num1=input('请输入第一个数,x:') num2=input('请输入第二个数,y:') num3=input('请输入第三个数,z:') if num1>num2: # if 语句判断 num1,num2=num2,num1 if num1>num3: num1, num3 = num3, num1 if num2>num3: num2,num3=num3,num2
print(num1,num2,num3)复制
代码运行截图:
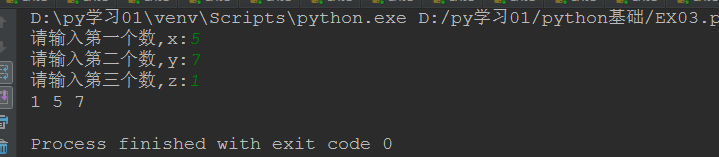
延伸1.:这三个数由大到小输出
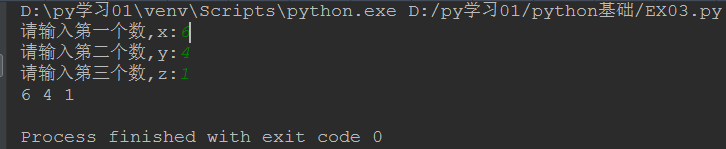
num1=input('请输入第一个数,x:')
num2=input('请输入第二个数,y:')
num3=input('请输入第三个数,z:')
if num1>num2: # if 语句判断
num1,num2=num1,num2
if num1>num3:
num1, num3 = num1, num3
if num2>num3:
num2,num3=num2,num3
print(num1,num2,num3)
代码运行截图:复制
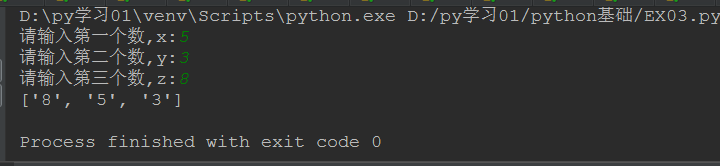
2.sort() 函数用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数。
1 list=[num1,num2,num3] 2 3 # sort() 函数用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数。 4 5 # True 为降序 ,False 默认为升序 6 list.sort(reverse=True) 7 8 print(list)复制
代码运行截图:
vowels = ['e', 'a', 'u', 'o', 'i']
# 降序
vowels.sort(reverse=True)
# 输出结果
print('降序输出:')
print(vowels)
复制

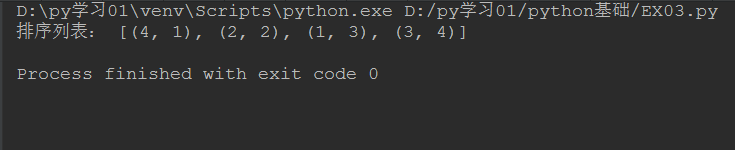
3. 制定元素排序
# 获取列表的第二个元素
def takeSecond(elem):
return elem[1]
# 列表
li1= [(2, 2), (3, 4), (4, 1), (1, 3)]
# 指定第二个元素排序
li1.sort(key=takeSecond)
# 输出类别
print('排序列表:',li1)
复制
https://blog.csdn.net/ccclych1/article/details/80496955
Python菜鸟教程:https://www.runoob.com/python/att-list-sort.html