年前,收到了短信报警,显示A服务的某台机器内存过高,超过80%
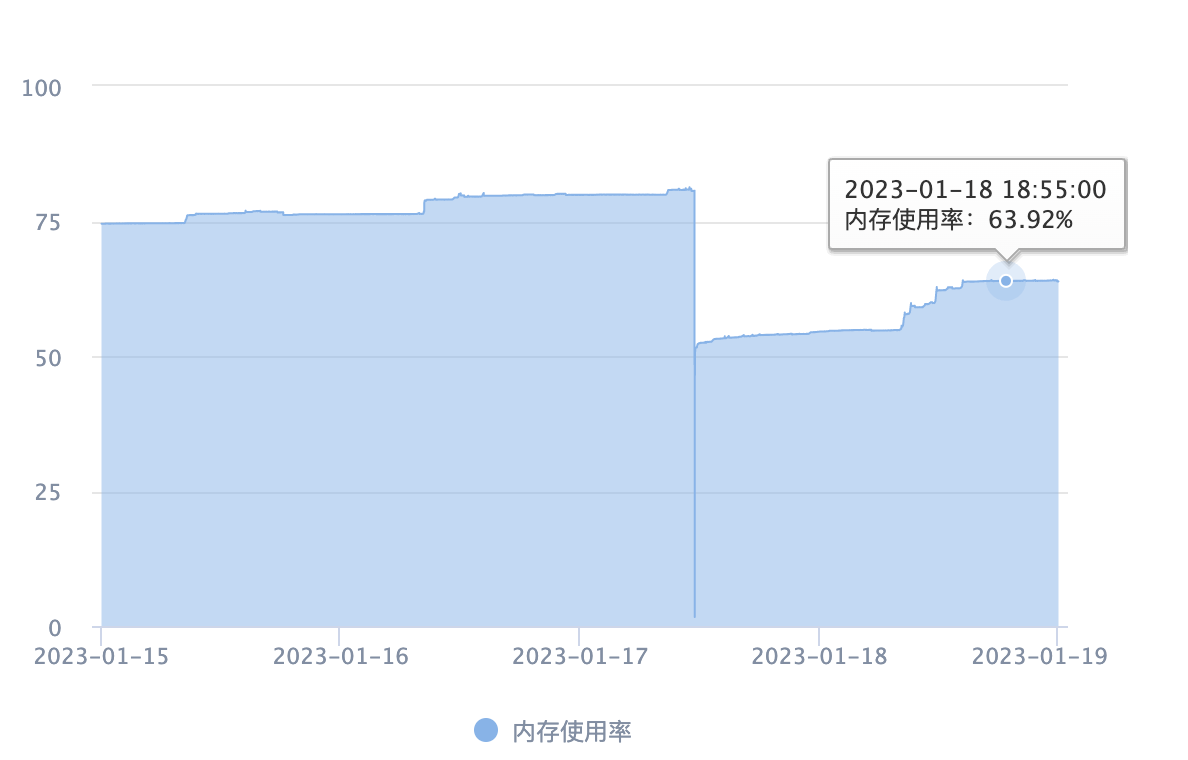
如上图所示,内存会阶段性增加。奇怪的是,十多台机器中只有这一台有这个问题
最先怀疑是内存泄漏的问题,所以首先使用jmap命令把堆dump下来
jmap -dump:format=b,file=service.hprof 1948
用MAT分析堆文件发现了一个奇怪的问题,下载下来7G的文件MAT显示的Size只有700M
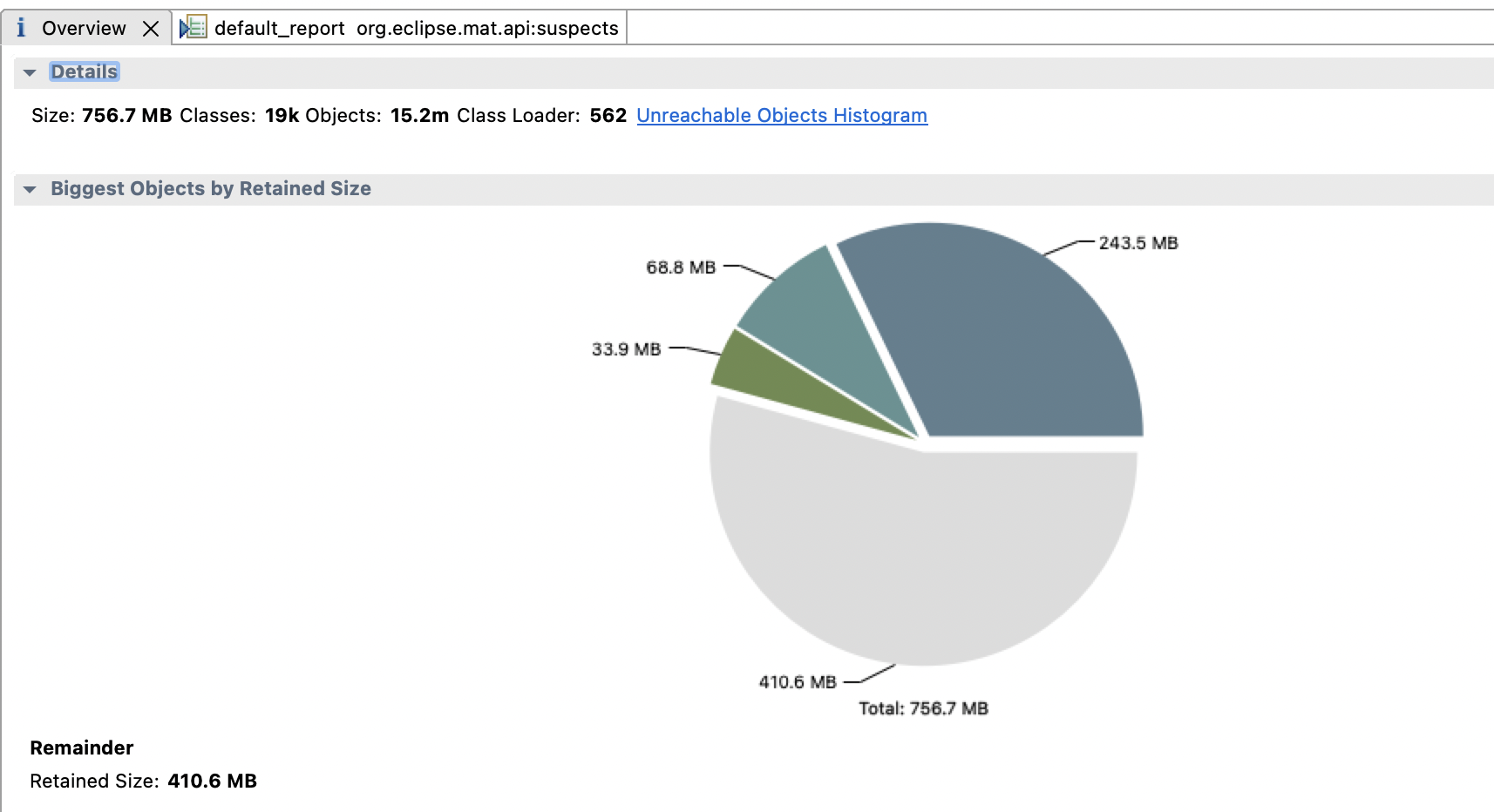
后来知道不加live选项会把堆中所有的对象dump下来,即使是已经是垃圾的对象
参考 what are "live" objects in java heap? (heap dump with jmap)
live 选项会在讲堆内容dump到文件时,强制做一次fullGC,剩下的就是live对象,也就是从GC Root可以寻达的对象
为什么有时不能用live呢,因为fullGC可能会让应用卡主,不能接受这种情况适用不增加live选项
后来我重新使用了live选项dump下来有900M
jmap -dump:live,file=live-dump.bin <pid>
首先用MAT的Leak Suspect看一下
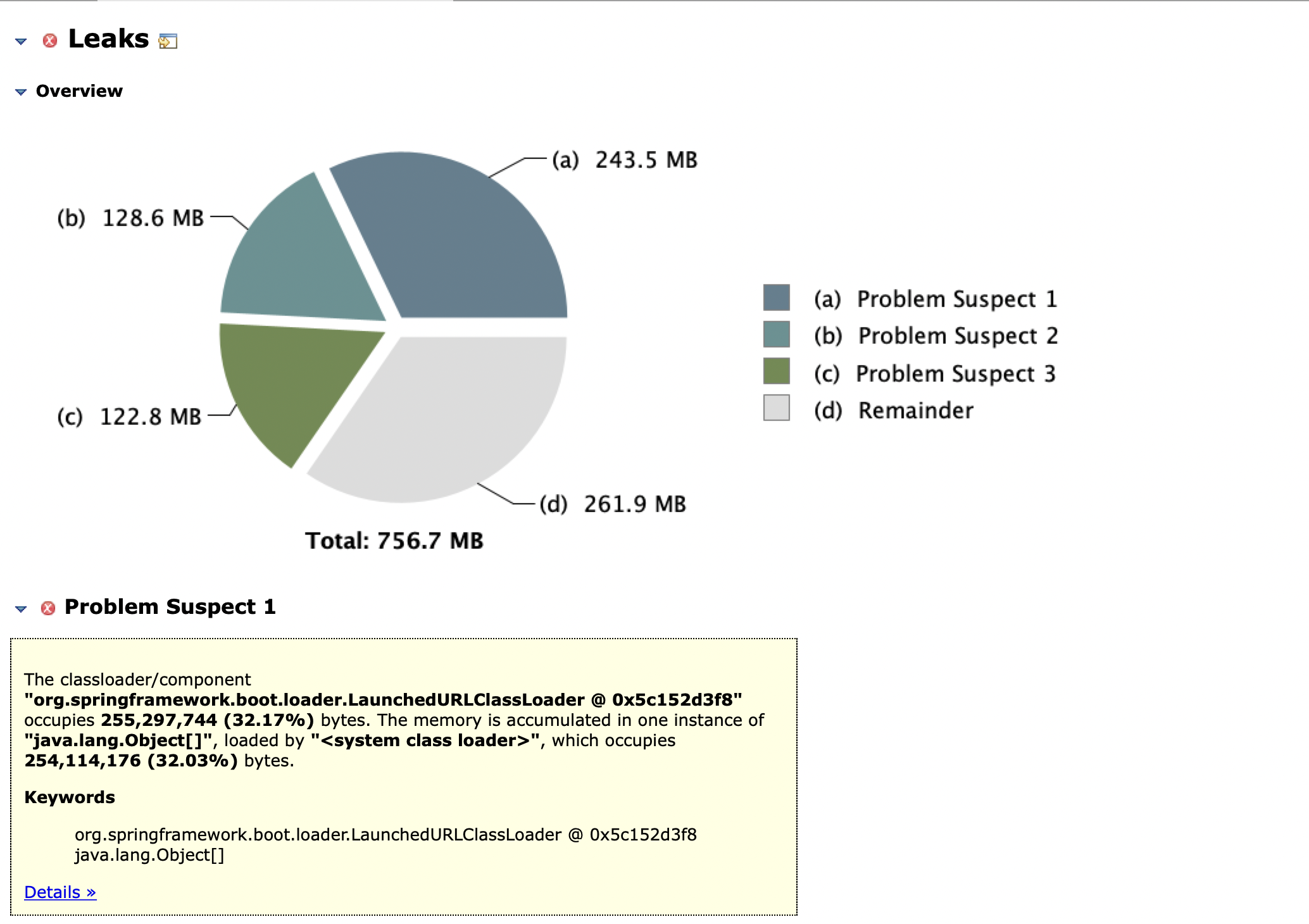
看到了org.springframework.boot.loader.LaunchedURLClassLoader这个对象有240M
因为一直不太清楚live选项的原因,所以就想用其他工具看看这7G到底都是什么

把hprof拖入IDEA,就可以看到上图,上面分析了所有的对象,从占用的大小就可以看出来
其中的Shallow表示的是:
对象本身占用内存的大小,也就是对象头加成员变量(不是成员变量的值)的总和
Retained表示的是:
如果一个对象被释放掉,那会因为该对象的释放而减少引用进而被释放的所有的对象(包括被递归释放的)所占用的heap大小,即对象被垃圾回收器回收后能被GC从内存中移除的所有对象之和。
具体参考一文让你理解什么是shallow heap及retained heap
我们把前几名的Shallow加起来也有好几G了
也可以点进Object[]查看这700多万的对象数组都是什么

可以看到一个占用450M的Object[10240]属于LaunchedURLClassLoader

上图中可以看到这450M中TagCateSimilarityUtils占了200M, 这是一个本地缓存,虽然占的多了一点,通过比对正常服务器的堆转储,是没有问题的
查看int[]对象时,发现了很多Retained是0的对象,也就是说这些对象已经是不可达对象,只不过还没有被回收,那是不是就是只要让这些对象回收了,内存占用就下来了

上面分析中看到了很多对象没有被回收,怀疑是没有FullGC(Mixed)所以老年代中的垃圾对象,一直都没回收,看了一下JVM参数
-Xmx8g -Xms8g -Xmn4g -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=512m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:G1HeapRegionSize=32m -Dfastjson.parser.safeMode=true
调整为,删除了一些默认和不生效的参数,移除了Xmn,交给G1自己调整
-Xmx8g -Xms8g -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:G1HeapRegionSize=32m -Dfastjson.parser.safeMode=true
不过并没有解决问题,此时我发现了新的问题:
这个问题和虚拟内存和实际内存有关,可以参考linux top命令 实存(RES)与虚存(VIRT)详解
VIRT:
1、进程“需要的”虚拟内存大小,包括进程使用的库、代码、数据,以及malloc、new分配的堆空间和分配的栈空间等;
2、假如进程新申请10MB的内存,但实际只使用了1MB,那么它会增长10MB,而不是实际的1MB使用量。
RES:
1、进程当前使用的内存大小
2. 如果申请10MB的内存,实际使用1MB,它只增长1MB,与VIRT相反;
监控显示的内存是实际占用的内存,Xms设置的是虚拟内存,参考降低 Java 程序的“虚拟内存地址”占用
可以看出 Java Heap 与 Metaspace 紧挨着分配,两块一共占用了 3GB 的 Size(虚拟内存地址空间),而表征物理内存占用的 Rss 却只有 673288KB。也就是说,mmap 只是给进程分配一个线性区域(虚拟内存),并没有分配物理内存,只有当进程访问这块内存时,操作系统才会分配具体的内存页给进程,这就是 Linux 内存管理的延迟分配策略
内存一旦被分配给Java程序,就不会还给操作系统了,所以监控看起来内存就是只增不减,个人理解这样对于Java程序也是有好处的,不用频繁申请内存,对于垃圾的区域标记然后就可以重新写了
Java也存在JVM参数-XX:+AlwaysPreTouch 来实现启动就把堆内存全都申请到
为了抵消延迟分配策略,在进程启动时强制分配好 Java Heap 的物理内存,虽然增加了启动延时,但是可以减少进程运行时由于分配内存造成的延时
堆内内存是正常的,不存在内存泄漏,只是正常的内存使用增长
在搜索LaunchedURLClassLoader内存泄漏问题时,看到了Spring Boot引起的“堆外内存泄漏”排查及经验总结,学到了如何进行堆外内存分析
一次完整的JVM堆外内存泄漏java故障排查记录也是一篇值得学习的如何分析堆外内存的文章
不过我们问题产生的原因和上面的不一致
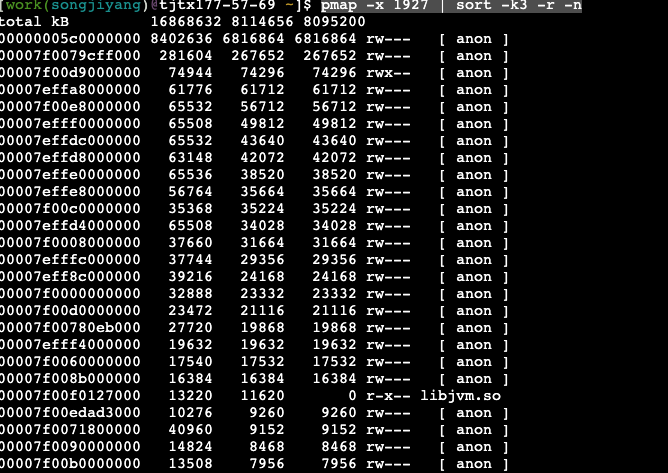
使用pmap分析应用的内存占用,但不太容易看出是什么占用了内存
pmap -x 1927 | sort -k3 -r -n
JVM的NativeMemoryTracking参数会看到更详细,不过需要重启,而且会有5%-10%的性能损耗
// 写在启动参数上面
-XX:NativeMemoryTracking=detail
// 生成内容在下图中
jcmd 1927 VM.native_memory detail scale=MB > temp3.txt
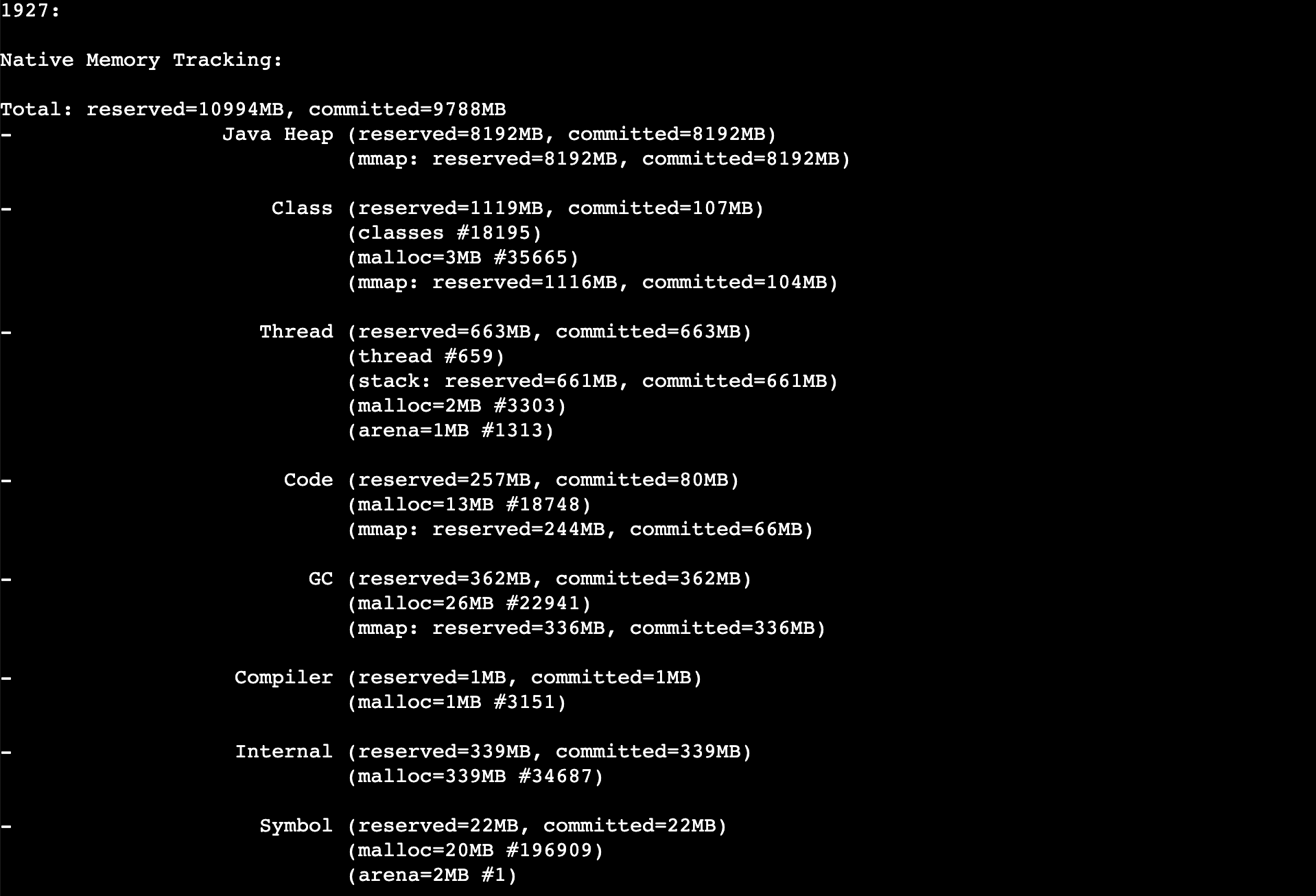
经过对堆外内存的观察,发现确实有一些比较高,例如线程占700M,发现了有很多不必要的线程,但不是随着时间不断增加的
上图中的Total一行的commited=9788MB,表示Java应用程序堆内加堆外内存最大可达这么多,这么一算12 * 0.8 = 9.6G,确实超了报警阈值
这样看来,堆外内存也没有问题,是Xmx和内存阈值设置的不匹配,导致内存正常使用的情况下报警了,也是没有合理预估堆外内存占用的原因,堆外占了快2G的内存
将报警阈值调到85%,发现内存在周期性的增长和减少,并不会超过阈值,如下图
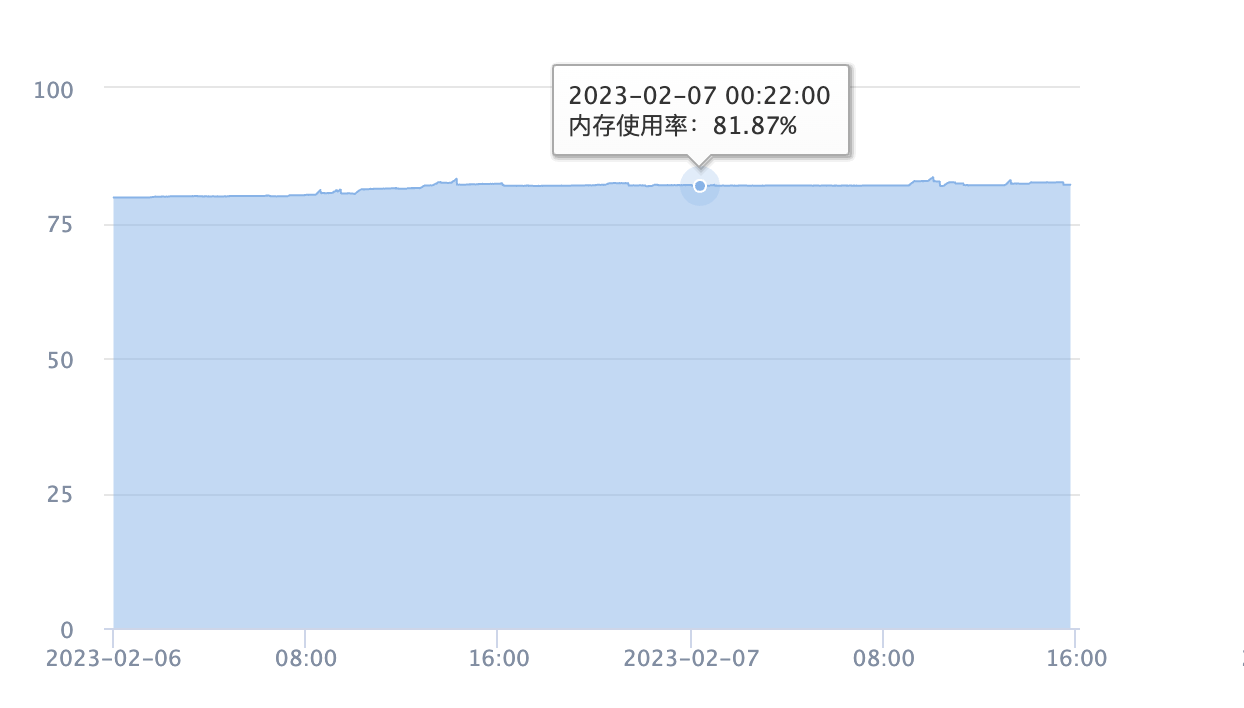
服务的内存使用情况是正常的,无论是堆内还是堆外内存,需要做的是设置合理的堆内存大小,预估堆外内存大小,合理设置报警阈值
通过这次分析也学习了如何对Java程序内存进行分析,也学习了很多工具
也意思到监控工具的重要性,在看别人分析的过程中,一般都会对JVM资源进行监控,这样就能很明显看出资源的动态,因为我们目前没有这样的工具,所以分析起来就比较麻烦
前面提到其中只有一台机器有这个现象,还没有找到原因,不过有几个现象:
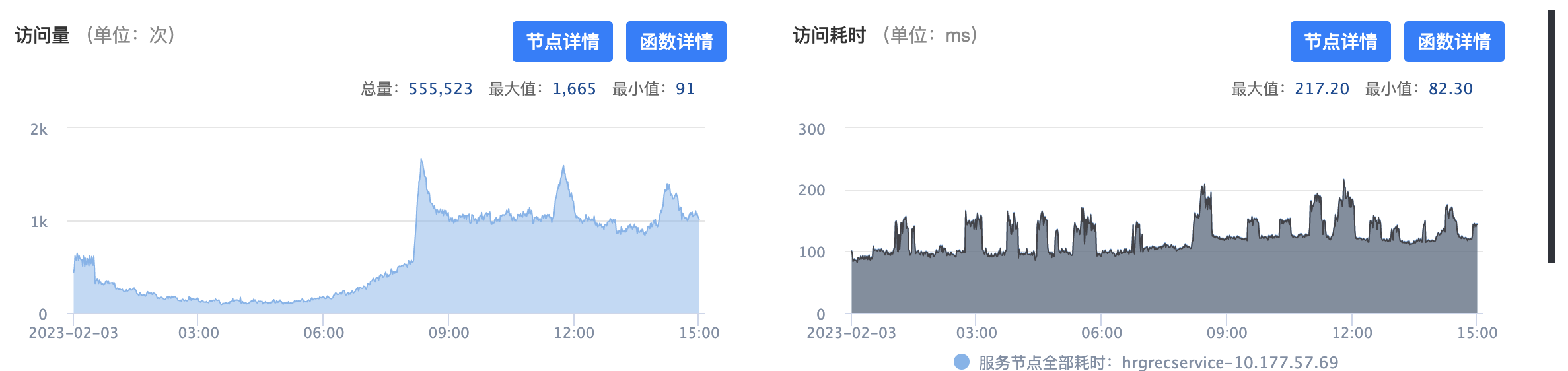
对比日志发现是Redis超时比较多,所以怀疑可能是机器网络的问题,不过目前还无结论
[1] 一文让你理解什么是shallow heap及retained heap
[2] linux top命令 实存(RES)与虚存(VIRT)详解
[3] 降低 Java 程序的“虚拟内存地址”占用
[4] 一次完整的JVM堆外内存泄漏java故障排查记录
[5] Spring Boot引起的“堆外内存泄漏”排查及经验总结