公司有一个推荐系统Rec,这个系统的主要功能是:
Rec作为微服务中的一环,本身不存储召回的物料信息,也不存储用户和物料的特征信息,它负责就是对各个服务的组合和流转
其流程如下:
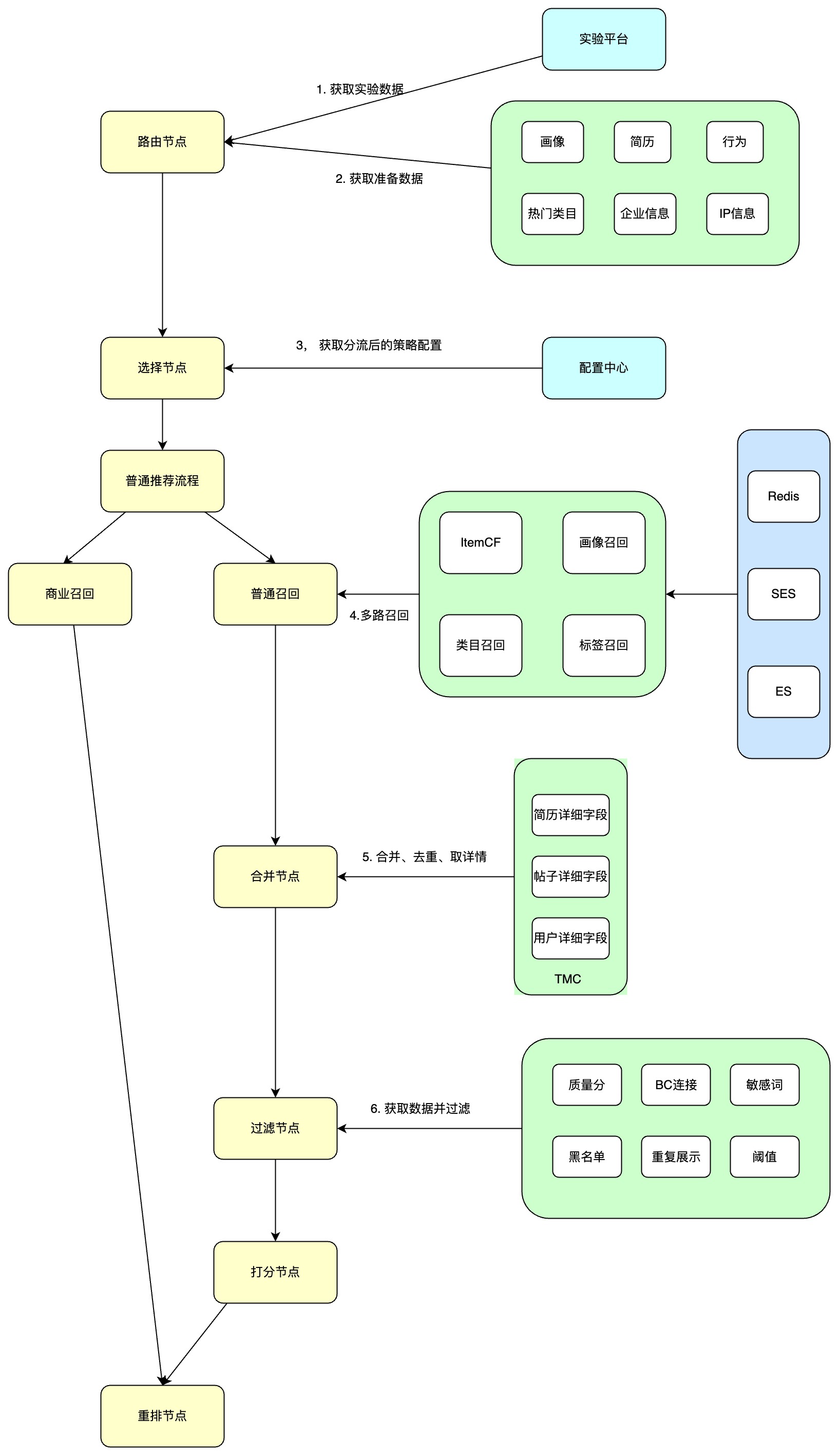
在开发Rec的过程中,发现流程中存在可以优化的地方,例如:
| 流程 | 问题 |
|---|---|
| “合并节点”需要等待所有的召回结果完成之后merge到一个List,然后去获取详情信息 | 获取详情信息是一个需要分批的IO操作,既然需要分批,为什么不是每个召回完成就去获取详情,而要等待合并。即使不需要分批,获取详情也会随着召回结果的数量变多而耗时变长 |
| “过滤节点”需要先准备过滤的数据,等所有数据准备好,再进行过滤 | 获取数据是IO操作,过滤是CPU密集操作,是不是可以获取完一部分数据就可以立即进行过滤 |
上述的问题是纯粹从性能方面去考虑,目前的流程从逻辑是更容易理解的
我们分析上述问题,并提出了的初步的优化方式
我们还要考虑下面几个问题:
上面提出的两个问题本质上是属于流程统筹方面的问题,在这个流程中,我们还是可以找到一些别的优化的地方:
例如“路由节点获取准备数据”是不是可以不用等待,提交完异步任务之后直接继续,在使用的时候去直接拿,如果发现还没有拿到数据就等着,有数据就直接使用,而不是原来的等待拿到数据再继续下一步
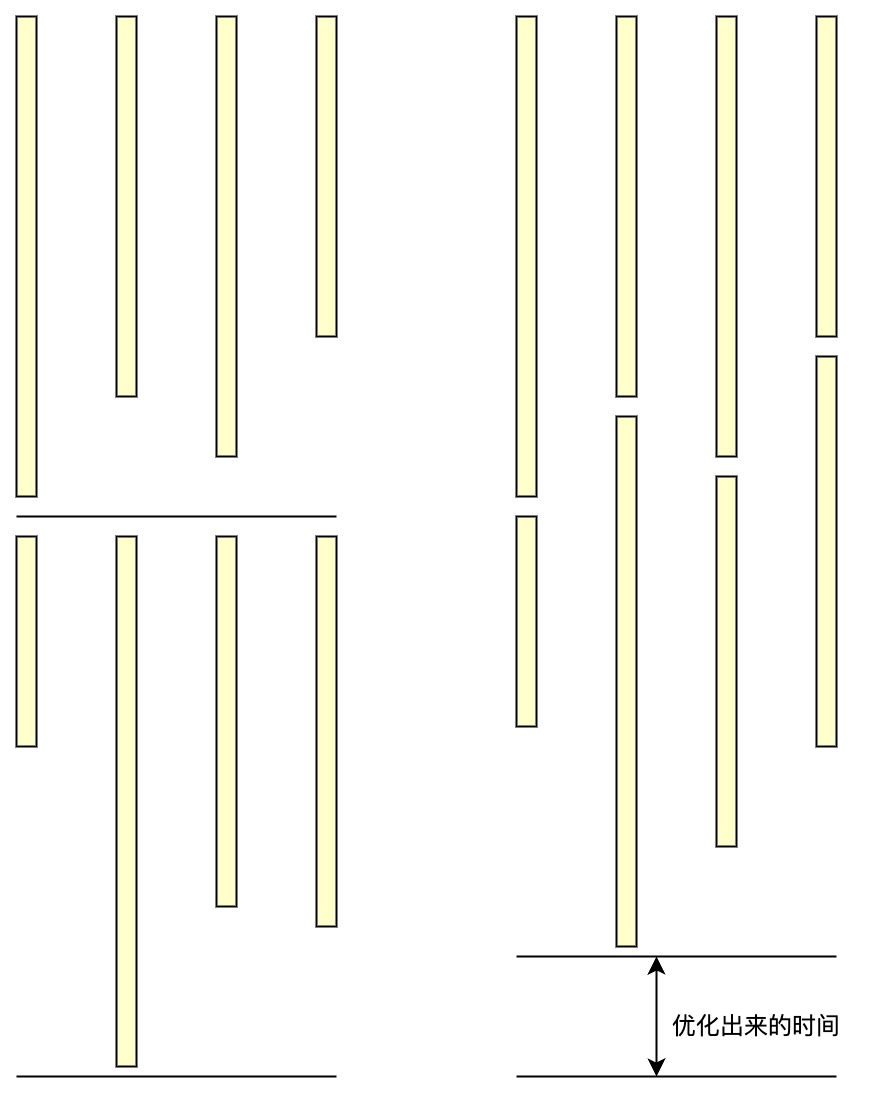
当存在多个获取任务时,会缩短执行的时间,举个例子:
原先的流程:都使用线程池都来完成,合并前花费10ms,合并后花费10ms,总耗时20ms
新的流程:都使用线程池都来完成,总耗时15ms
上述的流程图展示出来和上面的提出的两个问题属于一类,但这个问题不能简单改变流程,因为:
所以我们需要使用一些异步编程的手段,在流程不变的情况下,还能使其执行的更快,下面表示优化的时间是从哪来的:
在调研的过程中,发现了很多相关的技术:
Java中提供Future可以满足我们异步的需要吗?
如果只是一个异步任务,例如画像召回需要等待画像数据,我们可以在画像召回中使用future.get()
但在画像召回完成之后,我们要进行过滤,需要提前准备一些数据,例如已展示推荐数据,使用future.get()让画像召回变成了同步任务,在获取结果之前无法继续
项目目前就是使用了线程池+Future的方案,不过future.get()都在线程池submit之后
针对上述问题, JDK8设计出CompletableFuture。CompletableFuture提供了一种观察者模式类似的机制,可以让任务执行完成后通知监听的一方
利用CompletableFuture,我们可以这样写:
CompletableFuture recallFuture = CompletableFuture
.supplyAsync(获取画像数据任务)
.thenApply(画像召回)
.thenAccept(获取召回信息过滤数据)
CompletableFuture filterDataFuture = CompletableFuture
.supplyAsync(获取过滤数据任务)
recallFuture.thenCombineAsync(filterDataFuture, (s, w) -> {过滤数据 });
复制看起来CompletableFuture已经可以满足我们的需求了,为什么需要再了解Reactor呢?它们有什么差别?
官方参考手册通过对比Callback、CompletableFuture和Reactor,它们都可以实现异步功能,但CompletableFuture/Future有下面的缺点
Future objects are a bit better than callbacks, but they still do not do well at composition, despite the improvements brought in Java 8 by CompletableFuture. Orchestrating multiple Future objects together is doable but not easy. Also, Future has other problems:
It is easy to end up with another blocking situation with Future objects by calling the get() method.
They do not support lazy computation.
They lack support for multiple values and advanced error handling.
future.get()就进入到了阻塞,这种情况很容易出现除此之外,官方参考手册介绍了一些其他特点,参考3.3
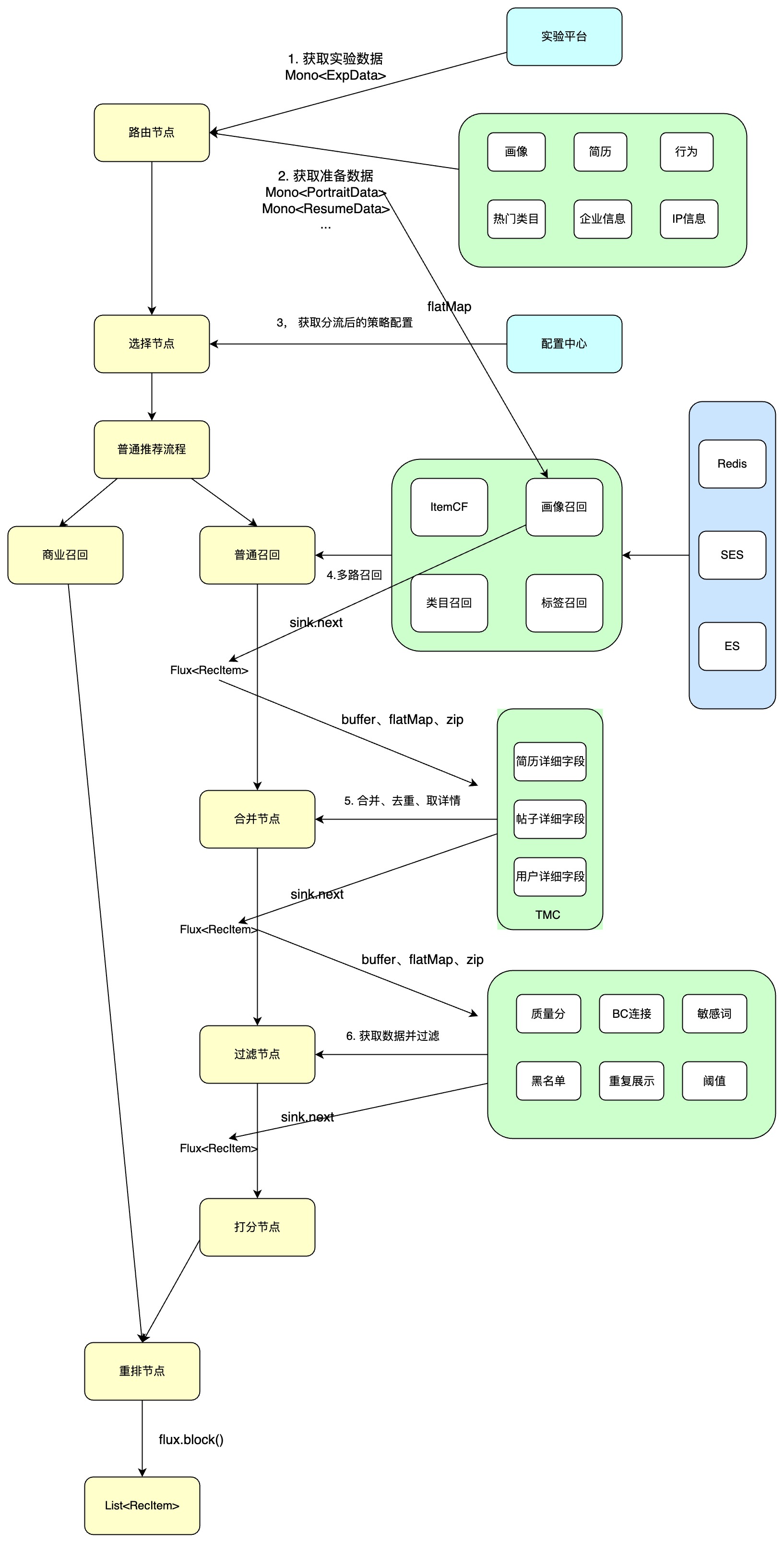
如何使用Reactor实现上述功能呢?
Mono<String> recallMono = Mono
.fromCallable(() -> "获取画像数据")
.flatMap((portraitData) -> Mono.fromCallable(() -> "画像召回"))
.flatMap((recItemData) -> Mono.fromCallable(() -> "获取召回信息过滤数据"));
Mono<String> filterDataMono = Mono
.fromCallable(() -> "获取过滤数据任务");
Mono.zip(recallMono, filterDataMono).filter((t)->true);
复制Java大部分的library都是同步的(HttpClient,JDBC),Mono可以和Future组合使用线程来实现异步任务,Java也存在一些异步库例如Netty,Redis Luttuce.
至于为什么会提到Quasar,贝壳技术 | 响应式编程和协程在 Java 语言的应用中介绍了响应式编程和协程一起使用的场景,给出了原因:
我个人觉得响应式编程本质是从统筹学来优化程序的,最著名的例子就是烧水泡茶流程,我们只不过是通过合理编排让硬件资源最大化利用。
具体实现是将原本同步逻辑中的片段打散到不同的线程中去异步执行,原本同步阻塞的线程这时候可以给别的任务使用,应该会减少更多线程的使用
待更新
[1] 贝壳技术 | 响应式编程和协程在 Java 语言的应用
[2] 异步编程利器:CompletableFuture详解 |Java 开发实战
[3] Reactor Java文档
[4] 并发模型之Actor和CSP
[5] RxJava VS Reactor
[6] CompletableFuture原理与实践-外卖商家端API的异步化