MaMa 看到别人有个软件,可以直接把一个网站上的数据全部爬进一个 Excel 里边,但是那个人不给这个软件,所以她怂恿我写一个。。。
千股千评 _ 数据中心 _ 东方财富网 (eastmoney.com)
对于里边的00~60开头的股票,把股票代码、涨跌幅、换手率、机构参与度给搞到一个 Excel 里边。

进入网站,打开 F12 里边的“网络”,多改几次页码,发现每一次都会有几个数据包。

我们选中刷新第一页时候的几个数据包,发现两个图片,一个不知道啥东西,我们凭直觉知道,图片大概率没啥用,于是不管他,点开那个不知道啥文件。

发现一个奇怪的 URL,我们把这玩意输进地址栏里边,一个 txt 出来了:

对比一下原始数据:

真不错,现在数据有了,我们也可以以此得出我们需要的数据在 txt 里边叫啥:
| TXTname | Name |
|---|---|
| SECURITY_CODE | 股票代码 |
| CHANGE_RATE | 涨跌幅 |
| TURNOVERRATE | 换手率 |
| ORG_PARTICIPATE | 机构参与度 |
看一看请求数据包的 URL,看看有啥特点:
datacenter-web.eastmoney.com/api/data/v1/get?callback=jQuery112305044442743842579_1713445654977&sortColumns=SECURITY_CODE&sortTypes=1&pageSize=50&pageNumber=1&reportName=RPT_DMSK_TS_STOCKNEW"eColumns=f2~01~SECURITY_CODE~CLOSE_PRICE%2Cf8~01~SECURITY_CODE~TURNOVERRATE%2Cf3~01~SECURITY_CODE~CHANGE_RATE%2Cf9~01~SECURITY_CODE~PE_DYNAMIC"eType=0&columns=ALL&filter=&token=894050c76af8597a853f5b408b759f5d
里面有一个 pageSize,用来调整每页显示多少,但是这个值不可以太大。
里面有一个 pageNumber,用来调整显示第几页。
我们可以使用 ... pageSize=1&pageNumber=1 ...、... pageSize=1&pageNumber=2 ... 来一个个的搞数据。
然后就完了,简化一下需求:
你需要对于几千个 txt 中的每一个,干如下的事情:
- 分离股票代码
- 根据
... ,"SECUCODE":"_NUM_", ...,分离出股票代码
- 如果里边出现了 60+ 开头的股票,就停止
- 分离其他三个数据,格式为
... ,"_NAME_":"_NUM_", ...- 输出为 Excel
让我们一通百度-Google-Bing-Cnblogs-CSDN-知乎(没学过网络)。
决定:跨语言编程绝对不是因为我C++菜搞不懂类型转换。
使用 python 的 requests 把文件搞下来:pip install requests
先下载一个试试看,URL太长,我用__PATH__替代掉了:


可谓是十分好的成功了啊。
我们爬个 \(5000\) 条,一条一条爬,发现慢的要死,得爬个 30min。
所以说还是 \(100\) 条一起爬罢。

注意 python range 不包含最大值。。。
后面交给 C++ 去做了。
比较的基础。

再次祭出 python 小宝贝。
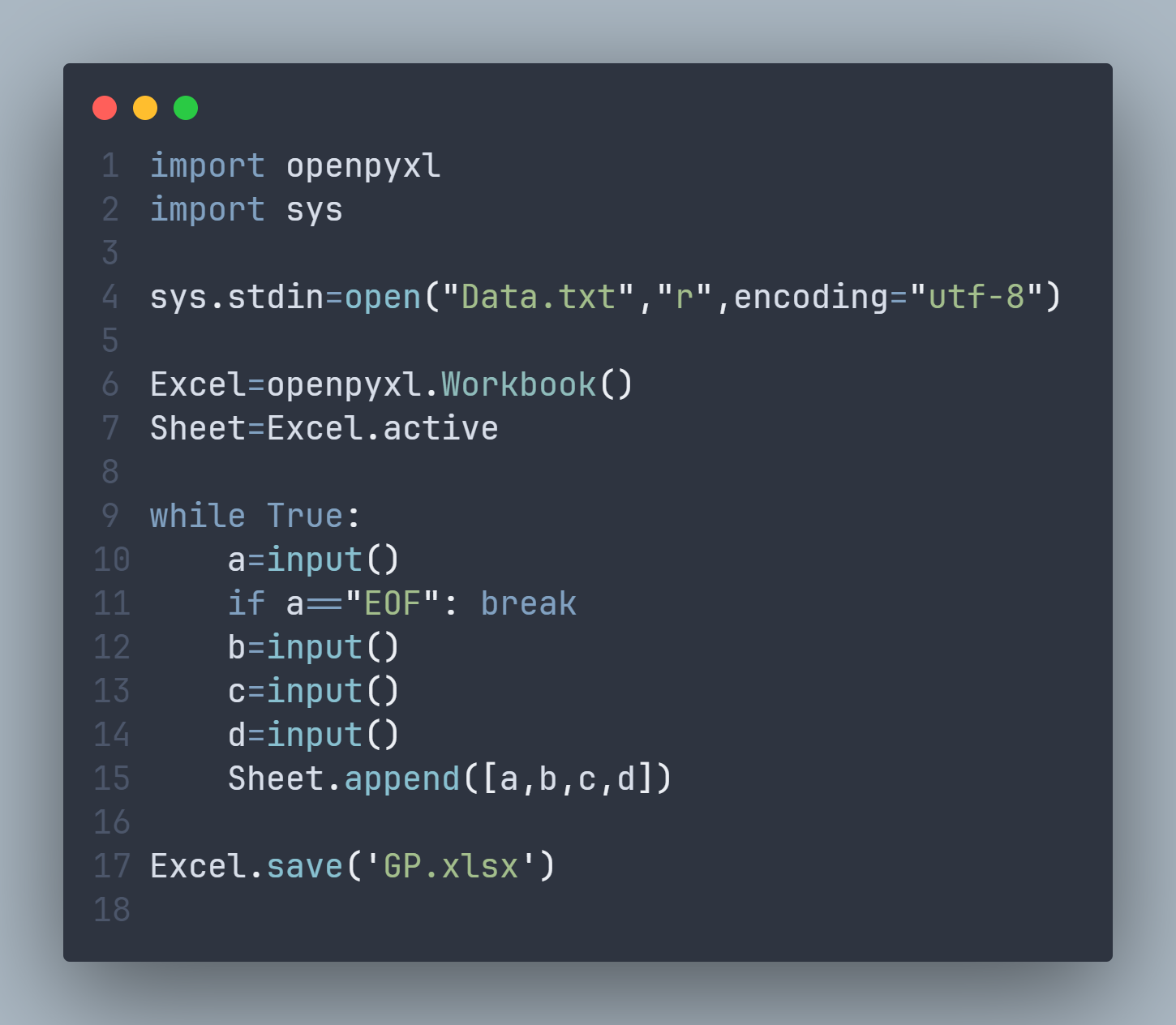
感觉看看好像 openpyxl 库比较好写一些,装一个罢:pip install openpyxl
Python向Excel写入内容的方法大全_python写入excel单元格-CSDN博客
电脑上没装 MinGW,导致没法运行 C++ 的 exe。
只好强行翻译了。
顺便加一个删除上一次文件的功能。
import requests
import openpyxl
import sys
import os
# 创建文件夹
def MakeDir(Name):os.makedirs(Name)
# 删除旧版数据
def Delete_Old():
os.system("rmdir /S /Q Files")
os.system("del Data.txt")
os.system("del GP.xlsx")
# 下载所有数据包
def Download():
MakeDir("Files")
print("All: 50 Datas")
for Number in range(1,51):
print("Download: No."+str(Number))
URL="https://datacenter-web.eastmoney.com/api/data/v1/get?callback=jQuery112305044442743842579_1713445654977&sortColumns=SECURITY_CODE&sortTypes=1&pageSize=100&pageNumber="+str(Number)+"&reportName=RPT_DMSK_TS_STOCKNEW"eColumns=f2~01~SECURITY_CODE~CLOSE_PRICE%2Cf8~01~SECURITY_CODE~TURNOVERRATE%2Cf3~01~SECURITY_CODE~CHANGE_RATE%2Cf9~01~SECURITY_CODE~PE_DYNAMIC"eType=0&columns=ALL&filter=&token=894050c76af8597a853f5b408b759f5d"
File=requests.get(URL)
with open ("Files/"+str(Number)+".txt","wb") as f:
f.write(File.content)
f.close
# 处理所有数据
Data=""
def Equals(x,s):
global Data
for i in range(0,len(s)):
if Data[x+i]!=s[i]:
return False
return True
def Get_string(x):
global Data
res=""
while Data[x]!='"' and Data[x]!=',' :
res=res+Data[x]
x+=1;
return res
def Get_double(x):
res=Get_string(x)
return float(res)
def Have(x):
global Data
return Data[x]!='-' or Data[x+1]!='"'
def Next_Start(x):
while Data[x]!=':':x+=1
x+=1
if Data[x]=='"': x+=1
return x
def Search():
global Data
Cnt=0
for i in range(0,len(Data)):
if Equals(i,"SECURITY_CODE"):
flag=Next_Start(i);
Number=int(Get_string(flag));
if Number>=680000:
print("EOF")
break
print(Get_string(flag))
if Equals(i,"CHANGE_RATE"):
flag=Next_Start(i);
if not Have(flag):
print("-")
else:
print(Get_double(flag))
if Equals(i,"TURNOVERRATE"):
flag=Next_Start(i);
if not Have(flag):
print("-")
else:
print(Get_double(flag))
if Equals(i,"ORG_PARTICIPATE"):
flag=Next_Start(i);
if not Have(flag):
print("-")
else:
print(Get_double(flag))
Cnt+=1
if Cnt==100:
break
def Input(i):
sys.stdin=open("Files/"+str(i)+".txt","r",encoding="utf-8")
res=input()
return res
def Process():
print("Process...")
sys.stdout=open("Data.txt","w",encoding="utf-8")
for i in range(1,51):
global Data
Data=Input(i)
Search()
# 数据输出至 Excel
def To_Excel():
sys.stdin=open("Data.txt","r",encoding="utf-8")
Excel=openpyxl.Workbook()
Sheet=Excel.active
while True:
a=input()
if a=="EOF": break
b=input()
c=input()
d=input()
Sheet.append([a,b,c,d])
Excel.save('GP.xlsx')
Delete_Old()
Download()
Process()
To_Excel()
复制