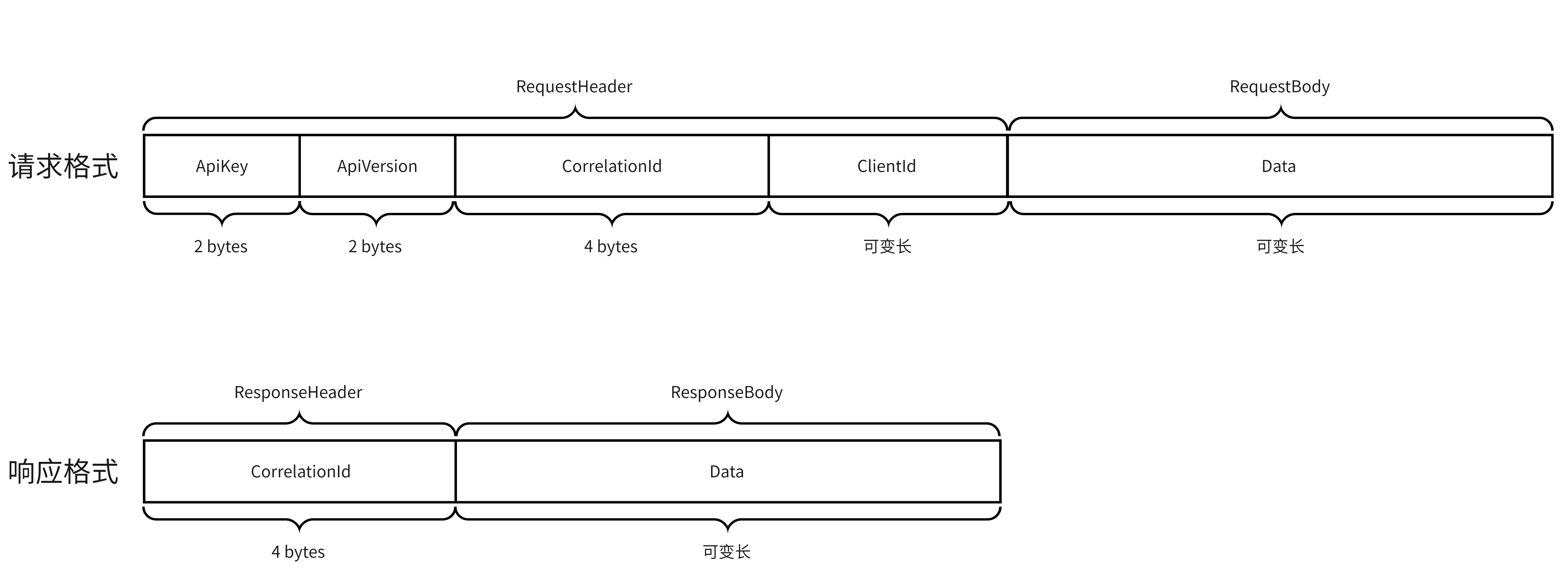
请求和响应都由两部分组成:Header和Body。RequestHeader中包含ApiKey、ApiVersion、CorrelationId、ClientId;ResponseHeader中只包含CorrelationId字段。接下来逐个讲解这些字段。
ApiKey
2字节整型,指明请求的类型;比如0代表Produce请求,1代表Fetch请求;具体id和请求类型之间的映射关系可在 org.apache.kafka.common.protocol.ApiKeys 中找到;
ApiVersion
随着API的升级迭代,各类型请求的请求体格式可能有变更;这个2字节的整型指明了请求体结构的版本;
CorrelationId
4字节整型,在Response中传回,Kafka Server端不处理,用于客户端内部关联业务数据;
ClientId
可变长字符串,标识客户端;
各业务操作(比如Produce、Fetch等)对应的请求体和响应体格式都维护在 org.apache.kafka.common.protocol.ApiKeys 中。接下来以Produce为例讲解ApiKeys是如何表达数据格式的。
ApiKeys是个枚举类,其核心属性如下:
public enum ApiKeys {
// 省略部分代码
... ...
// 上文提到的请求类型对应的id
public final short id;
// 业务操作名称
public final String name;
// 各版本请求体格式
public final Schema[] requestSchemas;
// 各版本响应体格式
public final Schema[] responseSchemas;
// 省略部分代码
... ...
}
复制其中PRODUCE枚举项的定义如下
PRODUCE(0, "Produce", ProduceRequest.schemaVersions(), ProduceResponse.schemaVersions())
复制可以看到各版本的请求格式维护在 ProduceRequest.schemaVersions(),代码如下
public static Schema[] schemaVersions() {
return new Schema[] {PRODUCE_REQUEST_V0, PRODUCE_REQUEST_V1, PRODUCE_REQUEST_V2, PRODUCE_REQUEST_V3,
PRODUCE_REQUEST_V4, PRODUCE_REQUEST_V5, PRODUCE_REQUEST_V6};
}
复制这里只是简单返回了一个Schema数组。一个Schema对象代表了一种数据格式。请求头中的ApiVersion指明了请求体的格式对应数组的第几项(从0开始)。
接下来我们看看Schema是如何表达数据格式的。其结构如下

Schema有两个字段:fields和fieldsByName。其中fields是体现数据格式的关键,它指明了字段的排序和各字段类型;而fieldsByName只是按字段名重新组织的Map,用于根据名称查找对应字段。
BoundField只是Field的简单封装。Field有两个核心字段:name和type。其中name表示字段名称,type表示字段类型。常见的Type如下:
Type.BOOLEAN;
Type.INT8;
Type.INT16;
Type.INT32;
// 可通过org.apache.kafka.common.protocol.types.Type查看全部类型
... ...
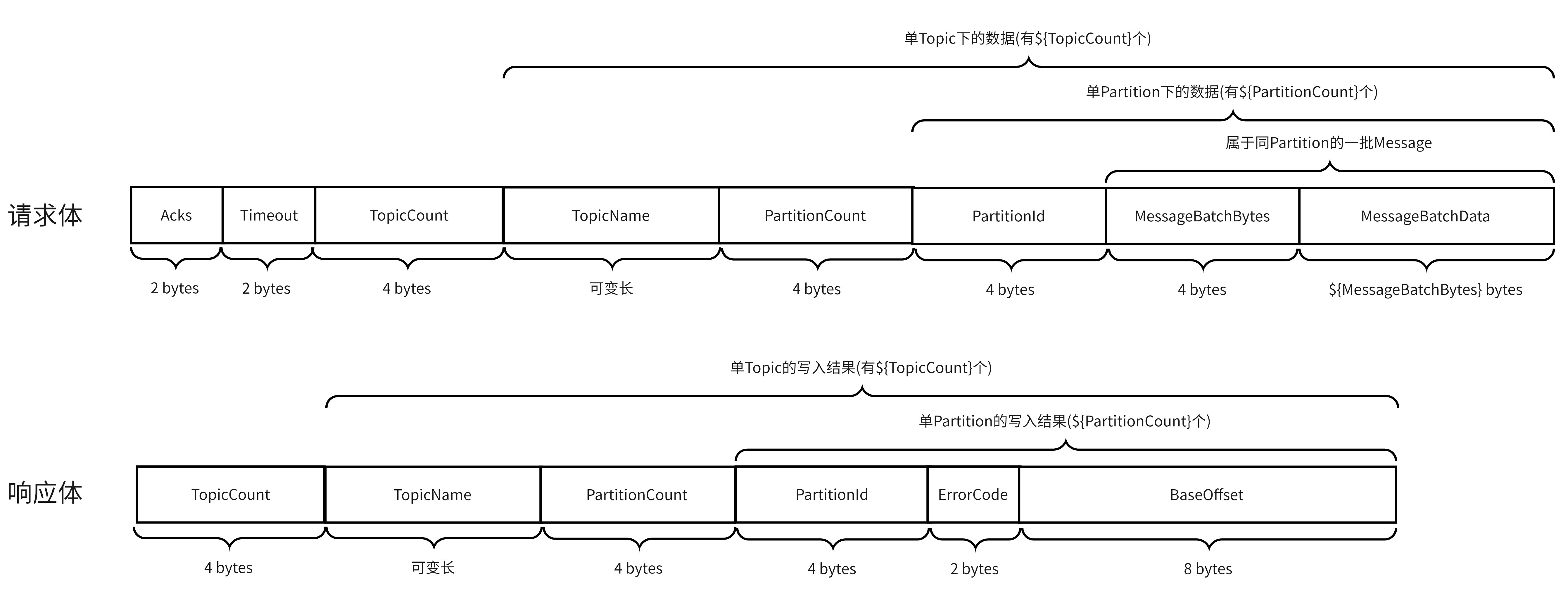
复制回到PRODUCE API,通过查看Schema的定义,能看到其V0版本的请求体和响应体的结构如下:
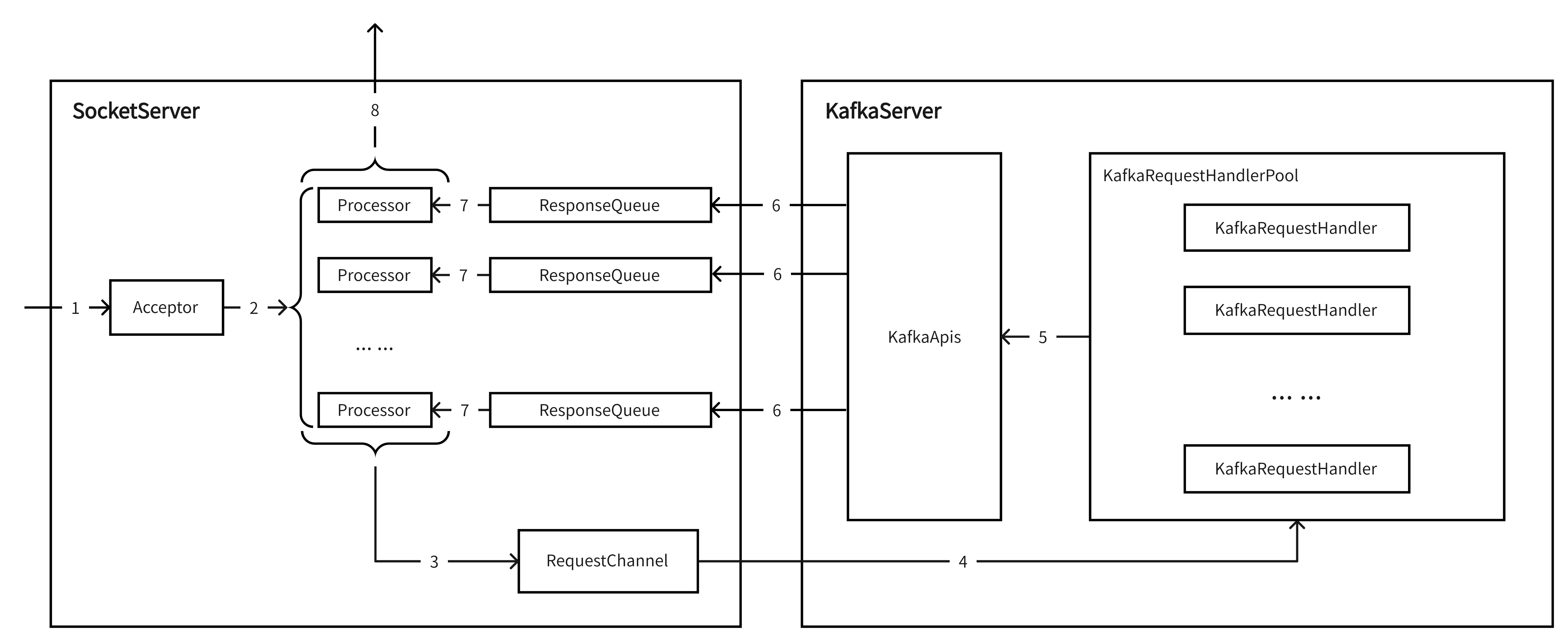
Acceptor监听到ACCEPT事件(TCP创建连接"第一次握手"的SYN);
Acceptor将将连接注册到Processor列表内的其中一个,由该Processor监听这个连接的后续可读可写事件;
Processor接收到完整请求后,会将Request追加到RequestChannel中进行排队,等待后续处理;
KafkaServer中有个requestHandlerPool的字段,KafkaRequestHandlerPool类型,代表请求处理线程池;KafkaRequestHandler就是其中的线程,会从RequestChannel拉请求进行处理;
KafkaRequestHandler将拉到的Request传入KafkaApis.handle(Request)方法进行处理;
KafkaApis根据不同的ApiKey调用不同的方法进行处理,处理完毕后会将Response最终写入对应的Processor的ResponseQueue中等待发送;KafkaApis.handle(Request)的方法结构如下:
def handle(request: RequestChannel.Request) { try { // 省略部分代码 ... ... request.header.apiKey match { case ApiKeys.PRODUCE => handleProduceRequest(request) case ApiKeys.FETCH => handleFetchRequest(request) case ApiKeys.LIST_OFFSETS => handleListOffsetRequest(request) case ApiKeys.METADATA => handleTopicMetadataRequest(request) case ApiKeys.LEADER_AND_ISR => handleLeaderAndIsrRequest(request) // 省略部分代码 ... ... } } catch { case e: FatalExitError => throw e case e: Throwable => handleError(request, e) } finally { request.apiLocalCompleteTimeNanos = time.nanoseconds } }复制
Processor从自己的ResponseQueue中拉取待发送的Respnose;
Processor将Response发给客户端;
才疏学浅,未能窥其十之一二,随时欢迎各位交流补充。若文章质量还算及格,可以点赞收藏加以鼓励,后续我继续更新。
知乎主页:https://www.zhihu.com/people/hao_zhihu
关注收藏不迷路,第一时间接收技术文章推送
微信公众号:
