通过前边的讲解和学习,细心认真地小伙伴或者童鞋们可能发现在Playwright中,没有Element这个概念,只有Page的概念,Page不仅仅指的是某个页面,例如页面间的跳转等,还包含了所有元素、事件的概念,所以我们包括定位元素、页面转向,都是基于Page操作的。页面提供了与浏览器中的单个选项卡或 Chromium 中的扩展后台页面进行交互的方法。一个浏览器实例可能有多个 Page 实例。
相信第一次接触Playwright的同学,一定会对Browser、Context 和Page这三个概念所困扰,不知道这三者有怎样的联系,今天宏哥就带大家梳理一下,一张图让大家秒懂!
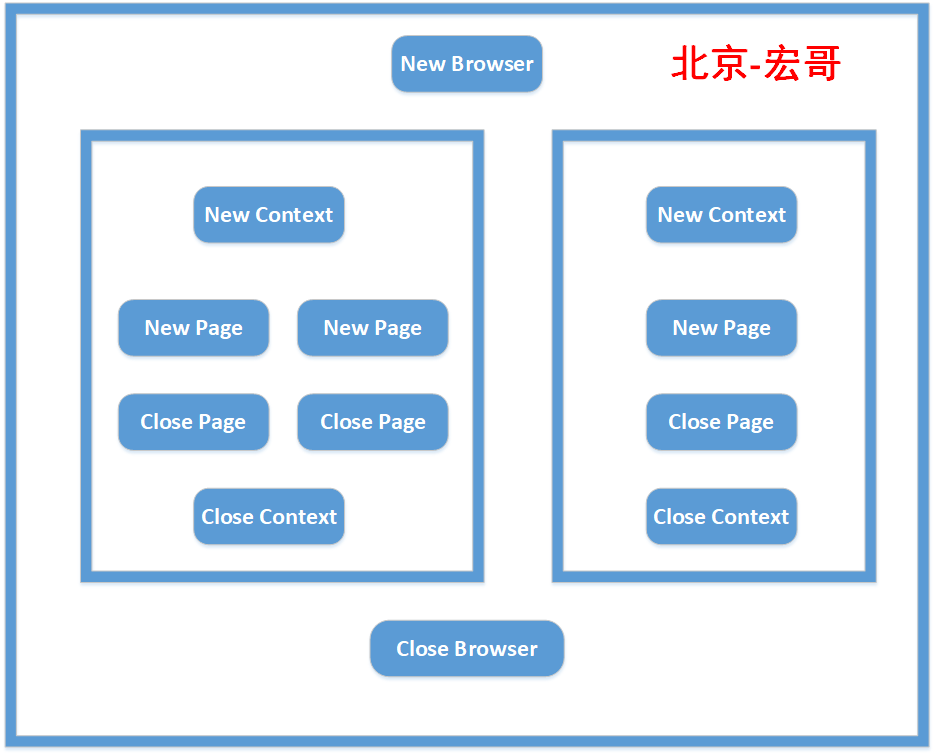
对应一个浏览器实例(Chromium、Firefox或WebKit),Playwright脚本以启动浏览器实例开始,以关闭浏览器结束。浏览器实例可以在headless或者 headful模式下启动。一个 Browser 可以包含多个 BrowserContext。一个Browser是一个Chromium, Firefox 或 WebKit(plarywright支持的三种浏览器)的实例plarywright脚本通常以启动浏览器实例开始,以关闭浏览器结束。浏览器实例可以在headless(没有 GUI)或head模式下启动。
启动browser实例是比较耗费资源的,plarywright做的就是如何通过一个browser实例最大化多个BrowserContext的性能。
Playwright为每个测试创建一个浏览器上下文,即BrowserContext,浏览器上下文相当于一个全新的浏览器配置文件,提供了完全的测试隔离,并且零开销。创建一个新的浏览器上下文只需要几毫秒,每个上下文都有自己的Cookie、浏览器存储和浏览历史记录。浏览器上下文允许同时打开多个页面并与之交互,每个页面都有自己单独的状态,一个 BrowserContext 可以包含多个 Page。一个BrowserContex就像是一个独立的匿名模式会话(session),非常轻量,但是又完全隔离。
每个browser实例可有多个BrowserContex,且完全隔离。比如可以在两个BrowserContext中登录两个不同的账号,也可以在两个 context 中使用不同的代理。
context还可用于模拟涉及移动设备、权限、区域设置和配色方案的多页面场景。
页面指的是浏览器上下文中的单个选项卡或弹出窗口。在Page中主要完成与页面元素交互,一个 Page 可以包含多个 Frame。
每个页面有一个主框架(page.MainFrame()),也可以有多个子框架,由 iframe 标签创建产生。在playwright中,无需切换iframe,可以直接定位元素(这点要比selenium方便很多)。好了接下来我们着重来看一下page。
page.goto("https://example.com")复制
page.screenshot(path="screenshot.png")复制
page.on("frameattached", handler)复制
返回一个Locator:
page.get_by_text("test") # 模糊匹配 page.get_by_text("test", exact=True) # 精准匹配复制
page.go_back() page.go_back(**kwargs)复制
page.go_forward() page.go_forward(**kwargs)复制
page.locator(selector) page.locator(selector, **kwargs)复制
以度娘为例,首先启动浏览器,然后再设置浏览器的大小。查询“北京宏哥”后,刷新页面执行回退到百度首页,然后有执行前进进入到搜索“北京宏哥”页面,最后退出浏览器。
按照上边的步骤进行代码设计,如下图所示:
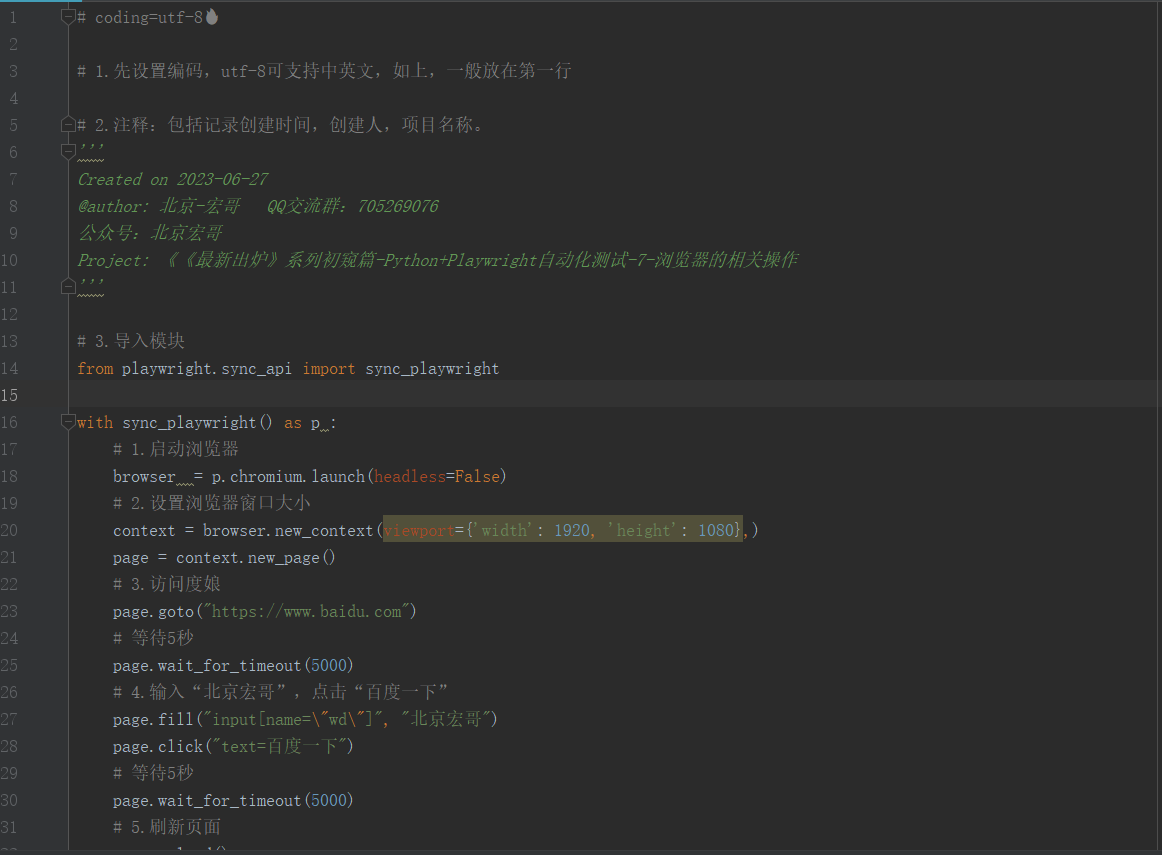
# coding=utf-8🔥
# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行
# 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-06-27
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《《最新出炉》系列初窥篇-Python+Playwright自动化测试-7-浏览器的相关操作
'''
# 3.导入模块
from playwright.sync_api import sync_playwright
with sync_playwright() as p :
# 1.启动浏览器
browser = p.chromium.launch(headless=False)
# 2.设置浏览器窗口大小
context = browser.new_context(viewport={'width': 1920, 'height': 1080},)
page = context.new_page()
# 3.访问度娘
page.goto("https://www.baidu.com")
# 等待5秒
page.wait_for_timeout(5000)
# 4.输入“北京宏哥”,点击“百度一下”
page.fill("input[name=\"wd\"]", "北京宏哥")
page.click("text=百度一下")
# 等待5秒
page.wait_for_timeout(5000)
# 5.刷新页面
page.reload()
# 等待5秒
page.wait_for_timeout(5000)
# 6.浏览器后退
page.go_back()
# 等待5秒
page.wait_for_timeout(5000)
# 7.浏览器前进
page.go_forward()
# 8.浏览器退出
page.wait_for_timeout(5000)
context.close()
browser.close()复制
1.运行代码,右键Run'Test',控制台输出,如下图所示:

2.运行代码后电脑端的浏览器的动作,可以看到查询“北京宏哥”后,刷新页面执行回退到百度首页,然后有执行前进进入到搜索“北京宏哥”页面。如下图所示:

browser,context和page这三层结构个人浅见:
(1)Browser可以理解为物理层,比较常用的参数为浏览器类型,headless(是否在内存中打开浏览器)以及超时时间。
(2)Context为上下文层,常用的参数为设置窗口大小以及录像路径。
(3)page为页面层,就是为了打开“可见”的页面,只有这一层才是真的访问了页面。
关于page的介绍和讲解也非常简单,这里就是希望小伙伴或者童鞋们在脑海里留下一个印象。好了,时间不早了今天就分享到这里,感谢你耐心地阅读!