上一篇已经将playwright的元素定位大法基本介绍的差不多了,但是在Web的UI自动化的测试中,我们通常需要使用一些方法来操作浏览器,今天就跟随学习了解一下。这一篇宏哥主要是介绍一下,在自动化测试的时候,我们常见的一些浏览器操作有哪些,宏哥将会一一介绍和讲解。
在介绍浏览器的相关操作之前,宏哥先介绍一下层级,宏哥理解的其实就是操作层级,不对的话,欢迎批评指正。在Playwright中,测试层级为:
Broswer->Context->Page
宏哥首先介绍一下浏览器常用的基本操作,然后再通过具体实例给小伙伴或者童鞋们演示一下。既然是浏览器的操作,那首先得将浏览器启动(打开)才能操作,因此首先介绍一下playwright如何启动浏览器。
浏览器是通过browser_type.launch()创建的。
browser = playwright.chromium.launch(headless=False, args=['--start-maximized'])
上面启动了一个浏览器,开启有头模式,并且通过args参数向chrome传递开启时窗口最大化。
开启浏览器格式为playwright.browser_type.launch (...args),browser_type为浏览器类型,args为传递给浏览器的参数,这个可以参考浏览器的官方文档。
忽略HTTPS告警:加入如下参数即可。
'--ignore-certificate-errors'
其他更多详细内容您可以参考官方文档,查看完整的API参数列表:BrowserType | Playwright Python
使用browser.new_context() 创建context对象,context之间是相互隔离的,可以理解为轻量级的浏览器实例。它不会与其他浏览器上下文共享 cookies/缓存。
如需要不同用户登录同一个网页,不需要创建多个浏览器实例,只需要创建多个context即可。
context = browser.new_context(no_viewport=True)
上下文就是浏览器的环境,Page是页面包含了元素、组件的状态等等,而上下文则包括了会话状态、Cookie、页面信息等。
注意:我们需要设置no_viewport=True,否则将默认按照800*600创建视口,你会发现,窗口很大,但是网页很小。
使用add_cookies()为上下文添加cookie。
browser_context.add_cookies([cookie_object1, cookie_object2])
参数为字典列表,每个cookie字典有如下字段,其中url或者域名、path虽然都是可选的,但必须要有一个。
name 名称 value 值 url 可选 domain 域名 path 路径 expires 浮点数,过期时间,Unix时间(精确到秒)可选 httpOnly 是否为httpOnly,可选 secure 安全模式,可选 sameSite "Strict"|"Lax"|"None" 同站策略,可选
在context上新建一个页面对象然后调用goto方法即可。
page = context.new_page() page.goto("https://www.baidu.com")
page.reload()
page.go_back()
page.go_forward()
前边宏哥提到可以通过设置 args 参数 --start-maximized 并且设置 no_viewport=True
from playwright.sync_api import sync_playwright with sync_playwright() as p: browser = p.chromium.launch( headless=False,#关闭无头模式 args=['--start-maximized'] #设置谷歌浏览器参数 ) context = browser.new_context(no_viewport=True) #设置no_viewport参数 page = context.new_page() page.goto("https://www.baidu.com") page.pause()
我们可以通过viewport指定窗口大小。已知问题:浏览器不会贴合到屏幕左侧。
viewport 可以在 new_context 或者 new_page 方法中设置,都可生效。
from playwright.sync_api import sync_playwright with sync_playwright() as p : browser = p.chromium.launch( headless=False, ) context = browser.new_context( viewport={'width': 1920, 'height': 1080}, ) page = context.new_page() page.goto("https://www.baidu.com") page.pause()
先关闭上下文,再退出浏览器。
关闭上下文时,上下文所属的页面也会一起关闭。
browser_context.close()
browser.close()
from playwright.sync_api import sync_playwright def run(playwright): iphone_13 = playwright.devices['iPhone 13'] browser = playwright.webkit.launch(headless=False) context = browser.new_context( **iphone_13, ) with sync_playwright() as playwright: run(playwright)
以度娘为例,首先启动浏览器,然后再设置浏览器的大小。查询“北京宏哥”后,刷新页面执行回退到百度首页,然后有执行前进进入到搜索“北京宏哥”页面,最后退出浏览器。
按照上边的步骤进行代码设计,如下图所示:
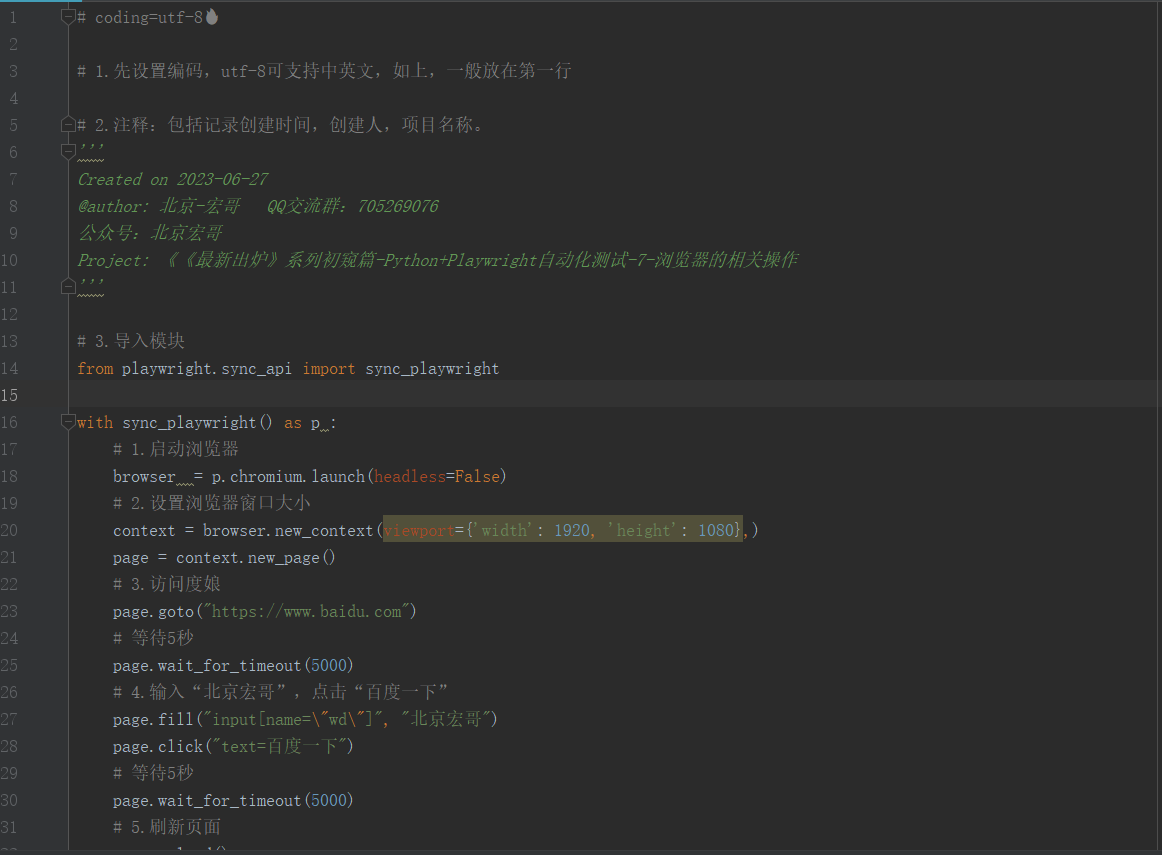
# coding=utf-8🔥 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。 ''' Created on 2023-06-27 @author: 北京-宏哥 QQ交流群:705269076 公众号:北京宏哥 Project: 《《最新出炉》系列初窥篇-Python+Playwright自动化测试-7-浏览器的相关操作 ''' # 3.导入模块 from playwright.sync_api import sync_playwright with sync_playwright() as p : # 1.启动浏览器 browser = p.chromium.launch(headless=False) # 2.设置浏览器窗口大小 context = browser.new_context(viewport={'width': 1920, 'height': 1080},) page = context.new_page() # 3.访问度娘 page.goto("https://www.baidu.com") # 等待5秒 page.wait_for_timeout(5000) # 4.输入“北京宏哥”,点击“百度一下” page.fill("input[name=\"wd\"]", "北京宏哥") page.click("text=百度一下") # 等待5秒 page.wait_for_timeout(5000) # 5.刷新页面 page.reload() # 等待5秒 page.wait_for_timeout(5000) # 6.浏览器后退 page.go_back() # 等待5秒 page.wait_for_timeout(5000) # 7.浏览器前进 page.go_forward() # 8.浏览器退出 page.wait_for_timeout(5000) context.close() browser.close()
1.运行代码,右键Run'Test',控制台输出,如下图所示:

2.运行代码后电脑端的浏览器的动作,可以看到查询“北京宏哥”后,刷新页面执行回退到百度首页,然后有执行前进进入到搜索“北京宏哥”页面。如下图所示:

好了,关于浏览器的相关操作非常简单,时间不早了今天就分享到这里,感谢你耐心地阅读!