https://zhuanlan.zhihu.com/p/541745804复制
于哥你好,最近面试挺多的,尤其是在问到java面试题,Redis被问的特别多,比如
Redis的内存模型?
Redis的底层数据结构是怎么的?
Redis的多线程模型 Redis的集群原理
Redis的雪崩,击穿,穿透怎么解决?
Redis它快吗?它为什么快?
等等...
 我太难了
我太难了
关于Redis如何优化,今天分享一篇好的话题,助力大家能在面试的时候有一个好的收成~
以非数字的字符串键值对为例,假设key和value的长度均为12个字节,则内部使用的编码方式为embstr。共计90000个键值对占用的空间
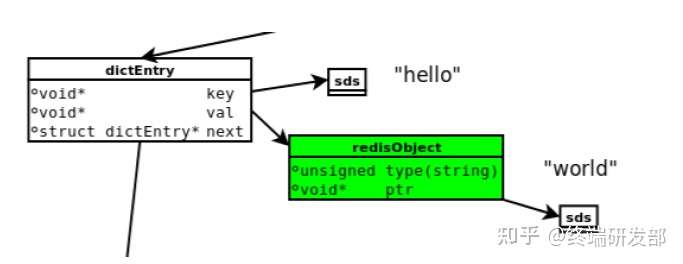
Redis中存储键值对使用字典,字典内部使用哈希表数组,数组的每个元素dictEntry中共有三个指针(指向键的指针,指向值的指针,指向下一个节点的指针),在64位系统中,每个指针占用8字节,则共计24个字节,向上取2的整数幂,则分配32个字节。
一个key,使用SDS存储,数据大小12字节,len+alloc+flags+空字符共4个字节(3.2版本之后),共计12+4=16个字节
一个value,外层使用对象redisObject并指向一个SDS(存放值内容)。对象内存占用16个字节,SDS需要16个字节
综上,一个dictEntry使用的内存总共为 32 + 16 + 16 + 16 = 80字节。
存储90000个键值对需要的bucket数组大小为90000向上取2的整数幂,即131072;每个bucket元素占用8字节(因为内部存储的指针)。
存储90000个键值对占用的总内存:90000*80 + 131072*8 = 82488576。
当存储的键值对长度由12字节增加到13字节,对应的SDS变成17字节,jemalloc分配32个字节,因此每个dictEntry占用的字节数变成112字节。则存储90000个的内存占用变为 90000*12 + 131072*8 = 11128576。
1. 利用jemalloc特性进行优化
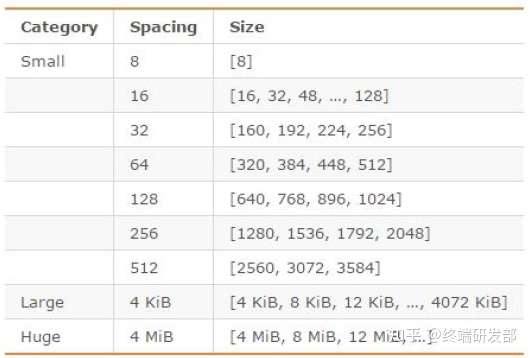
jemalloc是Redis的默认内存分配器,在64位系统中,将内存空间划分成小、大、巨大三个范围;每个范围又划分为许多小的内存块单位,当Redis存储数据时,选择适合的内存块进行存储。譬如存储130字节的对象,jemalloc会将其放入到160字节的内存单元中。
2. 使用整型/长整型
Redis存储字符串的编码类型有三种,当字符串为数字时,使用int(8字节)存储代替字符串,可以节省很多空间。
3. 共享对象
共享对象可以减少对象的创建,包括redisObject的创建。Redis中的共享对象目前只有0-9999,可以通过REDIS_SHARED_INTEGERS参数提高,譬如调整到20000,则0-19999都可以共享
4.缩短键值对的存储长度
大键值对,延长写入和读取耗时、延长持久化需要时间,延长网络传输时间,并且占用内存多,更容易触发内存淘汰机制。尽量缩短存储长度,必要时进行压缩和序列化
Redis的serverCron函数定期清除过期键,节约内存占用,避免键值对过多堆积,频繁触发内存淘汰机制
在64位系统中,默认没有设置最大内存,配置项maxmemory被注释了。当物理内存不足时,使用磁盘作为虚拟内存,将物理内存中的部分数据存放到虚拟内存,这个操作会阻塞Redis进程。当设置了最大内存,当超出限制时,触发内存淘汰。内存淘汰策略在Redis4.0后有8种,主要用到以下原理
缺点是类似全表扫描时,会将链表数据污染
缺点是短时间内大量访问的数据很难删除
删除大键值对比较耗时,造成主线程的阻塞,为此将删除的操作放在子线程中。共有四项配置:
Redis大部分的读写命令的时间复杂度在O(1)到O(N)之间。对于O(N)的命令,需要谨慎使用,如果执行时间过长,将会阻塞Redis
使用slowlog命令找出高耗时的Redis命令。慢查询的配置项:
serverCron函数每100毫秒执行一次过期扫描。随机抽取过期键字典中的20个键,删除其中的已经过期的键,判断过期键的比例是否超过25%,重复执行此流程。如果一次扫描中删除了大量过期键,将会造成阻塞。
在设置过期时间时,加入随机数。
Redis4.0之后,加入混合持久化功能,结合了RDB和AOF。在写入时,将当前数据以RDB的形式写入文件的开头,后续的操作命令以AOF的格式存入文件;在加载时,先加载RDB文件,再加载AOF命令。
RDB持久化,可能存在一定时间内的数据丢失。AOF持久化,文件较大时执行较慢,影响启动速度。在非必须持久化操作时,可以关闭持久化,避免间歇性的卡顿(serverCron函数周期性执行持久化操作)
使用Redis连接池,减少网络传输次数和非必要调用指令。
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;复制Redis分布式架构有:
详细:https://www.jianshu.com/p/f0c01c528d8d
使用物理机非虚拟机。虚拟机和物理机共享物理网口,并且一台物理机可能有多个虚拟机运行,在内存占用和网络延迟上性能较差
Linux默认开启,支持大内存页2MB分配。
开启THP之后,fork速度变慢,fork之后每个内存页从4KB变成2MB,大幅增加重写期间父进程内存消耗。同时每次写命令引起的复制内存页单位放大了512倍,会拖慢写操作的执行时间,导致大量写操作慢查询。
产生条件:1. 大量缓存同时失效 2.大量并发请求访问失效缓存 导致数据库宕机
解决方案:过期时间设置加入随机数
缓存中没有(过期),但数据库中存在数据。此时大量并发请求访问这部分数据,数据库压力陡增。缓存雪崩是大量的缓存击穿。
解决方案:
1.设置热点数据永不过期
2.接口限流熔断和降级
3.布隆过滤器。bloomfilter类似一个哈希表但是不存key,快速判断一个元素是否在集合中。使用多个哈希函数计算入参key得到坐标,在一个bit数组中存储对应位置为1。查找时只要有一个位置为0则不存在,但都为1也有可能不存在。使用多个哈希函数是基于哈希冲突的考量。
4.加锁。这种情况,只允许能有一个线程查询数据库,获取结果后将结果放入缓存,其余线程则直接访问缓存
public String getData(String key) throws Exception{
String data \= redis.get(key);
if(data == null){
if(lock.tryLock()){
data \= redis.get(key);
if(data == null){
//查询数据库
data = mysql.select();
redis.set(key,data);
}else{
return data;
}
}else{
Thread.sleep(1000);
return getData(key);
}
}
return data;
}复制缓存和数据库中都没有某数据,但有大量的并发请求查询这些数据。导致数据库宕机,主要考虑是漏洞攻击
解决方案:
作者:walker993
链接:https://www.cnblogs.com/walker993/p/14510691.html
来源:博客园
PS :最近的面试中被问到Redis的底层原理,为什么Redis会那么快,请说说 Redis 的线程模型?
面试官:Redis为何那么快,请说说 Redis 的线程模型? - 知乎 (zhihu.com)
我是程序于小二 @终端研发部,每天分享技术开发小技巧和职场经验哦,原创不易,记得来点赞收藏哦
