近期,上海合合信息科技股份有限公司发布的文本向量化模型 acge_text_embedding 在中文文本向量化领域取得了重大突破,荣获 Massive Text Embedding Benchmark (MTEB) 中文榜单(C-MTEB)第一名的成绩。这一成就标志着该模型将在大模型领域的应用中发挥更加迅速和广泛的影响。

假设你需要了解如何在家中自制咖啡,可能会在搜索引擎中输入‘家庭咖啡制作方法’。如果没有Embedding模型,传统的引擎会简单地匹配包含关键词的文章,提供一些表面相关的内容而非实用的指南。”团队成员提到,借助Embedding模型,引擎便能更准确地理解用户意图,从而提供包括但不限于选择咖啡豆、磨豆技巧、不同的冲泡方法等更专业的内容。
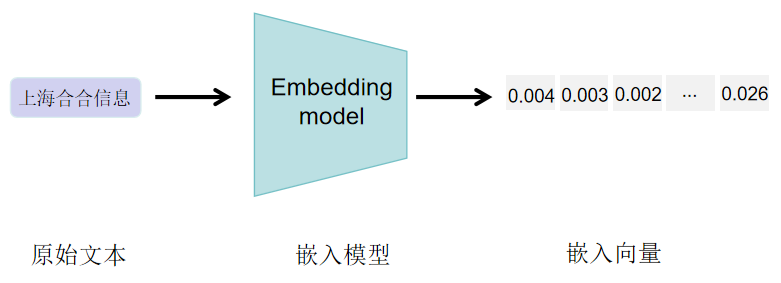
Text Embeddings 文本嵌入是一种将文本转化为包含语义信息的向量表示,因为机器处理信息需要数值输入,因此文本嵌入在许多自然语言处理(NLP)应用中起着至关重要的作用。例如,谷歌就利用文本嵌入来提升其搜索引擎的效能。此外,文本嵌入也可以用于通过聚类发现大量文本中的模式,或作为文本分类模型的输入。然而,文本嵌入的质量高度依赖于所使用的嵌入模型。
为此,Massive Text Embedding Benchmark(MTEB)旨在帮助用户在多种任务中找到最佳的嵌入模型。
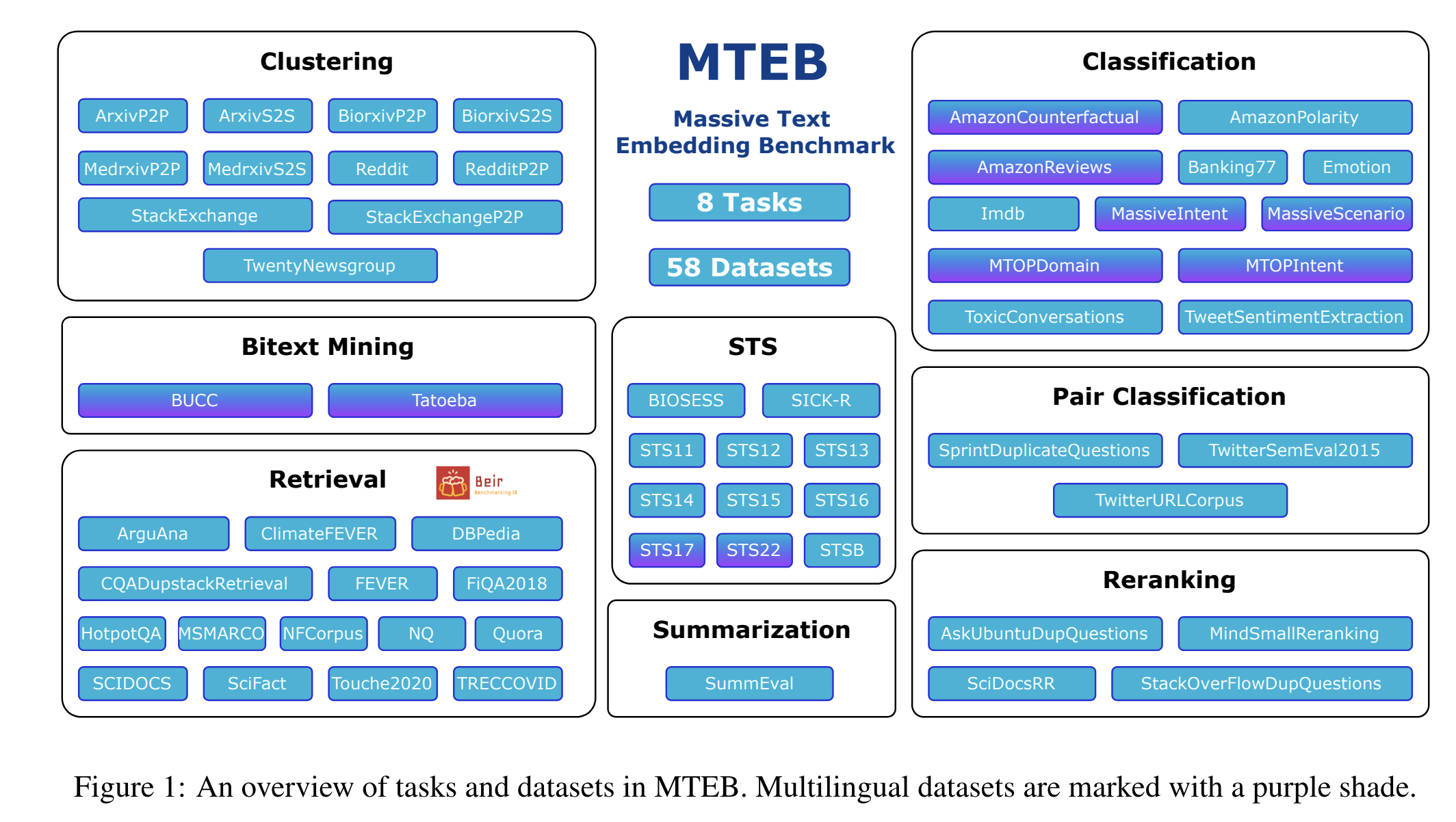
MTEB具备以下特点:
在MTEB的初步基准测试中,关注了以下特点。
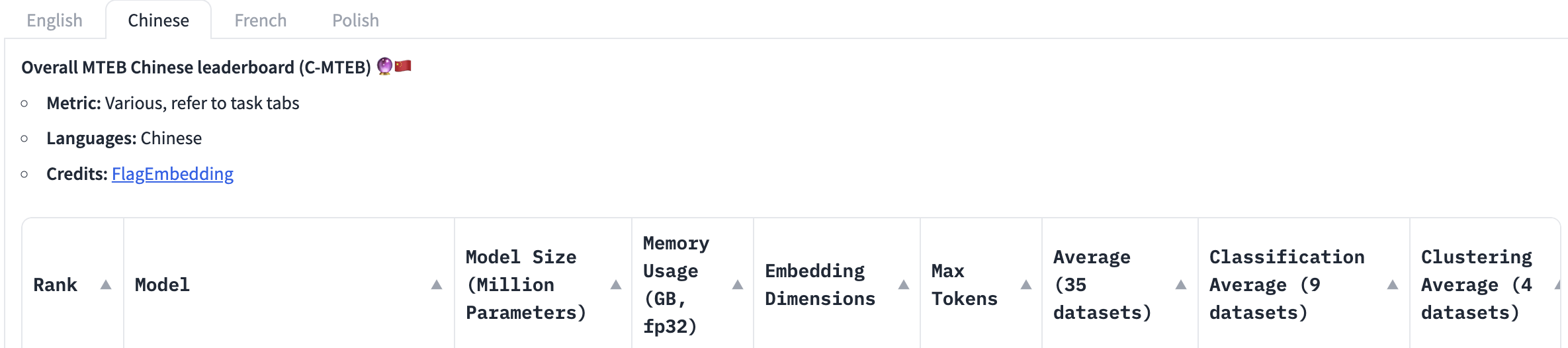

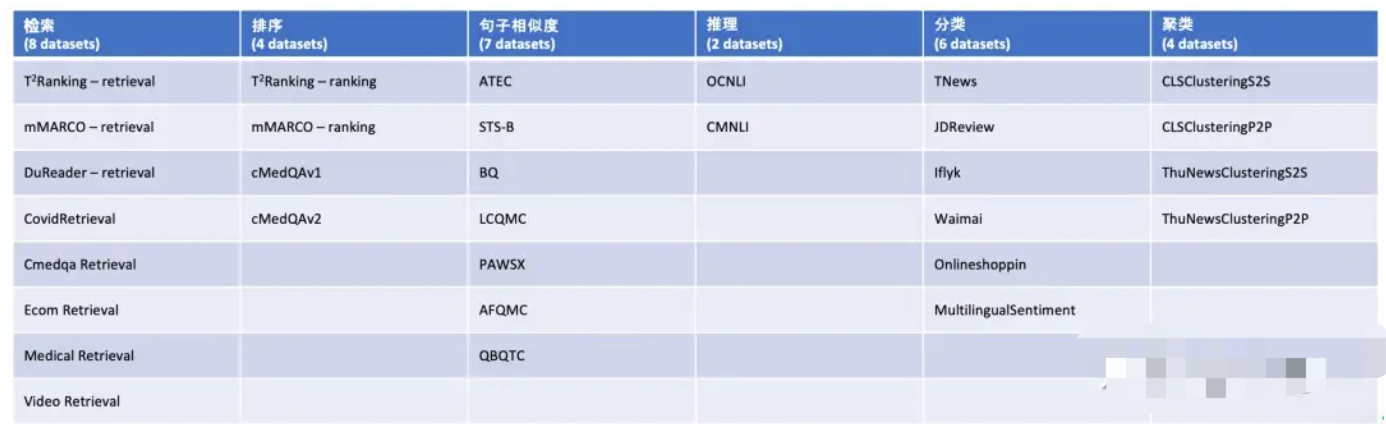
当前最全面的中文语义向量评测基准C-MTEB 开源,涵盖6大类评测任务(检索、排序、句子相似度、推理、分类、聚类),涉及31个相关数据集。
C-MTEB 是当前最大规模、最为全面的中文语义向量评测基准,为可靠、全面的测试中文语义向量的综合表征能力提供了实验基础。
acge模型来自于合合信息技术团队,对外技术试用平台TextIn.com。合合信息是行业领先的人工智能及大数据科技企业,致力于通过智能文字识别及商业大数据领域的核心技术、C端和B端产品以及行业解决方案为全球企业和个人用户提供创新的数字化、智能化服务。
acge是一个通用的文本编码模型,是一个可变长度的向量化模型,使用了Matryoshka Representation Learning,如图所示:
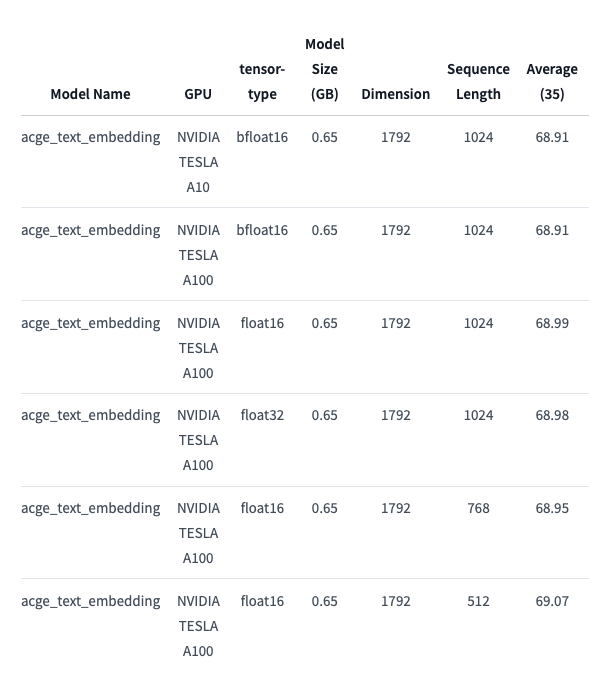
测试的时候因为数据的随机性、显卡、推理的数据类型导致每次推理的结果不一致,总共测试了4次,不同的显卡(A10 A100),不同的数据类型,测试结果放在了result文件夹中,选取了一个精度最低的测试作为最终的精度测试。 根据infgrad的建议,选取不用的输入的长度作为测试,Sequence Length为512时测试最佳。
相比于传统的预训练或微调垂直领域模型,acge模型支持在不同场景下构建通用分类模型、提升长文档信息抽取精度,且应用成本相对较低,可帮助大模型在多个行业中快速创造价值,推动科技创新和产业升级,为构建新质生产力提供强有力的技术支持。
具体实践上,为做好不同任务的针对性学习,团队使用策略学习训练方式,显著提升了检索、聚类、排序等任务上的性能;引入持续学习训练方式,克服了神经网络存在灾难性遗忘的问题,使模型训练迭代能够达到相对优秀的收敛空间;运用MRL技术,实现一次训练,获取不同维度的表征。
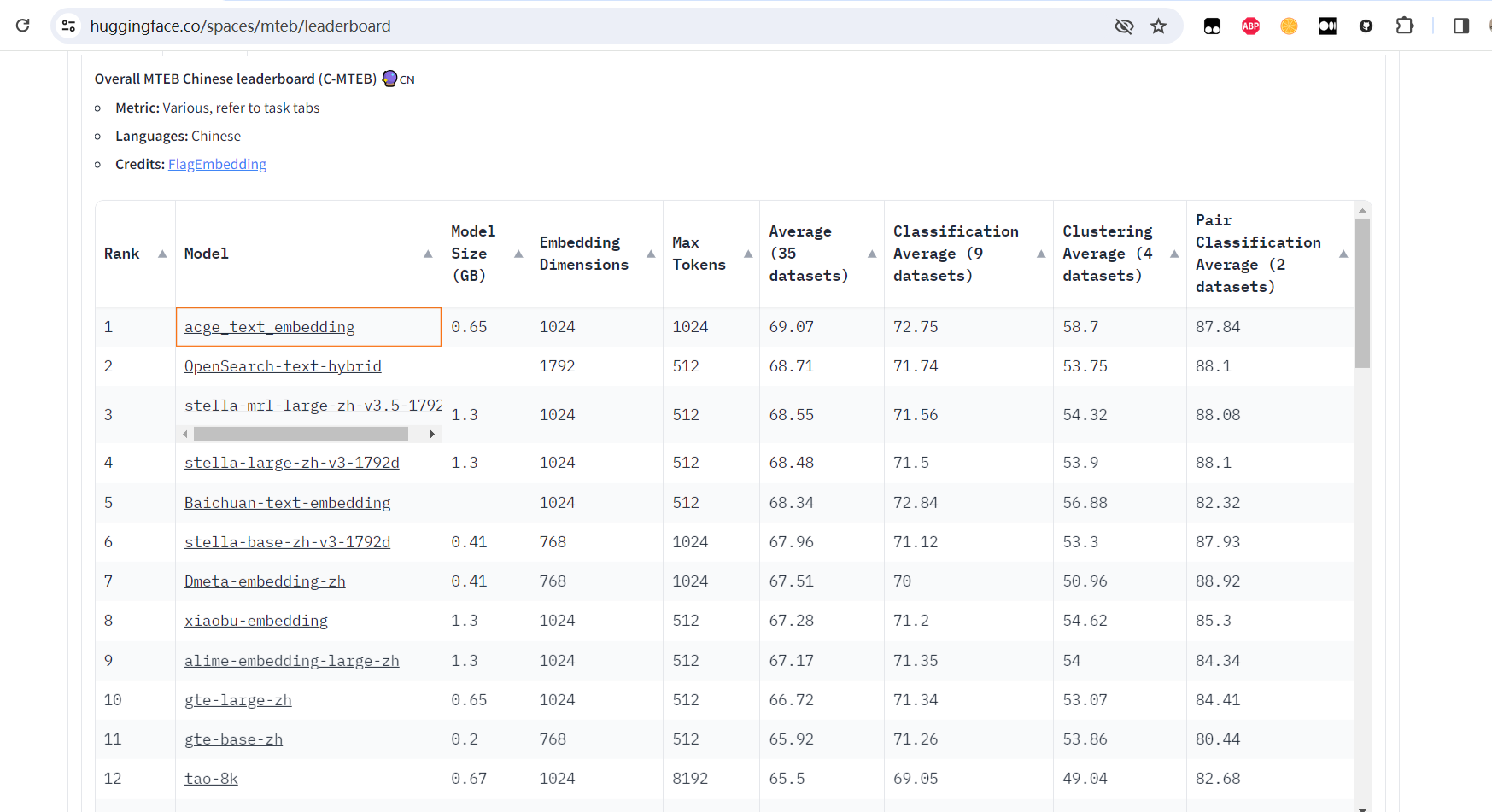
与目前C-MTEB榜单上排名前五的开源模型相比,合合信息本次发布的acge模型较小,占用资源少;模型输入文本长度为1024,满足绝大部分场景的需求。此外,acge模型还支持可变输出维度,让企业能够根据具体场景去合理分配资源。
在sentence-transformer库中的使用方法:
from sentence_transformers import SentenceTransformer
sentences = ["数据1", "数据2"]
model = SentenceTransformer('acge_text_embedding')
print(model.max_seq_length)
embeddings_1 = model.encode(sentences, normalize_embeddings=True)
embeddings_2 = model.encode(sentences, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
复制如果对该模型或智能文档处理等技术感兴趣,请访问textin.com。
OCR服务大降价,单次调用仅需0.025元!合合TextIn平台全线推出OCR云服务优惠活动,享单次最低0.025元!包括文字识别、表格识别、证照识别、票据识别及验真、PDF转WORD及图像处理等服务全线下调价格。详情请电脑端进入textin.com市场中查看。
如有帮助,请多关注
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。
LLM 大模型学习必知必会系列(十二):VLLM性能飞跃部署实践:从推理加速到高效部署的全方位优化[更多内容:XInference/FastChat等框架]
