本文介绍基于Python语言,实现对多个不同Excel文件进行数据读取与平均值计算的方法。
首先,让我们来看一下具体需求:目前有一个文件夹,其中存放了大量Excel文件;文件名称是每一位同学的名字,即文件名称没有任何规律。
而每一个文件都是一位同学对全班除了自己之外的其他同学的各项打分,我们以其中一个Excel文件为例来看:
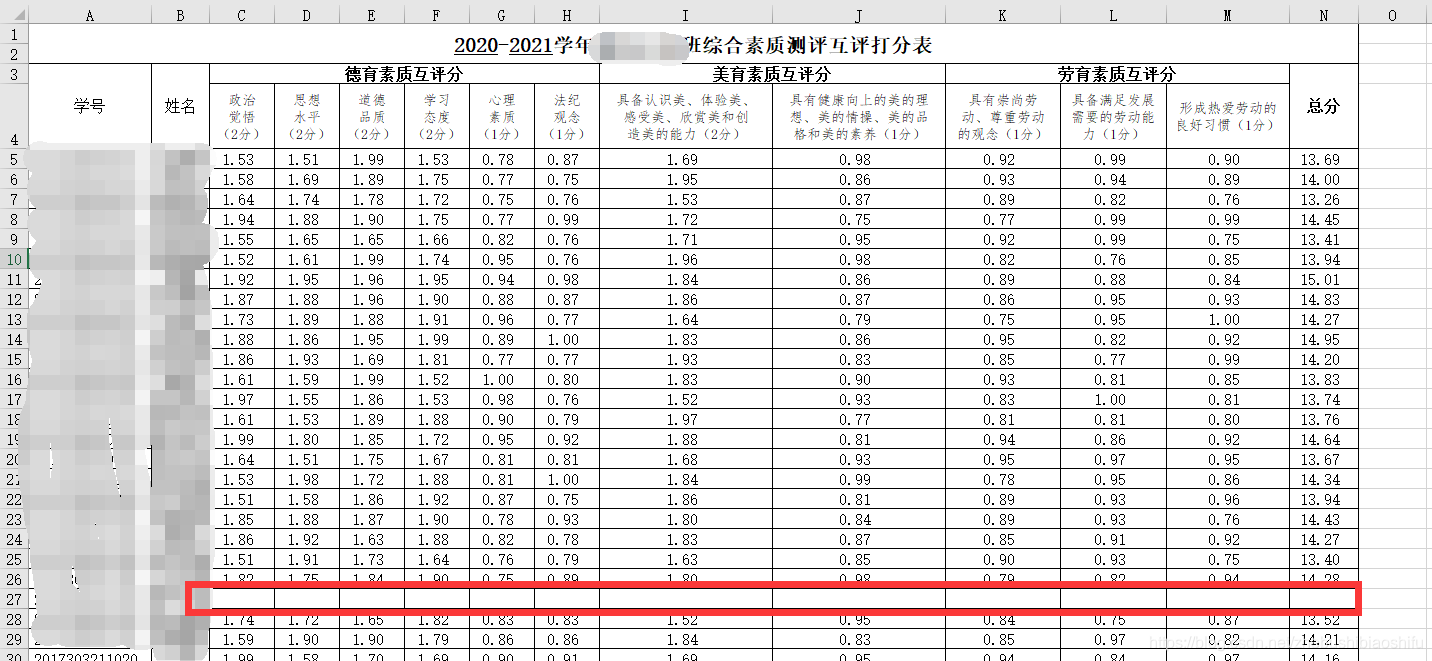
可以看到,全班同学人数(即表格行数)很多、需要打分的项目(即表格列数)有11个(不算总分);同时,由于不能给自己打分,导致每一份表格中会有一行没有数据。
而我们需要做的,就是求出每一位同学的、11个打分项目分别的平均分,并存放在一个新的、表头(行头与列头)与大家打分文件一致的总文件中,如下图。其中,每一个格子都代表了这位同学、这一项打分项目在经过班级除其之外的每一位同学打分后计算出的平均值。

可以看到,一个人就需要算11次平均,更何况一个班会有数十位同学。如果单独用Excel计算,是非常麻烦的。
而借助Python,就会简单很多。具体代码如下。在这里,就不再像平日里机器学习、深度学习代码博客那样,对代码加以逐段、分部分的具体解释了,直接列出全部代码,大家参考注释即可理解。
# -*- coding: utf-8 -*-
"""
Created on Thu Apr 8 16:24:41 2021
@author: fkxxgis
"""
import os
import numpy as np
from openpyxl import load_workbook
file_path='F:/班长/2020-2021综合测评与评奖评优/01_综合测评/地信XXXX班互评打分表/' #这里是每一位同学打分Excel文件存放的路径
output_path='F:/班长/2020-2021综合测评与评奖评优/01_综合测评/地信XXXX班综合素质测评互评打分表.xlsx' #这里是最终结果存放路径,请不要和上述路径一致
first_row=5 #第一个分数所在的行数
first_column=3 #第一个分数所在的列数
all_row=32 #班级同学总数
all_column=11 #需要计算的分数项目个数
all_excel=os.listdir(file_path) #获取打分文件路径下全部Excel文件
file_row=first_row+all_row-1
file_column=first_column+all_column-1
all_mean_score=np.zeros((file_row,file_column),dtype=float) #新建一个二维数组,存放每一位同学、每一项项目的分数平均值
for now_row in range(first_row,file_row+1):
for now_column in range (first_column,file_column+1):
all_score=[]
for excel_num in range(0,len(all_excel)):
now_excel=load_workbook(file_path+all_excel[excel_num]) #打开第一个打分Excel文件
all_sheet=now_excel.get_sheet_names() #获取打分文件的全部Sheet名称
now_sheet=now_excel.get_sheet_by_name(all_sheet[0]) #本文中分数全部存储于第一个Sheet,因此下标为0
single_score=now_sheet.cell(now_row,now_column).value #获取对应单元格数据
if single_score==None: #如果这个单元格为空(也就是自己不给自己打分的那一行)
pass
else:
all_score.append(single_score)
all_mean_score[now_row-1,now_column-1]=np.mean(all_score) #计算全部同学为这一位同学、这一个打分项目所打分数的平均值
output_excel=load_workbook(output_path) #读取结果存放Excel
output_all_sheet=output_excel.get_sheet_names() #这里代码含义同上
output_sheet=output_excel.get_sheet_by_name(output_all_sheet[0])
output_sheet=output_excel.active
for output_now_row in range(first_row,file_row+1):
for output_now_column in range (first_column,file_column+1):
exec("output_sheet.cell(output_now_row,output_now_column).value=all_mean_score[output_now_row-1,output_now_column-1]") #将二维数组中每一位同学、每一项打分项目的最终平均分数写入结果文件的对应位置
output_excel.save(output_path)
至此,大功告成。
介绍史上最全PYTHON文件类型读写库大盘点!包含常用和不常用的大量文件格式!文本、音频、视频应有尽有!废话不多说!走起来!