` 标签来创建段落。 - 使用 CSS 来设置页面布局。
懒得看的朋友,先说最终解决办法,主力为 前端依靠插件 bookjs-easy(点击直接跳转官网)并跳转到下面的第三点查看
接下来详细记录下整个试探的方向和历程
项目需求:是生成一个页数达到大几十页的pdf,然后这个pdf包含表格、折线图、图片等,且横竖幅交叉,即竖版页面和横板页面交叉
1.首先我们讨论的方法是直接调用浏览器的页面打印+生成pdf,这个试过后很大的问题就是1:页面比较模糊,2:文件过于大了,很容易就几十几百兆,达不到标准,当时就直接pass掉了
2.让我(后端)获取html模板然后填充数据再转成pdf,这个当时测试的时候发现很清晰,文件也很小(毕竟是代码生成的,肯定比页面打印的截图要清楚多)感觉能行,就按这个方向往下做了,其实这是最大的坑的开始。
翻了一大堆博客文件之后,我统计了几种html转成pdf的方法:itext、html2pdf、wkhtmltopdf
复制
<!-- 先把后面几种方法用到的依赖全放在这,有需要测试之类的可以看看(最终我的需求 解决办法用不到这个,简单版pdf应该可以用) -->复制
<dependency> <groupId>com.itextpdf</groupId> <artifactId>itextpdf</artifactId> <version>5.5.11</version> </dependency> <!-- https://mvnrepository.com/artifact/com.itextpdf.tool/xmlworker --> <dependency> <groupId>com.itextpdf.tool</groupId> <artifactId>xmlworker</artifactId> <version>5.5.11</version> </dependency> <!-- https://mvnrepository.com/artifact/com.itextpdf/html2pdf --> <dependency> <groupId>com.itextpdf</groupId> <artifactId>html2pdf</artifactId> <version>3.0.3</version> </dependency> <!-- https://mvnrepository.com/artifact/org.thymeleaf/thymeleaf --> <dependency> <groupId>org.thymeleaf</groupId> <artifactId>thymeleaf</artifactId> <version>3.1.2.RELEASE</version> </dependency> <dependency> <groupId>org.xhtmlrenderer</groupId> <artifactId>flying-saucer-pdf</artifactId> <version>9.1.20</version> </dependency> <!-- 解决中文字体问题 --> <dependency> <groupId>com.itextpdf</groupId> <artifactId>itext-asian</artifactId> <version>5.2.0</version> </dependency> <dependency> <groupId>org.jfree</groupId> <artifactId>jfreechart</artifactId> <version>1.5.0</version> </dependency> <dependency> <groupId>org.apache.pdfbox</groupId> <artifactId>pdfbox</artifactId> <version>2.0.24</version> </dependency>复制
2.1第一步,使用了itext,这个直接转,也可以生成pdf,但是样式有很大的问题,表格超出,显示不全等等,而且对html要求严格,中文字体也有问题,需要自己安装解决(这个方法若有需求,网上教程很多,不是本文重点就不说了)
2.2接下来进行到使用 Thymeleaf 插值并生成pdf了,问题还是一样,替换后的值,所有都是中文显示不了,得自己安装、配置字体,最主要的就是样式依然有问题,太折腾,放弃
package com.example.web.controller.pdftest; import org.thymeleaf.TemplateEngine; import org.thymeleaf.context.Context; import org.thymeleaf.templateresolver.FileTemplateResolver; import org.xhtmlrenderer.pdf.ITextRenderer; import java.io.ByteArrayOutputStream; import java.io.FileOutputStream; /** * @author hua * @date 2024/4/18 * 读取html文件且使用Thymeleaf插入值,并转化为pdf文件 */ public class htmltopdf2 { public static void main(String[] args) throws Exception { // 创建模板解析器,并设置相关属性 FileTemplateResolver templateResolver = new FileTemplateResolver(); templateResolver.setPrefix("E:/Java/"); templateResolver.setSuffix(".html"); templateResolver.setTemplateMode("HTML"); templateResolver.setCharacterEncoding("UTF-8"); // 创建Thymeleaf模板引擎对象 TemplateEngine templateEngine = new TemplateEngine(); templateEngine.setTemplateResolver(templateResolver); // 创建上下文对象,添加要替换的变量 Context context = new Context(); context.setVariable("t1", "wowowo"); context.setVariable("t2", "阿试试211哥"); context.setVariable("t3", "dw打赏q3q"); context.setVariable("t4", "w电脑网123dfsw"); context.setVariable("t5", "与i啊基础aaa"); context.setVariable("t7", "不参加sdoap"); // 渲染模板并获取处理后的HTML字符串 String processedHtml = templateEngine.process("test1", context); // 使用Flying Saucer将HTML转换为PDF ITextRenderer renderer = new ITextRenderer(); renderer.setDocumentFromString(processedHtml); renderer.layout(); // 创建输出流以便写入PDF ByteArrayOutputStream baos = new ByteArrayOutputStream(); renderer.createPDF(baos); // 将PDF字节流转为字节数组 byte[] pdfBytes = baos.toByteArray(); // 你可以选择保存到本地 try (FileOutputStream fos = new FileOutputStream("E:/Java/output.pdf")) { fos.write(pdfBytes); } } }复制
2.3然后我使用了html2pdf,这个一样和itex差不多了多少,问题也是一样,字体问题卡了很久,是真的烦人,依然得自己下载配置
public static void main(String[] args) { String htmlFile = "E:\\Java\\temps\\uuuio.html"; String pdfFile = "E:\\Java\\temps\\uuuio.pdf"; try { htmlTopdf.html2pdf(htmlFile, pdfFile); } catch (Exception e) { e.printStackTrace(); } } public static void html2pdf(String htmlFile, String pdfFile) throws Exception { ConverterProperties converterProperties = new ConverterProperties(); DefaultFontProvider dfp = new DefaultFontProvider(); //添加字体库 dfp.addDirectory("C:/Windows/Fonts"); converterProperties.setFontProvider(dfp); try (InputStream in = new FileInputStream(new File(htmlFile)); OutputStream out = new FileOutputStream(new File(pdfFile))){ HtmlConverter.convertToPdf(in, out, converterProperties); }catch (Exception e){ e.printStackTrace(); } }复制
2.4接下来登场的才是重量级 wkhtmltopdf ! 刚开始发现转化样式还可以,基本不会丢失。
坑来了!!!!当时和公司另一位前端试了一下,wkhtmltopdf不支持转化vue写法,不支持es6及以上的写法,所有的前端代码都得用原生写,还得用原生html渲染数据进去,非常费劲,再强调一下对于我们这种几十上百页的pdf来说太低效了
(题外话:而且这时候已经开始考虑横板竖版怎么解决了,这里用的是拼接,即按竖版为pdf1,横板为pdf2、、、就这样分开转换,然后再使用 pdftk 或者 pdfbox 拼接,虽然最后我没用到,但是这两个方法真的很好用,有需要的可以看下。)
这个阶段我负责把前端得html模板(基本也没啥了,就剩个表头)读过来、插表格、折线图,其实这就是前端的活,但没办法和我配合的这个偷懒、自己也不主动研究,整个过程我无论前后端基本都是我找方法,不说了,来气。
下面这个就是我使用wkhtmltopdf获取本地html文件,进行插值,再转成pdf的测试代码,实用意义不大,只是给真有需要的人,必须需要从后端写表格折线图的人可以参考下(代码中的t1、t2之类的都是html文件里需要预留的占位符,方便替换,占位符写法${t1}),强烈不建议使用这种后端写前端代码的操作,简直逆天
package com.example.web.controller.pdftest; import org.apache.pdfbox.io.MemoryUsageSetting; import org.apache.pdfbox.multipdf.PDFMergerUtility; import java.io.File; import java.io.IOException; /** * @author hua * @date 2024/4/22 */ public class HtmlToPdfUtil { // public static void main(String[] args) throws IOException, InterruptedException { // //templ表格:这个部分是模拟表格数据及表格html的拼接============================================================================== // // 查询得到的数据列表 // List<TestObject> dataList = new ArrayList<>(); // 模拟从接口查询得到的数据 // //往dataList中插入30组随机数 // int dataLength = 31; // for (int i = 1; i < dataLength; i++) { // TestObject obj = new TestObject(); // obj.setT1("插值" + i); // obj.setT2("插值" + i); // obj.setT3("插值" + i); // obj.setT4("插值" + i); // obj.setT5("插值" + i); // dataList.add(obj); // } // for (int i = dataLength; i < 53; i++) { // TestObject obj = new TestObject(); // obj.setT1(" "); // obj.setT2(" "); // obj.setT3(" "); // obj.setT4(" "); // obj.setT5(" "); // dataList.add(obj); // } // // 将对象列表转换成二维表格数据的字符串形式 // StringBuilder tbodyContentBuilder = new StringBuilder(); // for (int rowIndex = 0; rowIndex < dataList.size(); rowIndex++) { // tbodyContentBuilder.append("<tr>"); // // 对于数据行,从dataList获取数据 // if (rowIndex < dataList.size()) { // TestObject obj = dataList.get(rowIndex); // if (rowIndex < 26) { // // 前26行,填充左边五列 // tbodyContentBuilder.append("<td>").append(obj.getT1()).append("</td>"); // tbodyContentBuilder.append("<td>").append(obj.getT2()).append("</td>"); // tbodyContentBuilder.append("<td>").append(obj.getT3()).append("</td>"); // tbodyContentBuilder.append("<td>").append(obj.getT4()).append("</td>"); // tbodyContentBuilder.append("<td>").append(obj.getT5()).append("</td>"); // // 后五列留空 // tbodyContentBuilder.append("<td>").append("a1a6a" + (rowIndex+26)).append("</td>"); // tbodyContentBuilder.append("<td>").append("a1a7a" + (rowIndex+26)).append("</td>"); // tbodyContentBuilder.append("<td>").append("a1a8a" + (rowIndex+26)).append("</td>"); // tbodyContentBuilder.append("<td>").append("a1a9a" + (rowIndex+26)).append("</td>"); // tbodyContentBuilder.append("<td>").append("a1a10a" + (rowIndex+26)).append("</td>"); // } else { // // 假设 rowIndex 和 obj.getT1() 已经有具体的值 // int index6 = tbodyContentBuilder.indexOf("a1a6a" + rowIndex); // if (index6 != -1) { // tbodyContentBuilder.replace(index6, index6 + ("a1a6a" + rowIndex).length(), obj.getT1()); // } // int index7 = tbodyContentBuilder.indexOf("a1a7a" + rowIndex); // if (index7 != -1) { // tbodyContentBuilder.replace(index7, index7 + ("a1a7a" + rowIndex).length(), obj.getT2()); // } // int index8 = tbodyContentBuilder.indexOf("a1a8a" + rowIndex); // if (index8 != -1) { // tbodyContentBuilder.replace(index8, index8 + ("a1a8a" + rowIndex).length(), obj.getT3()); // } // int index9 = tbodyContentBuilder.indexOf("a1a9a" + rowIndex); // if (index9 != -1) { // tbodyContentBuilder.replace(index9, index9 + ("a1a9a" + rowIndex).length(), obj.getT4()); // } // int index10 = tbodyContentBuilder.indexOf("a1a10a" + rowIndex); // if (index10 != -1) { // tbodyContentBuilder.replace(index10, index10 + ("a1a10a" + rowIndex).length(), obj.getT5()); // } // } // } else { // // 对于没有数据的行,创建空白单元格 // for (int colIndex = 0; colIndex < 10; colIndex++) { // tbodyContentBuilder.append("<td> </td>"); // } // } // tbodyContentBuilder.append("</tr>"); // } // // //templ折线图:这个部分是折线图的页面数据========================================================================================== // // StringBuilder svgContentBuilder = new StringBuilder(); // svgContentBuilder.append("<tr>"); // svgContentBuilder.append("<td colspan=\"10\" rowspan=\"5\">"); // // svgContentBuilder.append("<svg width=\"400\" height=\"200\" style=\"display:block;margin:auto;\">\n" + // " <!-- 第一条线(黑色) -->\n" + // " <polyline points=\"20,180 60,160 100,180 140,140\" stroke=\"black\" fill=\"none\" stroke-width=\"2\"/>\n" + // "\n" + // " <!-- 第二条线(红色) -->\n" + // " <polyline points=\"160,160 200,180 240,140\" stroke=\"red\" fill=\"none\" stroke-width=\"2\"/>\n" + // "\n" + // " <!-- 第三条线(蓝色) -->\n" + // " <polyline points=\"220,180 260,160 300,180 340,140\" stroke=\"blue\" fill=\"none\" stroke-width=\"2\"/>\n" + // "\n" + // " <!-- x轴 -->\n" + // " <line x1=\"20\" y1=\"180\" x2=\"340\" y2=\"180\" stroke=\"black\" stroke-width=\"1\"/>\n" + // "\n" + // " <!-- y轴 -->\n" + // " <line x1=\"20\" y1=\"180\" x2=\"20\" y2=\"20\" stroke=\"black\" stroke-width=\"1\"/>\n" + // "\n" + // " <!-- x轴刻度和标签 -->\n" + // " <text x=\"20\" y=\"190\" font-size=\"10\">0</text>\n" + // " <text x=\"340\" y=\"190\" font-size=\"10\">X Max</text>\n" + // " <!-- 假设每50单位一个刻度,仅为示例 -->\n" + // " <text x=\"60\" y=\"190\" font-size=\"8\">50</text>\n" + // " <text x=\"120\" y=\"190\" font-size=\"8\">100</text>\n" + // " <text x=\"180\" y=\"190\" font-size=\"8\">150</text>\n" + // " <text x=\"240\" y=\"190\" font-size=\"8\">200</text>\n" + // " <text x=\"300\" y=\"190\" font-size=\"8\">250</text>\n" + // "\n" + // " <!-- y轴刻度和标签(旋转-90度) -->\n" + // " <text x=\"10\" y=\"180\" font-size=\"10\" transform=\"rotate(-90 10,180)\">Y Max</text>\n" + // " <!-- 同样,假设每50单位一个刻度 -->\n" + // " <text x=\"10\" y=\"170\" font-size=\"8\" transform=\"rotate(-90 10,170)\">50</text>\n" + // " <text x=\"10\" y=\"150\" font-size=\"8\" transform=\"rotate(-90 10,150)\">100</text>\n" + // " <text x=\"10\" y=\"130\" font-size=\"8\" transform=\"rotate(-90 10,130)\">150</text>\n" + // " <text x=\"10\" y=\"110\" font-size=\"8\" transform=\"rotate(-90 10,110)\">200</text>\n" + // "\n" + // "</svg>"); // svgContentBuilder.append("</td>"); // svgContentBuilder.append("</tr>"); // // //templtest:======================================================================================================== // //获取折线图数据 // List<TestObject> zxList = new ArrayList<>(); // for (int i = 1; i < 9; i++){ // TestObject testObject = new TestObject(); // testObject.setZ1("第"+i+"条线"); // List<Integer> z2 = new ArrayList<>(); // z2.add(i+1); // z2.add(i+20); // z2.add(i+3); // z2.add(i+4); // z2.add(i+30); // z2.add(i+6); // z2.add(i+7); // z2.add(i+80); // z2.add(i+9); // z2.add(i+40); // z2.add(i+11); // z2.add(i+10); // testObject.setZ2(z2); //// testObject.setZ3("rgba(255,0,0,0.5)"); // Random random = new Random(); // testObject.setZ4("rgba("+ random.nextInt(256) +","+ random.nextInt(256) +","+ random.nextInt(256) +","+random.nextInt(256)+")"); // testObject.setZ5(false); // testObject.setZ6(0); // zxList.add(testObject); // } // // StringBuilder zxContentBuilder = new StringBuilder(); // for (TestObject zx : zxList){ //// zxContentBuilder.append(","); // zxContentBuilder.append("{ label:'").append(zx.getZ1()).append("',"); // zxContentBuilder.append("data:").append(zx.getZ2()).append(","); // zxContentBuilder.append("borderColor:'").append(zx.getZ4()).append("',"); //// zxContentBuilder.append("backgroundColor:'").append(zx.getZ4()).append("',"); // zxContentBuilder.append("fill:").append(zx.isZ5()).append(","); // zxContentBuilder.append("lineTension:").append(zx.getZ6()).append(","); // zxContentBuilder.append("borderWidth:1,}"); // zxContentBuilder.append(","); // } // // // 假设这些是从上下文或其他方式获得的变量值 // Map<String, String> variables = new HashMap<>(); // variables.put("t1", "wqeqweqweqweqweqw"); // variables.put("t2", "2:中文 ENGLISH 9527"); // variables.put("t3", "3:张三"); // variables.put("t4", "4:李四"); // variables.put("t5", "5:王五"); // variables.put("t6", "6:江苏qwewqeq"); // variables.put("t7", "7:2023年10月21日"); // // // variables.put("t99", String.valueOf(tbodyContentBuilder)); //// variables.put("t88", String.valueOf(svgContentBuilder)); // //坐标轴横坐标 //// variables.put("t81", "'一月','二月','三月','四月','五月','六月','七月','八月','九月','十月','十一月','十二月'"); //// variables.put("t82", String.valueOf(zxContentBuilder)); // System.out.println("数据组装完成,读取源html文件,准备替换"); // // // 读取原始HTML文件 // String htmlContent = new String(Files.readAllBytes(Paths.get("E:\\Java\\temps\\uuuio.html"))); //// System.out.println("原生html==-->"+htmlContent); // //开始转化,进行占位符替换、插值拼接生成新html页面 // for (Map.Entry<String, String> entry : variables.entrySet()) { // System.out.println("\\$\\{" + entry.getKey() + "\\}"); // htmlContent = htmlContent.replaceAll("\\$\\{" + entry.getKey() + "\\}", entry.getValue()); // } // // System.out.println("替换后的html==-->"+htmlContent); // // 将处理过的HTML内容暂时写入到内存中或者临时文件(这一步取决于wkhtmltopdf的具体用法) // // 如果wkhtmltopdf可以直接接受内存中的数据,则无需写入临时文件 // // 下面代码假设它需要一个临时文件: // File tempHtmlFile = File.createTempFile("temp-", ".html"); // Files.write(tempHtmlFile.toPath(), htmlContent.getBytes()); // System.out.println("tempHtmlFile.getAbsolutePath()===="+tempHtmlFile.getAbsolutePath()); // // // 构建wkhtmltopdf命令 // //生成pdf的位置 // String command = "D:\\worksoft\\wkhtmltox\\wkhtmltopdf\\bin\\wkhtmltopdf.exe " + tempHtmlFile.getAbsolutePath() + " E:\\Java\\temps\\uuuio.pdf"; // Process process = Runtime.getRuntime().exec(command); // // 等待转换完成 // int exitCode = process.waitFor(); // if (exitCode == 0) { // System.out.println("PDF-temp12-转换成功!"); // } else { // System.err.println("PDF-temp12-转换失败!"); // InputStream errorStream = process.getErrorStream(); // //查看这个errorStream // try (BufferedReader reader = new BufferedReader(new InputStreamReader(errorStream))) { // String line; // while ((line = reader.readLine()) != null) { // System.err.println(line); // } // } // System.err.println("PDF-转换失败!"); // } // // 转换完成后删除临时HTML文件 // tempHtmlFile.delete(); // } }复制
然后就是非常好用的拼接pdf的方法1:合并横竖版日报(pdfbox依赖版)2:合并横竖版日报(pdftk插件版),虽然最后我没用到
@ApiOperation(value = "pdfbox依赖版")
@GetMapping("/mergePdf") public Result<String> mergePdf(@RequestParam Long reportId){ try { PDFMergerUtility pdfMerger = new PDFMergerUtility(); // 添加要合并的PDF文件 pdfMerger.addSource(new File("E:\\Java\\temps\\temp_portrait.pdf")); pdfMerger.addSource(new File("E:\\Java\\temps\\temp_landscape.pdf")); pdfMerger.addSource(new File("E:\\Java\\temps\\outttttt.pdf")); pdfMerger.setDestinationFileName("E:\\Java\\temps\\merge.pdf"); pdfMerger.mergeDocuments(MemoryUsageSetting.setupMainMemoryOnly()); } catch (Exception e) { e.printStackTrace(); } return success("生成成功!"); } @ApiOperation(value = "合并横竖版日报(pdftk插件版)") @GetMapping("/mergePdf2") public Result<String> mergePdf2(@RequestParam Long reportId){ try { String wkhtmltopdf = "D:\\worksoft\\wkhtmltox\\wkhtmltopdf\\bin\\wkhtmltopdf.exe "; String pdftk = "D:\\worksoft\\wkhtmltox\\pdftk\\PDFtk\\bin\\pdftk.exe "; // 调用wkhtmltopdf生成纵向页面的PDF Process p1 = Runtime.getRuntime().exec("D:\\worksoft\\wkhtmltox\\wkhtmltopdf\\bin\\wkhtmltopdf.exe --orientation Portrait " +"E:\\Java\\temps\\temp1.html"+ " E:\\Java\\temps\\temp_portrait.pdf"); p1.waitFor(); // 调用wkhtmltopdf生成横向页面的PDF Process p2 = Runtime.getRuntime().exec("D:\\worksoft\\wkhtmltox\\wkhtmltopdf\\bin\\wkhtmltopdf.exe --orientation Landscape " +"E:\\Java\\temps\\temp12.html"+ " E:\\Java\\temps\\temp_landscape.pdf"); p2.waitFor(); // 调用pdftk合并这两个PDF Process p3 = Runtime.getRuntime().exec("D:\\worksoft\\wkhtmltox\\pdftk\\PDFtk\\bin\\pdftk.exe E:\\Java\\temps\\temp_portrait.pdf E:\\Java\\temps\\temp_landscape.pdf cat output " + "E:\\Java\\temps\\outttttt.pdf"); p3.waitFor(); // 清理临时文件 // new File("temp_portrait.pdf").delete(); // new File("temp_landscape.pdf").delete(); } catch (Exception e) { e.printStackTrace(); } return success("生成成功!"); }复制
3.至此上面后端解决的方法我不能再继续了,有点走远了,前端依然不研究,我就又找了个插件,bookjs-easy! 我的神来了,这个项目很好,但是官网的文档对于第一次看的人来说并不友好(第一次还是要读一遍,别想偷懒,不然后面更费时间),有些地方容易摸不着北,接下来我指出其中几个主要步骤或提醒
3.1首先去官网拉代码bookjs-easy,然后运行,这时候你发现生成的按钮(不是预览打印,是生成pdf直接保存到本地)请求报错,说连接服务器失败之类的
因为你需要自己启动一个服务端,用来替换官方的接口(因为2023.07.01以后官方接口就不开放支持了)服务端项目地址(点击即可)这个服务端两种办法1是本地,2是docker,我和官网一样也强烈推荐docker,方便快捷。
访问你的服务器后(你得先有docker),依次执行下面的两行命令,第一行是拉取,第二步是执行,不会参数的不要改动,复制执行即可,如果报端口already使用的,改下端口,比如把命令行中的端口即 第一个3000改成3010 -p 3010:3000
docker pull wuxue107/screenshot-api-server ## -e MAX_BROWSER=[num] 环境变量可选,最大的puppeteer实例数,忽略选项则默认值:1 , 值auto:[可用内存]/200M ## -e PDF_KEEP_DAY=[num] 自动删除num天之前产生的文件目录,默认0: 不删除文件 docker run -p 3000:3000 -td --rm -e MAX_BROWSER=1 -e PDF_KEEP_DAY=0 -v ${PWD}:/screenshot-api-server/public --name=screenshot-api-server wuxue107/screenshot-api-server复制
启动后把你的请求生成pdf地址换成域名+端口,然后模仿官网模板发起请求即可(建议你的前端项目也和这个docker放一个服务器,能减少很多麻烦)

要注意的是这个 API: http://localhost:3000/api/wkhtmltopdf-book 换成你的接口以后他有时候会自动拼接api/book(至于为什么还没时间搞明白),导致请求失败需要注意,可以在docker中查看此服务的日志
会发现日志还是报错(查看日志的命令行: docker logs 你容器执行的项目id,查看id的命令行:docker ps -a 最前面的最前面的CONTAINER ID就是i)
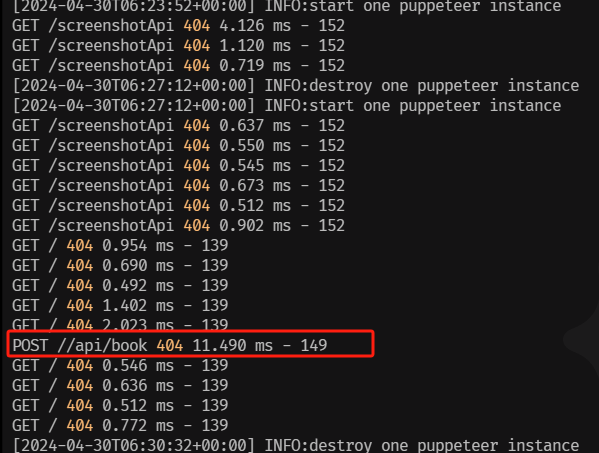
着重看这个红框里的,这种其实就差一步 http://localhost:3000/ ,前端的请求需要拿掉”/“,这里前端虽说试过了,但我还是让他再试一次,就成功请求了,不然又不知道要搞到多久
3.2至于横竖页面的解决办法,第一种,前端直接写横的,第二种前端控制旋转,把已写好的横页转一下,参考代码在下面
<!DOCTYPE html> <html> <head> <style> /* 使整个页面内容旋转90度 */ body { transform: rotate(90deg); /* 确保页面居中旋转,并适应视口 */ position: absolute; top: 50%; left: 50%; transform-origin: center center; width: 100vh; /* 旋转后,原宽度变为高度 */ height: 100vw; /* 原高度变为宽度 */ margin-top: -50vh; /* 调整垂直位置 */ margin-left: -50vw; /* 调整水平位置 */ overflow: auto; /* 确保可以滚动查看未在视口内的内容 */ } /* 可选:如果需要,可以对特定元素进行进一步的调整以优化显示效果 */ /* 例如,调整表格的宽度和高度以适应旋转后的布局 */ table { width: 100%; /* 根据需要调整表格宽度 */ height: auto; /* 或调整高度 */ } </style> </head> <body> <h1>标题也会旋转</h1> <table border="1"> <tr> <td>单元格1</td> <td>单元格2</td> </tr> <tr> <td>单元格3</td> <td>单元格4</td> </tr> </table> <p>这段文字和上面的表格都会随着页面旋转90度。</p> </body> </html>复制
至此,完整跑通这个功能,这给我折腾的,累了,明天放假,五一快乐!
写的很仓促,有什么不清楚的可以留言,看到我会回复
wkhtmltopdf复制