本文作为下一篇缓存文章的预备知识。
FIFO和LRU都是经典的缓存驱逐算法,在过去几十年中也出现了很多追求更高效率的驱逐算法,如ARC, 2Q, LIRS, TinyLFU。传统观点认为,基于LRU的缓冲未命中率要低于基于FIFO的算法,如CLOCK,这类高级算法通常都是基于LRU的。但基于LRU的算法存在3个问题:1)每个对象需要两个指针,对于包含小对象的负载会产生大量存储开销;2)由于在缓存命中时需要使用锁来将请求的对象放到队列首部,因此无法实现扩展;3)由于是随机写,闪存不友好。
由于很多现代CPU都包含多个核,因此缓存的扩展性意味着它的吞吐量可以随CPU核数的增加而增加。理想情况下,一个缓存的吞吐量和CPU核数呈线性关系。但在基于LRU的算法中,读取操作需要加锁才能更新元数据,因此无法完全利用CPU的计算能力。
可以使用ring buffer来实现FIFO,无需为每个对象分配指向元数据的指针,也无需在每次缓存命中时修改对象的位置,因此不存在可扩展瓶颈。另外FIFO按照先进先出的顺序来驱逐对象,因此是一种闪存友好的访问模式,可以减小闪存写入以及闪存损耗。但FIFO在效率上落后于LRU和一些先进的驱逐算法。
术语"one-hit-wonder ratio"指在一个序列(sequences)中,只被请求一次的对象所占的比例,通常用于CDN中(其存在较大的one-hit-wonder ratio)。虽然one-hit-wonder ratio会因为缓存负载的类型而有所变化,但我们发现越短的请求序列(shorter request sequences,即较少的对象)的one-hit-wonder ratio越高
这里的请求序列可以看做是一个请求样本

上面示例中,在序列长度为17,包含5个对象的场景中,有1个对象(E)仅被访问了一次,其one-hit-wonder ratio为20%;而在序列长度为7(1st~7st)的场景中,有2个对象(C,D)仅被访问了一次,其one-hit-wonder ratio为50%;类似地在序列长度为4(1st~4st)的场景中,其one-hit-wonder ratio为67%.
那么在实际生产中的表现是否和上面示例中一致?下图展示了对来自MSR的一个块缓存(hm_0) trace和来自Twitter的一个key-value 缓存的trace结果。X轴表示对象在trace中的比率(分别使用线性(左图)和对数表示(右图))。
可以看到完整trace的one-hit-wonder ratio(左图X轴为1.00的点)分别为13%(Twitter)和38%(MSR),而包含10%对象的随机子序列的one-hit-wonder ratio(右图X轴为10-1的点)分别为26%(Twitter)和75%(MSR)。
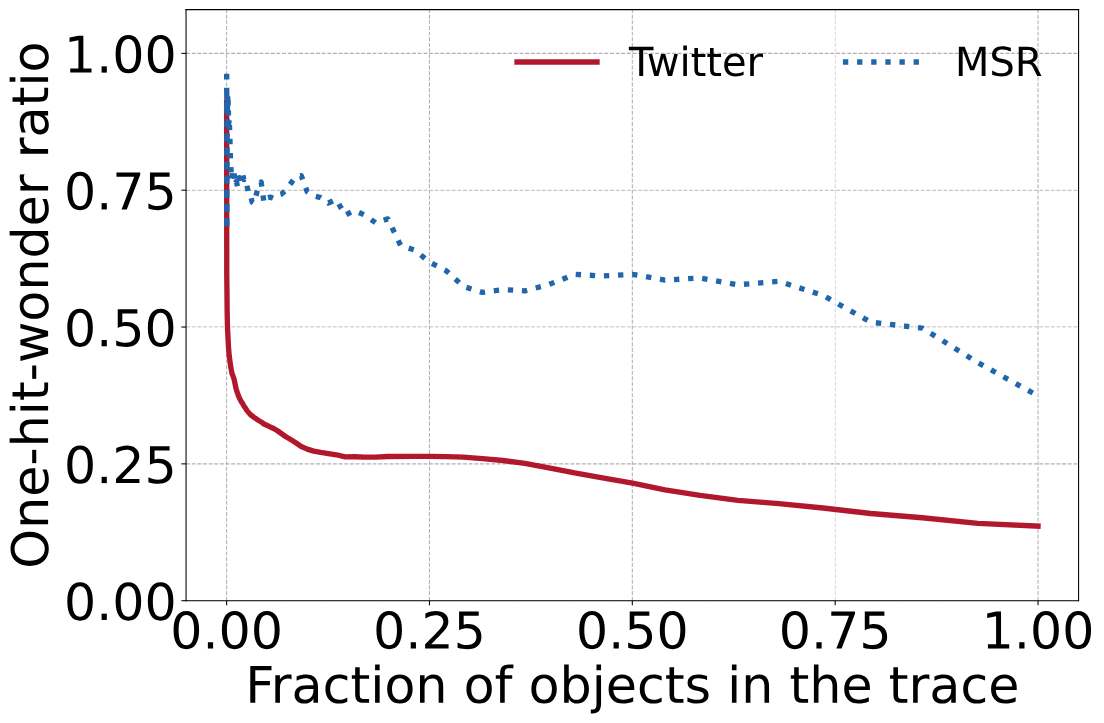
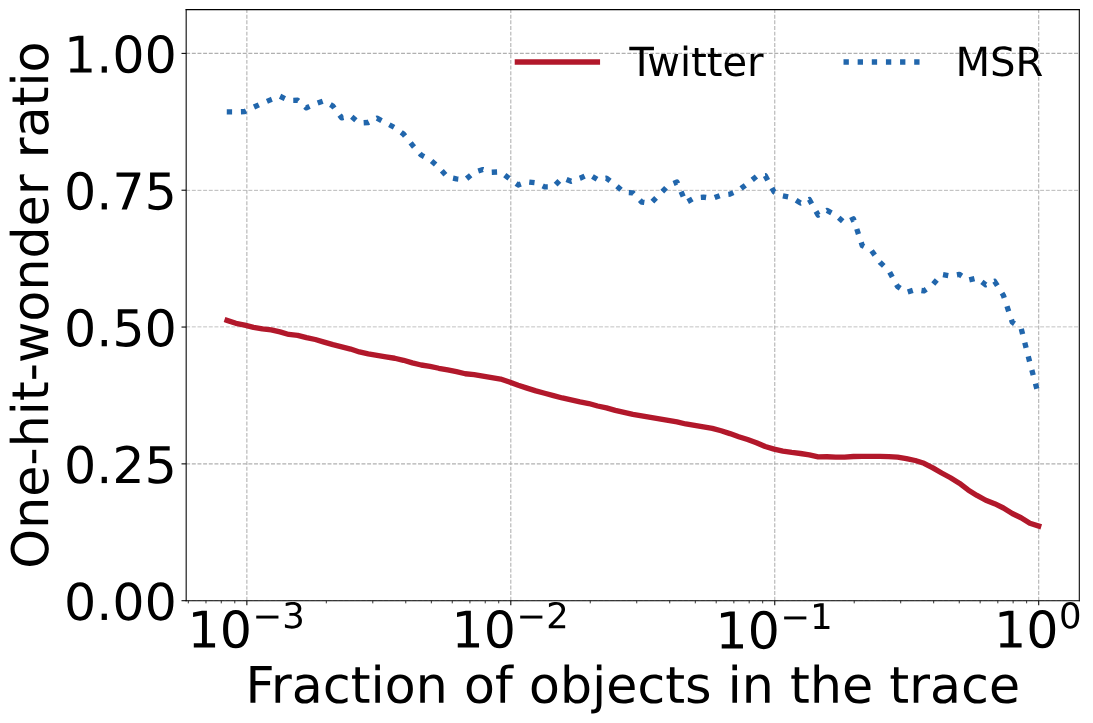
生产traces中的one-hit-wonder ratio。完整trace的one-hit-wonder ratio为13%和38%,可以看到,序列越短,one-hit-wonder ratio越高
我们进一步分析了一个包含6594条trace的大型缓存trace集合,并在箱线图中绘制了一次命中比例的分布。完整trace的one-hit-wonder ratio的中位数为26%,包含50% trace序列的one-hit-wonder ratio的中位数为38%。此外,包含10%和1% trace序列的one-hit-wonder ratio的中位数分别为72%和78%。
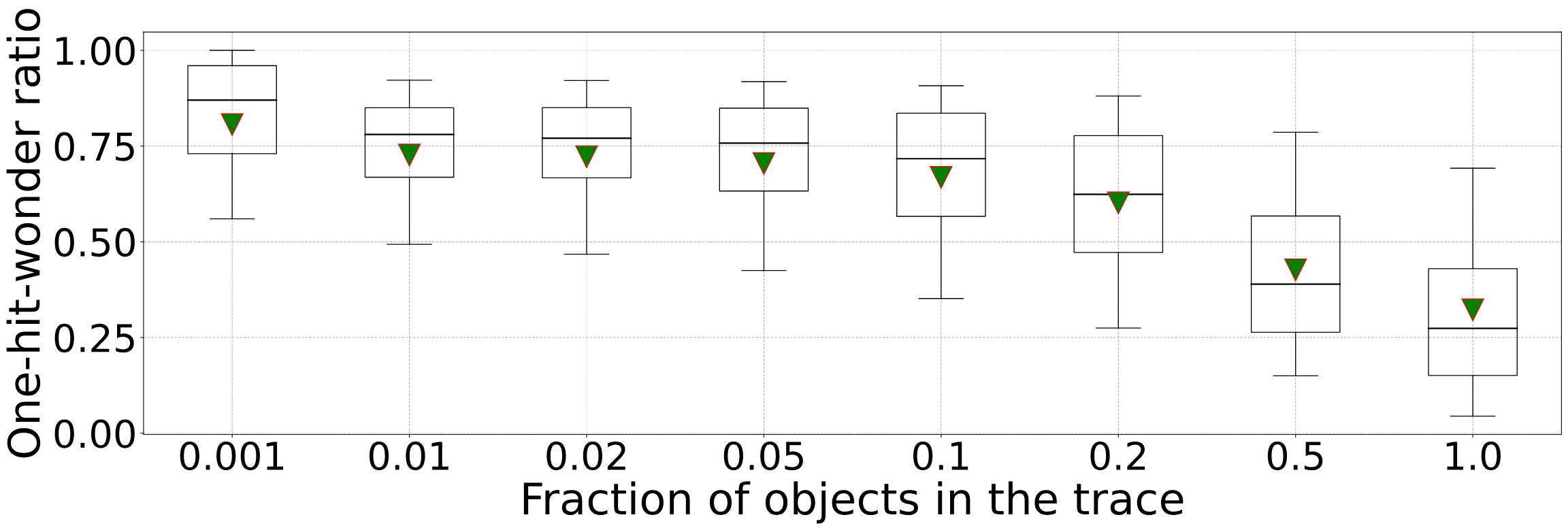
我们在分析中使用的trace大部分是为期一周,少部分是为期一个月的。由于缓存大小通常远小于trace的占用空间(trace中的对象数量/字节数),因此在短序列场景下就可能会发生缓存驱逐。我们观察发现,当缓存大小为trace空间的10%时,大约有72%的对象在驱逐之前不会被再次使用。
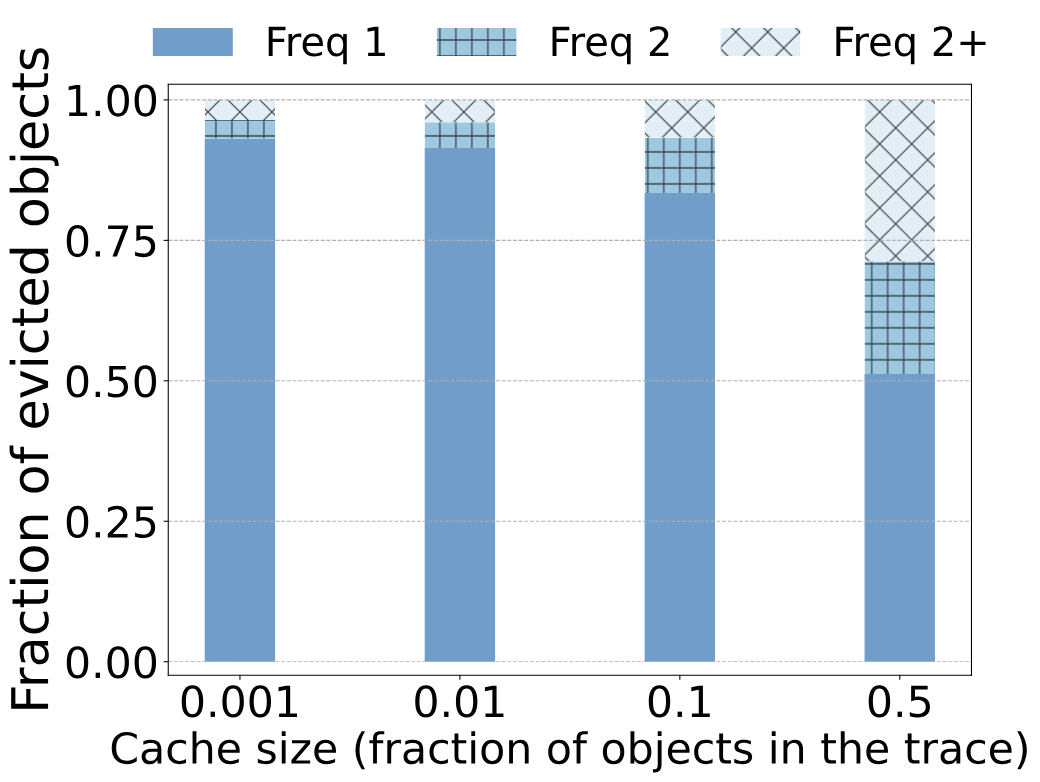
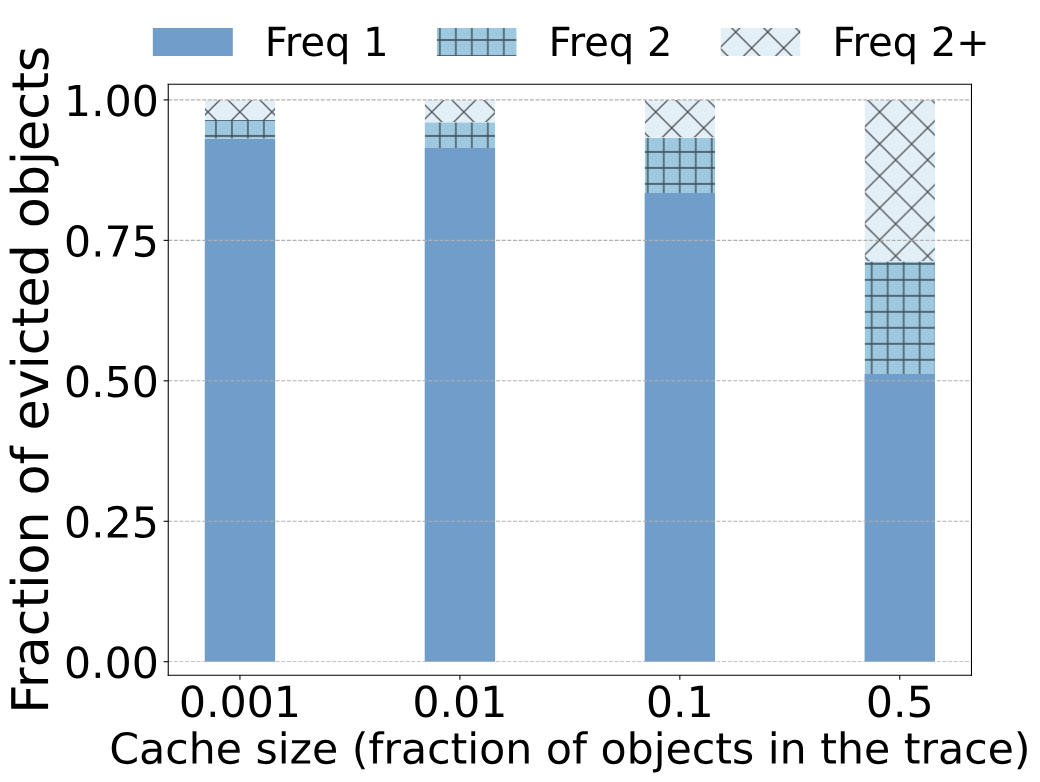
我们用缓存仿真进一步证实了观测结果。上图展示了驱逐对象的频率。我们的trace分析表明,在Twitter的trace中,当序列为trace空间的10%时,one-hit-wonder ratio为26%,而仿真展示了类似的结果:被LRU逐出的对象中有26%在插入缓存(大小为trace的10%)后没有被请求。类似地,在MSR的trace中,当序列长度为trace的10%时,one-hit-wonder ratio为75%,而仿真中被LRU驱逐的对象中的82%没有被再次使用。
很明显,缓存应该过滤掉这些one-hit wonders,因为它们占用了空间,却没有带来好处。
受上面观测结果的启发,我们设计了一个新的缓存驱逐算法,称为S3-FIFO:简单、使用三个静态FIFO队列的可扩展缓存(Simple, Scalable caching with three Static FIFO queues)。
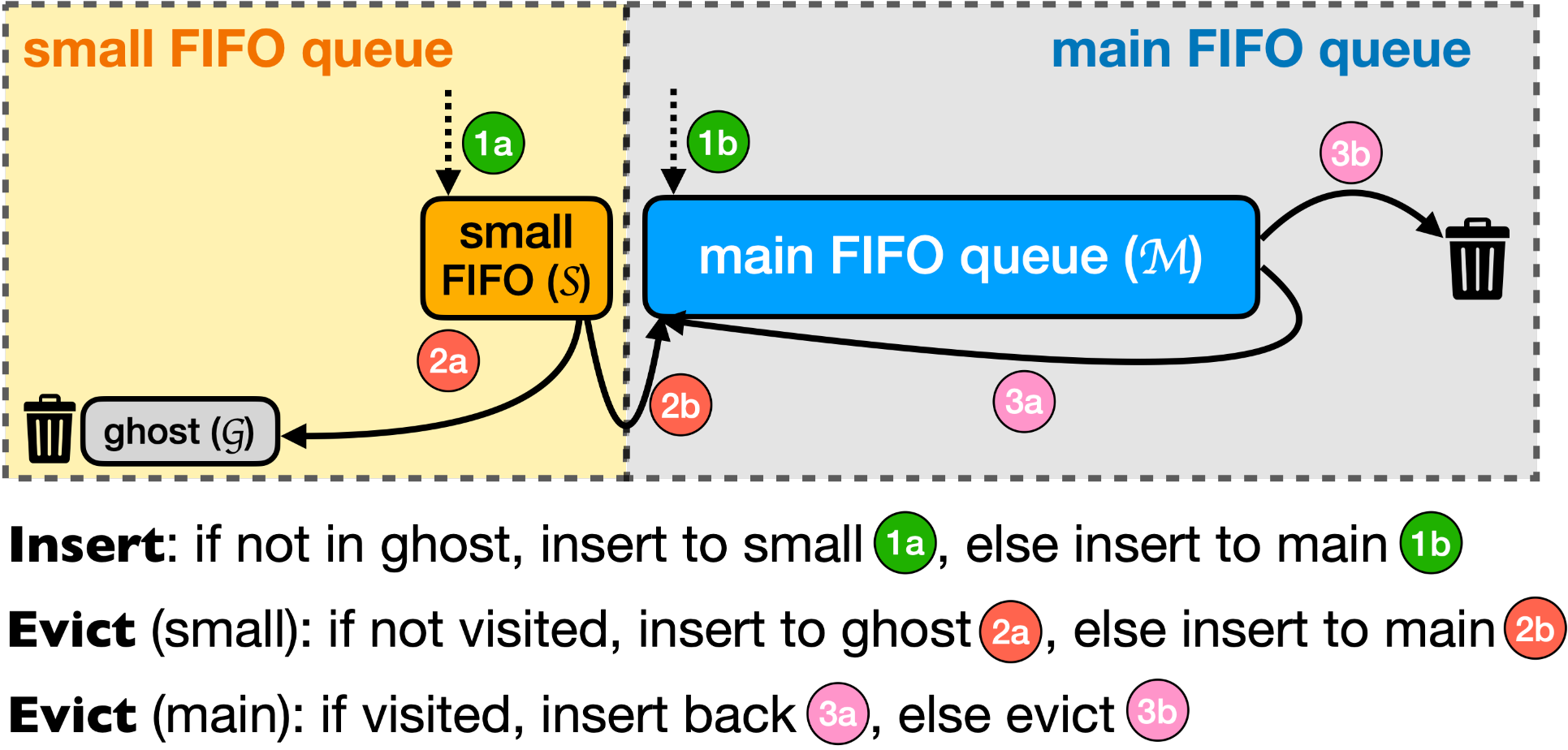
S3-FIFO使用3个FIFO队列:一个small FIFO队列(S),一个main FIFO队列(M),一个ghost FIFO队列(G)。我们将S设置为10%的缓存空间(实验得出)。M为90%的缓存空间,而G的大小和M相同。注意,当在ghost队列中发现请求的数据时,此时并不算缓存命中,原因是ghost队列并不保存数据。
缓存读:S3-FIFO中,每个对象使用两个bits(freq)来跟踪对象访问状态,上限为3,缓存命中时自动加1。
缓存写:当插入一个对象时,如果G中没有该对象,则插入S。当S满时,位于S尾部的对象要么会被转移到M(访问非0),要么被转移到G(访问为0),并在转移之后清除访问标记(freq)
当G满时,它会按照FIFO顺序驱逐对象。
M使用一个类似 FIFO-Reinsertion的算法,但同时使用两个bits来跟踪访问信息。至少对象的freq大于0,会被重新插入M首部,并将freq减1(freq-1)

添加对象的演示如下:
早两天写了一篇S3简单上传文件的小工具,知乎上看到了一个问题问如何实现显示MINIO上传进度,因此拓展一下这个小工具能够在上传大文件时显示进度。