otter是一个无竞争的缓存,在相关的性能测试中表项突出。otter的原理基于如下论文:
Cache的定义如下,其主要的组件包括:
cleanup 的goroutine来定期清理过期数据。otter将大部分存储的大小都设置为2的幂,这样实现的好处有两点:
在进行存储大小调整时,方便通过移位操作进行扩缩容
通过位与操作可以方便找到ring buffer中的数据位置:
func RoundUpPowerOf2(v uint32) uint32 {
if v == 0 {
return 1
}
v--
v |= v >> 1
v |= v >> 2
v |= v >> 4
v |= v >> 8
v |= v >> 16
v++
return v
}
func main() {
var capacity uint32 = 5 //定义buffer容量
var bufferHead uint32
t := RoundUpPowerOf2(capacity) //将buffer容量转换为向上取2的幂
mask := t - 1 //获取掩码
buffer := make([]int, t)
head := atomic.LoadUint32(&bufferHead)
buffer[head&mask] = 100 //获取下一个数据位置,并保存数据
atomic.AddUint32(&bufferHead, 1) //下一个数据位置+1
}
复制在Cache中有一个锁
evictionMutex,并发访问竞争中,仅用于变更从readBuffers中返回的热点数据的freq,因此对并发访问竞争的影响很小。
type Cache[K comparable, V any] struct {
nodeManager *node.Manager[K, V]
hashmap *hashtable.Map[K, V] //hashmap
policy *s3fifo.Policy[K, V] //s3-FIFO
expiryPolicy expiryPolicy[K, V] //expiryPolicy
stats *stats.Stats
readBuffers []*lossy.Buffer[K, V] //readBuffers
writeBuffer *queue.Growable[task[K, V]] //writeBuffer
evictionMutex sync.Mutex
closeOnce sync.Once
doneClear chan struct{}
costFunc func(key K, value V) uint32
deletionListener func(key K, value V, cause DeletionCause)
capacity int
mask uint32
ttl uint32
withExpiration bool
isClosed bool
}
复制Otter中的数据单位为node,一个node表示一个[k,v]。使用Manager来创建node,根据使用的过期策略和Cost,可以创建bec、bc、be、b四种类型的节点:
b -->Base:基本类型
e -->Expiration:使用过期策略
c -->Cost:大部分场景下的node的cost设置为1即可,但在如某个node的数据较大的情况下,可以通过cost来限制s3-FIFO中的数据量,以此来控制缓存占用的内存大小。
type Manager[K comparable, V any] struct {
create func(key K, value V, expiration, cost uint32) Node[K, V]
fromPointer func(ptr unsafe.Pointer) Node[K, V]
}
复制NewManager可以根据配置创建不同类型的node:
func NewManager[K comparable, V any](c Config) *Manager[K, V] {
var sb strings.Builder
sb.WriteString("b")
if c.WithExpiration {
sb.WriteString("e")
}
if c.WithCost {
sb.WriteString("c")
}
nodeType := sb.String()
m := &Manager[K, V]{}
switch nodeType {
case "bec":
m.create = NewBEC[K, V]
m.fromPointer = CastPointerToBEC[K, V]
case "bc":
m.create = NewBC[K, V]
m.fromPointer = CastPointerToBC[K, V]
case "be":
m.create = NewBE[K, V]
m.fromPointer = CastPointerToBE[K, V]
case "b":
m.create = NewB[K, V]
m.fromPointer = CastPointerToB[K, V]
default:
panic("not valid nodeType")
}
return m
}
复制需要注意的是
NewBEC、NewBC、NewBE、NewB返回的都是node指针,后续可能会将该指针保存到hashmap、s3-FIFO、readBuffers等组件中,因此在可以保证各组件操作的是同一个node,但同时也需要注意node指针的回收,防止内存泄露。
hashmap是一个支持并发访问的数据结构,它保存了所有缓存数据。这里参考了puzpuzpuz/xsync的mapof实现。
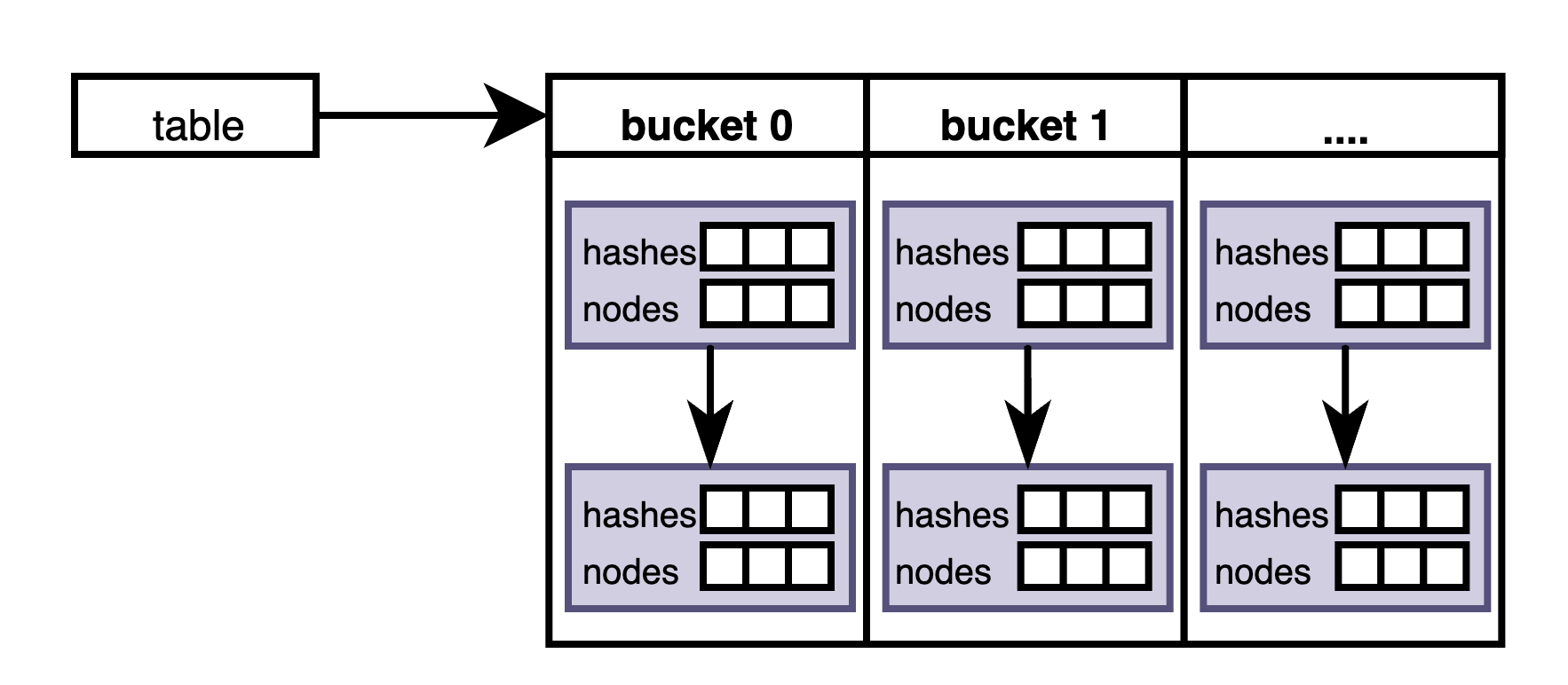
一个table包含一个bucket数组,每个bucket为一个链表,每个链表节点包含一个长度为3的node数组:
type Map[K comparable, V any] struct {
table unsafe.Pointer //指向一个table结构体,用于保存缓存数据
nodeManager *node.Manager[K, V] //用于管理node
// only used along with resizeCond
resizeMutex sync.Mutex
// used to wake up resize waiters (concurrent modifications)
resizeCond sync.Cond
// resize in progress flag; updated atomically
resizing atomic.Int64 //用于表示该map正处于resizing阶段,resizing可能会生成新的table,导致set失效,该值作为一个条件判断使用
}
复制type table[K comparable] struct {
buckets []paddedBucket //其长度为2的幂
// sharded counter for number of table entries;
// used to determine if a table shrinking is needed
// occupies min(buckets_memory/1024, 64KB) of memory
size []paddedCounter//用于统计table中的node个数,使用多个counter分散统计的目的是为了降低访问冲突
mask uint64 //为len(buckets)-1, 用于和node的哈希值作位于运算,计算node所在的bucket位置
hasher maphash.Hasher[K] //哈希方法,计算node的哈希值
}
复制bucket是一个单向链表:
type bucket struct {
hashes [bucketSize]uint64 //保存node的哈希值,bucketSize为3
nodes [bucketSize]unsafe.Pointer //保存node指针,node指针和node的哈希值所在的索引位置相同
next unsafe.Pointer//指向下一个bucket
mutex sync.Mutex //用于操作本bucket的锁
}
复制table的结构如下
下面是map的初始化方法,为了增加检索效率并降低链表长度,table中的buckets数目(size)不宜过小:
func newMap[K comparable, V any](nodeManager *node.Manager[K, V], size int) *Map[K, V] {
m := &Map[K, V]{
nodeManager: nodeManager,
}
m.resizeCond = *sync.NewCond(&m.resizeMutex)
var t *table[K]
if size <= minNodeCount {
t = newTable(minBucketCount, maphash.NewHasher[K]()) //minBucketCount=32
} else {
bucketCount := xmath.RoundUpPowerOf2(uint32(size / bucketSize))
t = newTable(int(bucketCount), maphash.NewHasher[K]())
}
atomic.StorePointer(&m.table, unsafe.Pointer(t))
return m
}
复制下面是向map添加数据的方式,注意它支持并行添加数据。set操作的是一个table中的某个bucket。如果table中的元素大于某个阈值,就会触发hashmap扩容(resize),此时会创建一个新的table,并将老的table中的数据拷贝到新建的table中。
set和resize都会变更相同的table,为了防止冲突,下面使用了bucket锁以及一些判断来防止此类情况:
每个bucket都有一个锁,resize在调整table大小时会新建一个table,然后调用copyBuckets将原table的buckets中的数据拷贝到新的table的buckets中。通过bucket锁可以保证resize和set不会同时操作相同的bucket
由于resize会创建新的table,有可能导致set和resize操作不同的table,进而导致set到无效的table中。
如果resize发生在set之前,则通过if m.resizeInProgress() 来保证二则操作不同的table
如果同时发生resize和set,则可以通过bucket锁+if m.newerTableExists(t)来保证操作的是最新的table。
由于copyBuckets时也会用到bucket锁,如果此时正在执行set,则copyBuckets会等待set操作完成后再将数据拷贝到新的table中。copyBuckets之后会将新的table保存到hashmap中,因此需要保证bucket和table的一致性,在set时获取到bucket锁之后需要进一步验证table是否一致。
func (m *Map[K, V]) set(n node.Node[K, V], onlyIfAbsent bool) node.Node[K, V] {
for {
RETRY:
var (
emptyBucket *paddedBucket
emptyIdx int
)
//获取map的table
t := (*table[K])(atomic.LoadPointer(&m.table))
tableLen := len(t.buckets)
hash := t.calcShiftHash(n.Key())//获取node的哈希值
bucketIdx := hash & t.mask //获取node在table中的bucket位置
//获取node所在的bucket位置
rootBucket := &t.buckets[bucketIdx]
//获取所操作的bucket锁,在resize时,会创建一个新的table,然后将原table中的数据拷贝到新创建的table中。
//resize的copyBuckets是以bucket为单位进行拷贝的,且在拷贝时,也会对bucket加锁。这样就保证了,如果同时发生set和resize,
//resize的copyBuckets也会等操作相同bucket的set结束之后才会进行拷贝。
rootBucket.mutex.Lock()
// the following two checks must go in reverse to what's
// in the resize method.
//如果正在调整map大小,则可能会生成一个新的table,为了防止出现无效操作,此时不允许继续添加数据
if m.resizeInProgress() {
// resize is in progress. wait, then go for another attempt.
rootBucket.mutex.Unlock()
m.waitForResize()
goto RETRY
}
//如果当前操作的是一个新的table,需要重新选择table
if m.newerTableExists(t) {
// someone resized the table, go for another attempt.
rootBucket.mutex.Unlock()
goto RETRY
}
b := rootBucket
//set node的逻辑是首先在bucket链表中搜索是否已经存在该node,如果存在则直接更新,如果不存在再找一个空位将其set进去
for {
//本循环用于在单个bucket中查找是否已经存在需要set的node。如果找到则根据是否设置onlyIfAbsent来选择
//是否原地更新。如果没有在当前bucket中找到所需的node,则需要继续查找下一个bucket
for i := 0; i < bucketSize; i++ {
h := b.hashes[i]
if h == uint64(0) {
if emptyBucket == nil {
emptyBucket = b //找到一个最近的空位,如果后续没有在bucket链表中找到已存在的node,则将node添加到该位置
emptyIdx = i
}
continue
}
if h != hash { //查找与node哈希值相同的node
continue
}
prev := m.nodeManager.FromPointer(b.nodes[i])
if n.Key() != prev.Key() { //为了避免哈希碰撞,进一步比较node的key
continue
}
if onlyIfAbsent { //onlyIfAbsent用于表示,如果node已存在,则不会再更新
// found node, drop set
rootBucket.mutex.Unlock()
return n
}
// in-place update.
// We get a copy of the value via an interface{} on each call,
// thus the live value pointers are unique. Otherwise atomic
// snapshot won't be correct in case of multiple Store calls
// using the same value.
atomic.StorePointer(&b.nodes[i], n.AsPointer())//node原地更新,保存node指针即可
rootBucket.mutex.Unlock()
return prev
}
//b.next == nil说明已经查找到最后一个bucket,如果整个bucket链表中都没有找到所需的node,则表示这是新的node,需要将node
//添加到bucket中。如果bucket空间不足,则需要进行扩容
if b.next == nil {
//如果已有空位,直接添加node即可
if emptyBucket != nil {
// insertion into an existing bucket.
// first we update the hash, then the entry.
atomic.StoreUint64(&emptyBucket.hashes[emptyIdx], hash)
atomic.StorePointer(&emptyBucket.nodes[emptyIdx], n.AsPointer())
rootBucket.mutex.Unlock()
t.addSize(bucketIdx, 1)
return nil
}
//这里判断map中的元素总数是不是已经达到扩容阈值growThreshold,即当前元素总数大于容量的0.75倍时就执行扩容
//其实growThreshold计算的是table中的buckets链表的数目,而t.sumSize()计算的是tables中的node总数,即
//所有链表中的节点总数。这么比较的原因是为了降低计算的时间复杂度,当tables中的nodes较多时,能够及时扩容
//buckets数目,而不是一味地增加链表长度。
//参见:https://github.com/maypok86/otter/issues/79
growThreshold := float64(tableLen) * bucketSize * loadFactor
if t.sumSize() > int64(growThreshold) {
// need to grow the table then go for another attempt.
rootBucket.mutex.Unlock()
//扩容,然后重新在该bucket中查找空位。需要注意的是扩容会给map生成一个新的table,
//并将原table的数据拷贝过来,由于table变了,因此需要重新set(goto RETRY)
m.resize(t, growHint)
goto RETRY
}
// insertion into a new bucket.
// create and append the bucket.
//如果前面bucket中没有空位,且没达到扩容要求,则需要新建一个bucket,并将其添加到bucket链表中
newBucket := &paddedBucket{}
newBucket.hashes[0] = hash
newBucket.nodes[0] = n.AsPointer()
atomic.StorePointer(&b.next, unsafe.Pointer(newBucket))//保存node
rootBucket.mutex.Unlock()
t.addSize(bucketIdx, 1)
return nil
}
//如果没有在当前bucket中找到所需的node,则需要继续查找下一个bucket
b = (*paddedBucket)(b.next)
}
}
}
复制func (m *Map[K, V]) copyBuckets(b *paddedBucket, dest *table[K]) (copied int) {
rootBucket := b
//使用bucket锁
rootBucket.mutex.Lock()
for {
for i := 0; i < bucketSize; i++ {
if b.nodes[i] == nil {
continue
}
n := m.nodeManager.FromPointer(b.nodes[i])
hash := dest.calcShiftHash(n.Key())
bucketIdx := hash & dest.mask
dest.buckets[bucketIdx].add(hash, b.nodes[i])
copied++
}
if b.next == nil {
rootBucket.mutex.Unlock()
return copied
}
b = (*paddedBucket)(b.next)
}
}
复制Get的逻辑和set的逻辑类似,但get时无需关心是否会操作老的table,原因是如果产生了新的table,其也会复制老的数据。
s3-FIFO可以看作是hashmap的数据过滤器,使用s3-FIFO来淘汰hashmap中的数据。
S3-FIFO的ghost使用了Dqueue。
Dqueue就是一个ring buffer,支持PopFront/PushFront和PushBack/PopBack,其中buffer size为2的幂。其快于golang的container/list库。
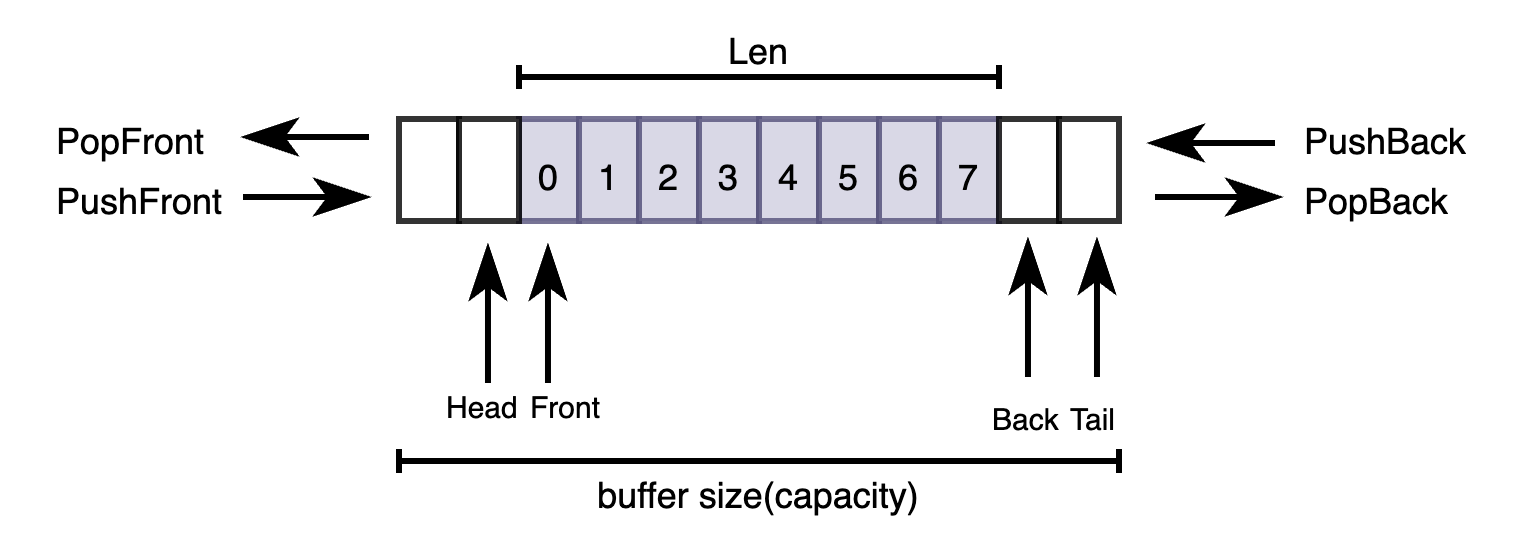
由于是ring buffer,随着push和pop操作,其back和front的位置会发生变化,因此可能会出现back push的数据到了Front前面的情况。
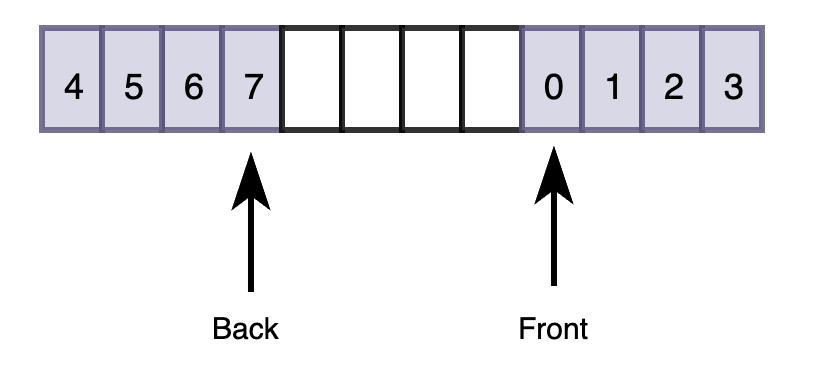
用法如下:
package main
import (
"fmt"
"github.com/gammazero/deque"
)
func main() {
var q deque.Deque[string]
q.PushBack("foo")
q.PushBack("bar")
q.PushBack("baz")
fmt.Println(q.Len()) // Prints: 3
fmt.Println(q.Front()) // Prints: foo
fmt.Println(q.Back()) // Prints: baz
q.PopFront() // remove "foo"
q.PopBack() // remove "baz"
q.PushFront("hello")
q.PushBack("world")
// Consume deque and print elements.
for q.Len() != 0 {
fmt.Println(q.PopFront())
}
}
复制在读取数据时,会将获取的数据也保存到readBuffers中,readBuffers的空间比较小,其中的数据可以看作是热点数据。当某个readBuffers[i]数组满了之后,会将readBuffers[i]中的所有nodes返回出来,并增加各个node的freq(给s3-FIFO使用),然后清空readBuffers[i]。
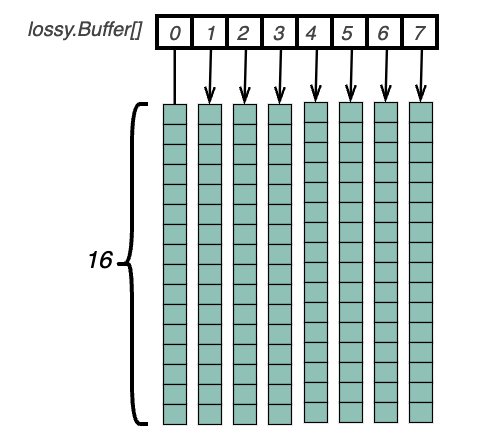
readBuffers是由4倍最大goroutines并发数的lossy.Buffer构成的数组,lossy.Buffer为固定大小的ring buffer 结构,包括用于创建node的nodeManager以及存放node数组的policyBuffers,容量大小为capacity(16)。
parallelism := xruntime.Parallelism()
roundedParallelism := int(xmath.RoundUpPowerOf2(parallelism))
复制readBuffersCount := 4 * roundedParallelism
readBuffers := make([]*lossy.Buffer[K, V], 0, readBuffersCount)
复制使用nodeManager来初始化lossy.Buffer,
for i := 0; i < readBuffersCount; i++ {
readBuffers = append(readBuffers, lossy.New[K, V](nodeManager))
}
复制下面是lossy.New的实现,Buffer长度为2的幂。
type Buffer[K comparable, V any] struct {
head atomic.Uint64 //指向buffer的head
headPadding [xruntime.CacheLineSize - unsafe.Sizeof(atomic.Uint64{})]byte
tail atomic.Uint64 //指向buffer的tail
tailPadding [xruntime.CacheLineSize - unsafe.Sizeof(atomic.Uint64{})]byte
nodeManager *node.Manager[K, V] //用于管理node
returned unsafe.Pointer //可以看做是一个条件锁,和hashmap的resizing作用类似,防止在buffer变更(add/free)的同时添加node
returnedPadding [xruntime.CacheLineSize - 2*8]byte
policyBuffers unsafe.Pointer //指向一个容量为16的PolicyBuffers,用于复制读缓存(buffer)中的热点数据
returnedSlicePadding [xruntime.CacheLineSize - 8]byte
buffer [capacity]unsafe.Pointer //存储读缓存的数据
}
复制type PolicyBuffers[K comparable, V any] struct {
Returned []node.Node[K, V]
}
复制func New[K comparable, V any](nodeManager *node.Manager[K, V]) *Buffer[K, V] {
pb := &PolicyBuffers[K, V]{
Returned: make([]node.Node[K, V], 0, capacity),
}
b := &Buffer[K, V]{
nodeManager: nodeManager,
policyBuffers: unsafe.Pointer(pb),
}
b.returned = b.policyBuffers
return b
}
复制下面是向readBuffers中添加数据的方式:
// Add lazily publishes the item to the consumer.
//
// item may be lost due to contention.
func (b *Buffer[K, V]) Add(n node.Node[K, V]) *PolicyBuffers[K, V] {
head := b.head.Load()
tail := b.tail.Load()
size := tail - head
//并发访问可能会导致这种情况,buffer满了就无法再添加元素,需要由其他操作通过返回热点数据来释放buffer空间
if size >= capacity {
// full buffer
return nil
}
// 添加开始,将tail往后移一位
if b.tail.CompareAndSwap(tail, tail+1) {
// tail中保存的是下一个元素的位置。使用mask位与是为了获取当前ring buffer中的tail位置。
index := int(tail & mask)
// 将node的指针保存到buffer的第index位,这样就完成了数据存储
atomic.StorePointer(&b.buffer[index], n.AsPointer())
// buffer满了,此时需要清理缓存,即将读缓存buffer中的热点数据数据存放到policyBuffers中,后续给s3-FIFO使用
if size == capacity-1 {
// 这里可以看做是一个条件锁,如果有其他线程正在处理热点数据,则退出。
if !atomic.CompareAndSwapPointer(&b.returned, b.policyBuffers, nil) {
// somebody already get buffer
return nil
}
//将整个buffer中的数据保存到policyBuffers中,并清空buffer。
pb := (*PolicyBuffers[K, V])(b.policyBuffers)
for i := 0; i < capacity; i++ {
// 获取head的索引
index := int(head & mask)
v := atomic.LoadPointer(&b.buffer[index])
if v != nil {
// published
pb.Returned = append(pb.Returned, b.nodeManager.FromPointer(v))
// 清空buffer的数据
atomic.StorePointer(&b.buffer[index], nil)
}
head++
}
b.head.Store(head)
return pb
}
}
// failed
return nil
}
复制Otter中的Add和Free是成对使用的,只有在Free中才会重置Add中变更的Buffer.returned。因此如果没有执行Free,则对相同Buffer的其他Add操作也无法返回热点数据。
idx := c.getReadBufferIdx()
pb := c.readBuffers[idx].Add(got) //获取热点数据
if pb != nil {
c.evictionMutex.Lock()
c.policy.Read(pb.Returned) //增加热点数据的freq
c.evictionMutex.Unlock()
c.readBuffers[idx].Free() //清空热点数据存放空间
}
复制Free方法如下:
// 在add返回热点数据,并在增加热点数据的freq之后,会调用Free方法释放热点数据的存放空间
func (b *Buffer[K, V]) Free() {
pb := (*PolicyBuffers[K, V])(b.policyBuffers)
for i := 0; i < len(pb.Returned); i++ {
pb.Returned[i] = nil //清空热点数据
}
pb.Returned = pb.Returned[:0]
atomic.StorePointer(&b.returned, b.policyBuffers)
}
复制writebuffer队列用于保存node的增删改事件,并由另外一个goroutine异步处理这些事件。事件类型如下:
const (
addReason reason = iota + 1
deleteReason
updateReason
clearReason //执行cache.Clear
closeReason //执行cache.Close
)
复制writebuffer的初始大小是最大并发goroutines数目的128倍:
queue.NewGrowable[task[K, V]](minWriteBufferCapacity, maxWriteBufferCapacity),复制
Growable是一个可扩展的ring buffer,从尾部push,从头部pop。在otter中作为存储node变动事件的缓存,类似kubernetes中的workqueue。
type Growable[T any] struct {
mutex sync.Mutex
notEmpty sync.Cond //用于通过push来唤醒由于队列中由于没有数据而等待的Pop操作
notFull sync.Cond //用于通过pop来唤醒由于数据量达到上限maxCap而等待的Push操作
buf []T //保存事件
head int //指向buf中下一个可以pop数据的索引
tail int //指向buf中下一个可以push数据的索引
count int //统计buf中的数据总数
minCap int //定义了buf的初始容量
maxCap int //定义了buf的最大容量,当count数目达到该值之后就不能再对buf进行扩容,需要等待pop操作来释放空间
}
复制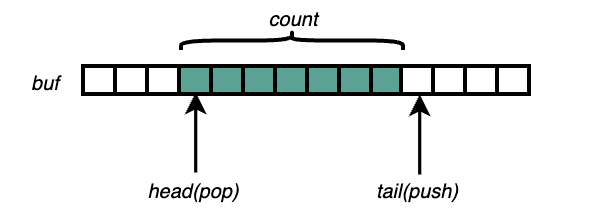
writebuffer的队列长度同样是2的幂,包括minCap和maxCap也是是2的幂:
func NewGrowable[T any](minCap, maxCap uint32) *Growable[T] {
minCap = xmath.RoundUpPowerOf2(minCap)
maxCap = xmath.RoundUpPowerOf2(maxCap)
g := &Growable[T]{
buf: make([]T, minCap),
minCap: int(minCap),
maxCap: int(maxCap),
}
g.notEmpty = *sync.NewCond(&g.mutex)
g.notFull = *sync.NewCond(&g.mutex)
return g
}
复制下面是扩展writebuffer的方法:
func (g *Growable[T]) resize() {
newBuf := make([]T, g.count<<1) //新的buf是原来的2倍
if g.tail > g.head {
copy(newBuf, g.buf[g.head:g.tail]) //将事件拷贝到新的buf
} else {
n := copy(newBuf, g.buf[g.head:]) //pop和push操作导致head和tail位置变动,且tail位于head之前,需要作两次copy
copy(newBuf[n:], g.buf[:g.tail])
}
g.head = 0
g.tail = g.count
g.buf = newBuf
}
复制支持的过期策略有:
RemoveExpired获取过期的nodes时,认为所有nodes都是过期的。下面介绍可变过期策略的实现:
var (
buckets = []uint32{64, 64, 32, 4, 1}
//注意spans中的元素值都是2的幂,分别为1(span[0]),64(span[1]),4096(span[2]),131072(span[3]),524288(span[4])。
//上面的buckets定义也很有讲究,spans[i]表示该buckets[i]的超时单位,buckets[i][j]的过期时间为j个spans[i],即过期时间为j*spans[i]。
//buckets之所以为{64, 64, 32, 4, 1},是因为buckets[1]的超时单位为64s,因此如果过期时间大于64s就需要使用buckets[1]的超时单位spans[1],
//反之则使用buckets[0]的超时单位spans[0],因此buckets[0]长度为64(64/1=64);
//以此类推,buckets[2]的超时单位为4096s,如果过期时间大于4096s就需要使用buckets[2]的超时单位spans[2],反之则使用buckets[1]的超时单位spans[1],
//因此buckets[1]长度为64(4096/64=64);buckets[3]的超时单位为131072s,如果过期时间大于131072s就需要使用buckets[3]的超时单位spans[3],
//反之则使用buckets[2]的超时单位spans[2],因此buckets[2]长度为32(131072/4096=32)...
//spass[4]作为最大超时时间单位,超时时间大于该spans[4]时,都按照spans[4]计算
//buckets[i]的长度随过期时间的增加而减少,这也符合常用场景,因为大部分场景中的过期时间都较短,像1.52d这种级别的过期时间比较少见
spans = []uint32{
xmath.RoundUpPowerOf2(uint32((1 * time.Second).Seconds())), // 1s--2^0
xmath.RoundUpPowerOf2(uint32((1 * time.Minute).Seconds())), // 1.07m --64s--2^6
xmath.RoundUpPowerOf2(uint32((1 * time.Hour).Seconds())), // 1.13h --4096s--2^12
xmath.RoundUpPowerOf2(uint32((24 * time.Hour).Seconds())), // 1.52d --131072s--2^17
buckets[3] * xmath.RoundUpPowerOf2(uint32((24 * time.Hour).Seconds())), // 6.07d --524288s--2^19
buckets[3] * xmath.RoundUpPowerOf2(uint32((24 * time.Hour).Seconds())), // 6.07d --524288s--2^19
}
shift = []uint32{
uint32(bits.TrailingZeros32(spans[0])),
uint32(bits.TrailingZeros32(spans[1])),
uint32(bits.TrailingZeros32(spans[2])),
uint32(bits.TrailingZeros32(spans[3])),
uint32(bits.TrailingZeros32(spans[4])),
}
)
复制下面是缓存数据使用的数据结构。
type Variable[K comparable, V any] struct {
wheel [][]node.Node[K, V]
time uint32
}
复制Variable.wheel的数据结构如下,Variable.wheel[i][]的数组长度等于buckets[i],buckets[i]的超时单位为spans[i],Variable.wheel[i][j]表示过期时间为j*spans[i]的数据所在的位置。
但由于超时单位跨度比较大,因此即使Variable.wheel[i][j]所在的nodes被认为是过期的,也需要进一步确认node是否真正过期。以64s的超时单位为例,过期时间为65s的node和过期时间为100s的node会放到相同的wheel[1][0]链表中,若当前时间为80s,则只有过期时间为65s的node才是真正过期的。因此需要进一步比较具体的node过期时间。
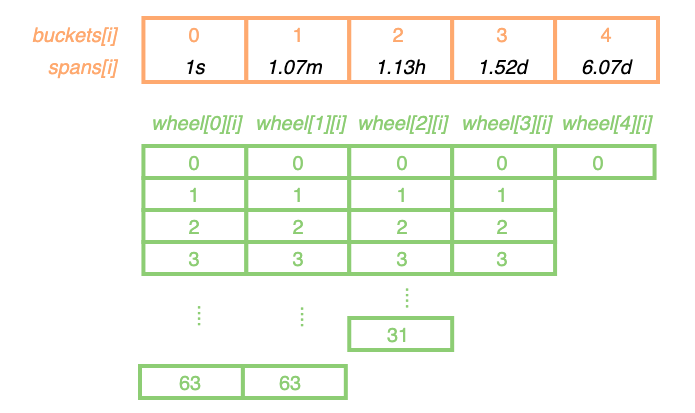
Variable.time是一个重要的成员:其表示上一次执行清理操作(移除过期数据或清除所有数据)的时间,并作为各个wheel[i]数组中的有效数据的起点。该值在执行清理操作之后会被重置,表示新的有效数据起点。要理解该成员的用法,应该将Variable.wheel[i]的数组看做是一个个时间块(而非位置点),每个时间块表示一个超时单位。
Variable的初始化Variable的初始化方式如下,主要就是初始化一个二维数组:
func NewVariable[K comparable, V any](nodeManager *node.Manager[K, V]) *Variable[K, V] {
wheel := make([][]node.Node[K, V], len(buckets))
for i := 0; i < len(wheel); i++ {
wheel[i] = make([]node.Node[K, V], buckets[i])
for j := 0; j < len(wheel[i]); j++ {
var k K
var v V
fn := nodeManager.Create(k, v, math.MaxUint32, 1) //默认过期时间为math.MaxUint32,相当于没有过期时间
fn.SetPrevExp(fn)
fn.SetNextExp(fn)
wheel[i][j] = fn
}
}
return &Variable[K, V]{
wheel: wheel,
}
}
复制func (v *Variable[K, V]) RemoveExpired(expired []node.Node[K, V]) []node.Node[K, V] {
currentTime := unixtime.Now()//获取到目前为止,系统启动的秒数,以此作为当前时间
prevTime := v.time //获取上一次执行清理的时间,在使用时会将其转换为以spans[i]为单位的数值,作为各个wheel[i]的起始清理位置
v.time = currentTime //重置v.time,本次清理之后的有效数据的起始位置,也可以作为下一次清理时的起始位置
//在清理数据时会将时间转换以spans[i]为单位的数值。delta表示上一次清理之后到当前的时间差。
//在清理时需要遍历清理各个wheel[i],如果delta大于buckets[i],则认为整个wheel[i]都可能出现过期数据,
//反之,则认为wheel[i]的部分区间数据可能过期。
for i := 0; i < len(shift); i++ {
//在prevTime和currentTime都小于shift[i]或二者非常接近的情况下delta可能为0,但delte为0时无需执行清理动作
previousTicks := prevTime >> shift[i]
currentTicks := currentTime >> shift[i]
delta := currentTicks - previousTicks
if delta == 0 {
break
}
expired = v.removeExpiredFromBucket(expired, i, previousTicks, delta)
}
return expired
}
复制下面用于清理wheel[i]下的过期数据:
func (v *Variable[K, V]) removeExpiredFromBucket(expired []node.Node[K, V], index int, prevTicks, delta uint32) []node.Node[K, V] {
mask := buckets[index] - 1
//获取buckets[index]对应的数组长度
steps := buckets[index]
//如果delta小于buckets[index]的大小,则[start,start+delta]之间的数据可能是过期的
//如果delta大于buckets[index]的大小,则整个buckets[i]都可能是过期的
if delta < steps {
steps = delta
}
//取上一次清理的时间作为起始位置,[start,end]之间的数据都认为可能是过期的
start := prevTicks & mask
end := start + steps
timerWheel := v.wheel[index]
for i := start; i < end; i++ {
//遍历wheel[index][i]中的链表
root := timerWheel[i&mask]
n := root.NextExp()
root.SetPrevExp(root)
root.SetNextExp(root)
for !node.Equals(n, root) {
next := n.NextExp()
n.SetPrevExp(nil)
n.SetNextExp(nil)
//注意此时v.time已经被重置为当前时间。进一步比较具体的node过期时间。
if n.Expiration() <= v.time {
expired = append(expired, n)
} else {
v.Add(n)
}
n = next
}
}
return expired
}
复制下图展示了删除过期数据的方式
v.time中保存了上一次清理的时间,进而转换为本次wheel[i]的清理起始位置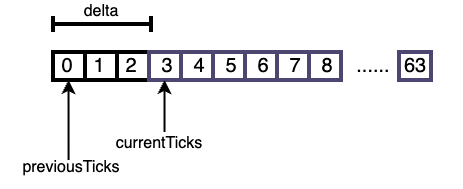
添加数据时首先需要找到该数据在Variable.wheel中的位置Variable.wheel[i][j],然后添加到该位置的链表中即可。
在添加数据时需要避免将数据添加到上一次清理点之前
// findBucket determines the bucket that the timer event should be added to.
func (v *Variable[K, V]) findBucket(expiration uint32) node.Node[K, V] {
//expiration是绝对时间。获取距离上一次清理过期数据(包括清理所有数据)所过去的时间,或看做是和起始有效数据的距离。
duration := expiration - v.time
length := len(v.wheel) - 1
for i := 0; i < length; i++ {
//找到duration的最佳超时单位spans[i]
if duration < spans[i+1] {
//计算expiration包含多少个超时单位,并以此作为其在wheel[i]中的位置index。
//expiration >> shift[i]等价于(duration + v.time)>> shift[i],即和起始有效数据的距离
ticks := expiration >> shift[i]
index := ticks & (buckets[i] - 1)
return v.wheel[i][index]
}
}
return v.wheel[length][0] //buckets[4]的长度为1,因此二维索引只有一个值0。
}
复制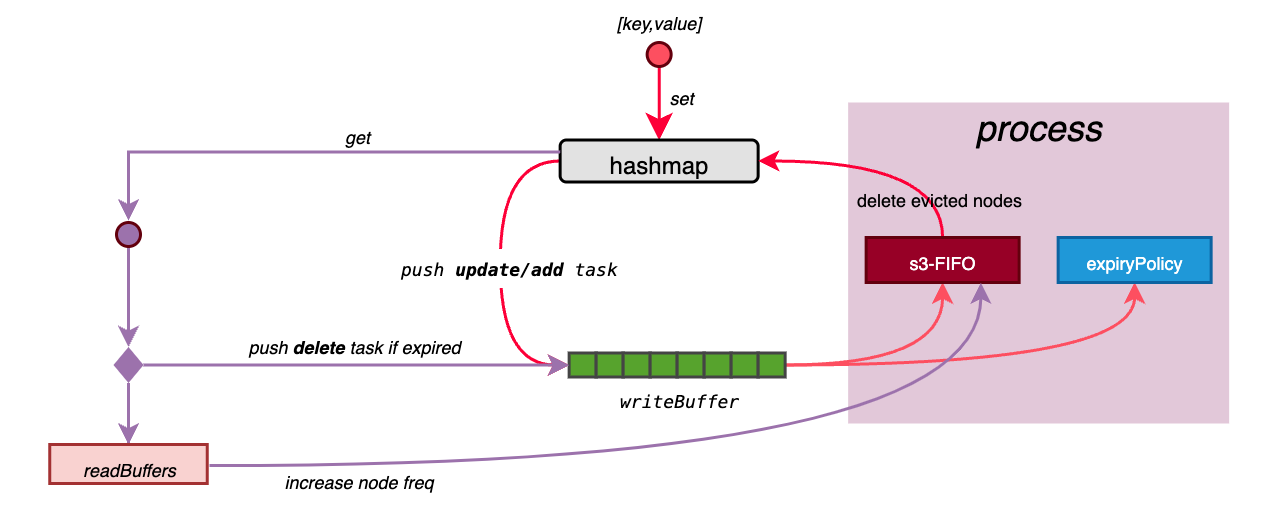
添加node时需要同时处理node add/update事件。
func (c *Cache[K, V]) set(key K, value V, expiration uint32, onlyIfAbsent bool) bool {
//限制node的cost大小,过大会占用更多的缓存空间
cost := c.costFunc(key, value)
if int(cost) > c.policy.MaxAvailableCost() {
c.stats.IncRejectedSets()
return false
}
n := c.nodeManager.Create(key, value, expiration, cost)
//只添加不存在的节点
if onlyIfAbsent {
//res == nil说明是新增的node
res := c.hashmap.SetIfAbsent(n)
if res == nil {
// 将node添加事件添加到writeBuffer中
c.writeBuffer.Push(newAddTask(n))
return true
}
c.stats.IncRejectedSets() //如果node存在,则不作任何处理,增加rejected统计
return false
}
//evicted != nil表示对已有node进行了更新,反之则表示新加的node
evicted := c.hashmap.Set(n)
if evicted != nil {
// update,将老节点evicted设置为无效状态,并将node更新事件添加到writeBuffer中
evicted.Die()
c.writeBuffer.Push(newUpdateTask(n, evicted))
} else {
// 将node添加事件添加到writeBuffer中
c.writeBuffer.Push(newAddTask(n))
}
return true
}
复制Get需要处理删除过期node事件。
// GetNode returns the node associated with the key in this cache.
func (c *Cache[K, V]) GetNode(key K) (node.Node[K, V], bool) {
n, ok := c.hashmap.Get(key)
if !ok || !n.IsAlive() { //不返回非active状态的node
c.stats.IncMisses()
return nil, false
}
//如果node过期,需要将node删除事件添加到writeBuffer中,后续由其他goroutine执行数据删除
if n.HasExpired() {
c.writeBuffer.Push(newDeleteTask(n))
c.stats.IncMisses()
return nil, false
}
//在读取node之后的动作,获取热点node,并增加s3-FIFO node的freq
c.afterGet(n)
//增加命中统计
c.stats.IncHits()
return n, true
}
复制在成功读取node之后,需要处理热点nodes:
func (c *Cache[K, V]) afterGet(got node.Node[K, V]) {
idx := c.getReadBufferIdx()
//获取热点nodes
pb := c.readBuffers[idx].Add(got)
if pb != nil {
c.evictionMutex.Lock()
//增加nodes的freq
c.policy.Read(pb.Returned)
c.evictionMutex.Unlock()
//已经处理完热点数据,清理存放热点数据的buffer
c.readBuffers[idx].Free()
}
}
复制另外还有一种获取方法,此方法中不会触发驱逐策略,即不会用到readBuffers和s3-FIFO:
func (c *Cache[K, V]) GetNodeQuietly(key K) (node.Node[K, V], bool) {
n, ok := c.hashmap.Get(key)
if !ok || !n.IsAlive() || n.HasExpired() {
return nil, false
}
return n, true
}
复制otter有两种途径来处理缓存中的数据,一种是通过处理writeBuffer中的事件来对缓存数据进行增删改,另一种是定期清理过期数据。
writeBuffer中保存了缓存读写过程中的事件。
需要注意的是hashmap中的数据会按照add/delete操作实时更新,只有涉及到s3-FIFO驱逐的数据才会通过writeBuffer异步更新。
func (c *Cache[K, V]) process() {
bufferCapacity := 64
buffer := make([]task[K, V], 0, bufferCapacity)
deleted := make([]node.Node[K, V], 0, bufferCapacity)
i := 0
for {
//从writeBuffer中获取一个事件
t := c.writeBuffer.Pop()
//调用Cache.Clear()或Cache.Close()时会清理cache。Cache.Clear()和Cache.Close()中都会清理hashmap和readBuffers
//这里清理writebuffer和s3-FIFO
if t.isClear() || t.isClose() {
buffer = clearBuffer(buffer)
c.writeBuffer.Clear()
c.evictionMutex.Lock()
c.policy.Clear()
c.expiryPolicy.Clear()
if t.isClose() {
c.isClosed = true
}
c.evictionMutex.Unlock()
//清理完成
c.doneClear <- struct{}{}
//如果是close则直接退出,否则(clear)会继续处理writeBuffer中的事件
if t.isClose() {
break
}
continue
}
//这里使用了批量处理事件的方式
buffer = append(buffer, t)
i++
if i >= bufferCapacity {
i -= bufferCapacity
c.evictionMutex.Lock()
for _, t := range buffer {
n := t.node()
switch {
case t.isDelete()://删除事件,发生在直接删除数据或数据过期的情况下。删除expiryPolicy,和s3-FIFO中的数据
c.expiryPolicy.Delete(n)
c.policy.Delete(n)
case t.isAdd()://添加事件,发送在新增数据的情况下,将数据添加到expiryPolicy和s3-FIFO中
if n.IsAlive() {
c.expiryPolicy.Add(n)
deleted = c.policy.Add(deleted, n) //添加驱逐数据
}
case t.isUpdate()://更新事件,发生在添加相同key的数据的情况下,此时需删除老数据,并添加活动状态的新数据
oldNode := t.oldNode()
c.expiryPolicy.Delete(oldNode)
c.policy.Delete(oldNode)
if n.IsAlive() {
c.expiryPolicy.Add(n)
deleted = c.policy.Add(deleted, n) //添加驱逐数据
}
}
}
//从expiryPolicy中删除s3-FIFO驱逐的数据
for _, n := range deleted {
c.expiryPolicy.Delete(n)
}
c.evictionMutex.Unlock()
for _, t := range buffer {
switch {
case t.isDelete():
n := t.node()
c.notifyDeletion(n.Key(), n.Value(), Explicit)
case t.isUpdate():
n := t.oldNode()
c.notifyDeletion(n.Key(), n.Value(), Replaced)
}
}
//从hashmap中删除s3-FIFO驱逐的数据
for _, n := range deleted {
c.hashmap.DeleteNode(n)
n.Die()
c.notifyDeletion(n.Key(), n.Value(), Size)
c.stats.IncEvictedCount()
c.stats.AddEvictedCost(n.Cost())
}
buffer = clearBuffer(buffer)
deleted = clearBuffer(deleted)
if cap(deleted) > 3*bufferCapacity {
deleted = make([]node.Node[K, V], 0, bufferCapacity)
}
}
}
}
复制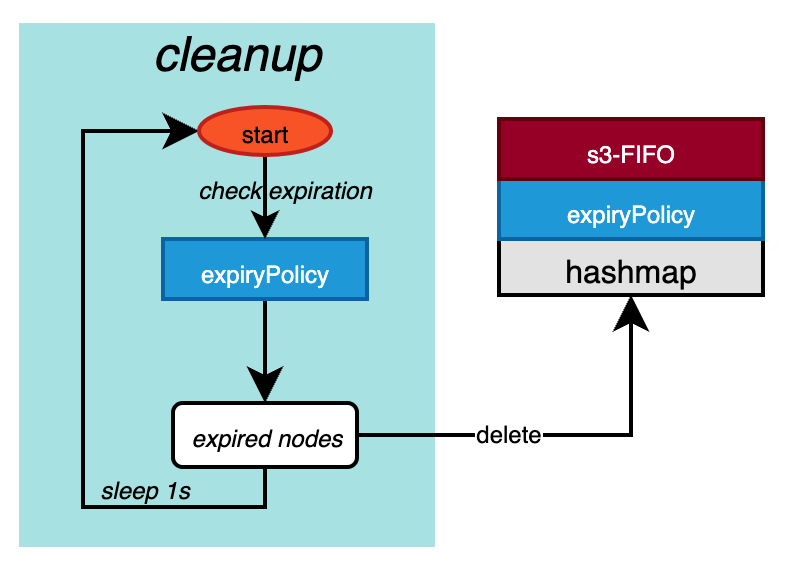
cleanup是一个单独的goroutine,用于定期处理Cache.hashmap中的过期数据。在调用Cache.Get时会判断并删除(通过向writeBuffer中写入deleteReason事件,由process goroutine异步删除)s3-FIFO(Cache.policy)中的过期数据。
另外无需处理readbuffers中的过期数据,因为从readbuffers读取到热点数据之后,只会增加这些数据的freq,随后会清空存放热点数据的空间,不会对其他组件的数据造成影响。
func (c *Cache[K, V]) cleanup() {
bufferCapacity := 64
expired := make([]node.Node[K, V], 0, bufferCapacity)
for {
time.Sleep(time.Second) //每秒尝试清理一次过期数据
c.evictionMutex.Lock()
if c.isClosed {
return
}
//删除expiryPolicy、policy和hashmap中的过期数据
expired = c.expiryPolicy.RemoveExpired(expired)
for _, n := range expired {
c.policy.Delete(n)
}
c.evictionMutex.Unlock()
for _, n := range expired {
c.hashmap.DeleteNode(n)
n.Die()
c.notifyDeletion(n.Key(), n.Value(), Expired)
}
expired = clearBuffer(expired)
if cap(expired) > 3*bufferCapacity {
expired = make([]node.Node[K, V], 0, bufferCapacity)
}
}
}
复制这里还有一些跟作者的互动: