标签操作其实也是基于浏览器上下文(BrowserContext)进行操作的,而且宏哥在之前的BrowserContext也有提到过,但是有的童鞋或者小伙伴还是不清楚怎么操作,或者思路有点模糊,因此今天单独来对其进行讲解和分享一下,希望您有所帮助。
单个标签操作这个是最简单的,之前讲的绝大多数都是单个标签的操作。通过context.new_page()就可以创建一个页面。
实战举例:以度娘为例,首先启动浏览器,然后再设置浏览器的大小。查询“北京宏哥”后,刷新页面执行回退到百度首页,然后有执行前进进入到搜索“北京宏哥”页面,最后退出浏览器。
按照上边的步骤进行代码设计,如下图所示:
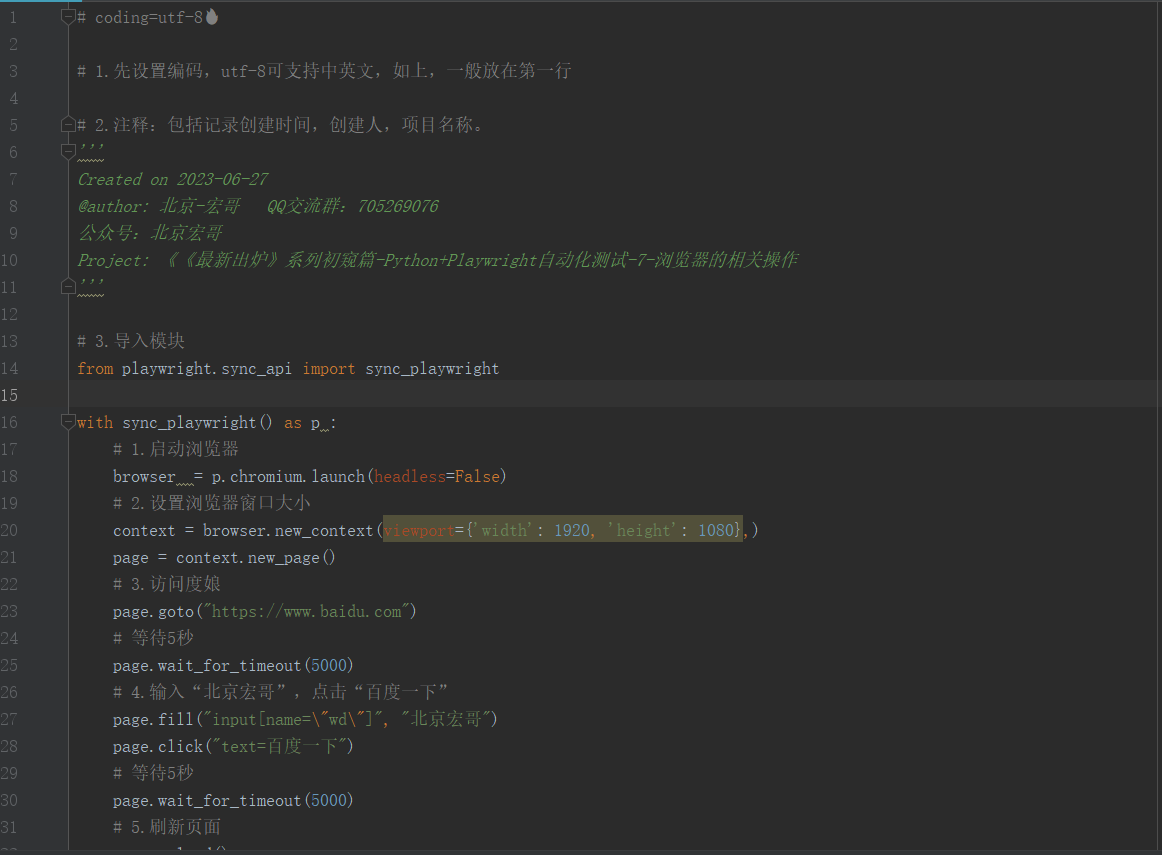
# coding=utf-8🔥
# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行
# 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-06-27
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《《最新出炉》系列初窥篇-Python+Playwright自动化测试-10-标签页操作
'''
# 3.导入模块
from playwright.sync_api import sync_playwright
with sync_playwright() as p :
# 1.启动浏览器
browser = p.chromium.launch(headless=False)
# 2.设置浏览器窗口大小
context = browser.new_context(viewport={'width': 1920, 'height': 1080},)
page = context.new_page()
# 3.访问度娘
page.goto("https://www.baidu.com")
# 等待5秒
page.wait_for_timeout(5000)
# 4.输入“北京宏哥”,点击“百度一下”
page.fill("input[name=\"wd\"]", "北京宏哥")
page.click("text=百度一下")
# 等待5秒
page.wait_for_timeout(5000)
# 5.刷新页面
page.reload()
# 等待5秒
page.wait_for_timeout(5000)
# 6.浏览器后退
page.go_back()
# 等待5秒
page.wait_for_timeout(5000)
# 7.浏览器前进
page.go_forward()
# 8.浏览器退出
page.wait_for_timeout(5000)
context.close()
browser.close()复制
1.运行代码,右键Run'Test',控制台输出,如下图所示:

2.运行代码后电脑端的浏览器的动作,可以看到查询“北京宏哥”后,刷新页面执行回退到百度首页,然后有执行前进进入到搜索“北京宏哥”页面。如下图所示:

每个浏览器上下文可以承载多个页面(选项卡)。
# create two pages page_one = context.new_page() page_two = context.new_page() # get pages of a browser context all_pages = context.pages复制
实战举例:在page_one 标签页打开百度,输入“北京-宏哥”, 在page_two 标签页打开百度,输入“宏哥”。
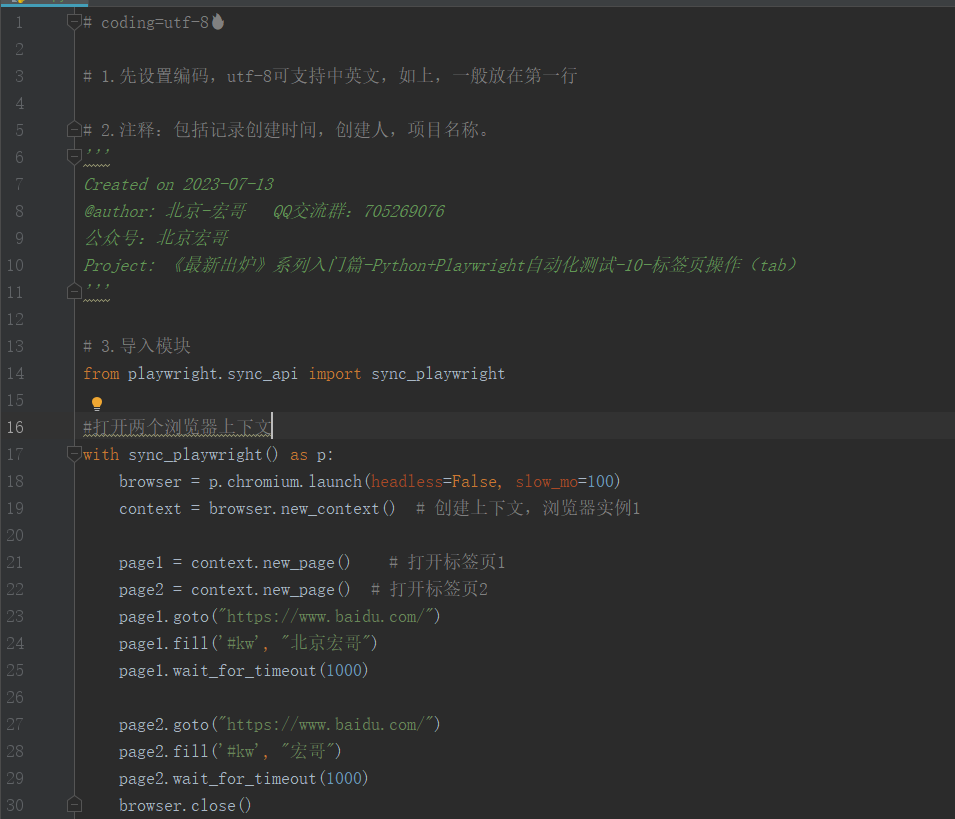
# coding=utf-8🔥 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。 ''' Created on 2023-07-13 @author: 北京-宏哥 QQ交流群:705269076 公众号:北京宏哥 Project: 《最新出炉》系列入门篇-Python+Playwright自动化测试-10-标签页操作(tab) ''' # 3.导入模块 from playwright.sync_api import sync_playwright #打开两个浏览器上下文 with sync_playwright() as p: browser = p.chromium.launch(headless=False, slow_mo=100) context = browser.new_context() # 创建上下文,浏览器实例1 page1 = context.new_page() # 打开标签页1 page2 = context.new_page() # 打开标签页2 page1.goto("https://www.baidu.com/") page1.fill('#kw', "北京宏哥") page1.wait_for_timeout(1000) page2.goto("https://www.baidu.com/") page2.fill('#kw', "宏哥") page2.wait_for_timeout(1000) browser.close()复制
1.运行代码,右键Run'Test',控制台输出,如下图所示:
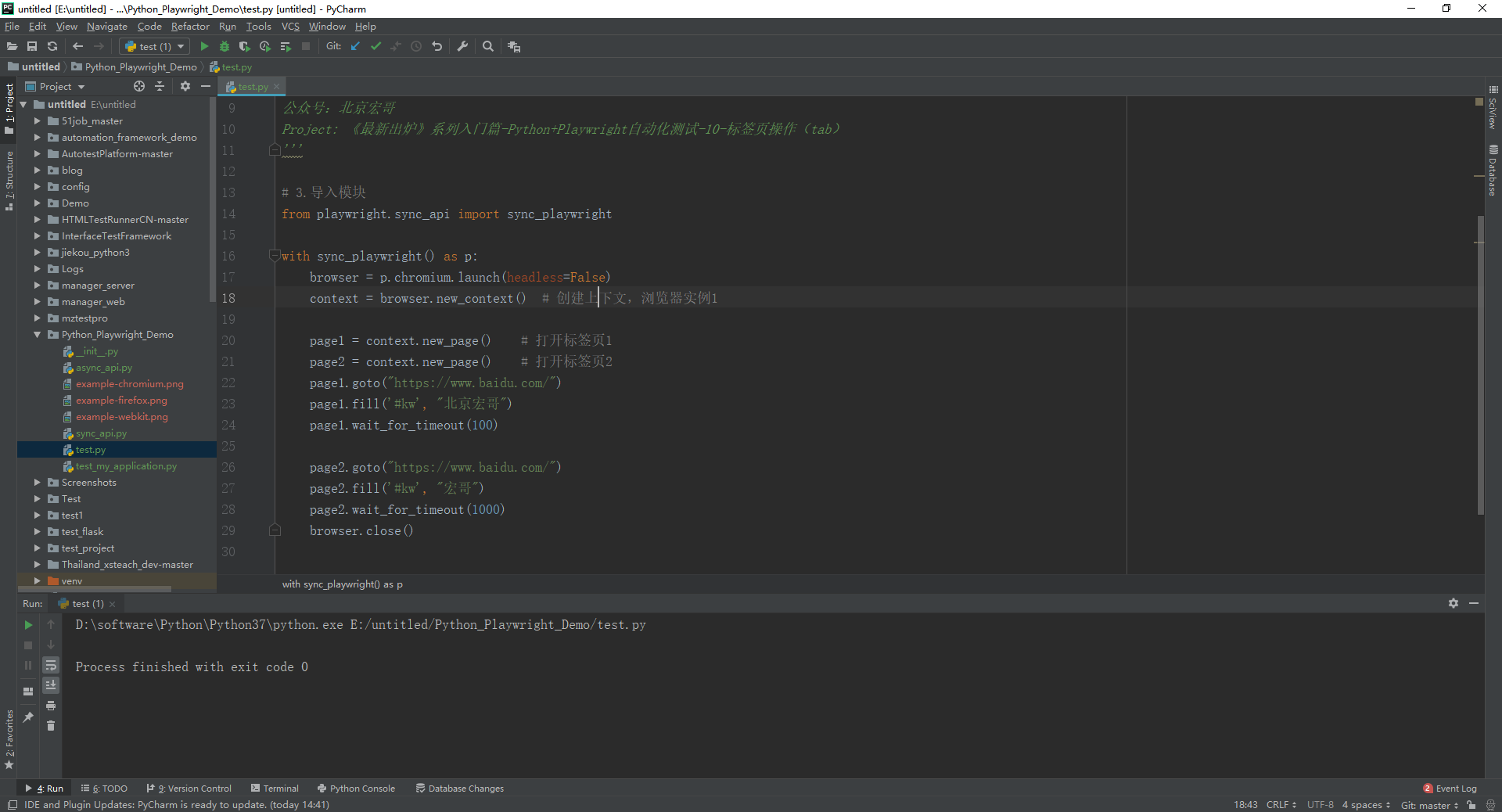
2.运行代码后电脑端的浏览器的动作。虽然你看不到第一个页面的操作,实际上它已经操作了,每个页面 page对象都是聚焦的活动页面, 不需要将页面置于最前面。如下图所示:
浏览器上下文中的事件page可用于获取在上下文中创建的新页面。这可用于处理通过target="_blank"链接打开的新页面。
# Get page after a specific action (e.g. clicking a link) with context.expect_page() as new_page_info: page.get_by_text("open new tab").click() # Opens a new tab new_page = new_page_info.value new_page.wait_for_load_state() print(new_page.title())复制
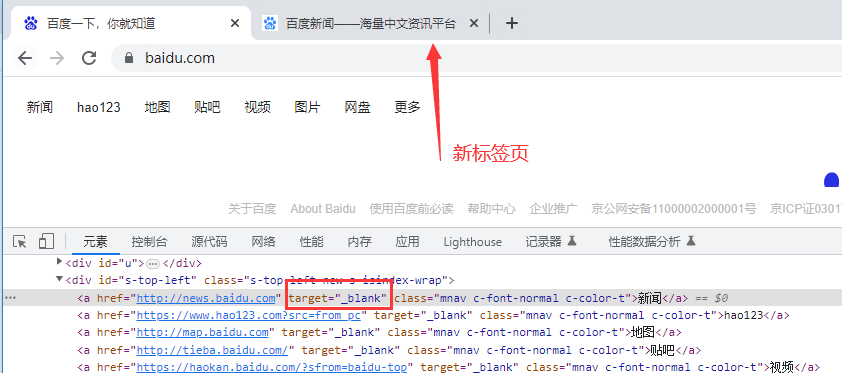
实战举例:打开百度页面的-新闻链接,会出现一个新标签页,如下图所示:
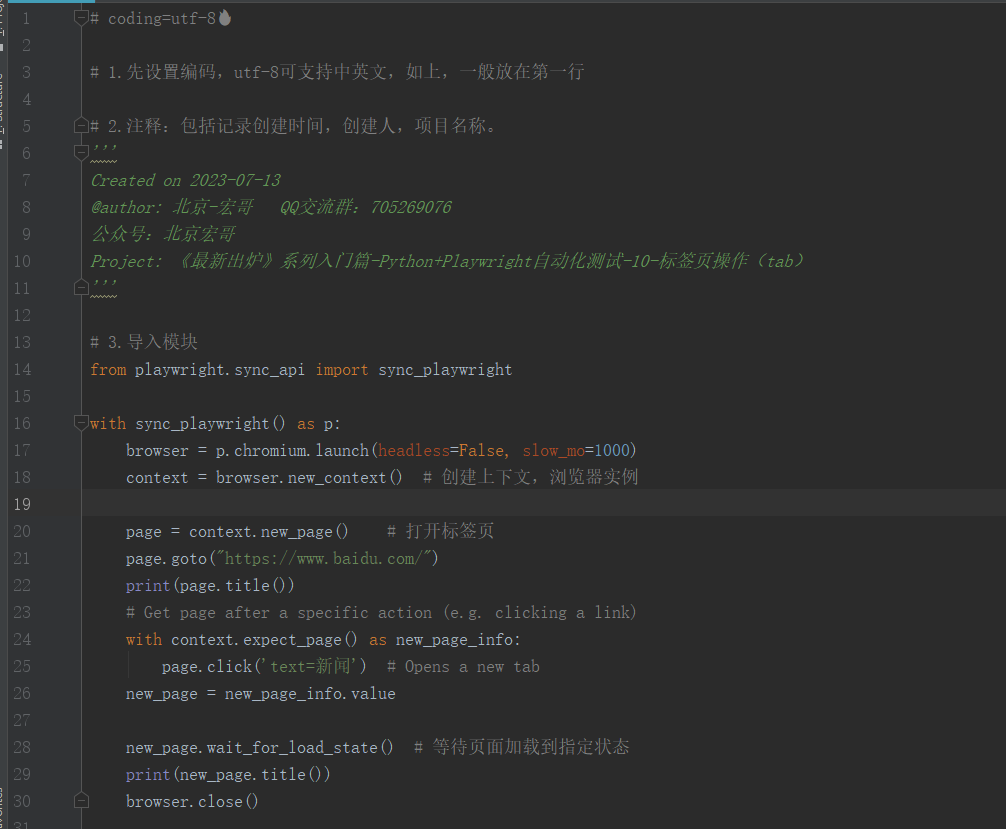
# coding=utf-8🔥 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。 ''' Created on 2023-07-13 @author: 北京-宏哥 QQ交流群:705269076 公众号:北京宏哥 Project: 《最新出炉》系列入门篇-Python+Playwright自动化测试-10-标签页操作(tab) ''' # 3.导入模块 from playwright.sync_api import sync_playwright with sync_playwright() as p: browser = p.chromium.launch(headless=False, slow_mo=1000) context = browser.new_context() # 创建上下文,浏览器实例 page = context.new_page() # 打开标签页 page.goto("https://www.baidu.com/") print(page.title()) # Get page after a specific action (e.g. clicking a link) with context.expect_page() as new_page_info: page.click('text=新闻') # Opens a new tab new_page = new_page_info.value new_page.wait_for_load_state() # 等待页面加载到指定状态 print(new_page.title()) browser.close()复制
1.运行代码,右键Run'Test',控制台输出,如下图所示:

2.运行代码后电脑端的浏览器的动作。如下图所示:
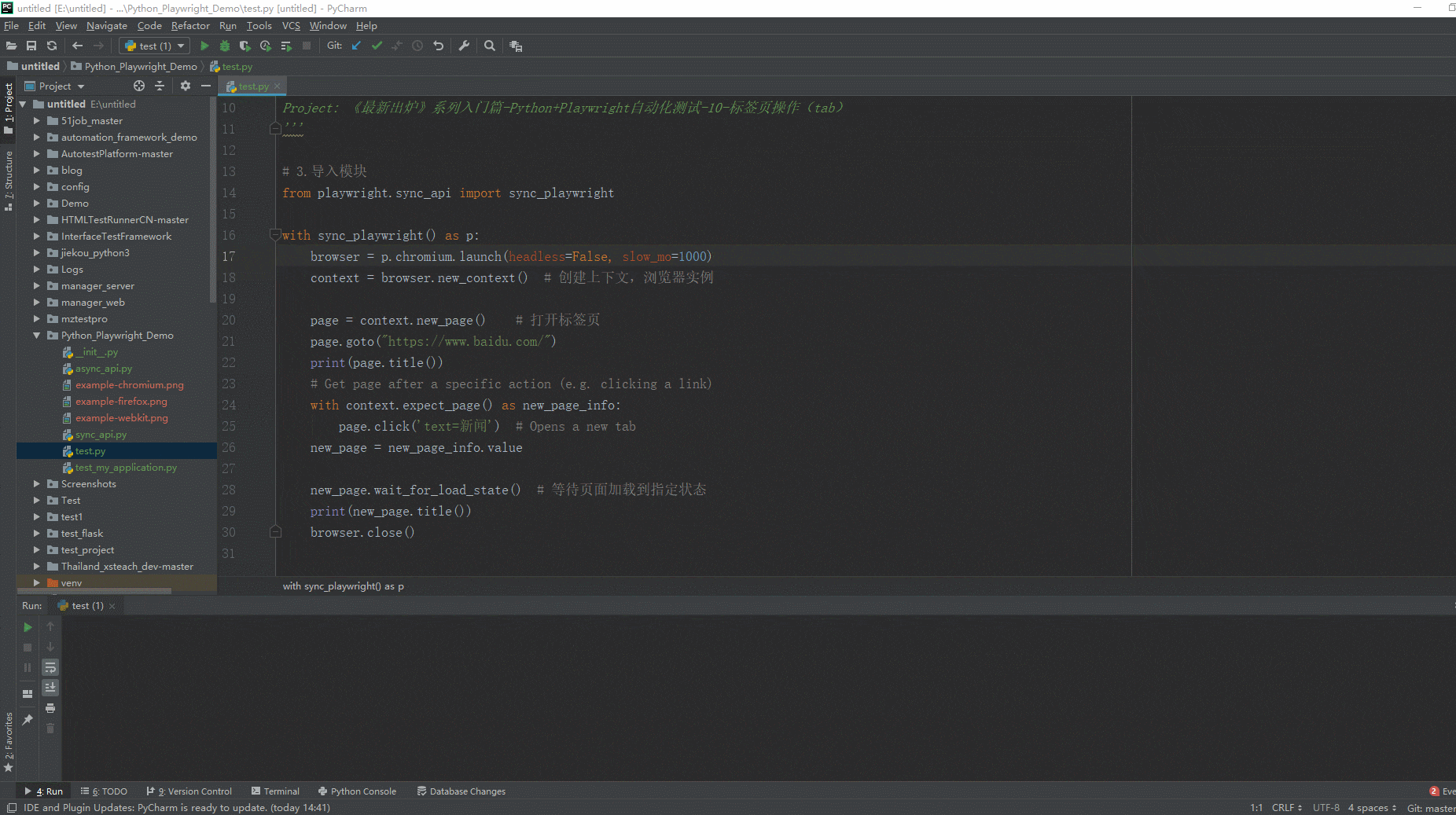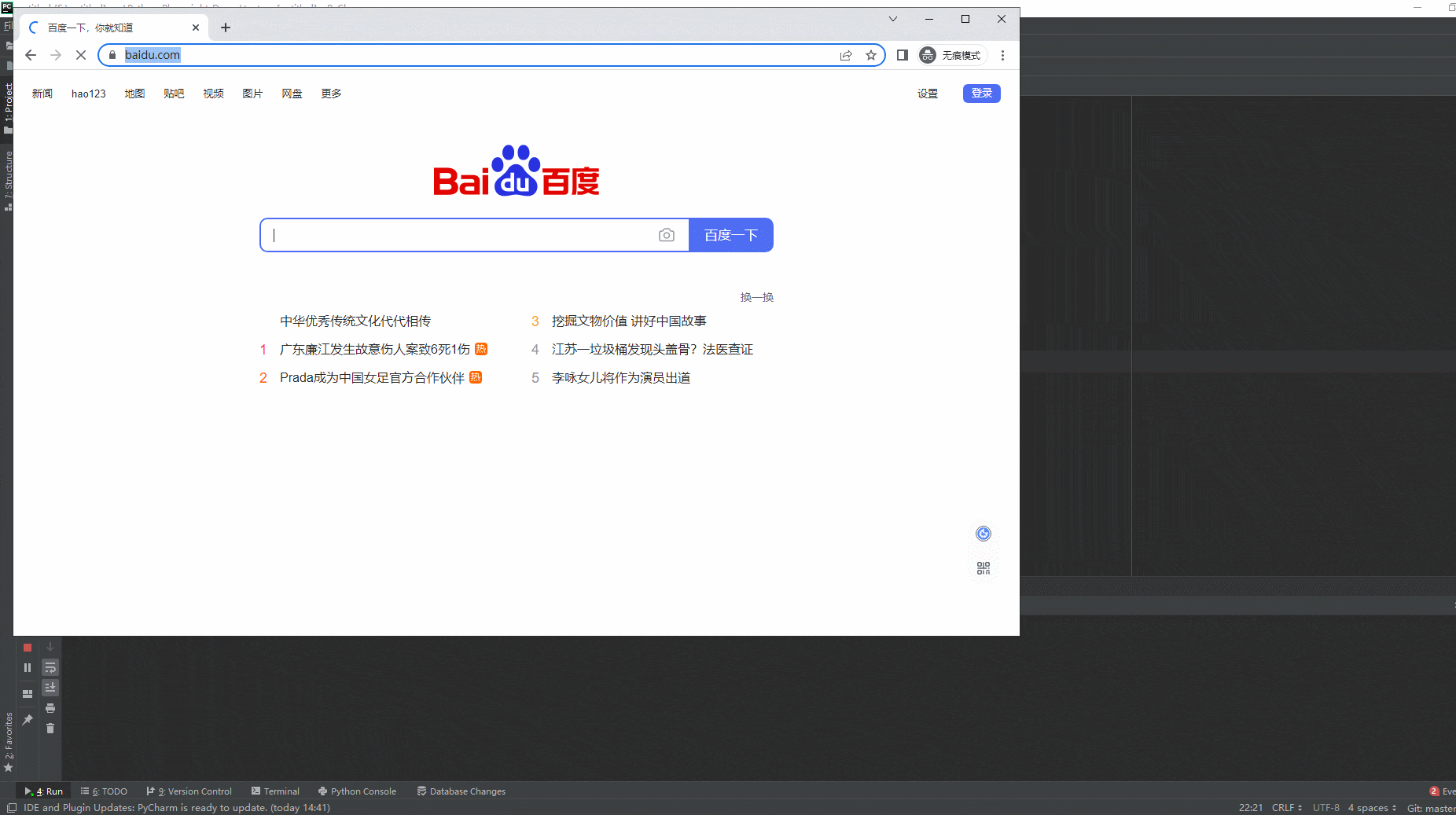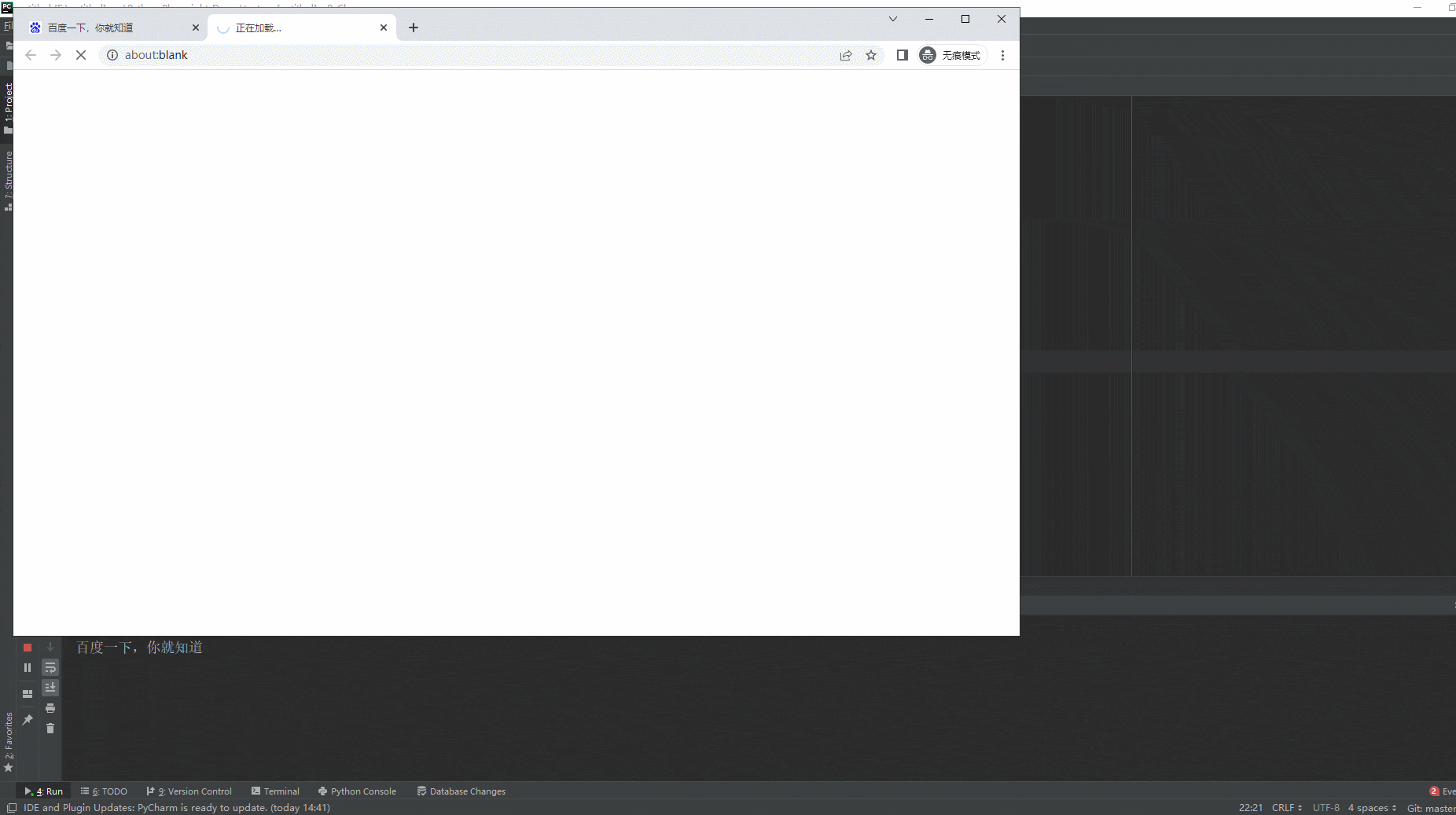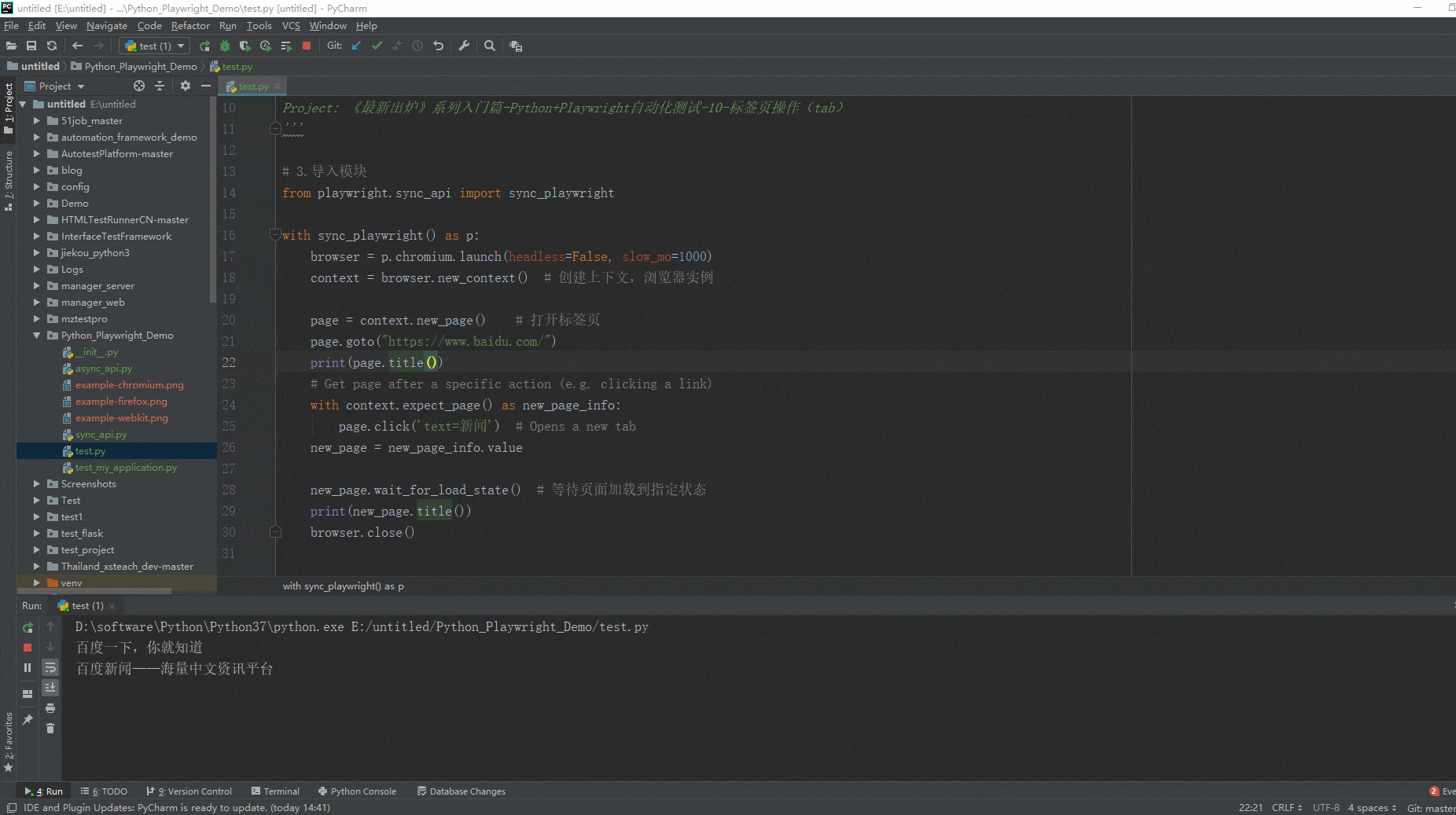
如果触发新页面的操作未知,可以使用以下模式。
# Get all new pages (including popups) in the context def handle_page(page): page.wait_for_load_state() print(page.title()) context.on("page", handle_page)复制
如果页面打开一个弹出窗口(例如通过链接打开的页面),您可以通过监听页面上的事件target="_blank"来获取对它的引用。popup
除了browserContext.on('page')事件之外还会发出此事件,但仅针对与此页面相关的弹出窗口。
# Get popup after a specific action (e.g., click) with page.expect_popup() as popup_info: page.get_by_text("open the popup").click() popup = popup_info.value popup.wait_for_load_state() print(popup.title())复制
如果触发弹出窗口的操作未知,则可以使用以下模式。
# Get all popups when they open def handle_popup(popup): popup.wait_for_load_state() print(popup.title()) page.on("popup", handle_popup)复制
好了,时间不早了,关于标签操作宏哥就今天就分享到这里。感谢你耐心地阅读。