如果让你来做一个有状态流式应用的故障恢复,你会如何来做呢?
单机和多机会遇到什么不同的问题?
Flink Checkpoint 是做什么用的?原理是什么?
Checkpoint 是对当前运行状态的完整记录。程序重启后能从 Checkpoint 中恢复出输入数据读取到哪了,各个算子原来的状态是什么,并继续运行程序。
即用于 Flink 的故障恢复。
这种机制保证了实时程序运行时,即使突然遇到异常也能够进行自我恢复。
如果让你来设计,对于流式应用如何做到故障恢复?
我们从最简单的单机单线程看起。
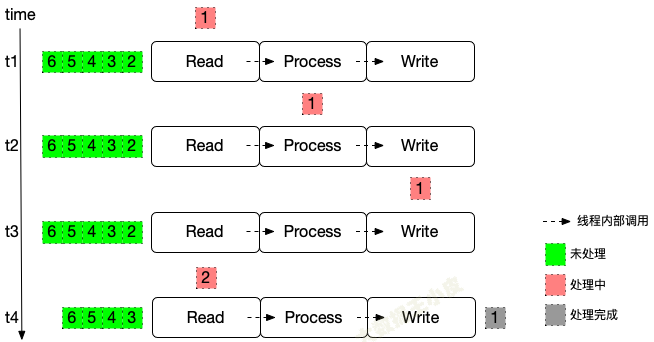
很简单,这种情况下,整个流程一次只处理一条数据。
每个计算节点还是只处理一条数据,但该节点空闲就可以处理下一条数据。
如果还按照一个数据 Write 阶段结束开始保存状态,就会出现问题:
一种解决方式:
这样,各个节点保存的都是相同数据节点时的状态。
故障恢复时,能做到不重复处理数据,也就是精确一次(Exactly-once)。
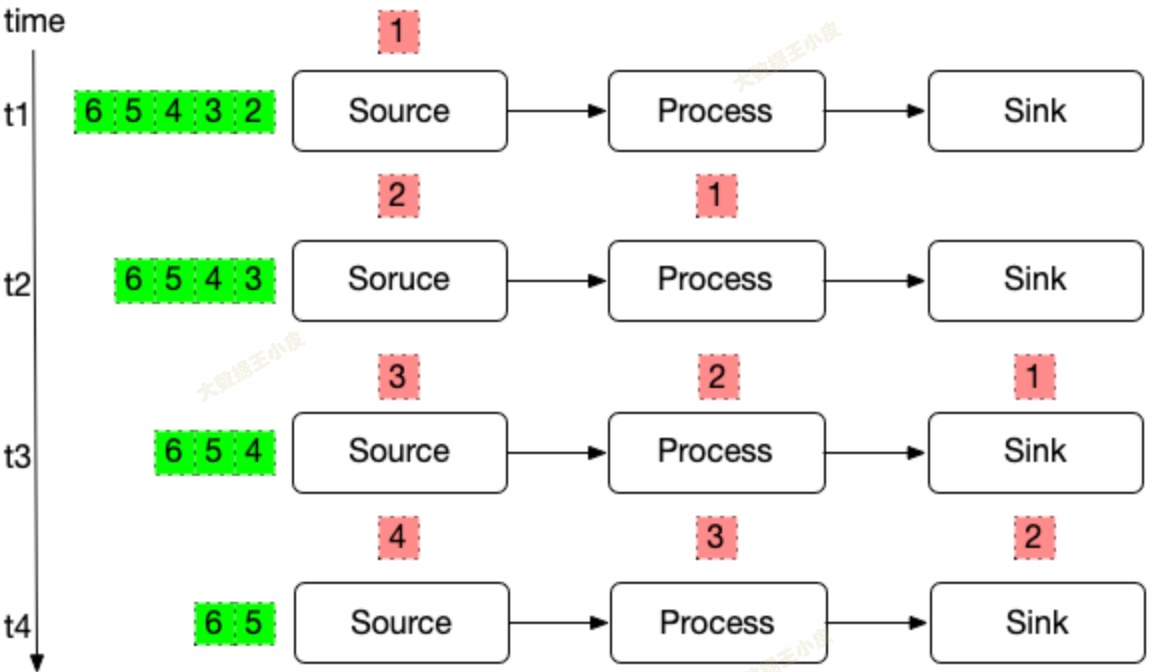
但这里,你可能会发现一个问题:
这里实际是「程序内部精确一次」和「端到端精确一次」。
那么如何做到「端到端精确一次」?
不过以上方法为了做到端到端精确一次,会带来数据延迟问题。(因为要等 Checkpoint 做完,数据才实际可读)。
解决数据延迟有一种方案:
前面的例子中,我们提到了部分一致性级别,这里我们总结下。在流处理中,一致性可以分为 3 个级别:
按区间分:
🤔 如果是你来设计,checkpoint 都需要保留哪些信息,才能让程序恢复执行?
【这里说的就是 state】
考虑一个开发需求:单词计数。
从 kafka 中读数据,处理逻辑是将输入数据拆分成单词,有一个 map 记录各个单词的数量,最后输出。
想要恢复的时候还能接着上次的状态来,要么就需要几个信息:
以及,上述信息应是针对同一条数据的。否则状态就乱了。
那么可以得到,保留的信息是:
| source | 中间算子 | sink |
|---|---|---|
| 已输入的数据(offset) | [<hello, 5>, <world, 10>, ...] | 写出到第几条了 |
随着业务的发展,单机已经不能满足需求了,开始并行分布式的处理。
读取、处理、写出,也不再是一个进程从头到尾干完,会拆分到多个机器上执行。也不再等待一条数据处理完,才处理下一条。
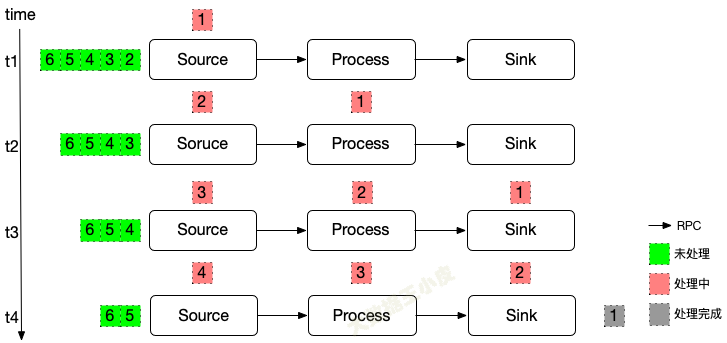
多机多线程,问题就开始变得复杂起来:
🤔 先思考下,如果还用单线程中 barrier 的方式来处理。会遇到什么问题,该如何解决?
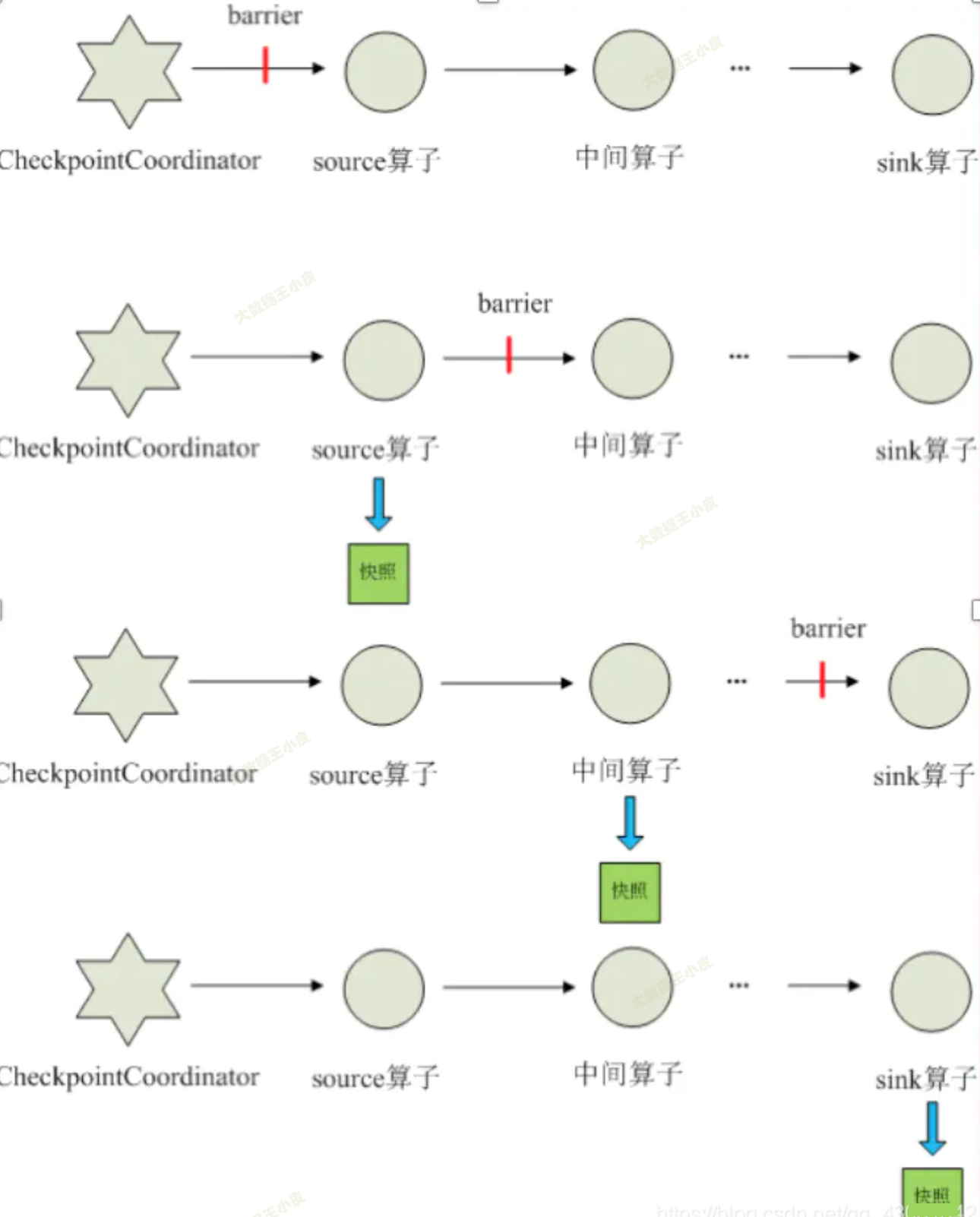
我们还是在数据流中插入 barrier。
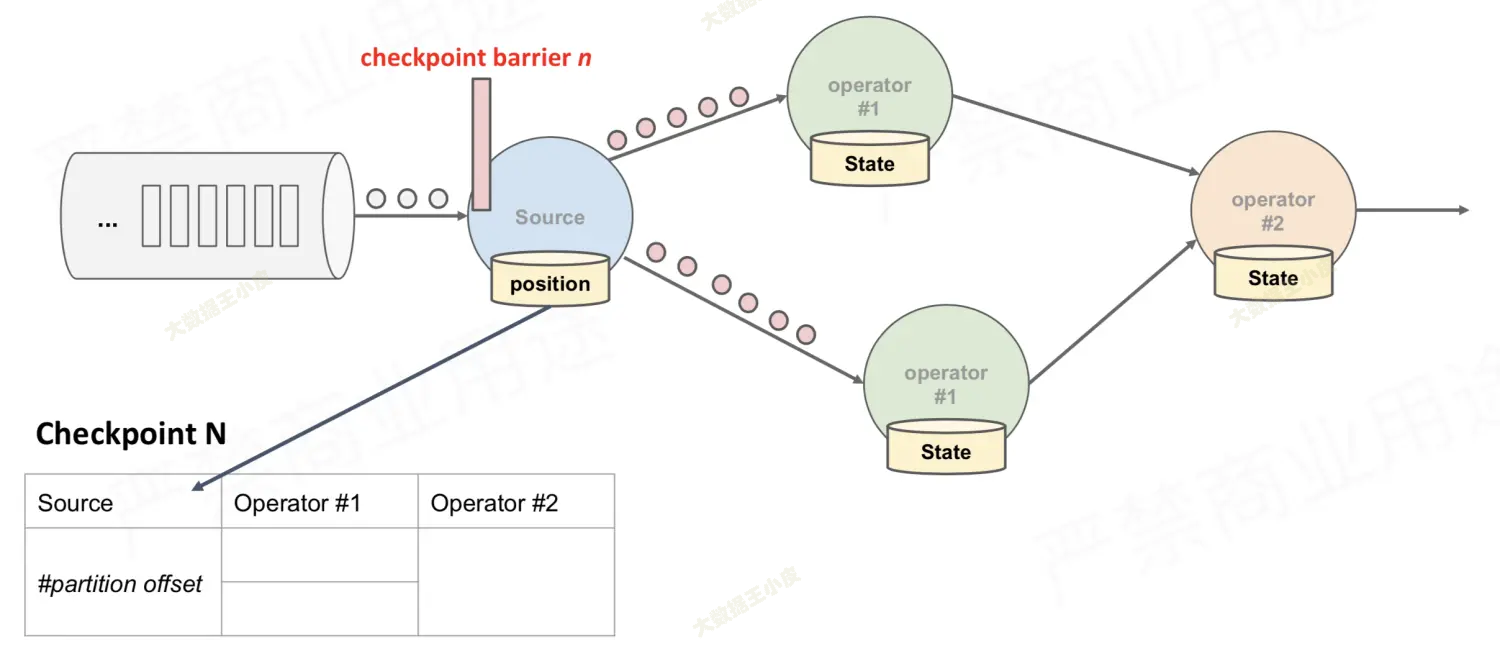
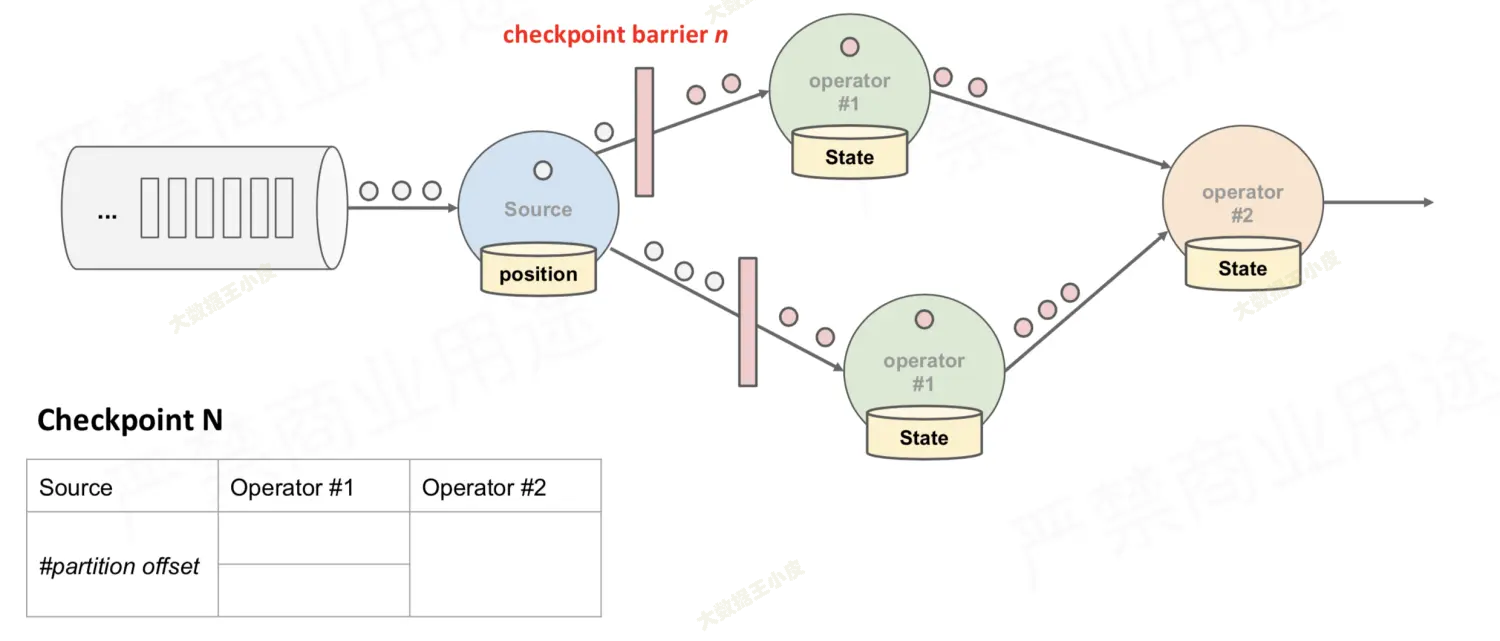
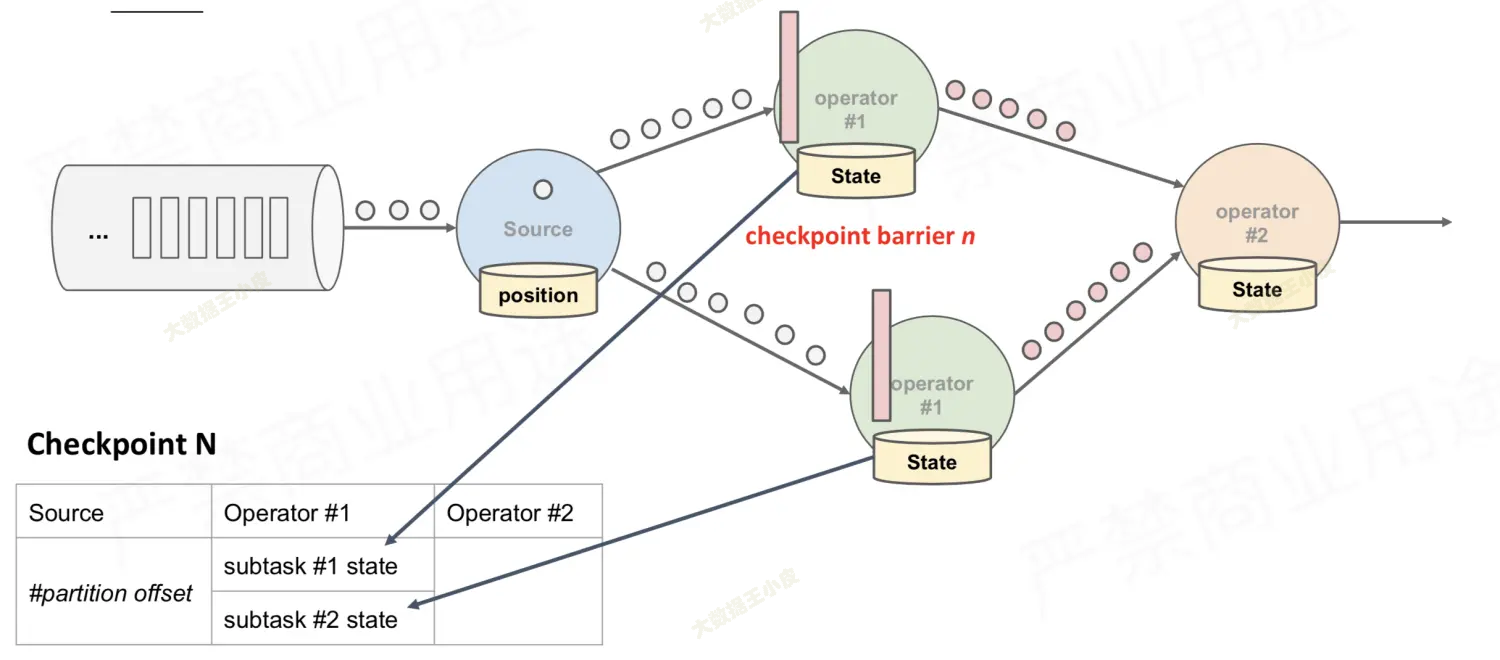
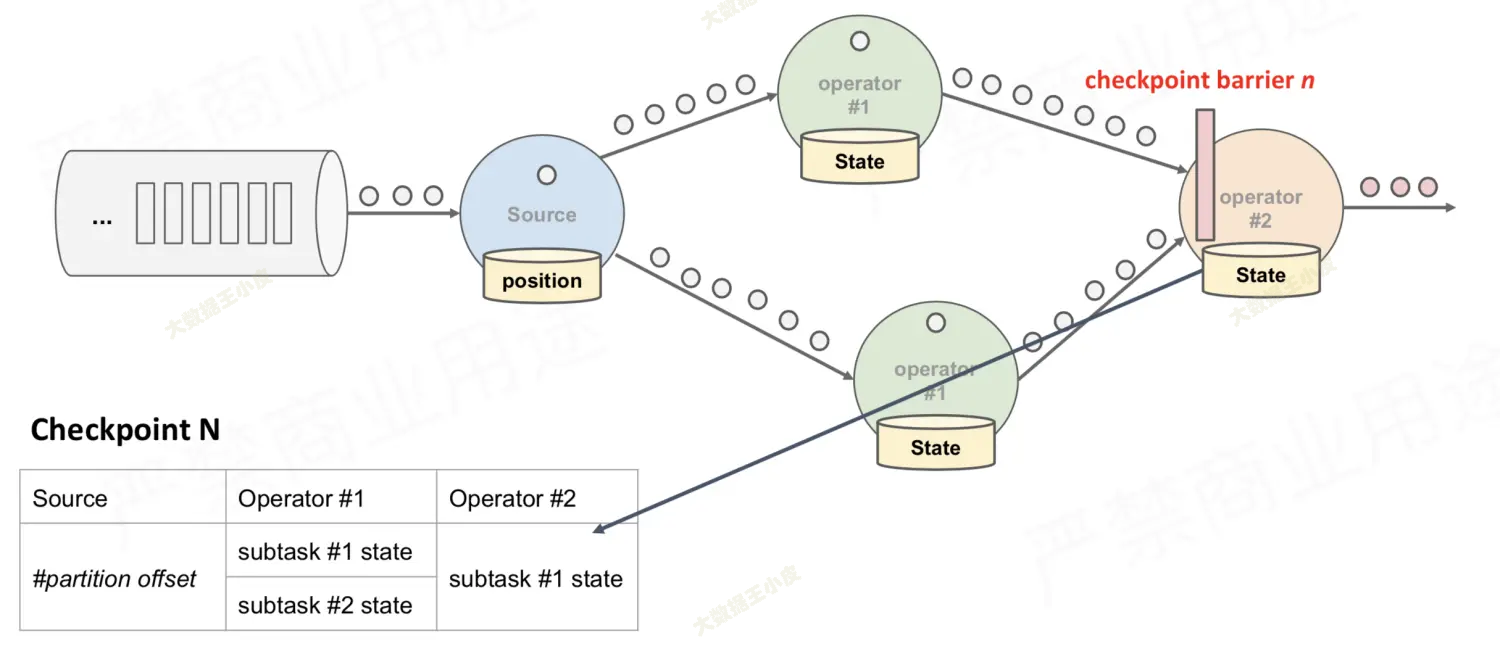
对于多分支合并的情况,在等待所有 barrier 到齐的过程中:
如何在不中断运算的前提下产生快照?
前面做快照,我们假设的是节点收到 barrier 后,就不再接收新数据,把当前节点状态保存后,再接收新数据,然后把 barrier 再向后传递。
那,是否必须这样串行来呢?
那,后面节点保存完了,前面节点还没保存完怎么办?
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 开启 checkpoint,并设置间隔 ms
env.enableCheckpointing(1000);
// 模式 Exactly-Once、At-Least-Once
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 两个 checkpoint 之间最小间隔
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// 超时时间
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 同时执行的 checkpoint 数量(比如上一个还没执行完,下一个已经触发开始了)
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 当用户取消了作业后,是否保留远程存储上的Checkpoint数据
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
复制Flink 开箱即用地提供了两种 Checkpoint 存储类型:
JobManagerCheckpointStorage
FileSystemCheckpointStorage
本节介绍了 Flink Checkpoint 故障恢复机制。从单机单线程,到多机多线程一步步分析如何实现状态保存和故障恢复。
同时对一致性级别进行了探讨,对程序内部和端到端一致性的实现方式给出了可行的方案。
后续会对 Checkpoint 程序内部实现原理进行剖析。
参考文章:
Flink Checkpoint 深入理解-CSDN博客
漫谈 Flink - Why Checkpoint - Ying
Flink之Checkpoint机制-阿里云开发者社区 (图不错)
Flink 状态一致性、端到端的精确一次(ecactly-once)保证 - 掘金
硬核!八张图搞懂 Flink 端到端精准一次处理语义 Exactly-once(深入原理,建议收藏)-腾讯云开发者社区-腾讯云