好家伙,写爬虫
代码:


import requests import re import os from collections import Counter import xlwt # 创建Excel文件 workbook = xlwt.Workbook(encoding='utf-8') worksheet = workbook.add_sheet('url_list') # 将数据写入Excel文件 worksheet.write(0, 0, '序号') #写入对应的字段 worksheet.write(0, 1, '图片详细地址') worksheet.write(0, 2, '图片TAG') def get_response(html_url): headers ={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.43' } response = requests.get(url=html_url,headers=headers) return response def get_img_src(html_url): #获取榜单地址 response =get_response(html_url) list_url =re.findall('<img src="(.*?)"',response.text) return list_url def get_img_src_ciping(html_url): #获取榜单地址 response =get_response(html_url) # print(response.text) list_url =re.findall('title="(.*?)">',response.text) if(list_url): return list_url[0] else: return "无内容" url = 'https://wallspic.com/cn/topic/pc_wallpapers' response = get_response(html_url=url) html_code = response.text # print(html_code) # 定义正则表达式匹配模式 pattern = r'"link":"(.*?)"' # 使用re.findall()方法获取所有匹配结果 result_list = re.findall(pattern, html_code) cleaned_urls_1 = [] for url in result_list: cleaned_url = url.replace("\\/\\/", "/") cleaned_url = url.replace("\\/", "/") cleaned_urls_1.append(cleaned_url) print(cleaned_url) cleaned_urls_2 = [] cleaned_urls_3 = [] for url in cleaned_urls_1: # 使用os.path.splitext()方法将URL路径拆分为文件名和扩展名 filename, ext = os.path.splitext(url) # 判断扩展名是否为.jpg if ext.lower() == '.jpg': cleaned_urls_2.append(url) if ext.lower() != '.jpg' and ext.lower() !='.webp': cleaned_urls_3.append(url) # print(cleaned_urls_2) save_dir = 'C:/Users/10722/Desktop/python答辩/canuse/img/' # 指定保存路径 if not os.path.exists(save_dir): os.makedirs(save_dir) #下载图片 row = 1 for url in cleaned_urls_2: worksheet.write(row, 0, row+1) #将排行写入excel表格 worksheet.write(row, 1, url) #将歌名写入excel表格 filename = os.path.basename(url) # 获取文件名 filepath = os.path.join(save_dir, filename) # 拼接保存路径和文件名 response = requests.get(url) with open(filepath, 'wb') as f: f.write(response.content) print(f'{filename} 下载完成') row+=1 print('全部图片下载完成') cleaned_urls_4 =[] roww = 1 for url in cleaned_urls_3: # print(url) response=get_img_src_ciping(html_url=url) # print(response) worksheet.write(roww, 2, response) #将tag写入excel表格 roww+=1 cleaned_urls_4.append(response) print(cleaned_urls_4) # urls=str(cleaned_urls_4) # 将数组中的字符串拼接成一个长字符串 long_string = " ".join(cleaned_urls_4) # 使用空格将长字符串分割成一个单词列表 word_list = long_string.split() # 使用Counter对单词列表进行词频统计 word_counts = Counter(word_list) words =str(word_counts) worksheet.write(roww, 2, words) #将歌手写入excel表格 print(word_counts) workbook.save('C:/Users/10722/Desktop/python答辩/canuse/图片详情.xls')复制
效果展示
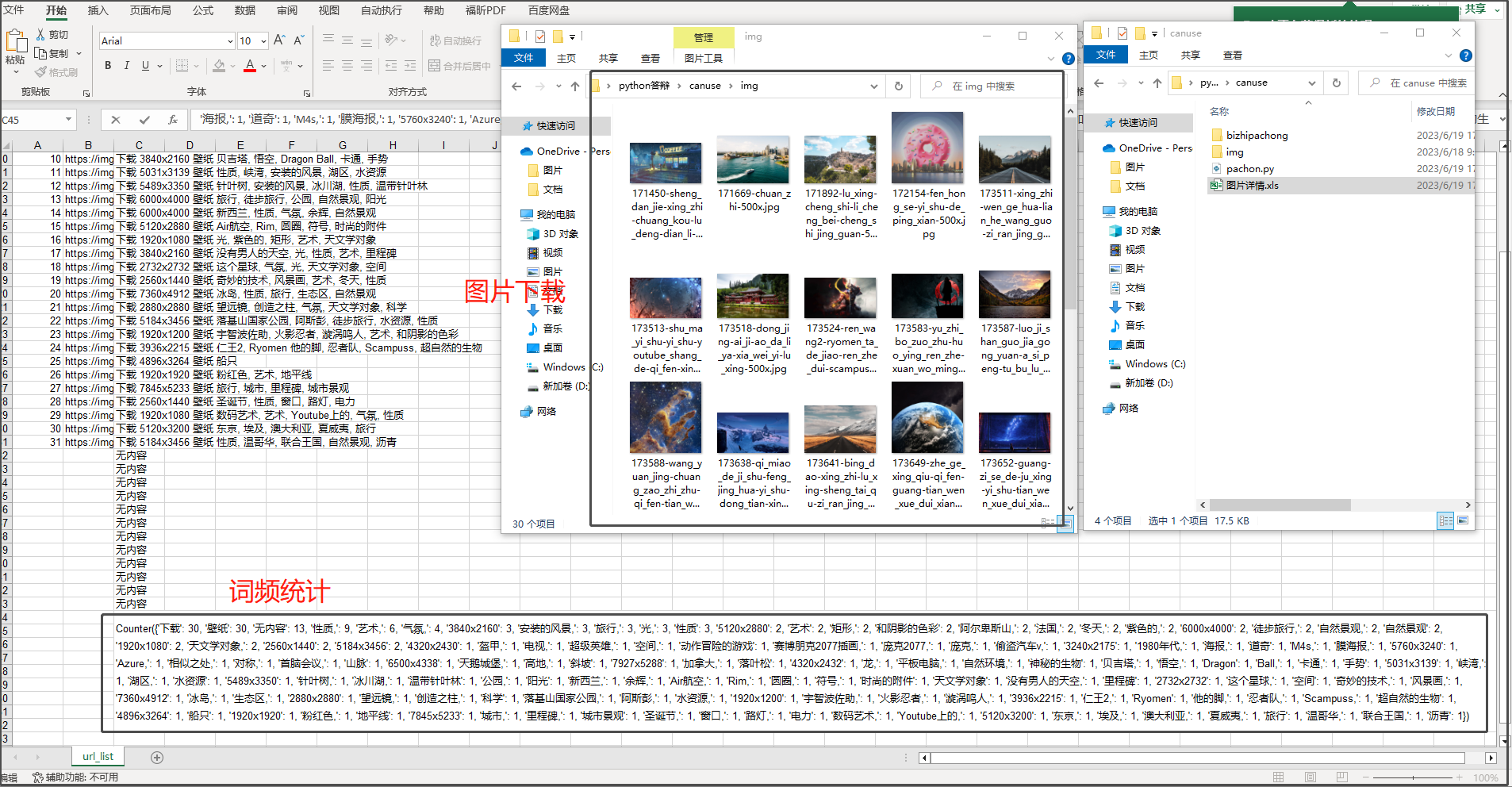
上次爬虫去答辩了,爬的酷狗音乐的某个排行榜,
老师问我为什么没有把音乐也爬下来,
然后去翻了一下,这个音乐加密有点超出我的能力范围了(他真的太会藏了)

重写吧
我决定换个网站,爬个图片吧
找个壁纸网站
最佳 电脑壁纸 [30000+] |在 Wallspic 上免费下载
看上去好爬
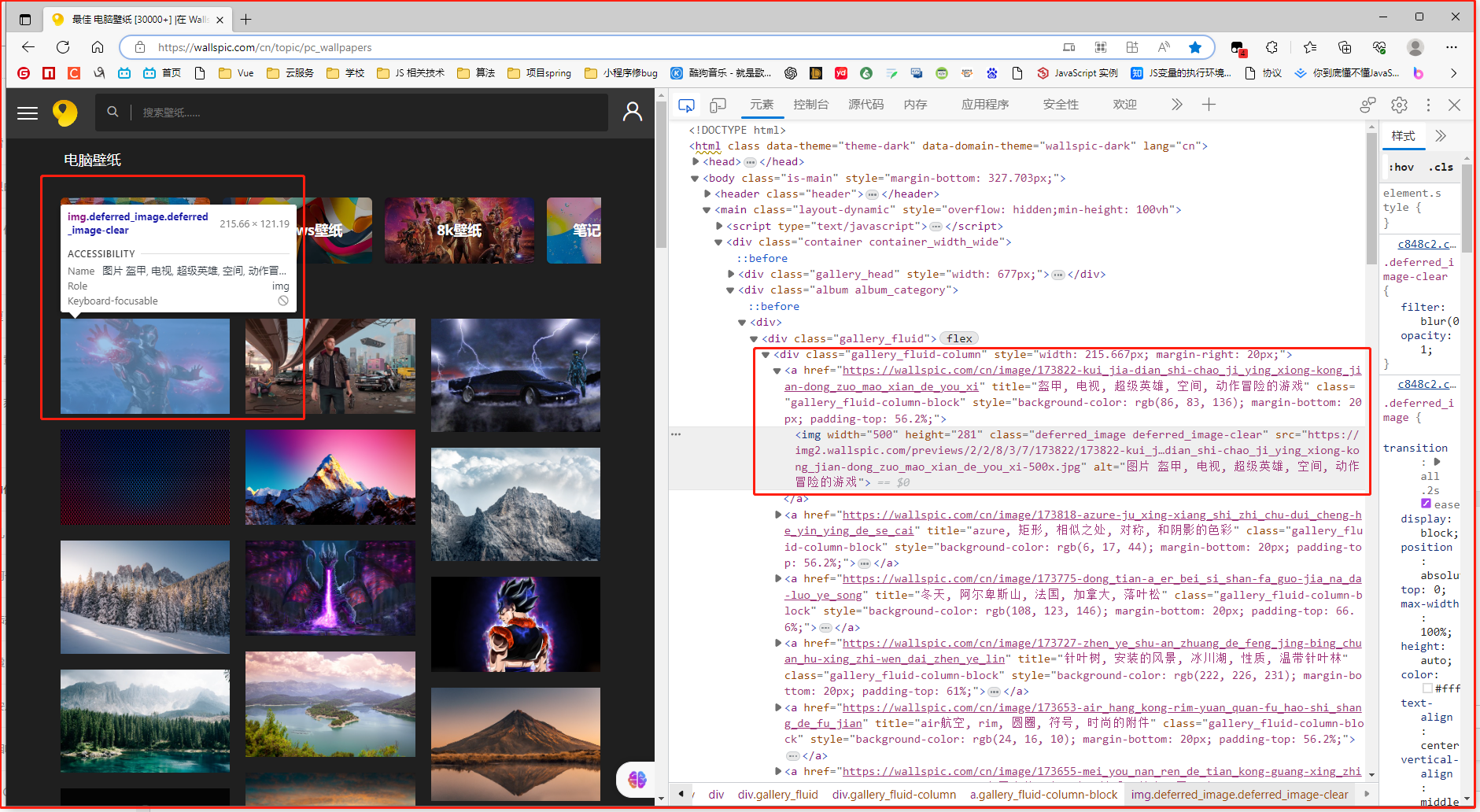
可以直接拿到图片的src
开干!
依旧按照以下思路进行
1.发请求,随后拿到服务器发过来的.html文件
2.用正则表达式去套对应的,我们需要的数据
3.处理数据,最后把他们以某种方式呈现
url = 'https://wallspic.com/cn/topic/pc_wallpapers' response = get_response(html_url=url) html_code = response.text print(html_code)复制
来看看拿到的.html文本
我们并不能很直观的直接拿到<img>标签中的src
他似乎是通过某种方式注入
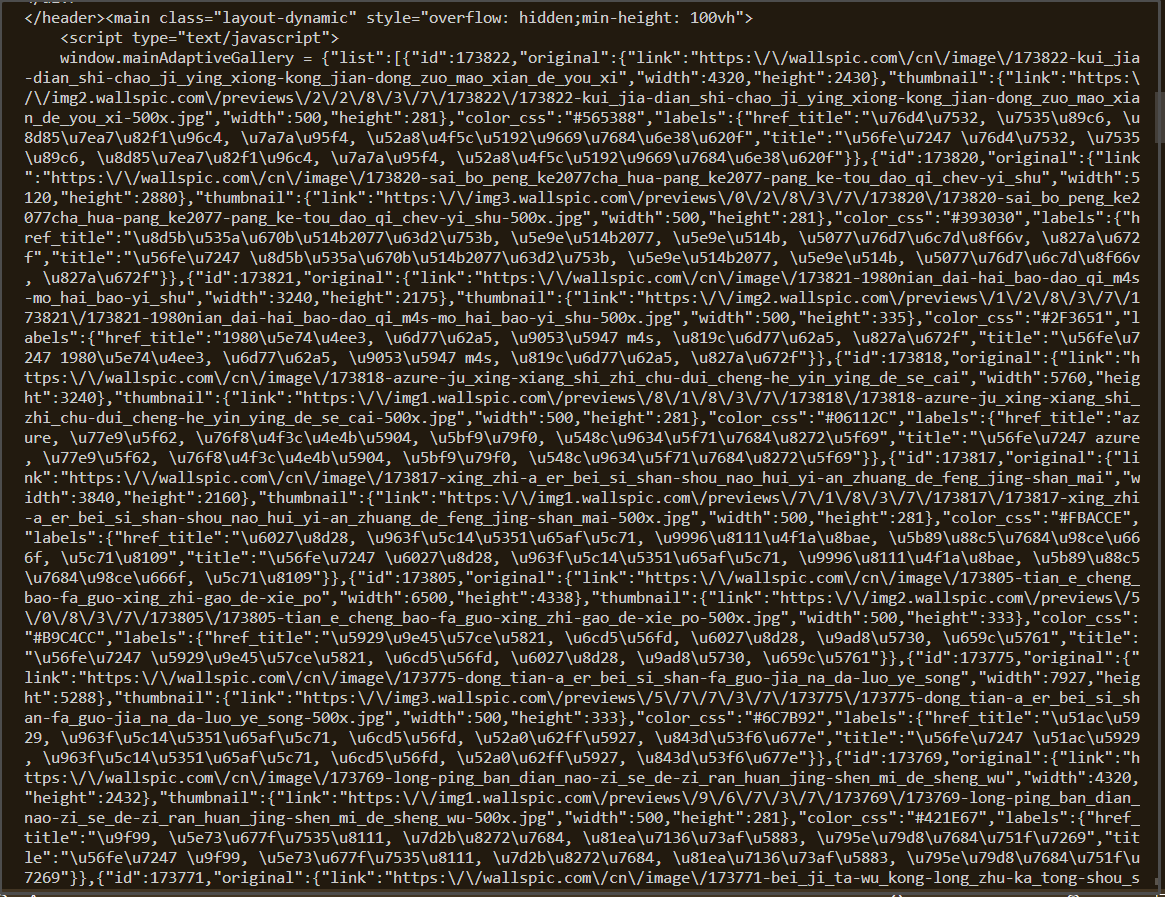

但是没有太大问题,我们依旧能够找到其中的src
用一个方法()把他们"过滤出来"
cleaned_urls_1 = [] for url in result_list: cleaned_url = url.replace("\\/\\/", "/") cleaned_url = url.replace("\\/", "/") cleaned_urls_1.append(cleaned_url) print(cleaned_url)复制
来看看
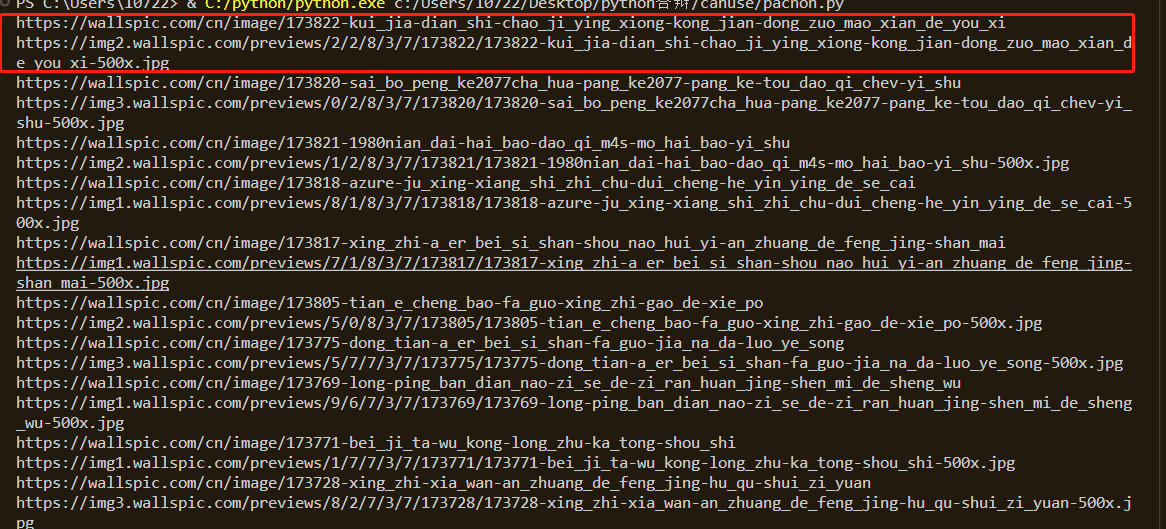
这里可以看到,在这些地址中,以两条为一组,其中,第一条为该壁纸的详情页,第二条为该壁纸的真正src
随后,可以想个办法把他们分别放到不同的数组中
cleaned_urls_2 = [] cleaned_urls_3 = [] for url in cleaned_urls_1: # 使用os.path.splitext()方法将URL路径拆分为文件名和扩展名 filename, ext = os.path.splitext(url) # 判断扩展名是否为.jpg if ext.lower() == '.jpg': cleaned_urls_2.append(url) if ext.lower() != '.jpg' and ext.lower() !='.webp': cleaned_urls_3.append(url)复制
这里偷个懒,直接使用第三方插件os去做一个拆分,然后用ext.lower拿到他们的后缀,再进行一个判断
把两种地址分类,把他们放到不同的数组中,
详情页在后面有用,要对图片的TAG进行一个词频统计
save_dir = 'C:/Users/10722/Desktop/python答辩/canuse/img/' # 指定保存路径 if not os.path.exists(save_dir): os.makedirs(save_dir) #下载图片 row = 1 for url in cleaned_urls_2: worksheet.write(row, 0, row+1) #将排行写入excel表格 worksheet.write(row, 1, url) #将歌名写入excel表格 filename = os.path.basename(url) # 获取文件名 filepath = os.path.join(save_dir, filename) # 拼接保存路径和文件名 response = requests.get(url) # with open(filepath, 'wb') as f: # f.write(response.content) # print(f'{filename} 下载完成') row+=1 print('全部图片下载完成')复制
这里用response发一个get请求就可以了,
这里同样的,我们去到图片的详情页,然后用一个正则表达式去套图片的TAG
def get_img_src_ciping(html_url): #获取榜单地址 response =get_response(html_url) # print(response.text) list_url =re.findall('title="(.*?)">',response.text) if(list_url): return list_url[0] else: return "无内容"复制
再使用插件collections去统计词频
cleaned_urls_4 =[] roww = 1 for url in cleaned_urls_3: # print(url) response=get_img_src_ciping(html_url=url) # print(response) worksheet.write(roww, 2, response) #将tag写入excel表格 roww+=1 cleaned_urls_4.append(response) print(cleaned_urls_4) # urls=str(cleaned_urls_4) # 将数组中的字符串拼接成一个长字符串 long_string = " ".join(cleaned_urls_4) # 使用空格将长字符串分割成一个单词列表 word_list = long_string.split() # 使用Counter对单词列表进行词频统计 word_counts = Counter(word_list) words =str(word_counts)复制
然后就,搞定啦
完整代码:
import requests import re import os from collections import Counter import xlwt # 创建Excel文件 workbook = xlwt.Workbook(encoding='utf-8') worksheet = workbook.add_sheet('url_list') # 将数据写入Excel文件 worksheet.write(0, 0, '序号') #写入对应的字段 worksheet.write(0, 1, '图片详细地址') worksheet.write(0, 2, '图片TAG') def get_response(html_url): headers ={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.43' } response = requests.get(url=html_url,headers=headers) return response def get_img_src(html_url): #获取榜单地址 response =get_response(html_url) list_url =re.findall('<img src="(.*?)"',response.text) return list_url def get_img_src_ciping(html_url): #获取榜单地址 response =get_response(html_url) # print(response.text) list_url =re.findall('title="(.*?)">',response.text) if(list_url): return list_url[0] else: return "无内容" url = 'https://wallspic.com/cn/topic/pc_wallpapers' response = get_response(html_url=url) html_code = response.text # print(html_code) # 定义正则表达式匹配模式 pattern = r'"link":"(.*?)"' # 使用re.findall()方法获取所有匹配结果 result_list = re.findall(pattern, html_code) cleaned_urls_1 = [] for url in result_list: cleaned_url = url.replace("\\/\\/", "/") cleaned_url = url.replace("\\/", "/") cleaned_urls_1.append(cleaned_url) print(cleaned_url) cleaned_urls_2 = [] cleaned_urls_3 = [] for url in cleaned_urls_1: # 使用os.path.splitext()方法将URL路径拆分为文件名和扩展名 filename, ext = os.path.splitext(url) # 判断扩展名是否为.jpg if ext.lower() == '.jpg': cleaned_urls_2.append(url) if ext.lower() != '.jpg' and ext.lower() !='.webp': cleaned_urls_3.append(url) # print(cleaned_urls_2) save_dir = 'C:/Users/10722/Desktop/python答辩/canuse/img/' # 指定保存路径 if not os.path.exists(save_dir): os.makedirs(save_dir) #下载图片 row = 1 for url in cleaned_urls_2: worksheet.write(row, 0, row+1) #将排行写入excel表格 worksheet.write(row, 1, url) #将歌名写入excel表格 filename = os.path.basename(url) # 获取文件名 filepath = os.path.join(save_dir, filename) # 拼接保存路径和文件名 response = requests.get(url) # with open(filepath, 'wb') as f: # f.write(response.content) # print(f'{filename} 下载完成') row+=1 print('全部图片下载完成') cleaned_urls_4 =[] roww = 1 for url in cleaned_urls_3: # print(url) response=get_img_src_ciping(html_url=url) # print(response) worksheet.write(roww, 2, response) #将tag写入excel表格 roww+=1 cleaned_urls_4.append(response) print(cleaned_urls_4) # urls=str(cleaned_urls_4) # 将数组中的字符串拼接成一个长字符串 long_string = " ".join(cleaned_urls_4) # 使用空格将长字符串分割成一个单词列表 word_list = long_string.split() # 使用Counter对单词列表进行词频统计 word_counts = Counter(word_list) words =str(word_counts) worksheet.write(roww, 2, words) #将歌手写入excel表格 print(word_counts) workbook.save('C:/Users/10722/Desktop/python答辩/canuse/图片详情.xls') # <img width="500" height="281" class="deferred_image deferred_image-clear" src="https://img2.wallspic.com/previews/2/2/8/3/7/173822/173822-kui_jia-dian_shi-chao_ji_ying_xiong-kong_jian-dong_zuo_mao_xian_de_you_xi-500x.jpg" alt="图片 盔甲, 电视, 超级英雄, 空间, 动作冒险的游戏">复制