先说结论:通过优化Xms,改为和Xmx一致,使系统的超时率降了四分之三

一个同事说他负责的服务在一次上线之后超时率增加了一倍
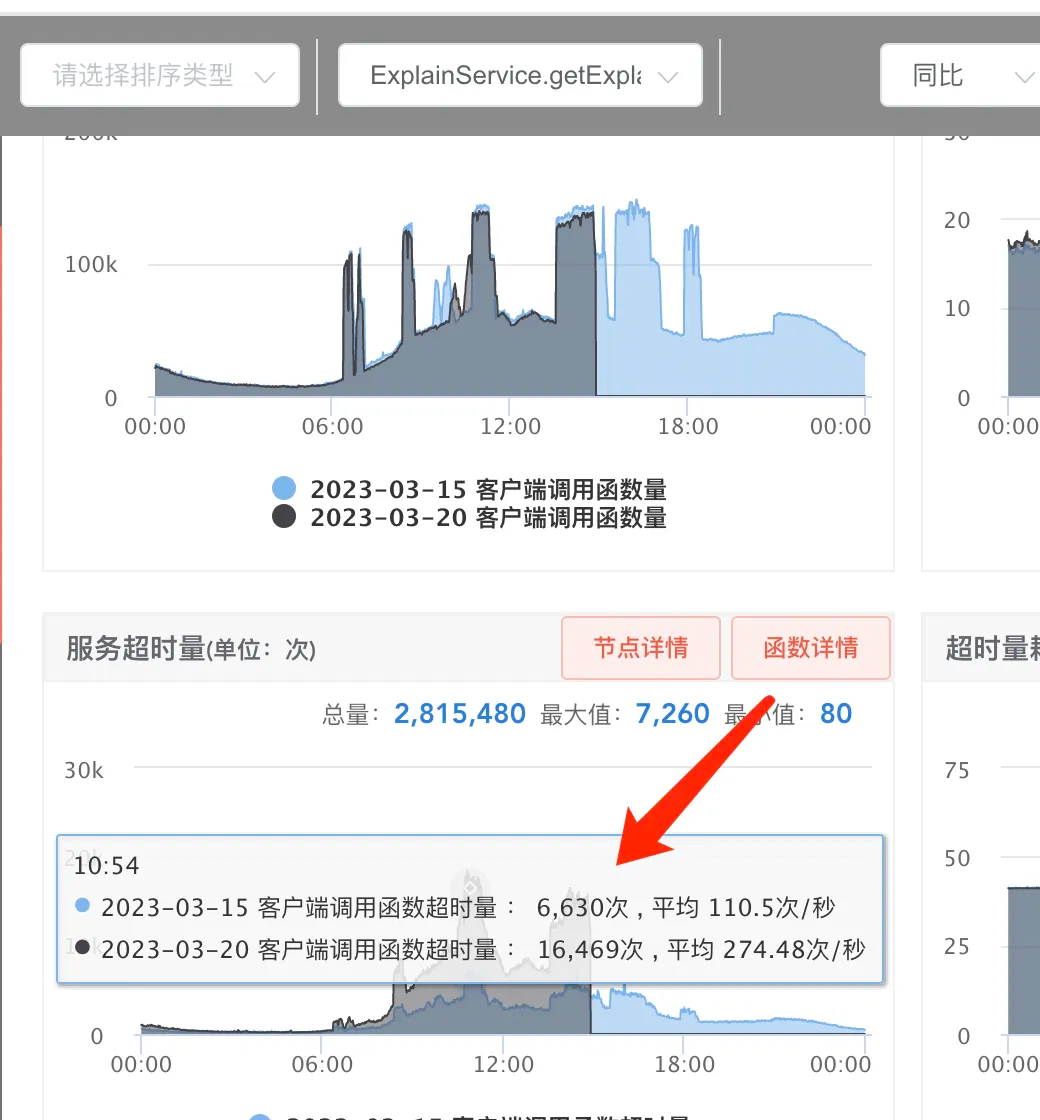
首先找了一台机器,看了监控
上线后最明显的变化就是CPU使用率变高了
上线只加了简单的判断条件,按理不应该导致CPU变高成这样
又发现了一个奇怪的现象是,在没有上线的情况下,CPU使用率突然降低了,然后就一直保持着很低的状态
CPU降低之后,超时率也有所降低,现在大概能理解超时是和CPU使用率有关的,可能存在CPU瓶颈
既然在没有上线的情况下,CPU使用率会降低,肯定有什么因素影响,猜测可能是依赖的服务,但依赖的服务太多,也没办法一个一个去看,哪个调用有问题
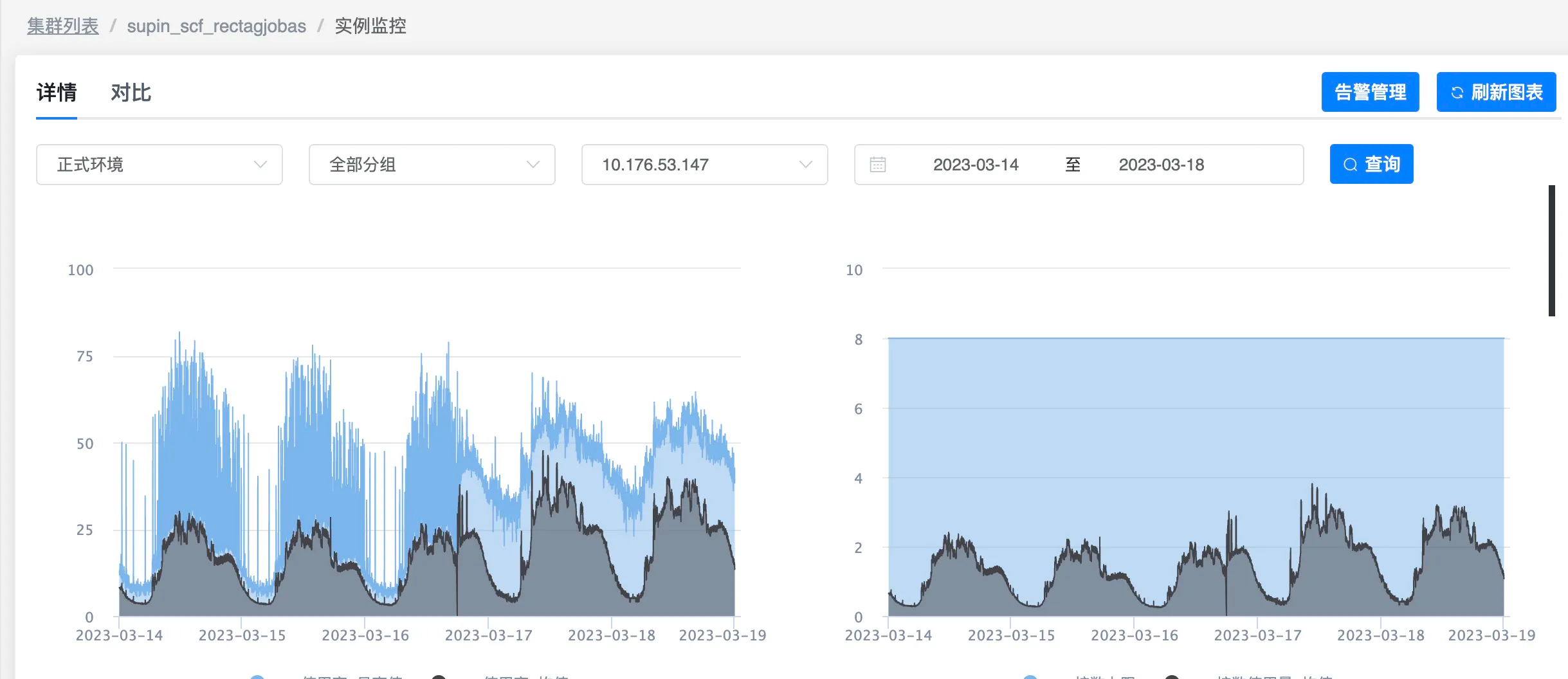
于是还是想在CPU使用率上找找问题,因为是上线导致的CPU使用率变高,所以看了其他上线时间的CPU使用率
还是有点思路了,发现大部分上线之后CPU使用率是会变高,部分没有(后面知道,因为有的上线本身就是优化,所以CPU使用率也会变低)
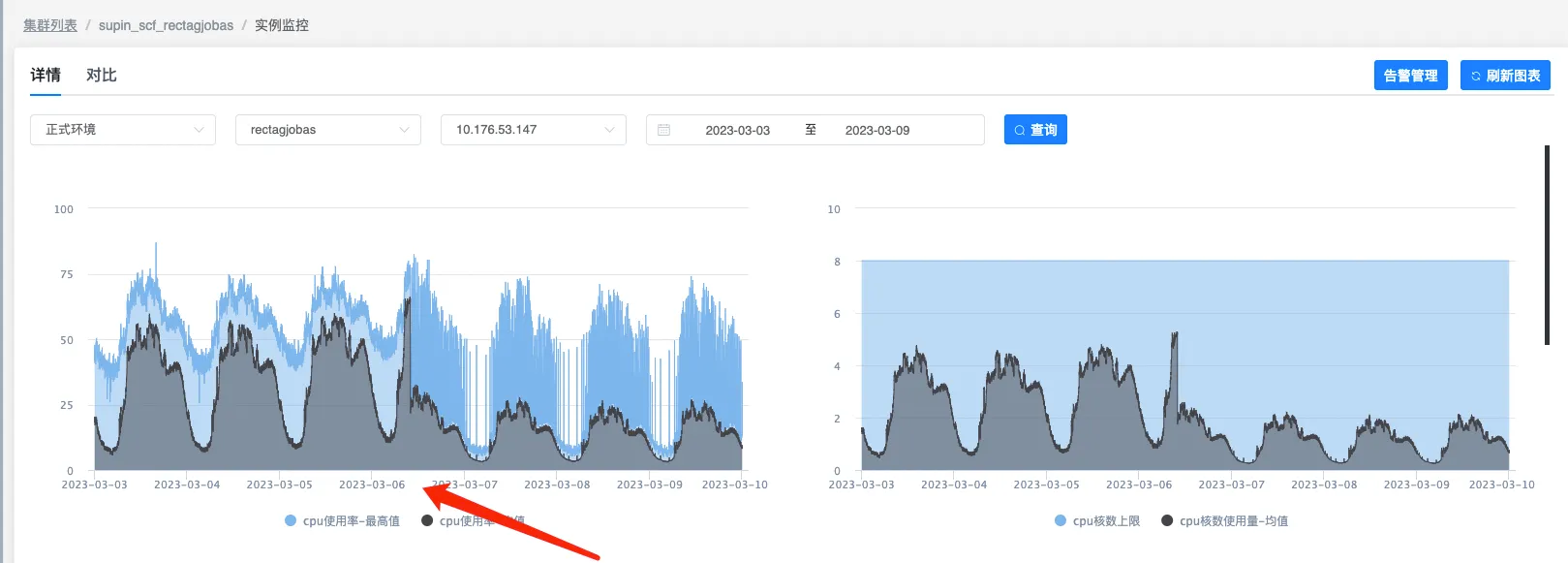
之前一直在关心CPU,突然看见了内存的使用率,一下就明白的问题所在,从下面这张图可以看出,CPU使用率和内存使用率是成反比的
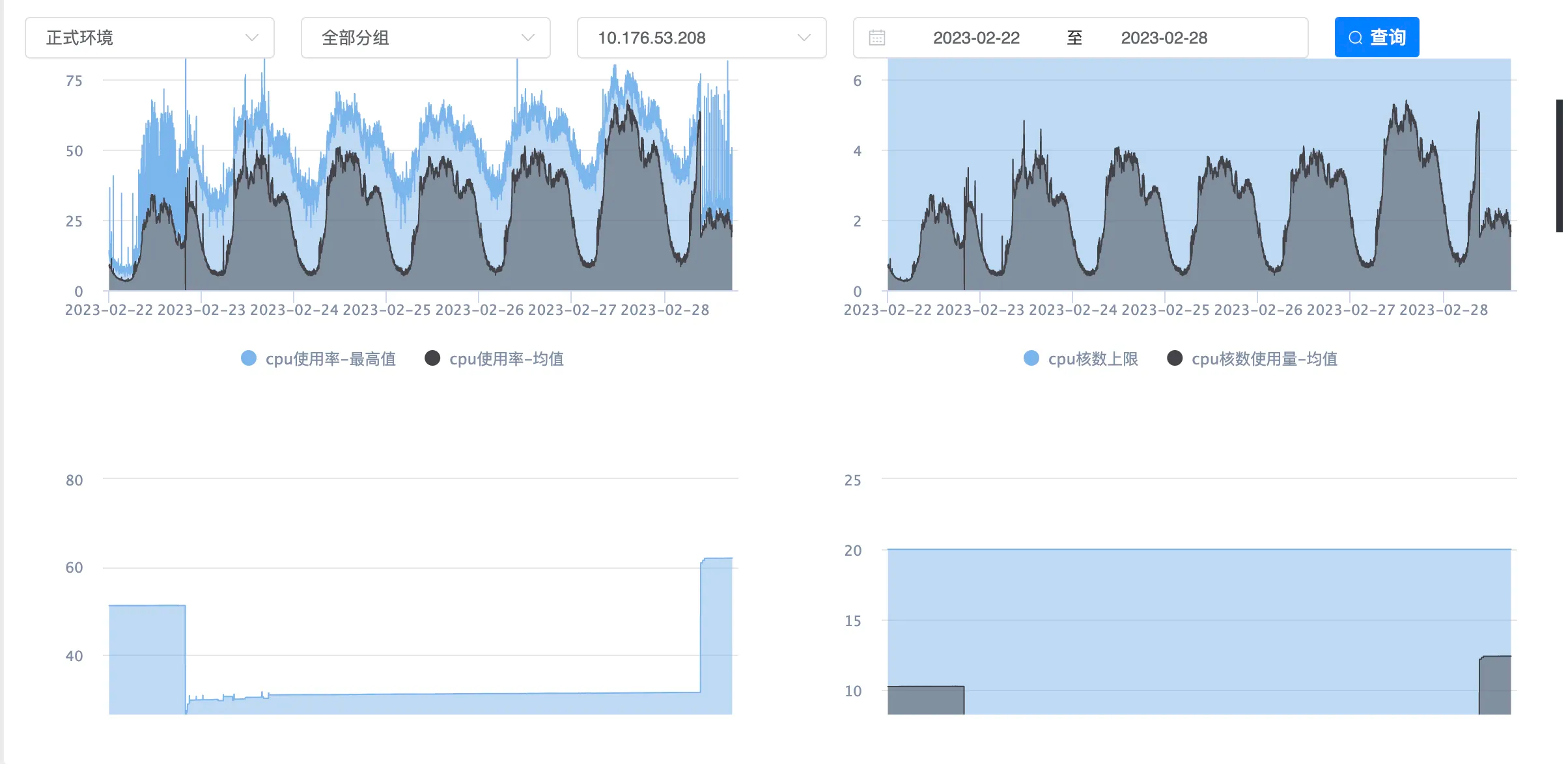
使用Java的都应该清楚,内存不够的时候,就会STW,然后去启动GC线程去GC,而且一般情况GC线程数和CPU核数是一致的,这个服务也是如此,此时CPU使用率必然是会变高的
上面3月6号CPU突然下降的原因也是因为内存使用变高了,这是在没有上线的情况下
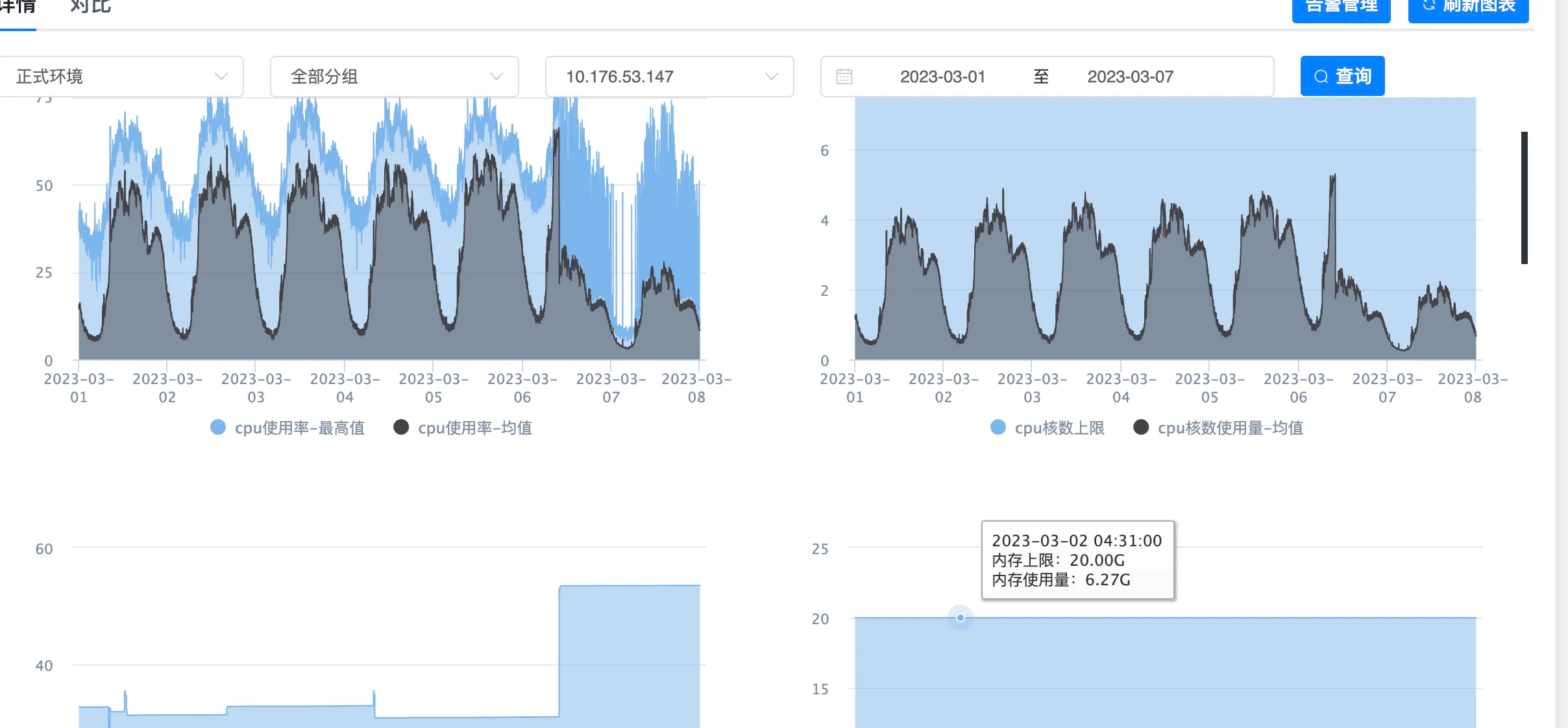
可以看到上面的图中,CPU使用率高的时候,内存占用只有20%左右,为什么空这这么多内存不用呢?看下JVM参数
-Xmx16g -Xms4g -Xss1024K -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=10 -XX:MetaspaceSize=512m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=8 -XX:G1HeapRegionSize=16m -XX:-OmitStackTraceInFastThrow
复制Xms配的是4G,也就是说JVM在启动时只会申请4G内存,当内存不足时,先会GC,当GC释放的内存还不够时,才会去申请更大的内存
这样的策略一般是为了节省内存,但目前主流的都是容器,节省下来的内存也不会给别的服务利用,所以我们这可以直接把Xms改为16G
改完之后立即得到了很好的效果,超时率降了四分之三,不过后续因为内存使用率变高,超过了阈值,所以又把Xmx和Xms调整为14G,这个问题可以参考我之前的文章一次Java服务内存过高的分析过程
这两个参数使用Java的都比较了解
Xmx: JVM的最大堆内存
Xms: JVM的初始堆内存
为了避免在生产环境由于heap内存扩大或缩小导致应用停顿,降低延迟,同时避免每次垃圾回收完成后JVM重新分配内存。所以,-Xmx和-Xms一般都是设置相等的
在生产环境中把Xms和Xmx设为相同值也是Oracle官方推荐
这个配置从机器上线跑了两年一直如此,大部分时间性能没被充分利用,现在有二十台机器都是以这样一种低性能模式跑了这么久,这绝对是一种浪费
在第三篇参考文章中,有个人的评论正好和我相反,他认为一开始将Xms和Xmx设置为一样,而实际没用那么多,其实也是一种浪费,不过这是18年前的文章,那时容器没有兴起,服务都在一个物理机上面共享内存,会是有这种问题的
在容器中,节省的内存别的服务也利用不了,所以Xms最后设置和Xmx一致,但是容器也是可能造成浪费的,比如上面我把Xmx和Xms从16G改为14G,从监控上来看耗时和超时率下降了一点,也就是把这个容器的内存往下调一点也是可以接受的,具体调到多少合适也不太确定
不过这种优化很没有必要,内存是很便宜的,而且适量冗余一些性能也可以理解
既然这么多好处,为什么Oracle不默认把Xms和Xmx设置为一致呢,我觉得可能是目前还是有大部分Java应用都不是容器环境,全局考虑,没有这样做,或许后续Java会判断是否是容器环境来自动设置Xms
[2] Is there any advantage in setting Xms and Xmx to the same value?