作者:来自 vivo 互联网大数据团队-Ye Jidong
本文主要介绍了由FileSystem类引起的一次线上内存泄漏导致内存溢出的问题分析解决全过程。
内存泄漏定义(memory leak):一个不再被程序使用的对象或变量还在内存中占有存储空间,JVM不能正常回收改对象或者变量。一次内存泄漏似乎不会有大的影响,但内存泄漏堆积后的后果就是内存溢出。
内存溢出(out of memory):是指在程序运行过程中,由于分配的内存空间不足或使用不当等原因,导致程序无法继续执行的一种错误,此时就会报错OOM,即所谓的内存溢出。
周末小叶正在王者峡谷乱杀,手机突然收到大量机器CPU告警,CPU使用率超过80%就会告警,同时也收到该服务的Full GC告警。该服务是小叶项目组非常重要的服务,小叶赶紧放下手中的王者荣耀打开电脑查看问题。


图1.1 CPU告警 Full GC告警
因为服务CPU和Full GC告警了,打开服务监控查看CPU监控和Full GC监控,可以看到两个监控在同一时间点都有一个异常凸起,可以看到在CPU告警的时候,Full GC特别频繁,猜测可能是Full GC导致的CPU使用率上升告警。
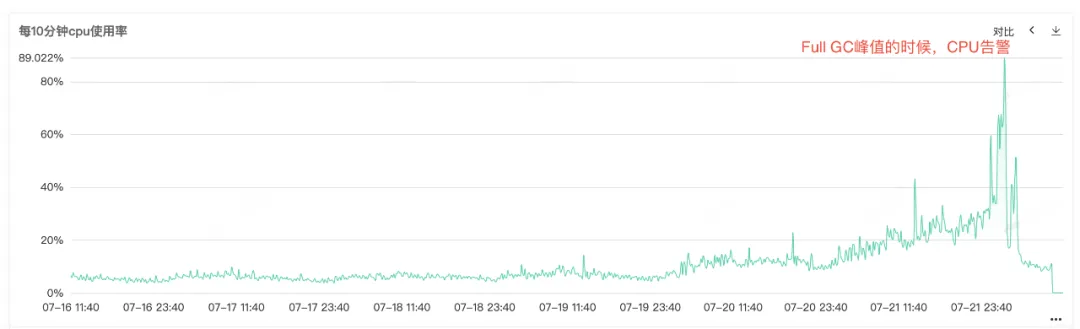
图2.1 CPU使用率
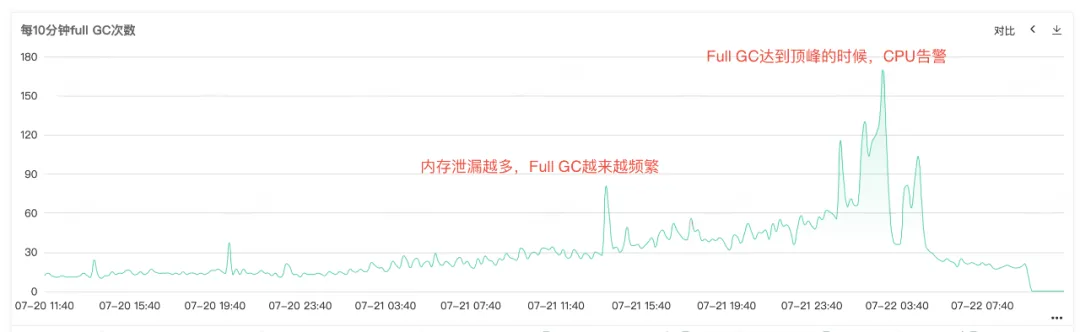
图2.2 Full GC次数
从Full Gc频繁可以知道服务的内存回收肯定存在问题,故查看服务的堆内存、老年代内存、年轻代内存的监控,从老年代的常驻内存图可以看到,老年代的常驻内存越来越多,老年代对象无法回收,最后常驻内存全部被占满,可以看出明显的内存泄漏。
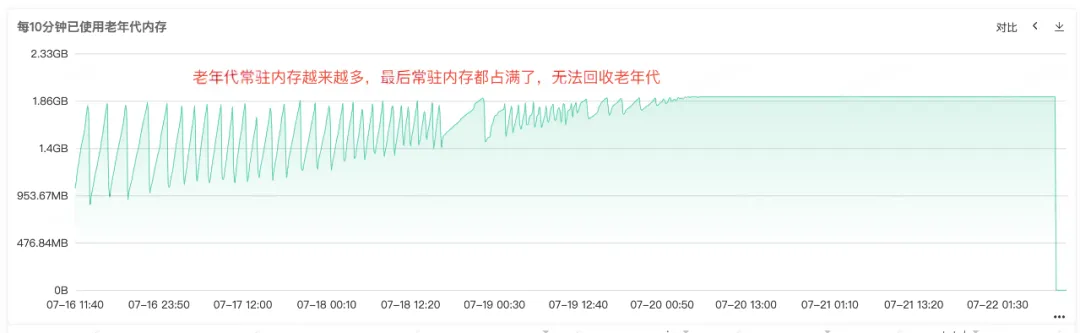
图2.3 老年代内存
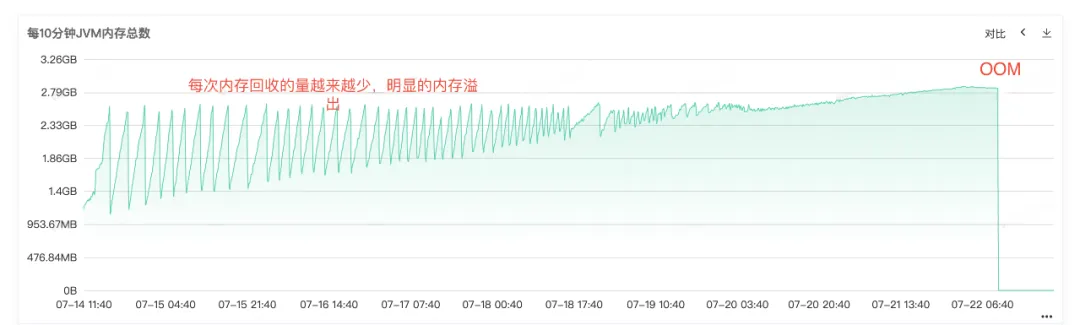
图2.4 JVM内存
从线上的错误日志也可以明确知道服务最后是OOM了,所以问题的根本原因是内存泄漏导致内存溢出OOM,最后导致服务不可用。

图2.5 OOM日志
在明确问题原因为内存泄漏之后,我们第一时间就是dump服务内存快照,将dump文件导入至MAT(Eclipse Memory Analyzer)进行分析。Leak Suspects 进入疑似泄露点视图。
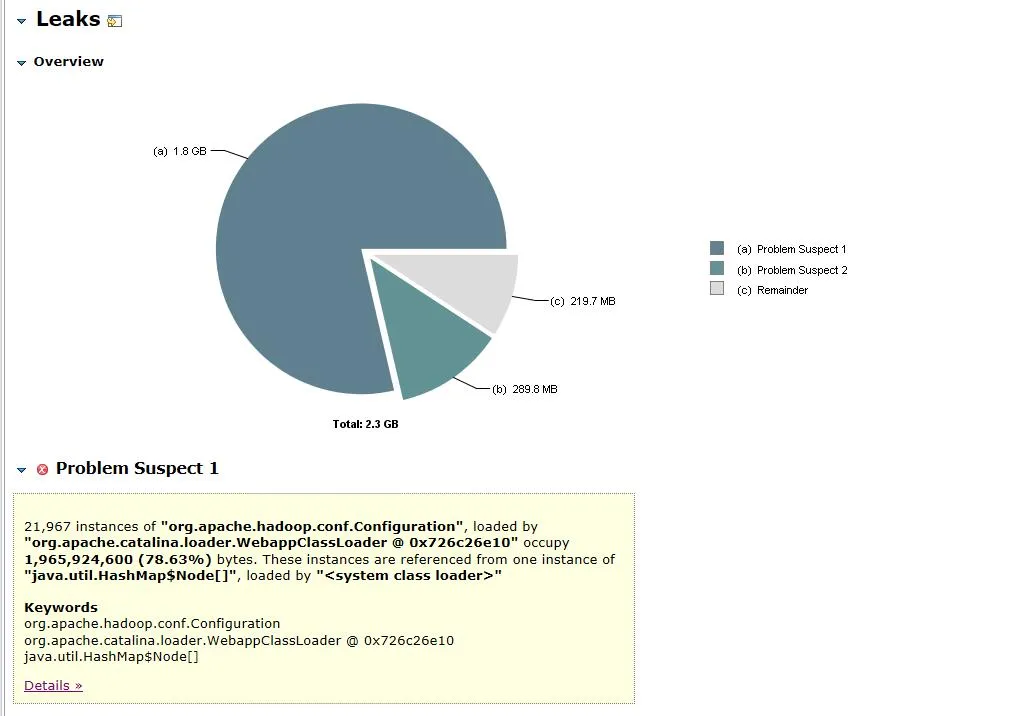
图3.1 内存对象分析
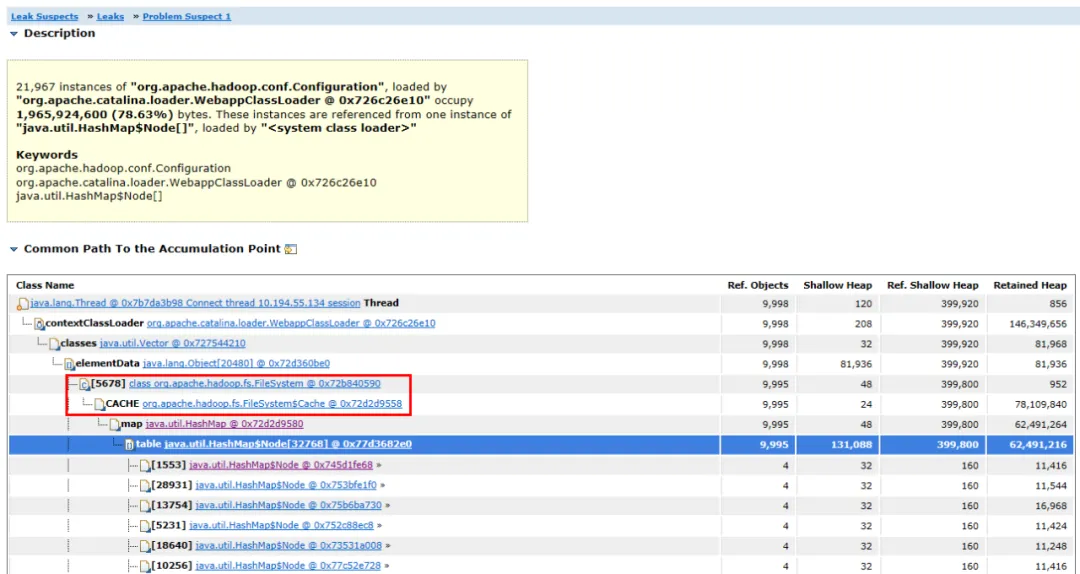
图3.2 对象链路图
打开的dump文件如图3.1所示,2.3G的堆内存 其中 org.apache.hadoop.conf.Configuration对象占了1.8G,占了整个堆内存的78.63%。
展开该对象的关联对象和路径,可以看到主要占用的对象为HashMap,该HashMap由FileSystem.Cache对象持有,再上层就是FileSystem。可以猜想内存泄漏大概率跟FileSystem有关。
找到内存泄漏的对象,那么接下来一步就是找到内存泄漏的代码。
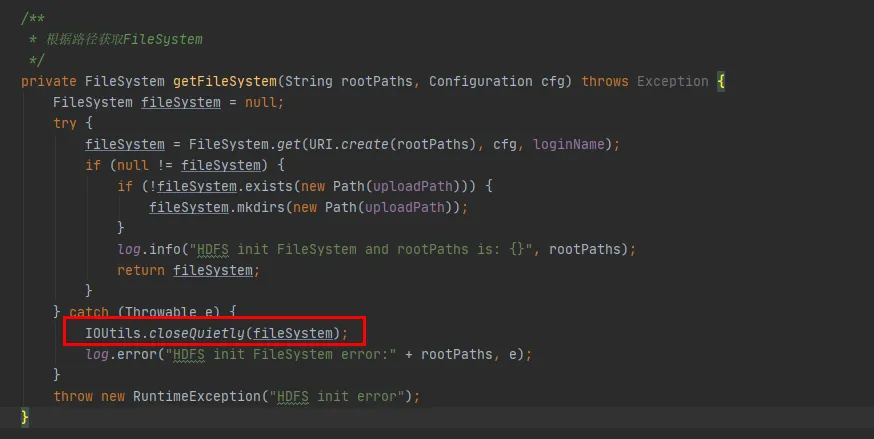
在图3.3我们的代码里面可以发现这么一段代码,在每次与hdfs交互时,都会与hdfs建立一次连接,并创建一个FileSystem对象。但在使用完FileSystem对象之后并未调用close()方法释放连接。
但是此处的Configuration实例和FileSystem实例都是局部变量,在该方法执行完成之后,这两个对象都应该是可以被JVM回收的,怎么会导致内存泄漏呢?
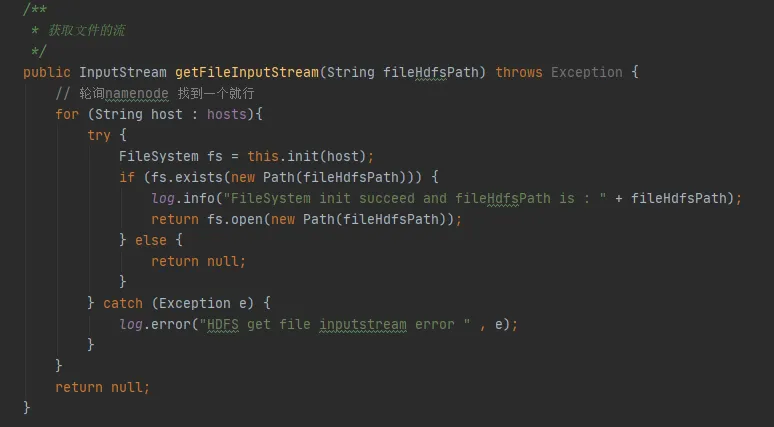
图3.3
(1)猜想一:FileSystem是不是有常量对象?
接下里我们就查看FileSystem类的源码,FileSystem的init和get方法如下:
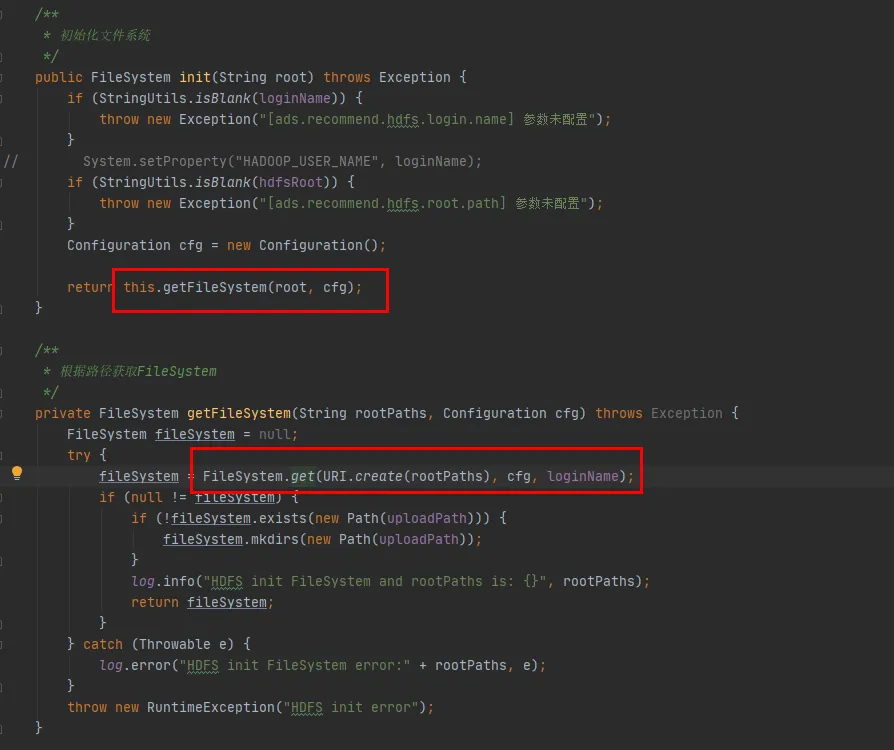

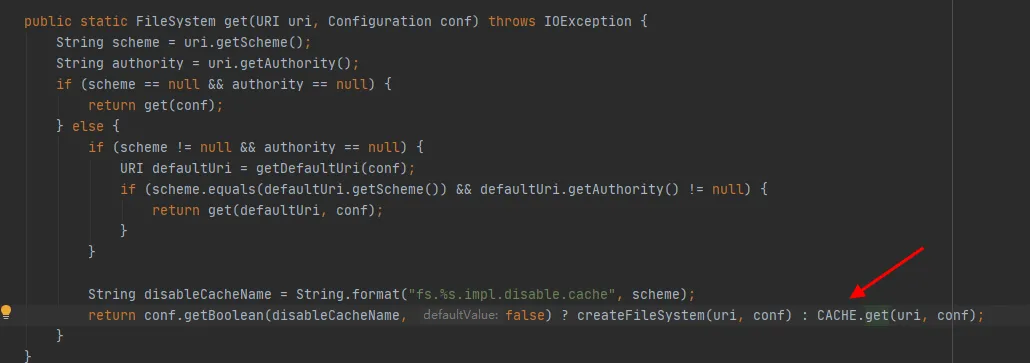
图3.4
从图3.4最后一行代码可以看到,FileSystem类存在一个CACHE,通过disableCacheName控制是否从该缓存拿对象。该参数默认值为false。也就是默认情况下会通过CACHE对象返回FileSystem。

图3.5
从图3.5可以看到CACHE为FileSystem类的静态对象,也就是说,该CACHE对象会一直存在不会被回收,确实存在常量对象CACHE,猜想一得到验证。
那接下来看一下CACHE.get方法:
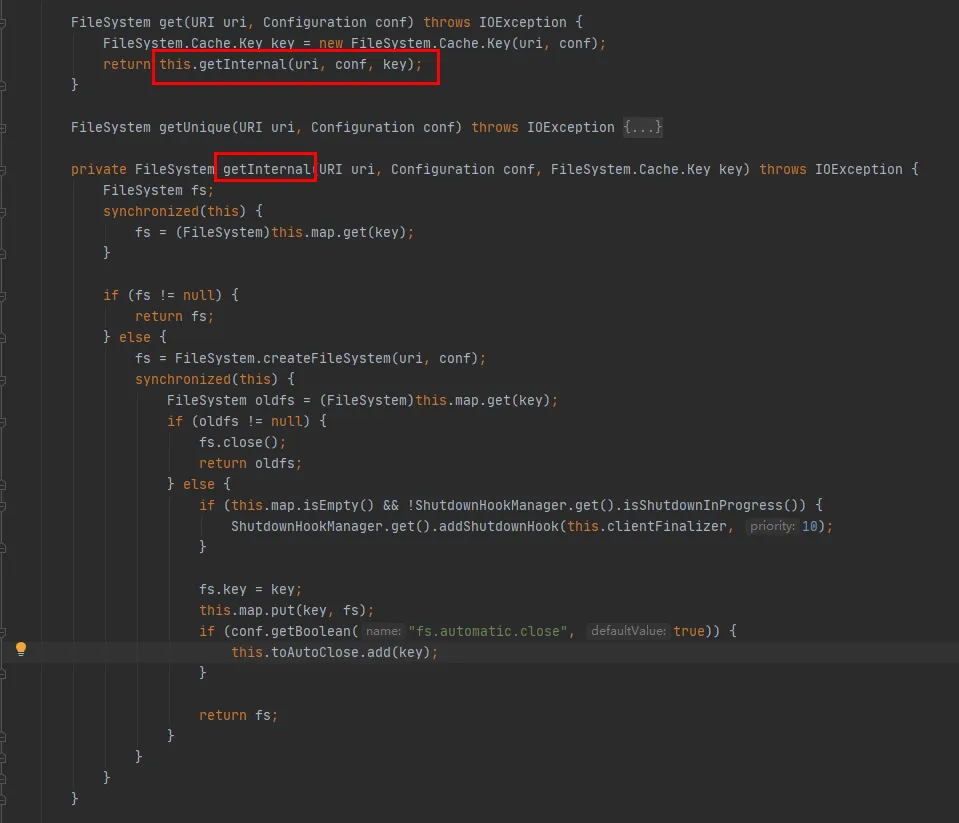
从这段代码中可以看出:
在Cache类内部维护了一个Map,该Map用于缓存已经连接好的FileSystem对象,Map的Key为Cache.Key对象。每次都会通过Cache.Key获取FileSystem,如果未获取到,才会继续创建的流程。
在Cache类内部维护了一个Set(toAutoClose),该Set用于存放需自动关闭的连接。在客户端关闭时会自动关闭该集合中的连接。
每次创建的FileSystem都会以Cache.Key为key,FileSystem为Value存储在Cache类中的Map中。那至于在缓存时候是否对于相同hdfs URI是否会存在多次缓存,就需要查看一下Cache.Key的hashCode方法了。
Cache.Key的hashCode方法如下:

schema和authority变量为String类型,如果在相同的URI情况下,其hashCode是一致。而unique该参数的值每次都是0。那么Cache.Key的hashCode就由ugi.hashCode()决定。
由以上代码分析可以梳理得到:
业务代码与hdfs交互过程中,每次交互都会新建一个FileSystem连接,结束时并未关闭FileSystem连接。
FileSystem内置了一个static的Cache,该Cache内部有一个Map,用于缓存已经创建连接的FileSystem。
参数fs.hdfs.impl.disable.cache,用于控制FileSystem是否需要缓存,默认情况下是false,即缓存。
Cache中的Map,Key为Cache.Key类,该类通过schem,authority,ugi,unique 4个参数来确定一个Key,如上Cache.Key的hashCode方法。
(2)猜想二:FileSystem同样hdfs URI是不是多次缓存?
FileSystem.Cache.Key构造函数如下所示:ugi由UserGroupInformation的getCurrentUser()决定。

继续看UserGroupInformation的getCurrentUser()方法,如下:

其中比较关键的就是是否能通过AccessControlContext获取到Subject对象。在本例中通过get(final URI uri, final Configuration conf,final String user)获取时候,在debug调试时,发现此处每次都能获取到一个新的Subject对象。也就是说相同的hdfs路径每次都会缓存一个FileSystem对象。
猜想二得到验证:同一个hdfs URI会进行多次缓存,导致缓存快速膨胀,并且缓存没有设置过期时间和淘汰策略,最终导致内存溢出。
(3)FileSystem为什么会重复缓存?
那为什么会每次都获取到一个新的Subject对象呢,我们接着往下看一下获取AccessControlContext的代码,如下:
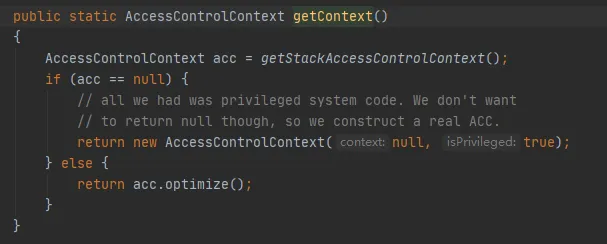
其中比较关键的是getStackAccessControlContext方法,该方法调用了Native方法,如下:

该方法会返回当前堆栈的保护域权限的AccessControlContext对象。
我们通过图3.6 get(final URI uri, final Configuration conf,final String user) 方法可以看到,如下:
先通过UserGroupInformation.getBestUGI方法获取了一个UserGroupInformation对象。
然后在通过UserGroupInformation的doAs方法去调用了get(URI uri, Configuration conf)方法
图3.7 UserGroupInformation.getBestUGI方法的实现,此处关注一下传入的两个参数ticketCachePath,user。ticketCachePath是获取配置hadoop.security.kerberos.ticket.cache.path的值,在本例中该参数未配置,因此ticketCachePath为空。user参数是本例中传入的用户名。
ticketCachePath为空,user不为空,因此最终会执行图3.7的createRemoteUser方法

图3.6

图3.7
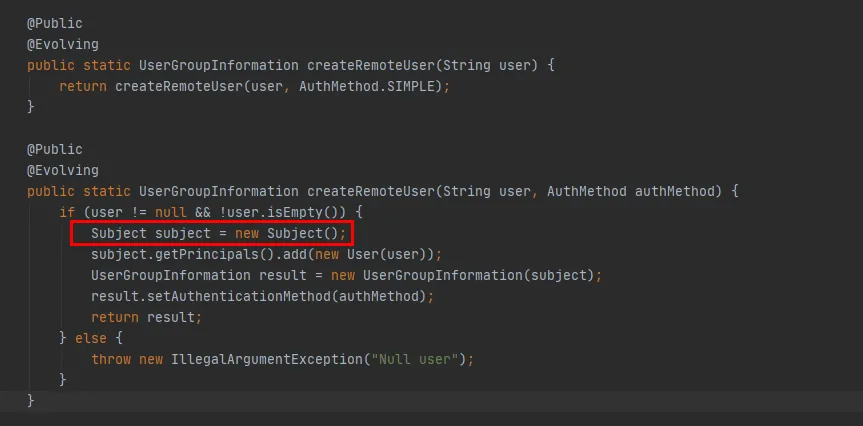
图3.8
从图3.8标红的代码可以看到在createRemoteUser方法中,创建了一个新的Subject对象,并通过该对象创建了UserGroupInformation对象。至此,UserGroupInformation.getBestUGI方法执行完成。
接下来看一下UserGroupInformation.doAs方法(FileSystem.get(final URI uri, final Configuration conf, final String user)执行的最后一个方法),如下:
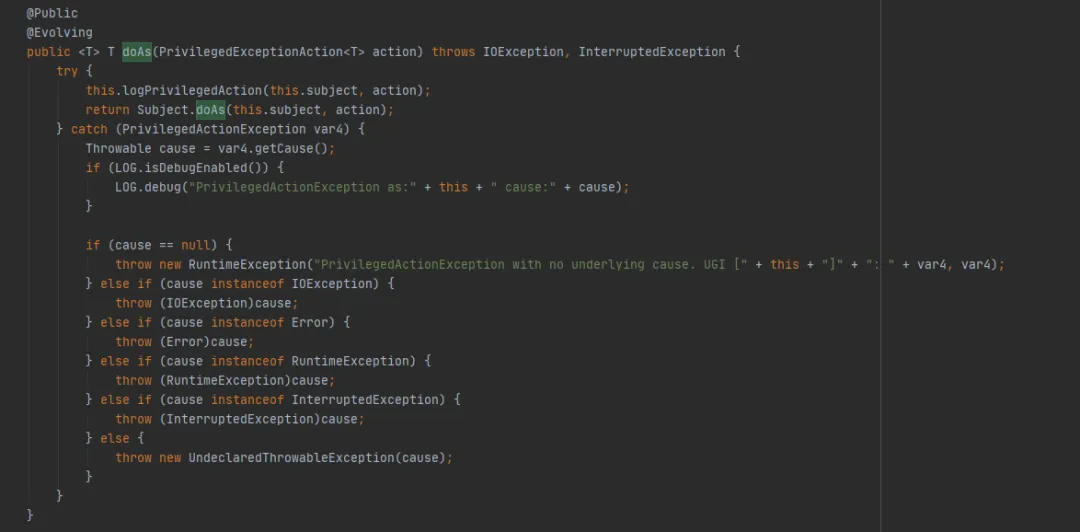
然后在调用Subject.doAs方法,如下:
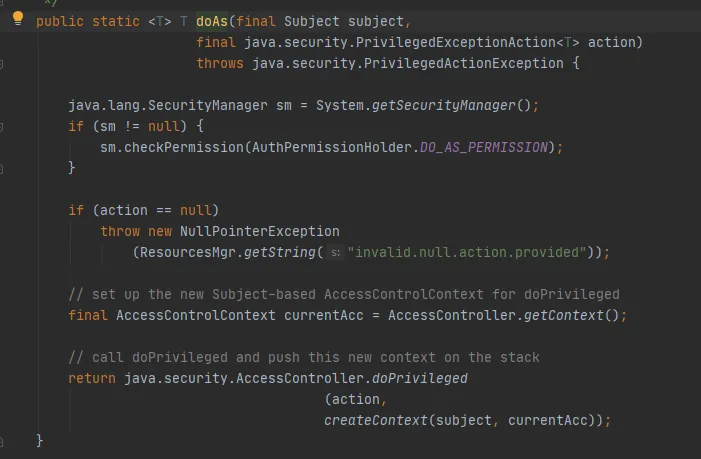
最后在调用AccessController.doPrivileged方法,如下:
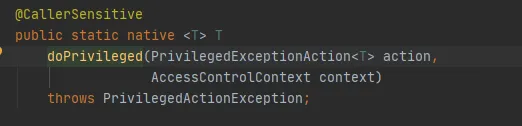
该方法为Native方法,该方法会使用指定的AccessControlContext来执行PrivilegedExceptionAction,也就是调用该实现的run方法。即FileSystem.get(uri, conf)方法。
至此,就能够解释在本例中,通过get(final URI uri, final Configuration conf,final String user) 方法创建FileSystem时,每次存入FileSystem的Cache中的Cache.key的hashCode都不一致的情况了。
小结一下:
在通过get(final URI uri, final Configuration conf,final String user)方法创建FileSystem时,由于每次都会创建新的UserGroupInformation和Subject对象。
在Cache.Key对象计算hashCode时,影响计算结果的是调用了UserGroupInformation.hashCode方法。
UserGroupInformation.hashCode方法,计算为:System.identityHashCode(subject)。即如果Subject是同一个对象则返回相同的hashCode,由于在本例中每次都不一样,因此计算的hashCode不一致。
综上,就导致每次计算Cache.key的hashCode不一致,便会重复写入FileSystem的Cache。
(4)FileSystem的正确用法
从上述分析,既然FileSystem.Cache都没有起到应起的作用,那为什么要设计这个Cache呢。其实只是我们的用法没用对而已。
在FileSystem中,有两个重载的get方法:
public static FileSystem get(final URI uri, final Configuration conf, final String user)
public static FileSystem get(URI uri, Configuration conf)复制
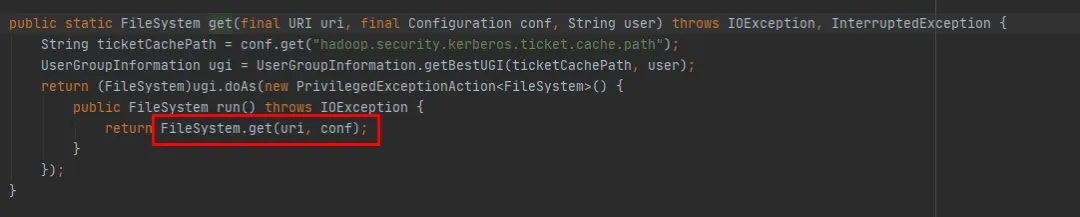
我们可以看到 FileSystem get(final URI uri, final Configuration conf, final String user)方法最后是调用FileSystem get(URI uri, Configuration conf)方法的,区别在于FileSystem get(URI uri, Configuration conf)方法于缺少也就是缺少每次新建Subject的的操作。

图3.9
没有新建Subject的的操作,那么图3.9 中Subject为null,会走最后的getLoginUser方法获取loginUser。而loginUser是静态变量,所以一旦该loginUser对象初始化成功,那么后续会一直使用该对象。UserGroupInformation.hashCode方法将会返回一样的hashCode值。也就是能成功的使用到缓存在FileSystem的Cache。

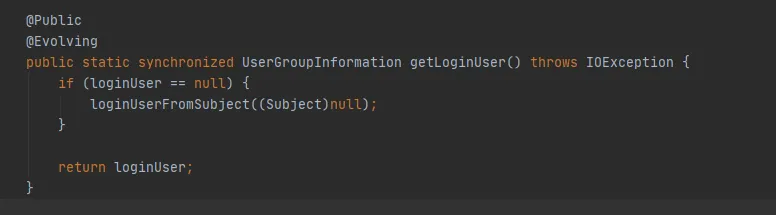
图3.10
经过前面的介绍,如果要解决FileSystem 存在的内存泄露问题,我们有以下两种方式:
(1)使用public static FileSystem get(URI uri, Configuration conf):
该方法是能够使用到FileSystem的Cache的,也就是说对于同一个hdfs URI是只会有一个FileSystem连接对象的。
通过System.setProperty("HADOOP_USER_NAME", "hive")方式设置访问用户。
默认情况下fs.automatic.close=true,即所有的连接都会通过ShutdownHook关闭。
(2)使用public static FileSystem get(final URI uri, final Configuration conf, final String user):
该方法如上分析,会导致FileSystem的Cache失效,且每次都会添加至Cache的Map中,导致不能被回收。
在使用时,一种方案是:保证对于同一个hdfs URI只会存在一个FileSystem连接对象。
另一种方案是:在每次使用完FileSystem之后,调用close方法,该方法会将Cache中的FileSystem删除。
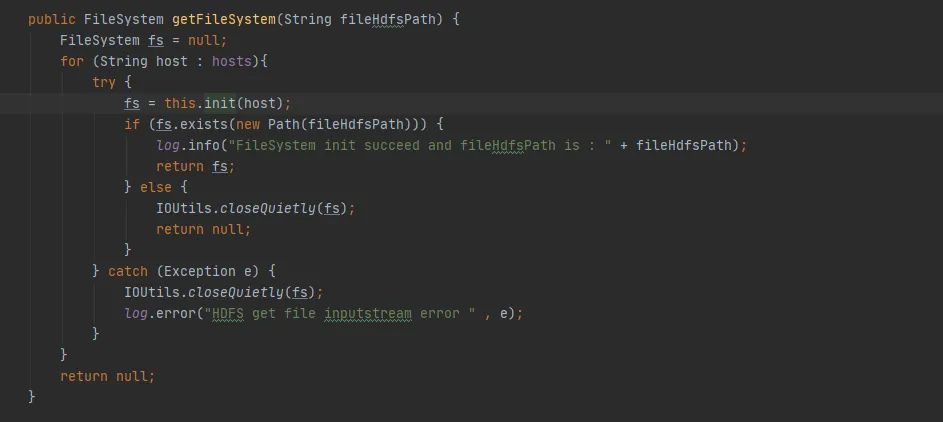
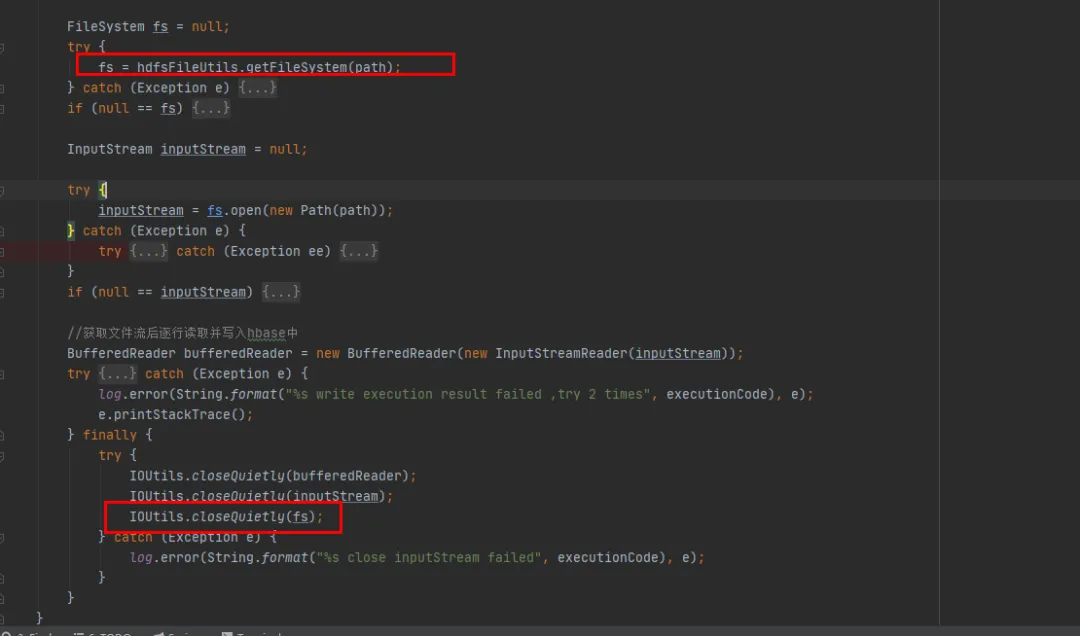
基于我们已有的历史代码最小改动的前提下,我们选择了第二种修改方式。在我们每次使用完FileSystem之后都关闭FileSystem对象。
对代码进行修复发布上线之后,如下图一所示,可以看到修复之后老年代的内存可以正常回收了,至此问题终于全部解决。
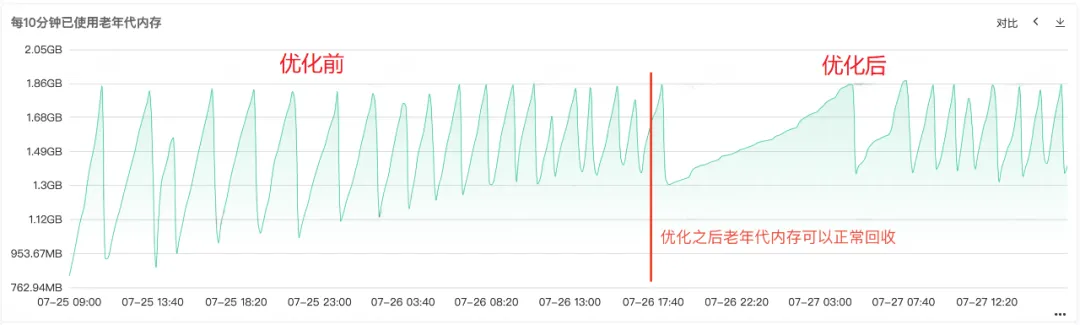
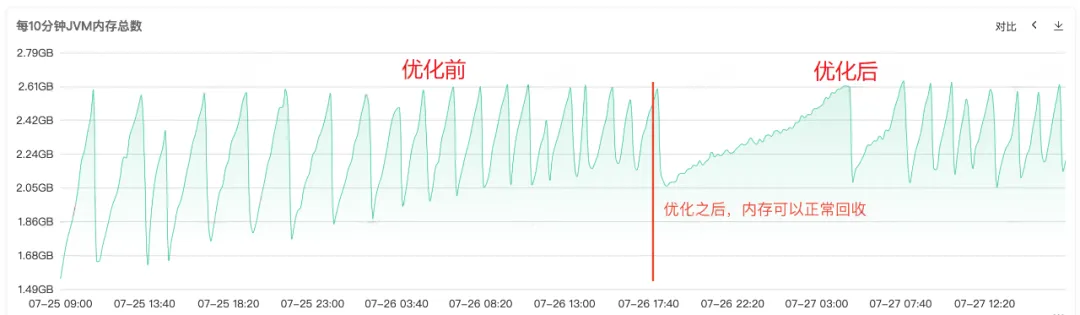
内存溢出是 Java 开发中最常见的问题之一,其原因通常是由于内存泄漏导致内存无法正常回收引起的。在我们这篇文章中,详细介绍一次完整的线上内存溢出的处理过程。
总结一下我们在碰到内存溢出时候的常用解决思路:
(1)生成堆内存文件:
在服务启动命令添加
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/base复制让服务在发生oom时自动dump内存文件,或者使用 jamp 命令dump内存文件。
(2)堆内存分析:使用内存分析工具帮助我们更深入地分析内存溢出问题,并找到导致内存溢出的原因。以下是几个常用的内存分析工具:
Eclipse Memory Analyzer:一款开源的 Java 内存分析工具,可以帮助我们快速定位内存泄漏问题。
VisualVM Memory Analyzer:一个基于图形化界面的工具,可以帮助我们分析java应用程序的内存使用情况。
(3)根据堆内存分析定位到具体的内存泄漏代码。
(4)修改内存泄漏代码,重新发布验证。
内存泄漏是内存溢出的常见原因,但不是唯一原因。常见导致内存溢出问题的原因还是有:超大对象、堆内存分配太小、死循环调用等等都会导致内存溢出问题。
在遇到内存溢出问题时,我们需要多方面思考,从不同角度分析问题。通过我们上述提到的方法和工具以及各种监控帮助我们快速定位和解决问题,提高我们系统的稳定性和可用性。
揭秘In-Context Learning(ICL):大型语言模型如何通过上下文学习实现少样本高效推理[示例设计、ICL机制详解]