本文介绍基于MATLAB实现全局多项式插值法与逆距离加权法的空间插值的方法,并对不同插值方法结果加以对比分析。
趁热打铁,前期我们完成了地学计算基本理论讲解(见文章地统计学的基本概念及公式详解)与空间数据变异函数计算与经验半方差图绘制(见文章MATLAB计算变异函数并绘制经验半方差图)这一地学计算的基本实践操作后,我们将深入探讨、实战地学计算中插值问题的两个重要方法:全局多项式插值法与逆距离加权法。
为方便大家理解,本文将讲解与代码部分独立开来;首先将具体的操作流程与方法仔细阐述,其次将本文所用到的全部代码完整附于本文末尾。其中,由于本文所用的数据并不是我的,因此遗憾不能将数据一并提供给大家;但是依据本篇博客的思想与对代码的详细解释,大家用自己手头的数据,可以将相关操作与分析过程加以完整重现。
空间数据的获取是进行空间分析的基础与起源,我们总是希望能够获取研究区域更多、更全面的精确空间属性数据信息。但在实际工作中,由于成本、资源等条件限制,不可能对全部未知区域加以测量,而更多只能得到有限数量的采样点的数据。因此,可以考虑选取合适的空间采样点,利用一定数学模型,依据已知采样点数据对研究区域所有位置的未知属性信息加以预测。
空间插值(Spatial Interpolation)即是一种将离散点测量数据转换为连续数据曲面的常用方法,包括内插(Interpolation)和外推(Extrapolation)两种应用形式。空间插值基于地理学第一定律,即一般地,距离越近的地物具有越高的相关性。
在方法层面,空间插值一般可以分为确定性插值方法(Deterministic Interpolation)与地质统计学方法(Geostatistics)。前者基于信息点之间相似程度或整个曲面的平滑程度创建拟合曲面,后者则基于信息点综合统计学规律,对其空间自相关性定量化,从而创建插值面。另一方面,依据插值计算时纳入考虑的采样点分布范围,又分为整体插值法与局部插值法。前者利用整个实测采样点数据集对全区进行拟合,如全局多项式插值法(Global Polynomial Interpolation);后者则只是用临近某一区域内的采样点数据预测未知点的数据,如反(逆)距离加权法(Inverse Distance Weighted,IDW)。此外,依据插值结果曲面中采样点预测值与实测值的关系,又可分为精确性插值与不精确插值。
本文借助MATLAB软件自主编程,分别利用全局多项式插值法与逆距离加权法,对湖北省荆门市沙洋县土壤pH值、有机质含量等两种属性数据进行空间插值计算,并对比对应插值方法的拟合效果。
全局多项式插值法以全部采样点覆盖区域为基础,通过最小二乘法等手段拟合出一个最合适的平面或曲面,使得各个采样点较为均匀地分布于这一平面或曲面的附近,且全部高出该面的点距之和与全部低于该面的点距之和的绝对值应当近似。全局多项式插值法不适合描述属性数据空间分布波动较大区域的特征。
逆距离加权法则利用待插值点周围一定范围的已知点数据,对中心待插点加以数据插值;某点距离待插点越近,其对这一点的影响越大,即对应系数越大。而权重的计算往往依赖于反距离(距离倒数)的p次方。一般地,取p等于2。依据方法原理可知,逆距离加权法往往会导致空间分布的多点中心现象。
本文利用上述MATLAB计算变异函数并绘制经验半方差图中的数据为范例,其包括湖北省荆门市沙洋县658个土壤采样点的空间位置(X与Y,单位为米)、pH值、有机质含量与全氮含量。这些数据同样存储于data.xls文件中,而后期操作多基于MATLAB软件加以实现。因此,首先需根据具体计算需要将源数据选择性地导入MATLAB软件中。
同上述博客所述,我们得到的原始采样点数据在采样记录、实验室测试等过程中,可能具有一定误差,从而出现个别异常值;而异常值的存在会对后期空间插值效果(尤其是局部插值方法)产生较大影响。因此,选用平均值加标准差法对异常数据加以筛选、剔除。这一方法的具体含义请见MATLAB计算变异函数并绘制经验半方差图。
上述博客中,分别利用“2S”与“3S”方法加以处理,发现“2S”方法处理效果相对后者较好。故本文直接选择使用“2S”方法处理结果继续进行。
得到异常值后,将其从原有658个采样点中剔除;剩余的采样点数据继续后续操作。
针对不同插值方法所得结果的精度检验,本文采取设置训练数据(Training Data)与测试数据(Test Data)并对比的方式进行。将经过上述异常剔除后的数据随机分为两个部分,其中80%作为训练数据,剩余20%作为测试数据(即验证集)。需要注意的是,测试数据仅可用于检测插值模型的构建效果,而不可参与模型构建过程,否则可能导致结果过度拟合(即模型对本次所给数据具有较好插值、拟合效果,但对外围无数据区域的预测效果较差)。由于验证集数据为随机选取,因此后期可多次执行程序,以期获得平稳的精度衡量指标。
正如全局多项式插值法名称所示,这一插值方法的原理实际上是对一个描述平面或曲面的多项式各个系数加以求解;而这一求解过程往往采用最小二乘法实现。
考虑到多项式的复杂度,本文将多项式阶数限定为二阶与三阶,并对其插值效果加以对比。二阶多项式形式如下:

三阶多项式形式如下:

上述两公式中,W(x,y)为待插点(x,y)的插值,x与y为坐标,φ为常数,其它字母代表各对应项系数。
若利用AcrMap等软件进行趋势面插值,则可依据实际情况适当提升阶数。
逆距离加权法通过各已知点自身实际数值及其关于待插点的权重实现插值,公式如下:

其中,ω_i为第i个已知点对待插点(x_0,y_0 )的权重,d_i0为二者间距离,n为已知点个数,p为幂参数,W(x_0,y_0 )为待插点(x_0,y_0 )的插值,Z(x_i,y_i )为第i个已知点对应属性数值。
本文中,取初始p=2,并依据插值效果适当对其加以调整。
如前所述,本文通过随机选定的测试数据对插值结果的精度进行比较与分析。结合实际空间数据的数值特点,最终所选用以衡量插值精度的指标包括平均误差(Mean Error,ME)[1]、平均绝对误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Square Error,RMSE)与相关系数(Correlation Coefficient)。
其中,平均误差可以获知插值结果与实测点观测值的大小关系;平均绝对误差表示空间插值与实测点观测值之间绝对误差的平均值,可以更好反映插值结果误差的实际情况;均方根误差表示插值结果与实测点观测值之间差异(即残差)的样本标准差;相关系数(这里选用皮尔逊相关系数)用以评价空间插值与实测点观测值之间的线性相关度。
通过上述过程,得到对应属性数据的插值结果。首先在MATLAB绘制插值结果三维图,随后将插值结果数据变量保存为ASCII数据格式文件,并导入AcrMap软件绘制专题地图。
其中,在数据由MATLAB导出为.txt格式后,需要在其开头部分添加以下信息:
ncols 1275
nrows 1209
xllcorner 600800
yllcorner 3364600
cellsize 50
NODATA_value -9999
复制其中,ncols与nrows对应数值分别代表插值结果列数与行数,xllcorner与yllcorner对应数值分别代表插值结果x、y坐标的最小值(即起始值),cellsize对应数值代表像元大小。
通过平均误差、平均绝对误差、均方根误差、相关系数等四个精度衡量指标,以及对应趋势面公式与三维插值结果图,将不同空间插值方法所得结果对比、分析如下,并绘制专题地图。
利用最小二乘法,分别对二阶多项式与三阶多项式进行系数求解,并得到pH值、有机质含量等两种空间属性数据的全局多项式插值结果与各精度指标。针对不同阶数多项式,分别执行六次插值操作,并求出平均值。得到结果分别如表1至表6所示。


由表1至表3可知,针对pH值的全局多项式插值法,二阶、三阶多项式所得插值结果的平均误差均为负数,即两种方法均趋向于获得较之观测值高的插值结果;而后者所得平均误差的数值较小于前者(即后者这一指标绝对值较小)。二阶、三阶多项式插值结果对应平均绝对误差、均方根误差相差不大,但后者上述两种指标数值同样小于前者。三阶多项式相关系数同样略大于二阶多项式。综上所述,面向pH值的全局多项式插值法,其运用三阶多项式的插值效果较优于运用二阶多项式的插值效果,且这一结果在平均误差、平均绝对误差、均方根误差与相关系数等四个精度衡量指标中均有所体现。
由表4至表6可知,针对有机质含量的全局多项式插值法,二阶、三阶多项式所得插值结果的平均误差均为正数,即两种方法均趋向于获得较之观测值低的插值结果;而后者所得平均误差的数值较大于前者。二阶、三阶多项式插值结果对应平均绝对误差相差不大,但后者上述指标数值同样略大于前者。二阶多项式的均方根误差较之三阶多项式低,且二者这一指标有着较为明显的差距。三阶多项式相关系数同样略小于二阶多项式。综上所述,面向有机质含量的全局多项式插值法,其运用二阶多项式的插值效果与运用三阶多项式的插值效果整体区分度不大,二阶多项式插值结果在平均误差、平均绝对误差与相关系数等三个精度衡量指标中略优于三阶多项式,而三阶多项式插值结果则在均方根误差这一指标中表现出色。考虑到不同测试数据的选取具有随机性,因此认为上述较为接近的结果并不能特别表现出二者中更优的插值方法选择。
综合表1至表6可知,对于全局多项式插值法,其多项式阶数的选择并不一定是越高越好,而是需要依据实际数据情况加以尝试、选择。较高的阶数除了会增大计算量、延长程序执行时间外,其插值结果精度亦有可能并无增长,甚至在某些指标中出现下降趋势。
综上所述,分别利用二阶多项式与三阶多项式获取全局多项式插值法对应趋势面函数。
针对pH值的二阶、三阶全局多项式插值趋势面函数如下:

其中,上述二阶与三阶趋势面函数分别对应各精度衡量指标情况如表7所示。

上述二阶与三阶趋势面函数分别对应三维插值结果图如下。


针对有机质含量的二阶、三阶全局多项式插值趋势面函数如下:

其中,上述二阶与三阶趋势面函数分别对应各精度衡量指标情况如表8所示。

上述二阶与三阶趋势面函数分别对应三维插值结果图如下。


通过本文前述部分的相关方法,将MATLAB插值数据结果文件导入ArcMap,经过剪裁后制作湖北省荆门市沙洋县土壤pH值、有机质含量全局多项式插值专题地图。其中,专题地图的具体制作方法这里就不再赘述了,大家可以参考ENVI大气校正方法反演Landsat 7地表温度中的方法。



得到专题地图如下所示。
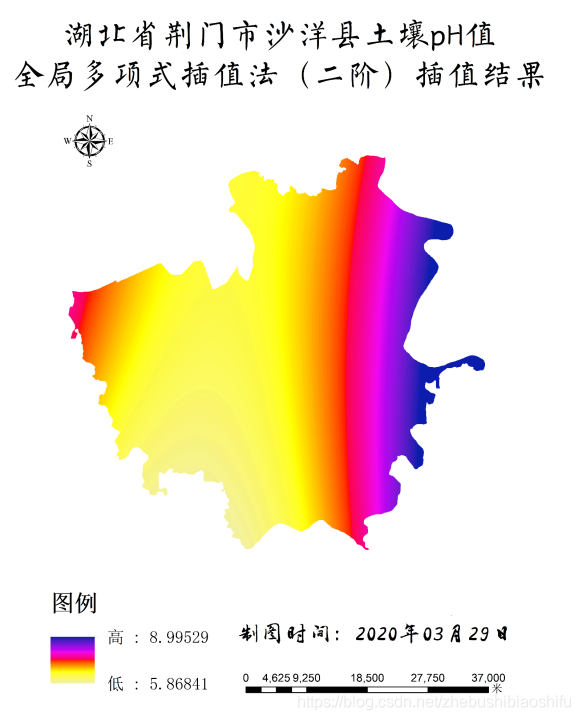



由上述四幅专题地图可知,三阶多项式插值所得结果较之二阶多项式普遍具有更广的数值范围,如二阶pH值插值地图中最大结果为8.99,而其三阶插值则可达到10.34;同样,二阶有机质含量插值地图中最小结果为8.91,而其三阶插值则可低至5.53。针对这一现象,个人认为可能是由于三阶多项式插值曲面弯曲程度较之二阶多项式插值更大,平滑效应较之二阶多项式不明显,因此其所能达到的数值范围亦较大。
另一方面,由专题地图这一角度观之,可以发现pH值与有机质含量分布具有一定空间关系:pH值较高区域,有机质含量往往较低(主要集中于沙洋县东部地区);反之,有机质含量则往往较高(主要集中于沙洋县中、西部地区)。而这一结果也符合“土壤有机质与pH值之间具有较高负相关关系”的结论[2]。
依据本文前述方法,取初始p=2,并依据插值效果适当调整,多次重复执行逆距离加权法,得到pH值、有机质含量等两种空间属性数据的插值结果与各精度指标。得到结果如表9所示。

由表9可知,面向pH值与有机质含量的逆距离加权法插值效果在上述四个精度衡量指标中表现并不是特别理想,较之前述全局多项式插值法(包括二阶、三阶)结果误差略大。尤其是有机质含量逆距离加权法结果的均方根误差,其平均数值已达5.10左右,说明各次IDW方法的有机质含量插值结果与实测点观测值之间差异(即残差)的样本标准差较大。此外,逆距离加权法有机质含量插值结果的平均相关系数未高于0.50。而与有机质含量相比,pH值的插值结果各项精度衡量指标整体稍优;由此可以看出,pH值的逆距离加权法插值效果整体精度较好于有机质含量;而这可能与两种属性数据各自内部的空间相关性、数值取值、分布特征等有关。由整体精度衡量指标来看,编程实现的逆距离加权法效果较之全局多项式插值法略差。
另一方面,在多次执行逆距离加权法插值过程中发现,每次执行效果精度差异变化较大;尤其是有机质含量,有时上述各项精度指标可以达到一个很好的水平,而有时则较差,如均方根误差甚至有时可达8左右。由此抑或可以看出,逆距离加权法作为一种局部插值方法,其执行效果所受到训练数据与测试数据的选取情况影响较大。
pH值与有机质含量的逆距离加权法插值三维结果分别如下两幅图所示。


通过本文前述部分的相关方法,将MATLAB插值数据结果文件导入ArcMap,经过剪裁后制作湖北省荆门市沙洋县土壤pH值、有机质含量逆距离加权法插值专题地图。


由上述两幅专题地图可知,逆距离加权法插值所得结果较之全局多项式插值法,生成的表面起伏变化数量更多、程度更大,而起伏所影响的范围则较小;且如前所述,逆距离加权法得到的插值结果具有较多小范围的中心分布区域,即插值专题图中可见包含若干气泡状小点分布的属性数据特征。此外,pH值与有机质含量的分布特征及其二者间的空间相互关系依然同全局多项式插值法结果,即二者数据大小间呈现出相反状态,沙洋县中、西部地区pH值相对较低而有机质含量较高,东部地区则pH值相对较高而有机质含量较低。
同时,正如本文第一部分所述,由于逆距离加权法是一种局部插值法,每一待插点的插值结果均很大程度上受到其临近点数值的影响;因此上述空间分布特征亦只是其结果的整体趋势,其中也会有部分特例。例如,结合上述两幅专题地图可以看到,逆距离加权法所得pH值插值结果在沙洋县西部地区亦有部分局部极大值点,而这些极大值点的数值甚至与东部地区持平;同时,其有机质含量插值结果在沙洋县中、西部地区亦存在零星散布的局部极小值点。
%% 文件信息读入 clc;clear; info=xlsread('data.xls'); opoX=info(:,1); opoY=info(:,2); oPH=info(:,3); % oOM=info(:,4); % oTN=info(:,5); %% 2S法计算异常值 mPH=mean(oPH); sPH=std(oPH); num2=find(oPH>(mPH+2*sPH)|oPH<(mPH-2*sPH)); %% 异常值剔除 PH=oPH; for i=1:length(num2) n=num2(i,1); PH(n,:)=[0]; end PH(all(PH==0,2),:)=[]; poX=opoX; for i=1:length(num2) n=num2(i,1); poX(n,:)=[0]; end poX(all(poX==0,2),:)=[]; poY=opoY; for i=1:length(num2) n=num2(i,1); poY(n,:)=[0]; end poY(all(poY==0,2),:)=[]; %% 验证集筛选 very=[randperm(length(PH),floor(length(PH)*0.2))]'; %% 验证集剔除 cPH=PH; vPH=zeros(length(very),1); vpoX=vPH; vpoY=vPH; for i=1:length(very) m=very(i,1); vPH(i,:)=cPH(m,:); cPH(m,:)=[0]; end cPH(all(cPH==0,2),:)=[]; cpoX=poX; for i=1:length(very) m=very(i,1); vpoX(i,:)=cpoX(m,:); cpoX(m,:)=[0]; end cpoX(all(cpoX==0,2),:)=[]; cpoY=poY; for i=1:length(very) m=very(i,1); vpoY(i,:)=cpoY(m,:); cpoY(m,:)=[0]; end cpoY(all(cpoY==0,2),:)=[]; %% 最小二乘法求解预处理 inva2=[ones(size(cpoX)),cpoX.^2,cpoY.^2,cpoX.*cpoY,cpoX,cpoY]; inva3=[ones(size(cpoX)),cpoX.^3,cpoY.^3,(cpoX.^2).*cpoY,cpoX.*(cpoY.^2),cpoX.^2,cpoY.^2,cpoX.*cpoY,cpoX,cpoY]; %% 最小二乘法求解 [coef2,bint2,r2,rint2,stats2]=regress(cPH,inva2); [coef3,bint3,r3,rint3,stats3]=regress(cPH,inva3); %% 趋势面法效果图绘制准备 step=50; npoX=600800:step:664500; npoY=3364600:step:3425000; [mnpX,mnpY]=meshgrid(npoX,npoY); %% 趋势面法插值 pPH2=coef2(1,:)+coef2(2,:)*mnpX.^2+coef2(3,:)*mnpY.^2+coef2(4,:)*mnpX.*mnpY+coef2(5,:)*mnpX+coef2(6,:)*mnpY; pPH3=coef3(1,:)+coef3(2,:)*mnpX.^3+coef3(3,:)*mnpY.^3+coef3(4,:)*(mnpX.^2).*mnpY+coef3(5,:)*mnpX.*(mnpY.^2)+coef3(6,:)*mnpX.^2+coef3(7,:)*mnpY.^2+coef3(8,:)*mnpX.*mnpY+coef3(9,:)*mnpX+coef3(10,:)*mnpY; %% 趋势面法效果图绘制 scatter3(cpoX,cpoY,cPH); hold on; mesh(mnpX,mnpY,pPH2); title('Global Polynomial Interpolation Results of Quadratic of Organic Matter'); figure(); scatter3(cpoX,cpoY,cPH); hold on; mesh(mnpX,mnpY,pPH3); title('Global Polynomial Interpolation Results of Cubic of Organic Matter'); %% 趋势面法精度对比 vpPH2=coef2(1,:)+coef2(2,:)*vpoX.^2+coef2(3,:)*vpoY.^2+coef2(4,:)*vpoX.*vpoY+coef2(5,:)*vpoX+coef2(6,:)*vpoY; MEERan2=mean(vPH-vpPH2); MEERan21=mean(abs(vpPH2-vPH)); RMSEan2=sqrt(sum(vpPH2-vPH).^2/length(vPH)); COCOan2=corrcoef(vpPH2,vPH); vpPH3=coef3(1,:)+coef3(2,:)*vpoX.^3+coef3(3,:)*vpoY.^3+coef3(4,:)*(vpoX.^2).*vpoY+coef3(5,:)*vpoX.*(vpoY.^2)+coef3(6,:)*vpoX.^2+coef3(7,:)*vpoY.^2+coef3(8,:)*vpoX.*vpoY+coef3(9,:)*vpoX+coef3(10,:)*vpoY; MEERan3=mean(vPH-vpPH3); MEERan31=mean(abs(vpPH3-vPH)); RMSEan3=sqrt(sum(vpPH3-vPH).^2/length(vPH)); COCOan3=corrcoef(vpPH3,vPH); %% 趋势面法导出ASCII save 3.txt pPH2 -ASCII; save 4.txt pPH3 -ASCII;复制
%% 文件信息读入 clc;clear; info=xlsread('data.xls'); opoX=info(:,1); opoY=info(:,2); oPH=info(:,3); power=2; % oOM=info(:,4); % oTN=info(:,5); %% 2S法计算异常值 mPH=mean(oPH); sPH=std(oPH); num2=find(oPH>(mPH+2*sPH)|oPH<(mPH-2*sPH)); %% 异常值剔除 PH=oPH; for i=1:length(num2) n=num2(i,1); PH(n,:)=[0]; end PH(all(PH==0,2),:)=[]; poX=opoX; for i=1:length(num2) n=num2(i,1); poX(n,:)=[0]; end poX(all(poX==0,2),:)=[]; poY=opoY; for i=1:length(num2) n=num2(i,1); poY(n,:)=[0]; end poY(all(poY==0,2),:)=[]; %% 验证集筛选 very=[randperm(length(PH),floor(length(PH)*0.2))]'; %% 验证集剔除 cPH=PH; vPH=zeros(length(very),1); vpoX=vPH; vpoY=vPH; for i=1:length(very) m=very(i,1); vPH(i,:)=cPH(m,:); cPH(m,:)=[0]; end cPH(all(cPH==0,2),:)=[]; cpoX=poX; for i=1:length(very) m=very(i,1); vpoX(i,:)=cpoX(m,:); cpoX(m,:)=[0]; end cpoX(all(cpoX==0,2),:)=[]; cpoY=poY; for i=1:length(very) m=very(i,1); vpoY(i,:)=cpoY(m,:); cpoY(m,:)=[0]; end cpoY(all(cpoY==0,2),:)=[]; %% IDW效果图绘制准备 step=50; npoX=600800:step:664500; npoY=3364600:step:3425000; [mnpX,mnpY]=meshgrid(npoX,npoY); %% IDW分母计算 temdeno=zeros(1,length(cPH)); deno=zeros(length(npoY),length(npoX)); for p=1:length(npoY) for q=1:length(npoX) for i=1:length(cPH) temdeno(1,i)=(sqrt((npoY(1,p)-cpoY(i,1))^2+(npoX(1,q)-cpoX(i,1))^2))^(-power); end deno(p,q)=sum(temdeno(:)); end end %% IDW求解 temPH=zeros(1,length(cPH)); pPH4=zeros(length(npoY),length(npoX)); for p=1:length(npoY) for q=1:length(npoX) for i=1:length(cPH) temPH(1,i)=cPH(i,1).*((sqrt((npoY(1,p)-cpoY(i,1))^2+(npoX(1,q)-cpoX(i,1))^2))^(-power))./deno(p,q); end pPH4(p,q)=sum(temPH(:)); end end %% IDW效果图绘制 scatter3(cpoX,cpoY,cPH); hold on; mesh(mnpX,mnpY,pPH4); title('IDW Results of Organic Matter'); %% IDW验证1 temdeno4=zeros(1,length(cPH)); deno4=zeros(length(vpoY),length(vpoX)); for p=1:length(vpoY) for q=1:length(vpoX) for i=1:length(cPH) temdeno4(1,i)=(sqrt((vpoY(p,1)-cpoY(i,1))^2+(vpoX(q,1)-cpoX(i,1))^2))^(-power); end deno4(p,q)=sum(temdeno4(:)); end end %% IDW验证2 temPH4=zeros(1,length(cPH)); vpPH4=zeros(length(vpoY),1); for p=1:length(vpoY) for i=1:length(cPH) temPH4(1,i)=cPH(i,1).*((sqrt((vpoY(p,1)-cpoY(i,1))^2+(vpoX(q,1)-cpoX(i,1))^2))^(-power))./deno4(p,q); end vpPH4(p,1)=sum(temPH4(:)); end %% 精度计算 MEERan4=mean(vPH-vpPH4); MEERan41=mean(abs(vpPH4-vPH)); RMSEan4=sqrt(sum(vpPH4-vPH).^2/length(vPH)); COCOan4=corrcoef(vpPH4,(vPH)'); %% 文件转存 save 5ph.txt pPH4 -ASCII;复制
[1] 曹祥会,龙怀玉,周脚根,等.河北省表层土壤有机碳和全氮空间变异特征性及影响因子分析[J].植物营养与肥料学报,2016,22(04):937-948.
[2] 戴万宏,黄耀,武丽,俞佳.中国地带性土壤有机质含量与酸碱度的关系[J].土壤学报,2009,46(05):851-860.