ES的多客户端并发更新是基于乐观并发控制,通过版本号机制来实现冲突检测。
ES的老版本是用过_version字段的版本号实现乐观锁的。现在新版增加了基于_seq_no与_primary_term字段,三个字段做乐观锁并发控制。
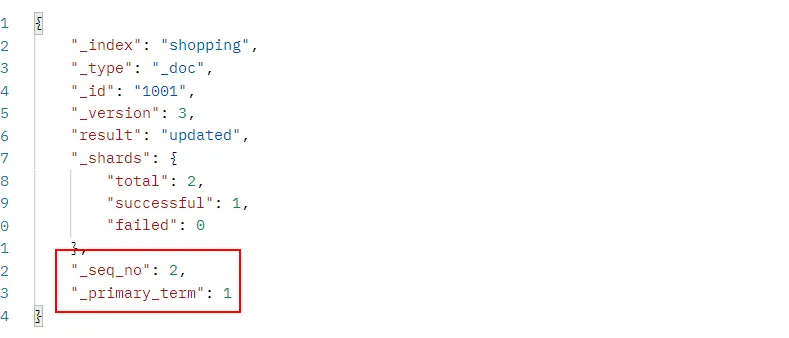
_version:标识文档的版本号,只有当前文档的更新,该字段才会累加;以文档为维度。
_seq_no:标识整个Index中的文档的版本号,只要Index中的文档有更新,就会累加该字段值;以Index为维度记录文档的操作顺序。
_primary_term:针对故障导致的主分片重启或主分片切换,每发生一次自增1;已分片为维度。
原先修改指定版本的请求参数是_version;目前修改指定版本的请求参数只能是
PUT user/_doc/1?if_seq_no=22&if_primary_term=2复制
乐观锁的操作主要就是两个步骤:
参考乐观锁的版本号,JDK提供了一个AtomicStampedReference类,在CAS的基础上增加了一个Stamp(印戳或标记),使用这个印戳可以用来觉察数据是否发生变化,给数据带上了一种实效性的检验。
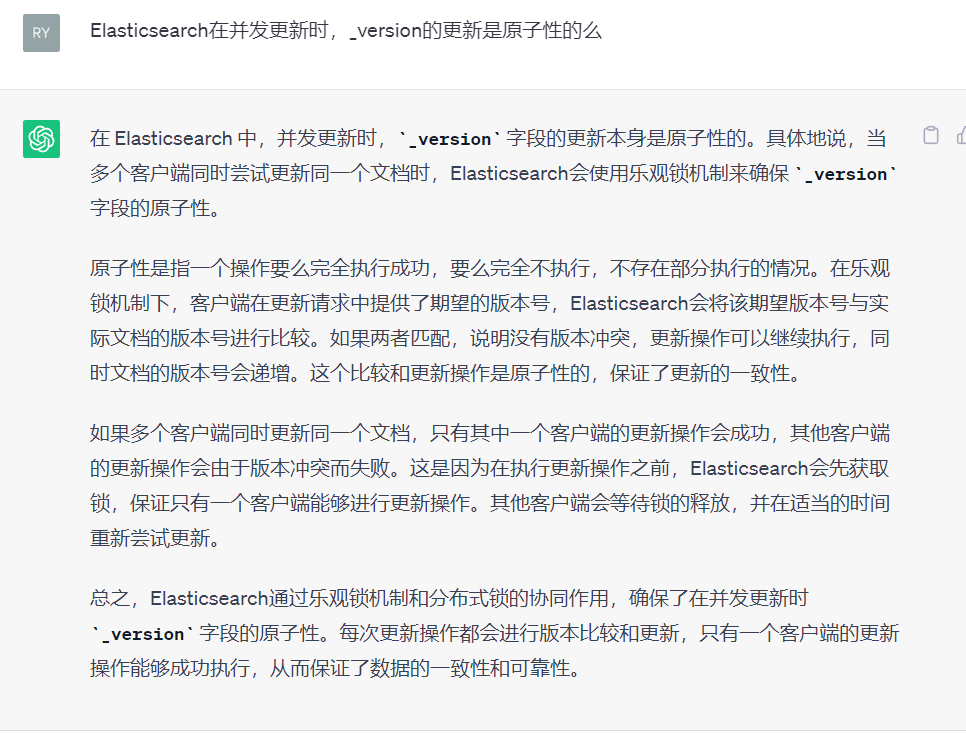
为什么要说到这个?网上很多资料就是一笔带过ES是通过乐观锁版本号来实现并发控制的,我就纳闷,仅仅通过版本号怎么实现的?ES的乐观锁实现就是类似AtomicStampedReference原理。其流程大致如下:
获取当前文档的最新版本号:在更新操作开始之前,Elasticsearch会获取当前文档的最新版本号。
检查版本号冲突:客户端在更新请求中提供了要更新文档的版本号,服务器会将客户端提供的版本号与实际文档的最新版本号进行比较。
如果客户端提供的版本号与实际文档的最新版本号一致,表示没有冲突,操作可以继续进行。
如果客户端提供的版本号与实际文档的最新版本号不一致,表示发生了版本冲突,更新操作会被拒绝并抛出VersionConflictEngineException异常。
原子性更新版本号:如果没有发生版本冲突,Elasticsearch会对文档的版本号进行原子性的更新。这意味着在更新过程中,其他并发的更新请求会被阻塞,直到当前更新操作完成。
更新文档内容:在版本号更新完成后,Elasticsearch会执行实际的文档更新操作,包括更新字段的值、添加或删除字段等。
这个过程就是一个典型的read-then-update的过程,ES保证原子事务。其实在并发更新下,哪怕是基于乐观锁多版本号控制,是一定要通过某种机制保证冲突检测与数据更新的原子性;并不是简单的一句多版本控制实现了乐观锁(是我自己较真了)。
翻了下GPT,如下是给出的回复。佐证了我的猜想(源码看了下,翻不动!)
乐观锁出现版本冲突时,ES提供了相应的机制获取冲突
List<VersionConflict> conflicts = response.getGetResult().getConflicts();复制
同时还可以配置重试策略,因为一般情况下,都是可以通过重试解决的,ES中配置retry_on_confict即可。